SpringMVC(九):SpringMVC 处理输出模型数据之ModelAndView
Spring MVC提供了以下几种途径输出模型数据:
1)ModelAndView:处理方法返回值类型为ModelAndView时,方法体即可通过该对象添加模型数据;
2)Map及Model:处理方法入参为org.springframework.ui.Model、org.springframework.ui.ModelMap或java.util.Map时,处理方法返回时,Map中的数据会自动被添加到模型中;
3)@SessionAttributes:将模型中的某个属性暂存到HttpSeession中,以便多个请求之间可以共享这个属性;
4)@ModelAttribute:方法入参标注该注解后,入参的对象就会放到数据模型中。
ModelAndView
用法示例:
添加TestModelAndView.java handler类:
package com.dx.springlearn.hanlders; import java.text.SimpleDateFormat;
import java.util.Date; import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.servlet.ModelAndView; @Controller
public class TestModelData {
private final String SUCCESS = "success"; @RequestMapping("/testModelAndView")
public ModelAndView testModelAndView() {
String viewName = SUCCESS;
ModelAndView modelAndView = new ModelAndView(viewName);
modelAndView.addObject("currentTime", new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date())); return modelAndView;
}
}
修改index.jsp,添加链接:
<a href="testModelAndView">test ModelAndView</a>
<br />
修改/WEB-INF/views/success.jsp,编辑添加内容:
current time:${requestScope.currentTime}
<br>
点击链接地址,显示结果:
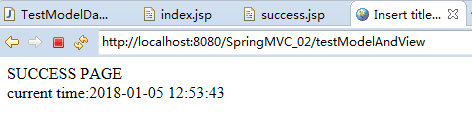
对TestModelAndView.java中“ modelAndView.addObject("currentTime", new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date()));”该行添加断点,进行调试:
根据调试信息,索引到DispatcherServlet的doDispatcher方法中:
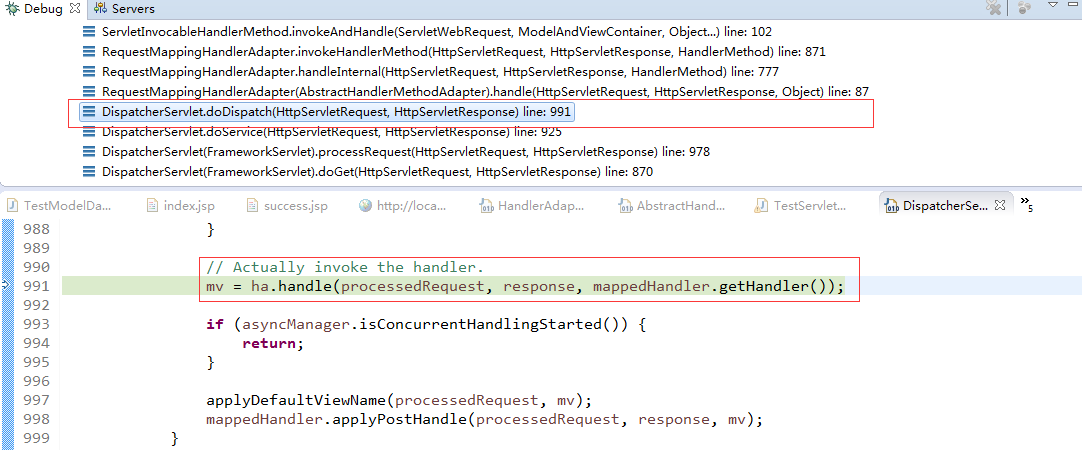
DispatcherServlet的doDispatcher方法源代码为:
/**
* Process the actual dispatching to the handler.
* <p>The handler will be obtained by applying the servlet's HandlerMappings in order.
* The HandlerAdapter will be obtained by querying the servlet's installed HandlerAdapters
* to find the first that supports the handler class.
* <p>All HTTP methods are handled by this method. It's up to HandlerAdapters or handlers
* themselves to decide which methods are acceptable.
* @param request current HTTP request
* @param response current HTTP response
* @throws Exception in case of any kind of processing failure
*/
protected void doDispatch(HttpServletRequest request, HttpServletResponse response) throws Exception {
HttpServletRequest processedRequest = request;
HandlerExecutionChain mappedHandler = null;
boolean multipartRequestParsed = false; WebAsyncManager asyncManager = WebAsyncUtils.getAsyncManager(request); try {
ModelAndView mv = null;
Exception dispatchException = null; try {
processedRequest = checkMultipart(request);
multipartRequestParsed = (processedRequest != request); // Determine handler for the current request.
mappedHandler = getHandler(processedRequest);
if (mappedHandler == null) {
noHandlerFound(processedRequest, response);
return;
} // Determine handler adapter for the current request.
HandlerAdapter ha = getHandlerAdapter(mappedHandler.getHandler()); // Process last-modified header, if supported by the handler.
String method = request.getMethod();
boolean isGet = "GET".equals(method);
if (isGet || "HEAD".equals(method)) {
long lastModified = ha.getLastModified(request, mappedHandler.getHandler());
if (logger.isDebugEnabled()) {
logger.debug("Last-Modified value for [" + getRequestUri(request) + "] is: " + lastModified);
}
if (new ServletWebRequest(request, response).checkNotModified(lastModified) && isGet) {
return;
}
} if (!mappedHandler.applyPreHandle(processedRequest, response)) {
return;
} // Actually invoke the handler.
mv = ha.handle(processedRequest, response, mappedHandler.getHandler()); if (asyncManager.isConcurrentHandlingStarted()) {
return;
} applyDefaultViewName(processedRequest, mv);
mappedHandler.applyPostHandle(processedRequest, response, mv);
}
catch (Exception ex) {
dispatchException = ex;
}
catch (Throwable err) {
// As of 4.3, we're processing Errors thrown from handler methods as well,
// making them available for @ExceptionHandler methods and other scenarios.
dispatchException = new NestedServletException("Handler dispatch failed", err);
}
processDispatchResult(processedRequest, response, mappedHandler, mv, dispatchException);
}
catch (Exception ex) {
triggerAfterCompletion(processedRequest, response, mappedHandler, ex);
}
catch (Throwable err) {
triggerAfterCompletion(processedRequest, response, mappedHandler,
new NestedServletException("Handler processing failed", err));
}
finally {
if (asyncManager.isConcurrentHandlingStarted()) {
// Instead of postHandle and afterCompletion
if (mappedHandler != null) {
mappedHandler.applyAfterConcurrentHandlingStarted(processedRequest, response);
}
}
else {
// Clean up any resources used by a multipart request.
if (multipartRequestParsed) {
cleanupMultipart(processedRequest);
}
}
}
}
结合第20行和第55行,我们可以得知:不管SpringMVC的handler类方法返回值是ModelAndView、String,也不管SpringMVC的handler类方法的入参是Map、Model、MapModel等,在SpringMVC内部都会把请求返回结果封装为一个ModelAndView。
ModelAndView实际上内部存储结构就是一个Map<String,Object>,具体请查看ModelAndView源代码
/*
* Copyright 2002-2017 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.springframework.web.servlet; import java.util.Map; import org.springframework.http.HttpStatus;
import org.springframework.lang.Nullable;
import org.springframework.ui.ModelMap;
import org.springframework.util.CollectionUtils; /**
* Holder for both Model and View in the web MVC framework.
