目标检测之YOLO V1
前面介绍的R-CNN系的目标检测采用的思路是:首先在图像上提取一系列的候选区域,然后将候选区域输入到网络中修正候选区域的边框以定位目标,对候选区域进行分类以识别。虽然,在Faster R-CNN中利用RPN网络将候选区域的提取以放到了CNN中,实现了end-to-end的训练,但是其本质上仍然是提取先提取候选区域,然后对候选区域识别,修正候选区域的边框位置。这称为tow-stage的方法,虽然在精度已经很高了,但是其速度却不是很好。造成速度不好的主要原因就是候选区域的提取,这就需要一种网络能够直接预测出图像中目标的位置,中间不需要候选区域的计算,这就是one-stage。
YOLO系就是one-stage目标检测的一种,其全名You only look once很形象,只需要将图片输入到网络中就预测中其中目标的bounding box以及bounding box所属的类别。相比R-CNN,YOLO损失了一定的精度,但是其有点就是速度快。
YOLO V1
YOLO V1将目标检测定义为一个回归问题,从图像像素信息直接得到目标的边框以及所属类别的概率,其有以下的优点:
- 快。其整个网络结构就是解决回归问题,很快。
- 在做predict的时候,使用的一整张图像的全局信息。two-stage的方法,每次只是“看到”图像的一块区域,YOLO 一次“看”一整张图像,所以它可以将目标整个的外观信息以及类别进行编码,目前最快最好的Fast R-CNN,较容易误将图像中的 background patches (背景的一个小块)看成是物体,因为它看的范围比较小。YOLO 的 background errors(背景错误) 比 Fast R-CNN 少一半多。
- YOLO得到的目标的特征表示更容易泛化
YOLO 和R-CNN性能的对比

YOLO的也有一定的缺点,其准确度落后于Faster R-CNN,并且由于其使用比较粗糙的网格来划分原图,导致其对小目标的检测效果不是很好。
主要思路
相对于R-CNN系首先从原图中计算出一系列的候选区域,YOLO则使用简单的方法,首先将图像划分为\(S\times S\)(论文中\(S = 7\))的网格,如果某个目标的中心位于一个grid cell中,则该grid cell就负责检测这个目标。
在YOLO网络中,目标的坐标信息是通过相对于某个grid cell左上角的偏移来表示的,目标的宽和高是用原图的宽和高占比表示的。 这就是这里为什么会说,如果某个目标的中心位于一个grid cell中,则该grid cell就负责检测这个目标,在做边框回归的时候,其GT就是该grid cell。
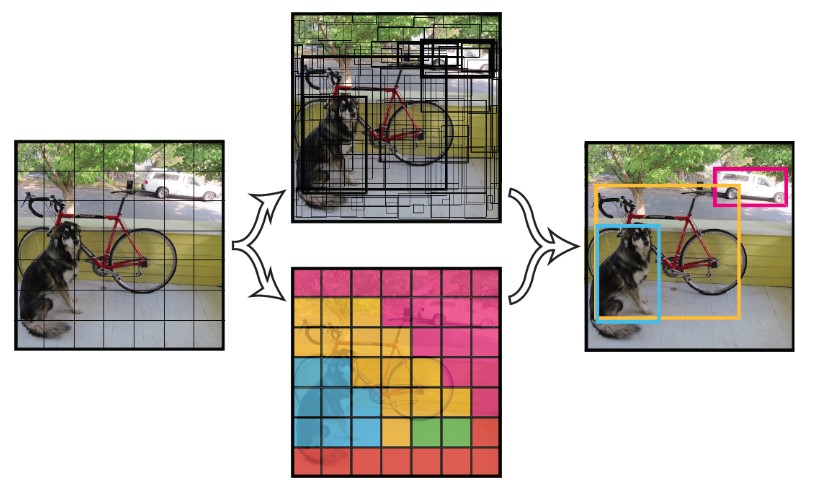
上面提到如果某个目标的中心位于一个grid cell中,则该grid cell就负责检测这个目标,也就是说在YOLO中,grid cell设计为可以代表目标,在网络中也是针对grid cell进行处理的。 在每个grid cell中预测出来\(B\)(\(B = 2\)个bounding box,而且要为每个预测出来的bounding box打个分数,来表示该bounding box是否包含目标以及该bbox作为目标边框的可信度,这个分数称为Confidence。Confidence 的定义如下:
\]
