推荐系统——online(上)
框架介绍
上一篇从总体上介绍了推荐系统,推荐系统online和offline是两个组成部分,其中offline负责数据的收集,存储,统计,模型的训练等工作;online部分负责处理用户的请求,模型数据的使用,online learning等。本篇因为online中有比较复杂的ranking,ranking又分为离线训练和online learning,本篇主要介绍online部分的reall,ranking部分下篇介绍。先从整体流程图开始绍,数据流分为两部分:
- 用户请求数据,一般是由用户下拉刷新或APP发送的默认请求,通过连接网关,请求发送到推进引擎;
- 用户产生[隐式反馈或显示反馈]1,这部分数据是由APP从后台收集,通过网关进入flume,然后进入kafka为后面模块使用做准备。
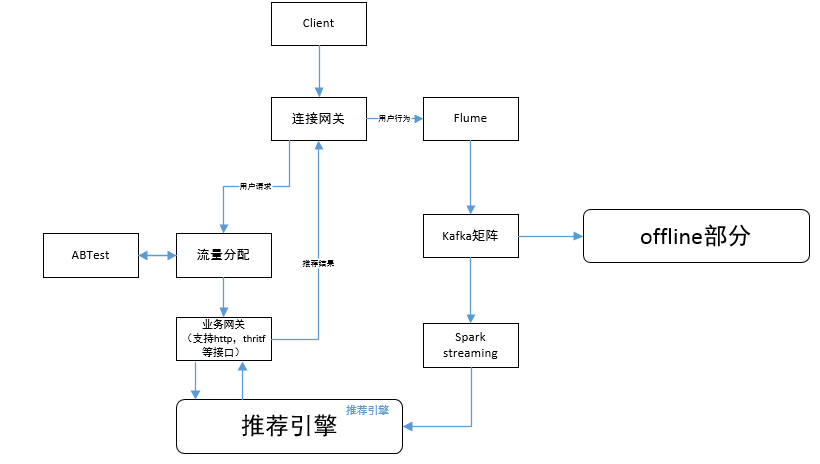
下面会根据这两部分展开讨论。
流量分配
这部分包括流量分配和ABTest两个模块,流量分配模块主要是根据需求来动态进行流量的分配,需要做到线上实时修改实时响应;ABTest是为Web和App的页面或流程设计两个版本(A/B)或多个版本(A/B/n),同时随机的分别让一定比例的客户访问,然后通过统计学方法进行分析,比较各版本对于给定目标的转化效果。你们可能觉得这两个模块功能有些冗余,其实并非如此,有一些单纯营运的需求是不需要进ABTest的。以视频推荐为例解释一下 这个问题,假设营运有这样的需求:“他们根据数据发现,iOS用户观看视频更喜欢购买会员进行免除广告,Andriod用户更倾向于观看网剧”(当然这只是一种假设),所以iOS在进行流量分配的时候会把付费视频比例提高,而Andriod会把原创网剧比例提高。然后新的一种算法或者UI希望知道是否会表现更好,这种情况就需要进行ABTest了,对照组和实验组里面iOS和Android都是包含的。这个部分并非是推荐系统的重点,以后有机会再开专题讲ABTest,所以这里就不再详细介绍了。
推荐引擎
推荐引擎主要就包括,gateway,recall(match),ranking,其中reall主要offline通过各种算法,最经典的就是基于用户行为的矩阵分解,包括itemCF、userCF、ALS,还有基于深度学习的wise&&deep等方法,后面讲offline的时候会着重说各种算法如何使用和适合的场景。
现在我们就默认为,各种算法已经训练完毕,然后会生成一些二进制文件,如下图,这些就是offline算法收敛后的权重向量结果

文件格式都是二进制,打开我们也看不懂,这里就不打开了,如果有人好奇可以私信我。这些产生后,如何到线上使用呢?用最土的办法,通过脚本每天定时cp到线上的server。也可以通过sql或者nosql数据库等方法,但是这个文件一般比较大,图里展示的只是我其中一个实验,日活大约百万级用户的训练结果数据,如果后面用户更多,item更丰富这个文件也就越大,使用数据库是不是好方式有待商榷。
gateway
这个模块只要负责用户请求的处理,主要功能包括请求参数检查,参数解析,结果组装返回。gateway业务比较轻量级,其中只有一个问题就是“假曝光”,假曝光是相对真曝光而言的,真曝光是指推送给用户的内容且用户看到了,假曝光就是指,推送给用户,但是未向用户展示的内容。推荐系统为了避免重复推荐,所以基于UUID存储推荐历史,存储时间是几小时,或者1天,再或几天,这个需要根据各自的业务情况,也要考虑资源库的大小。假曝光的处理可以在gateway中,把推送的message_id在gateway写入到nosql中,然后根据真曝光数据在离线pipeline中可以获取到,在离线pipeline定时运行时把假曝光的message_id的数据归还到recall队列中。