* Note that these are entirely distinct. This class merely holds
* both to make it possible for a controller to return both model
* and view in a single return value.
*
* <p>Represents a model and view returned by a handler, to be resolved
* by a DispatcherServlet. The view can take the form of a String
* view name which will need to be resolved by a ViewResolver object;
* alternatively a View object can be specified directly. The model
* is a Map, allowing the use of multiple objects keyed by name.
*
* @author Rod Johnson
* @author Juergen Hoeller
* @author Rob Harrop
* @author Rossen Stoyanchev
* @see DispatcherServlet
* @see ViewResolver
* @see HandlerAdapter#handle
* @see org.springframework.web.servlet.mvc.Controller#handleRequest
*/
public class ModelAndView { /** View instance or view name String */
@Nullable
private Object view; /** Model Map */
@Nullable
private ModelMap model; /** Optional HTTP status for the response */
@Nullable
private HttpStatus status; /** Indicates whether or not this instance has been cleared with a call to {@link #clear()} */
private boolean cleared = false; /**
* Default constructor for bean-style usage: populating bean
* properties instead of passing in constructor arguments.
* @see #setView(View)
* @see #setViewName(String)
*/
public ModelAndView() {
} /**
* Convenient constructor when there is no model data to expose.
* Can also be used in conjunction with {@code addObject}.
* @param viewName name of the View to render, to be resolved
* by the DispatcherServlet's ViewResolver
* @see #addObject
*/
public ModelAndView(String viewName) {
this.view = viewName;
} /**
* Convenient constructor when there is no model data to expose.
* Can also be used in conjunction with {@code addObject}.
* @param view View object to render
* @see #addObject
*/
public ModelAndView(View view) {
this.view = view;
} /**
* Create a new ModelAndView given a view name and a model.
* @param viewName name of the View to render, to be resolved
* by the DispatcherServlet's ViewResolver
* @param model Map of model names (Strings) to model objects
* (Objects). Model entries may not be {@code null}, but the
* model Map may be {@code null} if there is no model data.
*/
public ModelAndView(String viewName, @Nullable Map<String, ?> model) {
this.view = viewName;
if (model != null) {
getModelMap().addAllAttributes(model);
}
} /**
* Create a new ModelAndView given a View object and a model.
* <emphasis>Note: the supplied model data is copied into the internal
* storage of this class. You should not consider to modify the supplied
* Map after supplying it to this class</emphasis>
* @param view View object to render
* @param model Map of model names (Strings) to model objects
* (Objects). Model entries may not be {@code null}, but the
* model Map may be {@code null} if there is no model data.
*/
public ModelAndView(View view, @Nullable Map<String, ?> model) {
this.view = view;
if (model != null) {
getModelMap().addAllAttributes(model);
}
} /**
* Create a new ModelAndView given a view name and HTTP status.
* @param viewName name of the View to render, to be resolved
* by the DispatcherServlet's ViewResolver
* @param status an HTTP status code to use for the response
* (to be set just prior to View rendering)
* @since 4.3.8
*/
public ModelAndView(String viewName, HttpStatus status) {
this.view = viewName;
this.status = status;
} /**
* Create a new ModelAndView given a view name, model, and HTTP status.
* @param viewName name of the View to render, to be resolved
* by the DispatcherServlet's ViewResolver
* @param model Map of model names (Strings) to model objects
* (Objects). Model entries may not be {@code null}, but the
* model Map may be {@code null} if there is no model data.
* @param status an HTTP status code to use for the response
* (to be set just prior to View rendering)
* @since 4.3
*/
public ModelAndView(@Nullable String viewName, @Nullable Map<String, ?> model, @Nullable HttpStatus status) {
this.view = viewName;
if (model != null) {
getModelMap().addAllAttributes(model);
}
this.status = status;
} /**
* Convenient constructor to take a single model object.
* @param viewName name of the View to render, to be resolved
* by the DispatcherServlet's ViewResolver
* @param modelName name of the single entry in the model
* @param modelObject the single model object
*/
public ModelAndView(String viewName, String modelName, Object modelObject) {
this.view = viewName;
addObject(modelName, modelObject);
} /**
* Convenient constructor to take a single model object.
* @param view View object to render
* @param modelName name of the single entry in the model
* @param modelObject the single model object
*/
public ModelAndView(View view, String modelName, Object modelObject) {
this.view = view;
addObject(modelName, modelObject);
} /**
* Set a view name for this ModelAndView, to be resolved by the
* DispatcherServlet via a ViewResolver. Will override any
* pre-existing view name or View.
*/
public void setViewName(@Nullable String viewName) {
this.view = viewName;
} /**
* Return the view name to be resolved by the DispatcherServlet
* via a ViewResolver, or {@code null} if we are using a View object.
*/
@Nullable
public String getViewName() {
return (this.view instanceof String ? (String) this.view : null);
} /**
* Set a View object for this ModelAndView. Will override any
* pre-existing view name or View.
*/
public void setView(@Nullable View view) {
this.view = view;
} /**
* Return the View object, or {@code null} if we are using a view name
* to be resolved by the DispatcherServlet via a ViewResolver.
*/
@Nullable
public View getView() {
return (this.view instanceof View ? (View) this.view : null);
} /**
* Indicate whether or not this {@code ModelAndView} has a view, either
* as a view name or as a direct {@link View} instance.
*/
public boolean hasView() {
return (this.view != null);
} /**
* Return whether we use a view reference, i.e. {@code true}
* if the view has been specified via a name to be resolved by the
* DispatcherServlet via a ViewResolver.
*/
public boolean isReference() {
return (this.view instanceof String);
} /**
* Return the model map. May return {@code null}.
* Called by DispatcherServlet for evaluation of the model.
*/
@Nullable
protected Map<String, Object> getModelInternal() {
return this.model;
} /**
* Return the underlying {@code ModelMap} instance (never {@code null}).
*/
public ModelMap getModelMap() {
if (this.model == null) {
this.model = new ModelMap();
}
return this.model;
} /**
* Return the model map. Never returns {@code null}.
* To be called by application code for modifying the model.
*/
public Map<String, Object> getModel() {
return getModelMap();
} /**
* Set the HTTP status to use for the response.