其中,\(Pr(object)\)为bbox包含目标的概率(bbox存在目标则$Pr(object) =1 \(,不存在目标则\)Pr(object) = 0\(;\)IoU_{pred}^{truth}$表示预测出来的bbox和Ground Truth之间的IoU。 也就是说,如果bbox不含目标则其confidence = 0,包含目标的话Confidence就是bbox和Ground Truth之间的IoU。
这样,通过每个grid cell预测出来的bbox可由一个五元组表示\((x,y,w,h,Confidence)\),其中\((x,y)\)表示bbox的中心相对该grid cell左上角的偏移量,使用grid cell的长宽为比例,将其值归一化到\([0,1]\)之间;\((w,h)\)为bbox的宽度和长度,以图像的宽度和长度归一化到\([0,1]\)之间;\(C\)就是上面提到的Confidence,其值也是在\([0,1]\)之间。 这样每个bbox可以使用五元组\((x,y,w,h,Confidence)\)表示,并且其值都是在\([0,1]\)之间。
以grid cell为准预测出来的bbox表示了目标的边框信息,并不能判断出来其中包含的目标是属于哪一个类。所以YOLO网络还为每一个grid cell预测出\(C\)个conditional class probability(条件类别概率):
\]
即在一个grid cell中有一个Object的前提下,它属于某个类的概率。只为每个grid cell预测一组类概率,而不考虑框的数量。
类别概率\(P(class_i | object)\)是对于某个grid cell的,表示该grid cell能够预测一个目标的条件下,其目标的属于某个类的概率;而bbox的confidence表示的是,包含目标的可行性。 将这两个值相乘,就可以得到bbox中包含的目标的的类别的概率了。
所以在测试阶段,将grid cell的\(P(class_i | object)\)和以该grid cell为准预测出来bbox的confidence相乘
\]
该值就能反应出bbox包含某一个具体类别的目标的可信度。
在YOLO论文中,使用VOC的数据集,即有20个类别,将图像划分为\(7 \times 7\)的网格,每个grid cell预测出2个bbox,因此最终输出的数据张量尺寸为\(7 \times 7 \times 30\)。(\(S \times S \times (B \times 5 + C)\))。
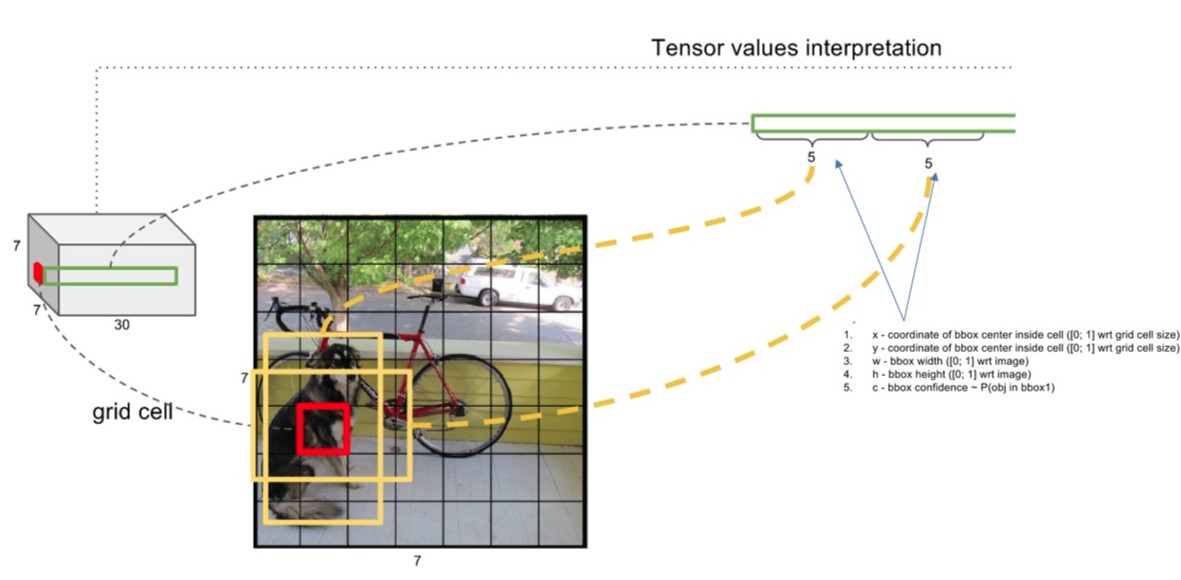
上图表示了YOLO网络针对某个grid cell的输出。
- 由于YOLO的最后输出层是全连接层,所以只能处理固定尺寸的图像\(448 \times 448 \times 3\)
- 虽然每个格子可以预测B个bounding box,但是最终只选择只选择IOU最高的bounding box作为物体检测输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个grid
cell 负责多个物体,但却只能检测出其中一个。这是YOLO方法的一个缺陷
网络结构
YOLO使用CNN来提取图像的特征,最后使用全连接层做回归预测,并且借鉴GooLeNet的思路,使用了\(1 \times 1\)卷积核。

YOLO由24个卷积层和2个全连接层组成,最终的输出为\(7 \times 7 \times 30\)的张量,也就是针对每一个grid cell YOLO网络都输出了一个30维的向量,这个30维的向量就包括上面提到的各种信息:grid cell为基准预测出来的两个bbox五元组,以及针对grid cell的预测某个类别的条件概率。具体如下:

目标函数
YOLO网络的输出实际上包含了三部分信息:bbox的位置信息,每个bbox的confidence以及每个grid cell的类别条件概率。 目标函数也就包含的三个部分:
& \lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{ij}^{obj}\left(x_i - \hat{x_i})^2 + (y_i - \hat{y_i)^2}) \right] + \lambda_{coord}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{ij}^{obj} \left[(\sqrt{w_i} - \sqrt{\hat{w_i}})^2 + (\sqrt{h_i} - \sqrt{\hat{h_i}})^2 \right] \\& + \sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{ij}^{obj}(C_i - \hat{C_i})^2 + \lambda_{noobj}\sum_{i=0}^{S^2}\sum_{j=0}^{B}1_{ij}^{noobj}(C_i - \hat{C_i})^2 \\& +
\sum_{i=0}^{S^2}1_{i}^{obj}\sum_{c \in classes}(p_i(c) - \hat{p_i)(c))^2})
\end{align*}
\]
很长的损失函数,首先来看两个超参\(\lambda_{coord}\)和\(\lambda_{noobj}\).
由于要将bbox的位置信息,confidence以及类别的概率放到同一个目标函数中,而且各个分量占的输出数据的多少也相差很多(位置信息只占了8个维度,而类别则占了20个维度),如果只是简单的使用方差作为损失则很难对三个要优化的目标做好平衡:
- 8维的位置损失和20维的分类损失同等重要显然是不合理的
- 如果一个grid cell中没有object(一幅图中这种grid cell很多),那么就会将这些grid cell中的box的confidence 置为0,相比于较少的有object的grid cell,这种做法是overpowering的,这会导致网络不稳定甚至发散。
针对上述问题,损失函数中使用权重来解决。
为了表示8维的位置损失的重要性,给位置损失前面设置个大的权重,论文中设置的是\(\lambda_{coord}= 5\)
为了平衡没有目标的grid cell,给没有目标的损失设较小的权重,论文中设置的是\(\lambda_{noobj} = 0.5\)
公式中的第一行表示bbox位置损失。关于bbox位置损失有两点,
- \(1_{ij}^{obj}\)第\(i\)个grid的第\(j\)个bbox是否负责该object的检测(与该object的ground truth的IoU最大的bbox负责该object的检测)。如果负责object的检测,则\(1_{ij}^{obj} = 1\),否则为0,不参与位置损失的计算。
- 因为目标的大小不同,其位置偏移量也不能同等对待。对于小的物体对偏移量的容忍度则较小,而大的物体其对偏移的容忍则大一些,也是是不同大小的目标,其偏移量的损失也不能一概而论。为了平衡这个问题,YOLO使用了一个比较巧妙的方法,不是直接使用预测目标的宽和高计算损失,而是使用其平方根\((\sqrt{w_i} - \sqrt{\hat{w_i}})^2 + (\sqrt{h_i} - \sqrt{\hat{h_i}})^2\),如下图