recall
用户请求到recall引擎后,会根据用户行为和相关配置,启动不同的召回器,下发召回任务,用户行为只要是看是否为新用户进冷启动,相关配置可能就是地区,国家等差异。用户的userprofile如果少于几个行为,一般建议为5-10个点击行为,少于这个标准属于冷启动用户,那么在recall manager的队列里只有冷启动召回器和热门召回器。热门召回器是为了保证推荐内容的热门度,而冷启动召回器是保证推荐结果的新鲜度。recall引擎还要负责任务分配,根据推荐场景,按召回源进行任务拆分,关键是让分布式任务到达负载均衡。
在各个召回器返回后recall manager收集返回结果,也就是各个召回器的返回的message_id的倒排队列,然后再进行一次整体的ranking。

下面再展开介绍一下召回器内部框架
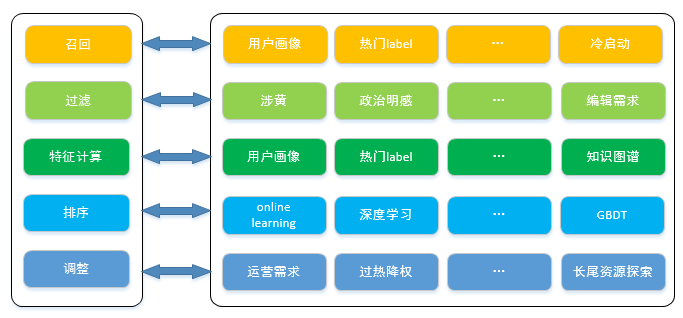
召回阶段,获取候选集,一般从基于用户画像、用户偏好、热门label等维度进行召回,如果是用户画像中点击少于10个会使用冷启动服务进行召回;
过滤阶段,对人工规则,涉黄,政治明感,政策因素,例如最近的未成年孕妇等进行过滤,总之计算保留合法的,合乎运营需要的结果;
特征计算阶段,结合用户实时行为、用户画像、知识图谱,计算出召回的候选集的特征向量;
排序阶段,使用算法模型对召回候选集进行粗排序,因为一般用户请求10条数据,召回样本大概在200-400个所以在召回器的排序内会进行序列重新调整。
- 调整阶段,在我们系统中调整策略有几十种,需要配合不同的运营需要,例如新闻内网比例要70%,头条的资源占10%,视频推荐中付费比例占40%等,调整可以理解为精细控制的过滤。
现在阶段召回,排序的都是message_id,并没有包含文章内容或是视频信息,这些内容会在ranking后,在detial服务中对推荐的返回结果的进行拼装,detail服务后还会有一层对整体结果的调整,下篇会详细介绍。
PS:最近小红和小熊都在忙着修改冷启动部分,后面会把我们的实践经验分享出来,经过了一个清明假期,更新有些晚了。
我们的文章只会迟到,从不缺席。
推荐系统——online(上)的更多相关文章
- 推荐系统遇上深度学习(十)--GBDT+LR融合方案实战
推荐系统遇上深度学习(十)--GBDT+LR融合方案实战 0.8012018.05.19 16:17:18字数 2068阅读 22568 推荐系统遇上深度学习系列:推荐系统遇上深度学习(一)--FM模 ...
- 【RS】Collaborative Memory Network for Recommendation Systems - 基于协同记忆网络的推荐系统
[论文标题]Collaborative Memory Network for Recommendation Systems (SIGIR'18) [论文作者]—Travis Ebesu (San ...
- 揭秘Keras推荐系统如何建立模型、获取用户爱好
你是否有过这样的经历?当你在亚马逊商城浏览一些书籍,或者购买过一些书籍后,你的偏好就会被系统学到,系统会基于一些假设为你推荐相关书目.为什么系统会知道,在这背后又藏着哪些秘密呢? 荐系统可以从百万甚至 ...