* <p>The response status is set just prior to View rendering.
* @since 4.3
*/
public void setStatus(@Nullable HttpStatus status) {
this.status = status;
} /**
* Return the configured HTTP status for the response, if any.
* @since 4.3
*/
@Nullable
public HttpStatus getStatus() {
return this.status;
} /**
* Add an attribute to the model.
* @param attributeName name of the object to add to the model
* @param attributeValue object to add to the model (never {@code null})
* @see ModelMap#addAttribute(String, Object)
* @see #getModelMap()
*/
public ModelAndView addObject(String attributeName, Object attributeValue) {
getModelMap().addAttribute(attributeName, attributeValue);
return this;
} /**
* Add an attribute to the model using parameter name generation.
* @param attributeValue the object to add to the model (never {@code null})
* @see ModelMap#addAttribute(Object)
* @see #getModelMap()
*/
public ModelAndView addObject(Object attributeValue) {
getModelMap().addAttribute(attributeValue);
return this;
} /**
* Add all attributes contained in the provided Map to the model.
* @param modelMap a Map of attributeName -> attributeValue pairs
* @see ModelMap#addAllAttributes(Map)
* @see #getModelMap()
*/
public ModelAndView addAllObjects(@Nullable Map<String, ?> modelMap) {
getModelMap().addAllAttributes(modelMap);
return this;
} /**
* Clear the state of this ModelAndView object.
* The object will be empty afterwards.
* <p>Can be used to suppress rendering of a given ModelAndView object
* in the {@code postHandle} method of a HandlerInterceptor.
* @see #isEmpty()
* @see HandlerInterceptor#postHandle
*/
public void clear() {
this.view = null;
this.model = null;
this.cleared = true;
} /**
* Return whether this ModelAndView object is empty,
* i.e. whether it does not hold any view and does not contain a model.
*/
public boolean isEmpty() {
return (this.view == null && CollectionUtils.isEmpty(this.model));
} /**
* Return whether this ModelAndView object is empty as a result of a call to {@link #clear}
* i.e. whether it does not hold any view and does not contain a model.
* <p>Returns {@code false} if any additional state was added to the instance
* <strong>after</strong> the call to {@link #clear}.
* @see #clear()
*/
public boolean wasCleared() {
return (this.cleared && isEmpty());
} /**
* Return diagnostic information about this model and view.
*/
@Override
public String toString() {
StringBuilder sb = new StringBuilder("ModelAndView: ");
if (isReference()) {
sb.append("reference to view with name '").append(this.view).append("'");
}
else {
sb.append("materialized View is [").append(this.view).append(']');
}
sb.append("; model is ").append(this.model);
return sb.toString();
} }
、ModelMap源代码
/*
* Copyright 2002-2017 the original author or authors.
*
* Licensed under the Apache License, Version 2.0 (the "License");
* you may not use this file except in compliance with the License.
* You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
* limitations under the License.
*/ package org.springframework.ui; import java.util.Collection;
import java.util.LinkedHashMap;
import java.util.Map; import org.springframework.core.Conventions;
import org.springframework.lang.Nullable;
import org.springframework.util.Assert; /**
* Implementation of {@link java.util.Map} for use when building model data for use
* with UI tools. Supports chained calls and generation of model attribute names.
*
* <p>This class serves as generic model holder for Servlet MVC but is not tied to it.
* Check out the {@link Model} interface for an interface variant.
*
* @author Rob Harrop
* @author Juergen Hoeller
* @since 2.0
* @see Conventions#getVariableName
* @see org.springframework.web.servlet.ModelAndView
*/
@SuppressWarnings("serial")
public class ModelMap extends LinkedHashMap<String, Object> { /**
* Construct a new, empty {@code ModelMap}.
*/
public ModelMap() {
} /**
* Construct a new {@code ModelMap} containing the supplied attribute
* under the supplied name.
* @see #addAttribute(String, Object)
*/
public ModelMap(String attributeName, Object attributeValue) {
addAttribute(attributeName, attributeValue);
} /**
* Construct a new {@code ModelMap} containing the supplied attribute.
* Uses attribute name generation to generate the key for the supplied model
* object.
* @see #addAttribute(Object)
*/
public ModelMap(Object attributeValue) {
addAttribute(attributeValue);
} /**
* Add the supplied attribute under the supplied name.
* @param attributeName the name of the model attribute (never {@code null})
* @param attributeValue the model attribute value (can be {@code null})
*/
public ModelMap addAttribute(String attributeName, @Nullable Object attributeValue) {
Assert.notNull(attributeName, "Model attribute name must not be null");
put(attributeName, attributeValue);
return this;
} /**
* Add the supplied attribute to this {@code Map} using a
* {@link org.springframework.core.Conventions#getVariableName generated name}.
* <p><emphasis>Note: Empty {@link Collection Collections} are not added to
* the model when using this method because we cannot correctly determine
* the true convention name. View code should check for {@code null} rather
* than for empty collections as is already done by JSTL tags.</emphasis>
* @param attributeValue the model attribute value (never {@code null})
*/
public ModelMap addAttribute(Object attributeValue) {
Assert.notNull(attributeValue, "Model object must not be null");
if (attributeValue instanceof Collection && ((Collection<?>) attributeValue).isEmpty()) {
return this;
}
return addAttribute(Conventions.getVariableName(attributeValue), attributeValue);
} /**
* Copy all attributes in the supplied {@code Collection} into this
* {@code Map}, using attribute name generation for each element.
* @see #addAttribute(Object)
*/
public ModelMap addAllAttributes(@Nullable Collection<?> attributeValues) {
if (attributeValues != null) {
for (Object attributeValue : attributeValues) {
addAttribute(attributeValue);
}
}
return this;
} /**
* Copy all attributes in the supplied {@code Map} into this {@code Map}.
* @see #addAttribute(String, Object)
*/
public ModelMap addAllAttributes(@Nullable Map<String, ?> attributes) {
if (attributes != null) {
putAll(attributes);
}
return this;
} /**
* Copy all attributes in the supplied {@code Map} into this {@code Map},
* with existing objects of the same name taking precedence (i.e. not getting
* replaced).
*/
public ModelMap mergeAttributes(@Nullable Map<String, ?> attributes) {
if (attributes != null) {
attributes.forEach((key, value) -> {
if (!containsKey(key)) {
put(key, value);
}
});
}
return this;
} /**
* Does this model contain an attribute of the given name?
* @param attributeName the name of the model attribute (never {@code null})
* @return whether this model contains a corresponding attribute
*/
public boolean containsAttribute(String attributeName) {
return containsKey(attributeName);
} }
、LinkedHashMap源代码
/*
* Copyright (c) 1997, 2013, Oracle and/or its affiliates. All rights reserved.
