使用curl制作简易百度搜索
这几天研究了一下php中的curl类库,做了一个简单的百度搜索,先上代码
<div style="width:200px;height:100px;">
<div>百度搜索</div>
<form action="" method="get">
<input type="text" name="key">
<input type="submit" value="搜索">
</form>
</div>
<?php
$k = '';
$k = !empty($_GET['key'])?$_GET['key']:'';
session_start();
$_SESSION['key'] = $k; $curl = curl_init();
// 设置你需要抓取的URL for($i = 0;$i<2;$i++){
curl_setopt($curl, CURLOPT_URL, "http://www.baidu.com/s?wd={$_SESSION['key']}&pn={$i}");
// 设置header
curl_setopt($curl, CURLOPT_HEADER, 1);
// 设置cURL 参数,要求结果保存到字符串中还是输出到屏幕上。
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1);
// 运行cURL,请求网页
$data = curl_exec($curl); $pre = '/<h3 class="t"><a.*?href = "(.*?)".*?target="_blank".*?>(.*?)<\/a><\/h3>/s';
preg_match_all($pre,$data,$match); foreach ($match[1] as $k => $v) {
?>
<div style="font-size:20px;color:red;">
<a href="<?php echo $v;?>" target="_blank"><?php echo strip_tags($match[2][$k]);?></a>
</div>
<?php
}
} curl_close($curl); ?>
经过分析百度的搜索时的url发现有一个规律
https://www.baidu.com/s?wd=搜索的关键字
但是我发现使用https协议后不能够获得百度上的数据于是改为http://www.baidu.com?wd=搜索的关键字就可以啦!!
效果图如下:
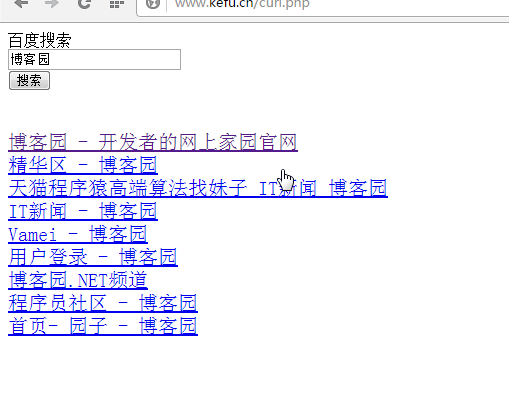
使用curl制作简易百度搜索的更多相关文章
- 【百度地图API】——如何用label制作简易的房产标签
原文:[百度地图API]--如何用label制作简易的房产标签 摘要: 最近,API爱好者们纷纷说,自定义marker太复杂了!不仅定义复杂,连所有的dom事件都要自己重新定义.有没有快速简易创建房产 ...
- 使用Tampermonkey(油猴) 插件,重新实现了,百度搜索热点过滤功能
昨天晚上,花了点时间学习了Chrome插件的制作方法,并书写了<Chrome 百度搜索热点过滤插件 - 开源软件>这一文章,简单地介绍自己实现的百度搜索热点过滤神器的原理和使用方式,并进行 ...
- 百度搜索推出惊雷算法严厉打击刷点击作弊行为-SEO公司分享
百度搜索推出惊雷算法严厉打击刷点击作弊行为 2017年11月20日凌晨,百度搜索引擎发布更新惊雷算法旨在打击刷点击作弊行为. 下面是惊雷算法相关新闻报道: 百度搜索将于11月底推出惊雷算法,严厉打击通 ...
- 免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作简易流量爬虫
前言 我们之前的爬虫都是模拟成浏览器后直接爬取,并没有动态设置IP代理以及UserAgent标识,本文记录免费IP代理池定时维护,封装通用爬虫工具类每次随机更新IP代理池跟UserAgent池,并制作 ...