- hadoop实现购物商城推荐系统
1,商城:是单商家,多买家的商城系统.数据库是mysql,语言java. 2,sqoop1.9.33:在mysql和hadoop中交换数据. 3,hadoop2.2.0:这里用于练习的是伪分布模式. ...
- Paper Reading:个性化推荐系统的研究进展
论文:个性化推荐系统的研究进展 发表时间:2009 发表作者:刘建国,周涛,汪秉宏 论文链接:论文链接 本文发表在2009,对经典个性化推荐算法做了基本的介绍,是非常好的一篇中文推荐系统方面的文章. ...
- 推荐系统实践 0x0d GBDT+LR
前一篇文章我们介绍了LR->FM->FFM的整个演化过程,我们也知道,效果最好的FFM,它的计算复杂度已经达到了令人发指的\(n^2k\).其实就是这样,希望提高特征交叉的维度来弥补稀疏特 ...
- AFM论文精读
深度学习在推荐系统的应用(二)中AFM的简单回顾 AFM模型(Attentional Factorization Machine) 模型原始论文 Attentional Factorization M ...
- GBDT+LR算法解析及Python实现
1. GBDT + LR 是什么 本质上GBDT+LR是一种具有stacking思想的二分类器模型,所以可以用来解决二分类问题.这个方法出自于Facebook 2014年的论文 Practical L ...
- 推荐算法之用矩阵分解做协调过滤——LFM模型
隐语义模型(Latent factor model,以下简称LFM),是推荐系统领域上广泛使用的算法.它将矩阵分解应用于推荐算法推到了新的高度,在推荐算法历史上留下了光辉灿烂的一笔.本文将对 LFM ...
- O2O场景下的推荐排序模型:
推荐系统遇上深度学习(五)--Deep&Cross Network模型理论和实践 发表: 2018-04-22 推荐系统遇上深度学习系列:推荐系统遇上深度学习(一)--FM模型理论和实践:ht ...
随机推荐
- 【openvpn】转载:烂泥:ubuntu 14.04搭建OpenVPN服务器
地址:http://www.cnblogs.com/ilanni/p/4681740.html (1)安装openVpn软件后.在openVpn的配置目录下添加配置文件: ca.crt client ...
- linux --> 进程和线程
进程和线程 进程(process)和线程(thread)是操作系统的基本概念,下面用一个类比,来解释它们. 1. 计算机的核心是CPU,它承担了所有的计算任务.它就像一座工厂,时刻在运行. 2. 假定 ...
- 启动tomcat时jmx port被占用
一.问题描述 今天一来公司,在IntelliJ IDEA 中启动Tomcat服务器时就出现了如下图所示的错误: 错误: 代理抛出异常错误: java.rmi.server.ExportExceptio ...
- Hibernate学习笔记四 查询
HQL语法 1.基本语法 String hql = " from com.yyb.domain.Customer ";//完整写法 String hql2 = " fro ...
- 网络1712--c语言函数作业总结
作业亮点 1.总体情况 很多同学在思路方面大部分写的都很详细,能够通过思路回顾自己的代码 大部分同学都认真完成PTA,也充分利用了函数来解题 大部分同学能够从上机考试中总结自己的失误和不足点,制订了自 ...
- Alpha阶段报告-hywteam
一.Alpha版本测试报告 1. 在测试过程中总共发现了多少Bug?每个类别的Bug分别为多少个? BUG名 修复的BUG 不能重现的BUG 非BUG 没能力修复的BUG 下个版本修复 文件路径的表示 ...
- 201621123050 《Java程序设计》第14周学习总结
1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结与数据库相关内容. 2. 使用数据库技术改造你的系统 2.1 简述如何使用数据库技术改造你的系统.要建立什么表?截图你的表设计. 答 ...
- 201621123057 《Java程序设计》第3周学习总结
1. 本周学习总结 初学面向对象,会学习到很多碎片化的概念与知识.尝试学会使用思维导图将这些碎片化的概念.知识点组织起来.请使用工具画出本周学习到的知识点及知识点之间的联系.步骤如下: 1.1 写出你 ...
- ios swift例子源码网址总结
http://blog.csdn.net/woaifen3344/article/details/40079351 http://www.ruanman.net/swift/learn/4607.ht ...
- 第四十四条:为所有导出的API元素编写文档注释
简而言之,要为API编写文档,文档注释是最好,最有效的途径.对于所有可导出的API元素来说,使用文档注释应该被看作是强制性的.要 采用一致的风格来遵循标准的约定.记住,在文档注释内部出现任何的HTML ...