* ORACLE PROPRIETARY/CONFIDENTIAL. Use is subject to license terms.
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*
*/ package java.util; import java.util.function.Consumer;
import java.util.function.BiConsumer;
import java.util.function.BiFunction;
import java.io.IOException; /**
* <p>Hash table and linked list implementation of the <tt>Map</tt> interface,
* with predictable iteration order. This implementation differs from
* <tt>HashMap</tt> in that it maintains a doubly-linked list running through
* all of its entries. This linked list defines the iteration ordering,
* which is normally the order in which keys were inserted into the map
* (<i>insertion-order</i>). Note that insertion order is not affected
* if a key is <i>re-inserted</i> into the map. (A key <tt>k</tt> is
* reinserted into a map <tt>m</tt> if <tt>m.put(k, v)</tt> is invoked when
* <tt>m.containsKey(k)</tt> would return <tt>true</tt> immediately prior to
* the invocation.)
*
* <p>This implementation spares its clients from the unspecified, generally
* chaotic ordering provided by {@link HashMap} (and {@link Hashtable}),
* without incurring the increased cost associated with {@link TreeMap}. It
* can be used to produce a copy of a map that has the same order as the
* original, regardless of the original map's implementation:
* <pre>
* void foo(Map m) {
* Map copy = new LinkedHashMap(m);
* ...
* }
* </pre>
* This technique is particularly useful if a module takes a map on input,
* copies it, and later returns results whose order is determined by that of
* the copy. (Clients generally appreciate having things returned in the same
* order they were presented.)
*
* <p>A special {@link #LinkedHashMap(int,float,boolean) constructor} is
* provided to create a linked hash map whose order of iteration is the order
* in which its entries were last accessed, from least-recently accessed to
* most-recently (<i>access-order</i>). This kind of map is well-suited to
* building LRU caches. Invoking the {@code put}, {@code putIfAbsent},
* {@code get}, {@code getOrDefault}, {@code compute}, {@code computeIfAbsent},
* {@code computeIfPresent}, or {@code merge} methods results
* in an access to the corresponding entry (assuming it exists after the
* invocation completes). The {@code replace} methods only result in an access
* of the entry if the value is replaced. The {@code putAll} method generates one
* entry access for each mapping in the specified map, in the order that
* key-value mappings are provided by the specified map's entry set iterator.
* <i>No other methods generate entry accesses.</i> In particular, operations
* on collection-views do <i>not</i> affect the order of iteration of the
* backing map.
*
* <p>The {@link #removeEldestEntry(Map.Entry)} method may be overridden to
* impose a policy for removing stale mappings automatically when new mappings
* are added to the map.
*
* <p>This class provides all of the optional <tt>Map</tt> operations, and
* permits null elements. Like <tt>HashMap</tt>, it provides constant-time
* performance for the basic operations (<tt>add</tt>, <tt>contains</tt> and
* <tt>remove</tt>), assuming the hash function disperses elements
* properly among the buckets. Performance is likely to be just slightly
* below that of <tt>HashMap</tt>, due to the added expense of maintaining the
* linked list, with one exception: Iteration over the collection-views
* of a <tt>LinkedHashMap</tt> requires time proportional to the <i>size</i>
* of the map, regardless of its capacity. Iteration over a <tt>HashMap</tt>
* is likely to be more expensive, requiring time proportional to its
* <i>capacity</i>.
*
* <p>A linked hash map has two parameters that affect its performance:
* <i>initial capacity</i> and <i>load factor</i>. They are defined precisely
* as for <tt>HashMap</tt>. Note, however, that the penalty for choosing an
* excessively high value for initial capacity is less severe for this class
* than for <tt>HashMap</tt>, as iteration times for this class are unaffected
* by capacity.
*
* <p><strong>Note that this implementation is not synchronized.</strong>
* If multiple threads access a linked hash map concurrently, and at least
* one of the threads modifies the map structurally, it <em>must</em> be
* synchronized externally. This is typically accomplished by
* synchronizing on some object that naturally encapsulates the map.
*
* If no such object exists, the map should be "wrapped" using the
* {@link Collections#synchronizedMap Collections.synchronizedMap}
* method. This is best done at creation time, to prevent accidental
* unsynchronized access to the map:<pre>
* Map m = Collections.synchronizedMap(new LinkedHashMap(...));</pre>
*
* A structural modification is any operation that adds or deletes one or more
* mappings or, in the case of access-ordered linked hash maps, affects
* iteration order. In insertion-ordered linked hash maps, merely changing
* the value associated with a key that is already contained in the map is not
* a structural modification. <strong>In access-ordered linked hash maps,
* merely querying the map with <tt>get</tt> is a structural modification.
* </strong>)
*
* <p>The iterators returned by the <tt>iterator</tt> method of the collections
* returned by all of this class's collection view methods are
* <em>fail-fast</em>: if the map is structurally modified at any time after
* the iterator is created, in any way except through the iterator's own
* <tt>remove</tt> method, the iterator will throw a {@link
* ConcurrentModificationException}. Thus, in the face of concurrent
* modification, the iterator fails quickly and cleanly, rather than risking
* arbitrary, non-deterministic behavior at an undetermined time in the future.
*
* <p>Note that the fail-fast behavior of an iterator cannot be guaranteed
* as it is, generally speaking, impossible to make any hard guarantees in the
* presence of unsynchronized concurrent modification. Fail-fast iterators
* throw <tt>ConcurrentModificationException</tt> on a best-effort basis.
* Therefore, it would be wrong to write a program that depended on this
* exception for its correctness: <i>the fail-fast behavior of iterators
* should be used only to detect bugs.</i>
*
* <p>The spliterators returned by the spliterator method of the collections
* returned by all of this class's collection view methods are
* <em><a href="Spliterator.html#binding">late-binding</a></em>,
* <em>fail-fast</em>, and additionally report {@link Spliterator#ORDERED}.
*
* <p>This class is a member of the
* <a href="{@docRoot}/../technotes/guides/collections/index.html">
* Java Collections Framework</a>.
*
* @implNote
* The spliterators returned by the spliterator method of the collections
* returned by all of this class's collection view methods are created from
* the iterators of the corresponding collections.
*
* @param <K> the type of keys maintained by this map
* @param <V> the type of mapped values
*
* @author Josh Bloch
* @see Object#hashCode()
* @see Collection
* @see Map
* @see HashMap
* @see TreeMap
* @see Hashtable
* @since 1.4
*/
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{ /*
* Implementation note. A previous version of this class was
* internally structured a little differently. Because superclass
* HashMap now uses trees for some of its nodes, class
* LinkedHashMap.Entry is now treated as intermediary node class
* that can also be converted to tree form. The name of this
* class, LinkedHashMap.Entry, is confusing in several ways in its
* current context, but cannot be changed. Otherwise, even though
* it is not exported outside this package, some existing source
* code is known to have relied on a symbol resolution corner case
* rule in calls to removeEldestEntry that suppressed compilation
* errors due to ambiguous usages. So, we keep the name to
* preserve unmodified compilability.