- 使用python抓取百度搜索、百度新闻搜索的关键词个数
由于实验的要求,需要统计一系列的字符串通过百度搜索得到的关键词个数,于是使用python写了一个相关的脚本. 在写这个脚本的过程中遇到了很多的问题,下面会一一道来. ps:我并没有系统地学习过pyth ...
- jsonp模拟获取百度搜索相关词汇
随便写了个jsonp模拟百度搜索相关词汇的小demo,帮助新手理解jsonp的用法. <!DOCTYPE html><html lang="en">< ...
- Splinter学习--初探1,模拟百度搜索
Splinter是以Selenium, PhantomJS 和 zope.testbrowser为基础构建的web自动化测试工具,基本原理同selenium 支持的浏览器包括:Chrome, Fire ...
- 利用python爬取海量疾病名称百度搜索词条目数的爬虫实现
实验原因: 目前有一个医疗百科检索项目,该项目中对关键词进行检索后,返回的结果很多,可惜结果的排序很不好,影响用户体验.简单来说,搜索出来的所有符合疾病中,有可能是最不常见的疾病是排在第一个的,而最有 ...
- Arcgis for Javascript API下类似于百度搜索A、B、C、D marker的实现方式
原文:Arcgis for Javascript API下类似于百度搜索A.B.C.D marker的实现方式 多说无益,首先贴两张图让大家看看具体的效果: 图1.百度地图搜索结果 图2.Arcgis ...
随机推荐
- 大数据技术之_19_Spark学习_02_Spark Core 应用解析小结
1.RDD 全称 弹性分布式数据集 Resilient Distributed Dataset它就是一个 class. abstract class RDD[T: ClassTag]( @tra ...
- Vue 进阶之路(六)
上篇文章我们分析了一下 vue 中的条件渲染,本篇我们说一下 vue 中的列表渲染和 set 方法. <!DOCTYPE html> <html lang="en" ...
- 第四节 pandas 数据加载
pandas提供了一些用于将表格型数据读取为DataFrame对象的函数,其中read_csv和read_table这两个使用最多. #导包import pandas as pd from panda ...
- C#编写扫雷游戏
翻看了下以前大学学习的一些小项目,突然发现有个项目比较有意思,觉得有必要把它分享出来.当然现在看来,里面有很多的不足之处,但因博主现在已经工作,没有时间再去优化.这个项目就是利用C#编写一个Windo ...
- 前端笔记之CSS(下)浮动&BFC&定位&Hack
一.浮动 1.1 各个语言的主要知识点 HTML:标签语义化(那么怎么样布局才是合理的?没有绝对的对和错) CSS: 样式: 布局: 标准流(标准文档流.普通文档流):盒子模型(width/heigh ...
- 第一次上机,HTML静态网页的开发
<html> <head> <title>第一次上级,cyy</title> </head> <body> <h3 ali ...
- Snapde一个全新的CSV超大文件编辑软件
今天介绍如果数据量超过104万行Excel无法打开了,用什么软件可以打开呢?Snapde,一个专门为编辑超大型数据量CSV文件而设计的单机版电子表格软件:它在C++语言开发的Snapman多人协作电子 ...
- Process 'command 'D:\jdk8\jdk\bin\java.exe'' finished with non-zero exit value 2
转载请标明出处,维权必究:https://www.cnblogs.com/tangZH/p/10539006.html 捣鼓了好久,现在已经不想说话,为何会出现这个问题,Process 'comman ...
- Appium的入门使用
ps:有没有人和我一样觉得Appium官方文档写的很烂的, 这官方文档,还不如很多人写的博客详细,而且对于初学的入门者实在是不够友好, 官网:https://github.com/appium/jav ...
- 当心Azure跨区域数据传输产生额外费用
最近同事发现Azure上一台虚拟机的费用环比增加了一部分.后面仔细检查发现费用来自数据传输, 因为这是早期部署的一台Azure虚拟机(Iaas),我们在本地生成备份,然后通过AzCopy到存储账号的B ...