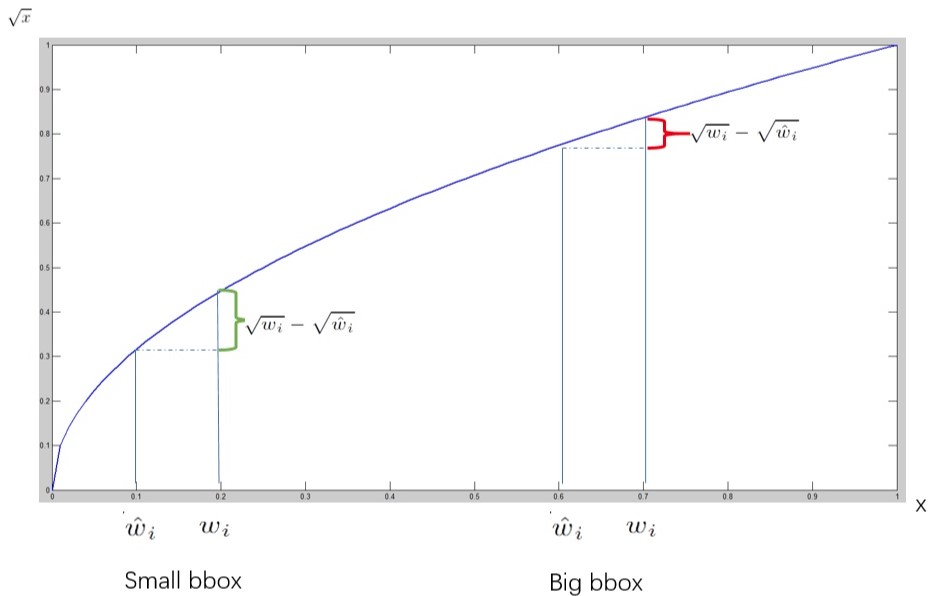 相同的位置偏移,反应在小目标的偏移损失比大目标预测的bbox要大。
相同的位置偏移,反应在小目标的偏移损失比大目标预测的bbox要大。
公式的第二行是bbox的confidence的损失。 YOLO中一个目标被一个grid cell负责检测,而同一个grid cell生成的\(B\)个bbox,也是和目标的 ground truth 的IoU负责。这样就会有大量的bbox是不负责检测目标的,也就是\(1_{ij}^{obj} = 0,1_{ij}^{noobj}=1\),而且由于包含目标的bbox较不包含目标的bbox要多很多,这里使用权值\(\lambda_{noobj}\)作为平衡,论文中使用\(\lambda_{noobj}=0.5\)
公式的第三行是grid cell的类别条件概率损失. \(1_{i}^{obj}\)表示第\(i\)个grid cell是否负责一个目标的检测。
下图能更好的解释YOLO损失函数的意义

测试
输入图片,网络会按照与训练时相同的分割方式将测试图片分割成\(S \times S\)的网格,因此,划分出来的每个网格预测的class信息和Bounding box预测的confidence信息相乘,就得到了每个Bounding box的class-specific confidence score,即得到了每个Bounding box预测具体物体的概率和Ground Truth重叠的好坏。
对于论文中,图片划分为\(7 \times 7\)的网格,最终会得到98个bbox。要分类的目标有20个类给,这样每个bbox对得到20个分数,表示该bbox在20个对象的得分。根据这20个得分情况,对98个bbox进行最大值抑制NMS,选出每个类别的最终bbox。
NMS的步骤如下:
1. 设置一个Score的阈值(0.2),低于该阈值的候选对象排除掉(将该Score设为0)。
2. 遍历20个对象(找到每个对象的最好的bbox)
2.1 遍历所有的98个bbox
2.1.1 选择socre最大的bbox添加到输出列表中
2.1.2 将计算余下的bbox的和score最大的bbox的IoU,如果大于设定的IoU阈值(0.5),则将该bbox的socre 设置为0.
2.1.3 从余下的bbox中选择score最大的,重复上面的过程,直到所有的bbox要么在输出列表中,要不其socre为0
2.2 输出列表中bbox即为当前类的预测bbox
summary
YOLO是one-stage的目标检测网络,其优点:
- 快
- 使用整幅图片进行预测,视野大,召回率低,表现为背景误检率低。
- 泛化能力强,对其他类的东西,训练后效果也是挺好的
缺点:
- 一个网格中只预测了两个框,并且只负责一类,YOLO对相互靠的很近的物体,还有很小的群体检测效果不好。
- 当同一类物体出现的不常见的长宽比和其他情况时泛化能力偏弱
- 大边界框的小误差通常是良性的,但小边界框的小误差对IOU的影响要大得多。但YOLO会同样的对待小边界框与大边界框的误差,虽然做了一定的处理,但是物体的大小对仍有很大的影响。
目标检测之YOLO V1的更多相关文章
- 目标检测:YOLO(v1 to v3)——学习笔记
前段时间看了YOLO的论文,打算用YOLO模型做一个迁移学习,看看能不能用于项目中去.但在实践过程中感觉到对于YOLO的一些细节和技巧还是没有很好的理解,现学习其他人的博客总结(所有参考连接都附于最后 ...