*
* The changes in node classes also require using two fields
* (head, tail) rather than a pointer to a header node to maintain
* the doubly-linked before/after list. This class also
* previously used a different style of callback methods upon
* access, insertion, and removal.
*/ /**
* HashMap.Node subclass for normal LinkedHashMap entries.
*/
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
} private static final long serialVersionUID = 3801124242820219131L; /**
* The head (eldest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> head; /**
* The tail (youngest) of the doubly linked list.
*/
transient LinkedHashMap.Entry<K,V> tail; /**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
*
* @serial
*/
final boolean accessOrder; // internal utilities // link at the end of list
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
} // apply src's links to dst
private void transferLinks(LinkedHashMap.Entry<K,V> src,
LinkedHashMap.Entry<K,V> dst) {
LinkedHashMap.Entry<K,V> b = dst.before = src.before;
LinkedHashMap.Entry<K,V> a = dst.after = src.after;
if (b == null)
head = dst;
else
b.after = dst;
if (a == null)
tail = dst;
else
a.before = dst;
} // overrides of HashMap hook methods void reinitialize() {
super.reinitialize();
head = tail = null;
} Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
} Node<K,V> replacementNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
LinkedHashMap.Entry<K,V> t =
new LinkedHashMap.Entry<K,V>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
} TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
} TreeNode<K,V> replacementTreeNode(Node<K,V> p, Node<K,V> next) {
LinkedHashMap.Entry<K,V> q = (LinkedHashMap.Entry<K,V>)p;
TreeNode<K,V> t = new TreeNode<K,V>(q.hash, q.key, q.value, next);
transferLinks(q, t);
return t;
} void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
} void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
} void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
} void internalWriteEntries(java.io.ObjectOutputStream s) throws IOException {
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
s.writeObject(e.key);
s.writeObject(e.value);
}
} /**
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the specified initial capacity and load factor.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
} /**
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the specified initial capacity and a default load factor (0.75).
*
* @param initialCapacity the initial capacity
* @throws IllegalArgumentException if the initial capacity is negative
*/
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
} /**
* Constructs an empty insertion-ordered <tt>LinkedHashMap</tt> instance
* with the default initial capacity (16) and load factor (0.75).
*/
public LinkedHashMap() {
super();
accessOrder = false;
} /**
* Constructs an insertion-ordered <tt>LinkedHashMap</tt> instance with
* the same mappings as the specified map. The <tt>LinkedHashMap</tt>
* instance is created with a default load factor (0.75) and an initial
* capacity sufficient to hold the mappings in the specified map.
*
* @param m the map whose mappings are to be placed in this map
* @throws NullPointerException if the specified map is null
*/
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super();
accessOrder = false;
putMapEntries(m, false);
} /**
* Constructs an empty <tt>LinkedHashMap</tt> instance with the
* specified initial capacity, load factor and ordering mode.
*
* @param initialCapacity the initial capacity
* @param loadFactor the load factor
* @param accessOrder the ordering mode - <tt>true</tt> for
* access-order, <tt>false</tt> for insertion-order
* @throws IllegalArgumentException if the initial capacity is negative
* or the load factor is nonpositive
*/
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
} /**
* Returns <tt>true</tt> if this map maps one or more keys to the
* specified value.
*
* @param value value whose presence in this map is to be tested
* @return <tt>true</tt> if this map maps one or more keys to the
* specified value
*/
public boolean containsValue(Object value) {
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
} /**
* Returns the value to which the specified key is mapped,
* or {@code null} if this map contains no mapping for the key.
*
* <p>More formally, if this map contains a mapping from a key
* {@code k} to a value {@code v} such that {@code (key==null ? k==null :
* key.equals(k))}, then this method returns {@code v}; otherwise
* it returns {@code null}. (There can be at most one such mapping.)
*
* <p>A return value of {@code null} does not <i>necessarily</i>
* indicate that the map contains no mapping for the key; it's also
* possible that the map explicitly maps the key to {@code null}.
* The {@link #containsKey containsKey} operation may be used to
* distinguish these two cases.
*/
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
} /**
* {@inheritDoc}
*/
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
} /**
* {@inheritDoc}
*/
public void clear() {
super.clear();
head = tail = null;
} /**
* Returns <tt>true</tt> if this map should remove its eldest entry.
* This method is invoked by <tt>put</tt> and <tt>putAll</tt> after
* inserting a new entry into the map. It provides the implementor
* with the opportunity to remove the eldest entry each time a new one
* is added. This is useful if the map represents a cache: it allows
* the map to reduce memory consumption by deleting stale entries.
*
* <p>Sample use: this override will allow the map to grow up to 100
* entries and then delete the eldest entry each time a new entry is
* added, maintaining a steady state of 100 entries.
* <pre>
* private static final int MAX_ENTRIES = 100;
*
* protected boolean removeEldestEntry(Map.Entry eldest) {
* return size() > MAX_ENTRIES;
* }
* </pre>
*
* <p>This method typically does not modify the map in any way,
* instead allowing the map to modify itself as directed by its
* return value. It <i>is</i> permitted for this method to modify
* the map directly, but if it does so, it <i>must</i> return
* <tt>false</tt> (indicating that the map should not attempt any
* further modification). The effects of returning <tt>true</tt>
* after modifying the map from within this method are unspecified.
*
* <p>This implementation merely returns <tt>false</tt> (so that this
* map acts like a normal map - the eldest element is never removed).
*
* @param eldest The least recently inserted entry in the map, or if
* this is an access-ordered map, the least recently accessed
* entry. This is the entry that will be removed it this
* method returns <tt>true</tt>. If the map was empty prior
* to the <tt>put</tt> or <tt>putAll</tt> invocation resulting
* in this invocation, this will be the entry that was just
* inserted; in other words, if the map contains a single
* entry, the eldest entry is also the newest.
* @return <tt>true</tt> if the eldest entry should be removed
* from the map; <tt>false</tt> if it should be retained.
*/
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
} /**
* Returns a {@link Set} view of the keys contained in this map.
* The set is backed by the map, so changes to the map are
* reflected in the set, and vice-versa. If the map is modified
* while an iteration over the set is in progress (except through
* the iterator's own <tt>remove</tt> operation), the results of
* the iteration are undefined. The set supports element removal,
* which removes the corresponding mapping from the map, via the
* <tt>Iterator.remove</tt>, <tt>Set.remove</tt>,
* <tt>removeAll</tt>, <tt>retainAll</tt>, and <tt>clear</tt>
* operations. It does not support the <tt>add</tt> or <tt>addAll</tt>
* operations.
* Its {@link Spliterator} typically provides faster sequential
* performance but much poorer parallel performance than that of
* {@code HashMap}.
*
* @return a set view of the keys contained in this map
*/
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new LinkedKeySet();
keySet = ks;
}
return ks;
} final class LinkedKeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<K> iterator() {
return new LinkedKeyIterator();
}
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
public final void forEach(Consumer<? super K> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.key);
if (modCount != mc)
throw new ConcurrentModificationException();
}
} /**
* Returns a {@link Collection} view of the values contained in this map.
* The collection is backed by the map, so changes to the map are
* reflected in the collection, and vice-versa. If the map is
* modified while an iteration over the collection is in progress
* (except through the iterator's own <tt>remove</tt> operation),
* the results of the iteration are undefined. The collection
* supports element removal, which removes the corresponding
* mapping from the map, via the <tt>Iterator.remove</tt>,
* <tt>Collection.remove</tt>, <tt>removeAll</tt>,
* <tt>retainAll</tt> and <tt>clear</tt> operations. It does not
* support the <tt>add</tt> or <tt>addAll</tt> operations.
* Its {@link Spliterator} typically provides faster sequential
* performance but much poorer parallel performance than that of
* {@code HashMap}.
*
* @return a view of the values contained in this map
*/
public Collection<V> values() {
Collection<V> vs = values;
if (vs == null) {
vs = new LinkedValues();
values = vs;
}
return vs;
} final class LinkedValues extends AbstractCollection<V> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<V> iterator() {
return new LinkedValueIterator();
}
public final boolean contains(Object o) { return containsValue(o); }
public final Spliterator<V> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED);
}
public final void forEach(Consumer<? super V> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
}
} /**
* Returns a {@link Set} view of the mappings contained in this map.
* The set is backed by the map, so changes to the map are
* reflected in the set, and vice-versa. If the map is modified
* while an iteration over the set is in progress (except through
* the iterator's own <tt>remove</tt> operation, or through the
* <tt>setValue</tt> operation on a map entry returned by the
* iterator) the results of the iteration are undefined. The set
* supports element removal, which removes the corresponding
* mapping from the map, via the <tt>Iterator.remove</tt>,
* <tt>Set.remove</tt>, <tt>removeAll</tt>, <tt>retainAll</tt> and
* <tt>clear</tt> operations. It does not support the
* <tt>add</tt> or <tt>addAll</tt> operations.
* Its {@link Spliterator} typically provides faster sequential
* performance but much poorer parallel performance than that of
* {@code HashMap}.
*
* @return a set view of the mappings contained in this map
*/
public Set<Map.Entry<K,V>> entrySet() {
Set<Map.Entry<K,V>> es;
return (es = entrySet) == null ? (entrySet = new LinkedEntrySet()) : es;
} final class LinkedEntrySet extends AbstractSet<Map.Entry<K,V>> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<Map.Entry<K,V>> iterator() {
return new LinkedEntryIterator();
}
public final boolean contains(Object o) {
if (!(o instanceof Map.Entry))
return false;
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Node<K,V> candidate = getNode(hash(key), key);
return candidate != null && candidate.equals(e);
}
public final boolean remove(Object o) {
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>) o;
Object key = e.getKey();
Object value = e.getValue();
return removeNode(hash(key), key, value, true, true) != null;
}
return false;
}
public final Spliterator<Map.Entry<K,V>> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
public final void forEach(Consumer<? super Map.Entry<K,V>> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e);
if (modCount != mc)
throw new ConcurrentModificationException();
}
} // Map overrides public void forEach(BiConsumer<? super K, ? super V> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.key, e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
} public void replaceAll(BiFunction<? super K, ? super V, ? extends V> function) {
if (function == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
e.value = function.apply(e.key, e.value);
if (modCount != mc)
throw new ConcurrentModificationException();
} // Iterators abstract class LinkedHashIterator {
LinkedHashMap.Entry<K,V> next;
LinkedHashMap.Entry<K,V> current;
int expectedModCount; LinkedHashIterator() {
next = head;
expectedModCount = modCount;
current = null;
} public final boolean hasNext() {
return next != null;
} final LinkedHashMap.Entry<K,V> nextNode() {
LinkedHashMap.Entry<K,V> e = next;
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
if (e == null)
throw new NoSuchElementException();
current = e;
next = e.after;
return e;
} public final void remove() {
Node<K,V> p = current;
if (p == null)
throw new IllegalStateException();
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
current = null;
K key = p.key;
removeNode(hash(key), key, null, false, false);
expectedModCount = modCount;
}
} final class LinkedKeyIterator extends LinkedHashIterator
implements Iterator<K> {
public final K next() { return nextNode().getKey(); }
} final class LinkedValueIterator extends LinkedHashIterator
implements Iterator<V> {
public final V next() { return nextNode().value; }
} final class LinkedEntryIterator extends LinkedHashIterator
implements Iterator<Map.Entry<K,V>> {
public final Map.Entry<K,V> next() { return nextNode(); }
} }
继续调试,找到DispatcherServlet的doDispatcher第72行并进入processDispatchResult方法:
/**
* Handle the result of handler selection and handler invocation, which is
* either a ModelAndView or an Exception to be resolved to a ModelAndView.
*/
private void processDispatchResult(HttpServletRequest request, HttpServletResponse response,
@Nullable HandlerExecutionChain mappedHandler, @Nullable ModelAndView mv,
@Nullable Exception exception) throws Exception { boolean errorView = false; if (exception != null) {
if (exception instanceof ModelAndViewDefiningException) {
logger.debug("ModelAndViewDefiningException encountered", exception);
mv = ((ModelAndViewDefiningException) exception).getModelAndView();
}
else {
Object handler = (mappedHandler != null ? mappedHandler.getHandler() : null);
mv = processHandlerException(request, response, handler, exception);
errorView = (mv != null);
}
} // Did the handler return a view to render?
if (mv != null && !mv.wasCleared()) {
render(mv, request, response);
if (errorView) {
WebUtils.clearErrorRequestAttributes(request);
}
}
else {
if (logger.isDebugEnabled()) {
logger.debug("Null ModelAndView returned to DispatcherServlet with name '" + getServletName() +
"': assuming HandlerAdapter completed request handling");
}
} if (WebAsyncUtils.getAsyncManager(request).isConcurrentHandlingStarted()) {
// Concurrent handling started during a forward
return;
} if (mappedHandler != null) {
mappedHandler.triggerAfterCompletion(request, response, null);
}
}
继续调试,找到DispatcherServlet的processDispatchResult第25行并进入render方法:
/**
* Render the given ModelAndView.
* <p>This is the last stage in handling a request. It may involve resolving the view by name.