- 第三十六节,目标检测之yolo源码解析
在一个月前,我就已经介绍了yolo目标检测的原理,后来也把tensorflow实现代码仔细看了一遍.但是由于这个暑假事情比较大,就一直搁浅了下来,趁今天有时间,就把源码解析一下.关于yolo目标检测的 ...
- 深度学习与CV教程(13) | 目标检测 (SSD,YOLO系列)
作者:韩信子@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/37 本文地址:http://www.showmeai.tech/article-det ...
- 【转】目标检测之YOLO系列详解
本文逐步介绍YOLO v1~v3的设计历程. YOLOv1基本思想 YOLO将输入图像分成SxS个格子,若某个物体 Ground truth 的中心位置的坐标落入到某个格子,那么这个格子就负责检测出这 ...
- 【目标检测】YOLO:
PPT 可以说是讲得相当之清楚了... deepsystems.io 中文翻译: https://zhuanlan.zhihu.com/p/24916786 图解YOLO YOLO核心思想:从R-CN ...
- 目标检测算法YOLO算法介绍
YOLO算法(You Only Look Once) 比如你输入图像是100x100,然后在图像上放一个网络,为了方便讲述,此处使用3x3网格,实际实现时会用更精细的网格(如19x19).基本思想是, ...
- 目标检测之YOLO V2 V3
YOLO V2 YOLO V2是在YOLO的基础上,融合了其他一些网络结构的特性(比如:Faster R-CNN的Anchor,GooLeNet的\(1\times1\)卷积核等),进行的升级.其目的 ...
- 第三十五节,目标检测之YOLO算法详解
Redmon, J., Divvala, S., Girshick, R., Farhadi, A.: You only look once: Unified, real-time object de ...
- 小白也能弄懂的目标检测之YOLO系列 - 第一期
大家好,上期分享了电脑端几个免费无广告且实用的录屏软件,这期想给大家来讲解YOLO这个算法,从零基础学起,并最终学会YOLOV3的Pytorch实现,并学会自己制作数据集进行模型训练,然后用自己训练好 ...
随机推荐
- SQL基本语句的优化10个原则
原则一:尽量避免在列上进行运算,这样会导致索引失效. 例如: ; 优化: SELECT * FROM table WHERE d >= '2011-01-01'; 原则二:使用JOIN时,应该用 ...
- MapReduce的架构及原理
MapReduce是一种分布式计算模型,是Hadoop的主要组成之一,承担大批量数据的计算功能.MapReduce分为两个阶段:Map和Reduce. 一.MapReduce的架构演变 客户端向Job ...
- 使用xshell链接虚拟机的方法
给大家介绍一下虚拟机和Xshell5连接的基本配置1.安装虚拟机,跟着提示一步一步安装即可,注意添加镜像文件,虚拟机就完成了.2.下载一个Xshell5,安装好之后.要修改虚拟机的网卡状态 1) ...
- redis的持久化之RDB的配置和原理
Redis优秀的性能是由于其将所有的数据都存储在内存中,同样memcached也是这样做的,内存中的数据会在服务器重启后就没有了,也就是不能保证持久化.但是为什么Redis能够脱颖而出呢,很大程度上是 ...
- 【方案】mvc 保证定时器回收限制
在项目中我们或多或少的遇到一些需要定时触发或者计算的东西,这个时候我们就需要定时器来作为解决方案.非常好思路清晰,业务逻辑完好,定时器也开好了,当我们信心满满的挂到IIS服务器的时候,发现写的定时器在 ...
- 微信小程序开发入门:10分钟从0开始写一个hello-world
小程序开发需要三个描述整体程序的app文件 和 一个描述多个页面的 pages文件夹. (1)三个app文件分别是app.js,app.json,app.wxss. app.js文件是脚本文件处理一些 ...
- PAT1097:Deduplication on a Linked List
1097. Deduplication on a Linked List (25) 时间限制 300 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 ...
- Pat1071: Speech Patterns
1071. Speech Patterns (25) 时间限制 300 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 HOU, Qiming Peo ...
- PAT1011:World Cup Betting
1011. World Cup Betting (20) 时间限制 400 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Wit ...
- OpenStack架构详解
OpenStack提供开放源码软件,建立公共和私有云. OpenStack是一个社区和一个项目,以及开放源码软件,以帮助企业运行的虚拟计算或者存储云. OpenStackd开源项目由社区维护,包括Op ...