* @param mv the ModelAndView to render
* @param request current HTTP servlet request
* @param response current HTTP servlet response
* @throws ServletException if view is missing or cannot be resolved
* @throws Exception if there's a problem rendering the view
*/
protected void render(ModelAndView mv, HttpServletRequest request, HttpServletResponse response) throws Exception {
// Determine locale for request and apply it to the response.
Locale locale =
(this.localeResolver != null ? this.localeResolver.resolveLocale(request) : request.getLocale());
response.setLocale(locale); View view;
String viewName = mv.getViewName();
if (viewName != null) {
// We need to resolve the view name.
view = resolveViewName(viewName, mv.getModelInternal(), locale, request);
if (view == null) {
throw new ServletException("Could not resolve view with name '" + mv.getViewName() +
"' in servlet with name '" + getServletName() + "'");
}
}
else {
// No need to lookup: the ModelAndView object contains the actual View object.
view = mv.getView();
if (view == null) {
throw new ServletException("ModelAndView [" + mv + "] neither contains a view name nor a " +
"View object in servlet with name '" + getServletName() + "'");
}
} // Delegate to the View object for rendering.
if (logger.isDebugEnabled()) {
logger.debug("Rendering view [" + view + "] in DispatcherServlet with name '" + getServletName() + "'");
}
try {
if (mv.getStatus() != null) {
response.setStatus(mv.getStatus().value());
}
view.render(mv.getModelInternal(), request, response);
}
catch (Exception ex) {
if (logger.isDebugEnabled()) {
logger.debug("Error rendering view [" + view + "] in DispatcherServlet with name '" +
getServletName() + "'", ex);
}
throw ex;
}
}
继续调试,找到是View接口类的render接口方法,CTRL+T查找引用类结构:
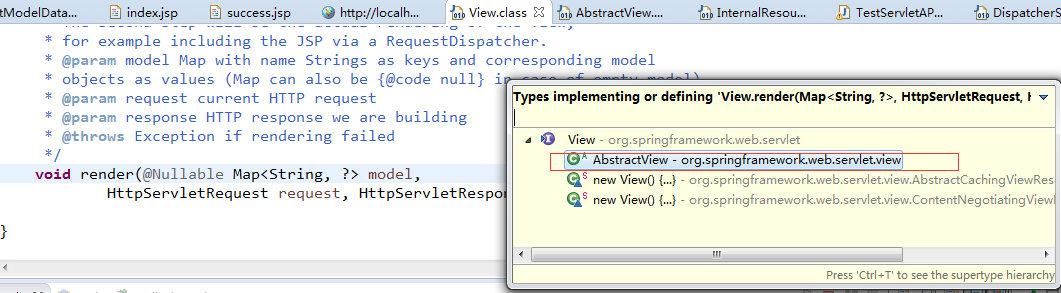
进入AbstractView抽象类,找到render方法:
/**
* Prepares the view given the specified model, merging it with static
* attributes and a RequestContext attribute, if necessary.
* Delegates to renderMergedOutputModel for the actual rendering.
* @see #renderMergedOutputModel
*/
@Override
public void render(@Nullable Map<String, ?> model, HttpServletRequest request,
HttpServletResponse response) throws Exception { if (logger.isTraceEnabled()) {
logger.trace("Rendering view with name '" + this.beanName + "' with model " + model +
" and static attributes " + this.staticAttributes);
} Map<String, Object> mergedModel = createMergedOutputModel(model, request, response);
prepareResponse(request, response);
renderMergedOutputModel(mergedModel, getRequestToExpose(request), response);
}
找到第18行方法renderMergedOutputModel方法,并进入该方法:
protected abstract void renderMergedOutputModel(
Map<String, Object> model, HttpServletRequest request, HttpServletResponse response) throws Exception;
此方法是AbstractView的一个抽象方法,CTRL+T:
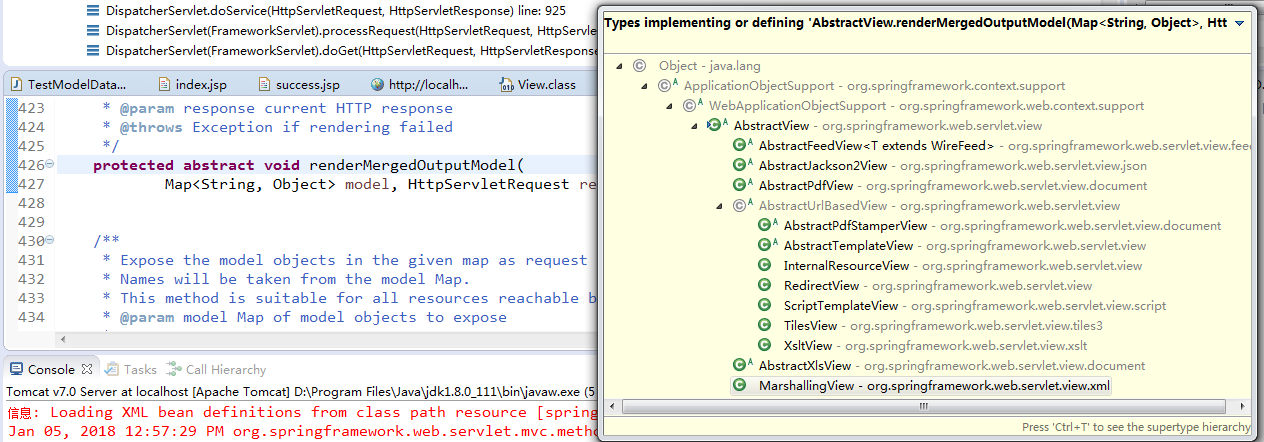
从上图中我们可以发现renderMergedOutputModel的实现类中包含了InternalResourceView,而我们的web.xml配置的springDispatcherServlet指定的类就是该类,因此直接查看InternalResourceView类即可。
进入InternalResourceView类renderMergedOutputModel方法:
@Override
protected void renderMergedOutputModel(
Map<String, Object> model, HttpServletRequest request, HttpServletResponse response) throws Exception { // Expose the model object as request attributes.
exposeModelAsRequestAttributes(model, request); // Expose helpers as request attributes, if any.
exposeHelpers(request); // Determine the path for the request dispatcher.
String dispatcherPath = prepareForRendering(request, response); // Obtain a RequestDispatcher for the target resource (typically a JSP).
RequestDispatcher rd = getRequestDispatcher(request, dispatcherPath);
if (rd == null) {
throw new ServletException("Could not get RequestDispatcher for [" + getUrl() +
"]: Check that the corresponding file exists within your web application archive!");
} // If already included or response already committed, perform include, else forward.
if (useInclude(request, response)) {
response.setContentType(getContentType());
if (logger.isDebugEnabled()) {
logger.debug("Including resource [" + getUrl() + "] in InternalResourceView '" + getBeanName() + "'");
}
rd.include(request, response);
} else {
// Note: The forwarded resource is supposed to determine the content type itself.
if (logger.isDebugEnabled()) {
logger.debug("Forwarding to resource [" + getUrl() + "] in InternalResourceView '" + getBeanName() + "'");
}
rd.forward(request, response);
}
}
找到第6行exposeModelAsRequestAttributes(model, request);方法并进入,此时进入方法归属类为AbstractView:
/**
* Expose the model objects in the given map as request attributes.
* Names will be taken from the model Map.
* This method is suitable for all resources reachable by {@link javax.servlet.RequestDispatcher}.
* @param model Map of model objects to expose
* @param request current HTTP request
*/
protected void exposeModelAsRequestAttributes(Map<String, Object> model,
HttpServletRequest request) throws Exception { model.forEach((modelName, modelValue) -> {
if (modelValue != null) {
request.setAttribute(modelName, modelValue);
if (logger.isDebugEnabled()) {
logger.debug("Added model object '" + modelName + "' of type [" + modelValue.getClass().getName() +
"] to request in view with name '" + getBeanName() + "'");
}
}
else {
request.removeAttribute(modelName);
if (logger.isDebugEnabled()) {
logger.debug("Removed model object '" + modelName +
"' from request in view with name '" + getBeanName() + "'");
}
}
});
}
从该方法中我们可以总结出一个结论:
不管SpringMVC的handler类方法返回值是ModelAndView、String,也不管SpringMVC的handler类方法的入参是Map、Model、MapModel等,这些参数信息都会被存放到SpringMVC的request请求域中,这也是为什么success.jsp中显示currentTime时,采用${requestScope.currentTime}的原因。
SpringMVC(九):SpringMVC 处理输出模型数据之ModelAndView的更多相关文章
- SpringMVC 学习笔记(四) 处理模型数据
Spring MVC 提供了下面几种途径输出模型数据: – ModelAndView: 处理方法返回值类型为 ModelAndView时, 方法体就可以通过该对象加入模型数据 – Map及Model: ...
- SpringMVC(十二):SpringMVC 处理输出模型数据之@ModelAttribute
Spring MVC提供了以下几种途径输出模型数据:1)ModelAndView:处理方法返回值类型为ModelAndView时,方法体即可通过该对象添加模型数据:2)Map及Model:处理方法入参 ...
- SpringMVC(十一):SpringMVC 处理输出模型数据之SessionAttributes
Spring MVC提供了以下几种途径输出模型数据:1)ModelAndView:处理方法返回值类型为ModelAndView时,方法体即可通过该对象添加模型数据:2)Map及Model:处理方法入参 ...
- SpringMVC(十):SpringMVC 处理输出模型数据之Map及Model
Spring MVC提供了以下几种途径输出模型数据: 1)ModelAndView:处理方法返回值类型为ModelAndView时,方法体即可通过该对象添加模型数据: 2)Map及Model:处理方法 ...
- SpringMVC:学习笔记(4)——处理模型数据
SpringMVC—处理模型数据 说明 SpringMVC 提供了以下几种途径输出模型数据: – ModelAndView: 处理方法返回值类型为 ModelAndView时, 方法体即可通过该对象添 ...
- SpringMVC(十五) RequestMapping map模型数据
控制器中使用map模型数据,传送数据给视图. 控制器参考代码: package com.tiekui.springmvc.handlers; import java.util.Arrays; impo ...
- 010 处理模型数据(ModelAndView,Map Model,@SessionAttributes)
1.处理数据模型 SpringMVC提供了几种途径出书模型数据 二:ModelAndView 1.介绍 2.index <%@ page language="java" co ...
- SpringMvc:处理模型数据
SpringMvc提供了以下途径输出模型数据: -ModelAndView:处理方法返回值类型为ModelAndView,方法体即可通过该对象添加模型数据 -Map或Model:入参为org.spri ...
- springmvc学习(五)——处理模型数据
Spring MVC 提供了以下几种途径输出模型数据: ModelAndView: 处理方法返回值类型为 ModelAndView 时, 方法体即可通过该对象添加模型数据Map 及 Model: 入参 ...
随机推荐
- 17.C++-string字符串类(详解)
C++字符串string类 在C语言里,字符串是用字符数组来表示的,而对于应用层而言,会经常用到字符串,而继续使用字符数组,就使得效率非常低. 所以在C++标准库里,通过类string从新自定义了字符 ...
- Dubbo源码-从HelloWorld开始
Dubbo简介 Dubbo,相信做后端的同学应该都用过,或者有所耳闻.没错,我就是那个有所耳闻中的一员. 公司在好几年前实现了一套自己的RPC框架,所以也就没有机会使用市面上琳琅满目的RPC框架产品. ...
- Java注解学习笔记
我们平常写Java代码,对其中的注解并不是很陌生,比如说写继承关系的时候经常用到@Override来修饰方法.但是@Override是用来做什么的,为什么写继承方法的时候要加上它,不加行不行.如果对J ...
- MYSQL数据库学习十六 安全性机制
16.1 MYSQL数据库所提供的权限 16.1.1 系统表 mysql.user 1. 用户字段 Host:主机名: User:用户名: Password:密码. 2. 权限字段 以“_priv”字 ...
- nxlog4go 的配置驱动
刚开始接触log4go项目时,没有注意到配置的重要性. 阅读了log4j.log4net.log4cpp.log4cplus的部分代码,发现它们都是以xml配置来驱动日志系统运行的. 多个源文件共享一 ...
- 将 Shiro 作为应用的权限基础 三:基于注解实现的授权认证过程
授权即访问控制,它将判断用户在应用程序中对资源是否拥有相应的访问权限. 如,判断一个用户有查看页面的权限,编辑数据的权限,拥有某一按钮的权限等等. 一.用户权限模型 为实现一个较为灵活的用户权限数据模 ...
- java基础笔记(2)----流程控制
java流程控制结构包括顺序结构,分支结构,循环结构. 顺序结构: 程序从上到下依次执行,中间没有任何判断和跳转. 代码如下: package com.lvsling.test; public cla ...
- 用SpringBoot搭建简单电商项目 01
前几节呢,我们已经简单介绍了SpringBoot框架的使用,从这一节开始,我们尝试着使用SpringBoot框架来一步一步搭建一个简单电商项目.当然了,这不是真正的电商项目,你可以看成是一个CRUD案 ...
- css3控制div上下跳动-效果图
效果图演示,源代码
- C语言——第一次作业(2)
1.写程序证明p++等价于(p)++还是等价于*(p++)? #include <stdio.h> int main() { int *p,a=5; p = &a; printf( ...