Python中编码的详细讲解
看这篇文章前,你应该已经知道了为什么有编码,以及编码的种类情况
- ASCII 占1个字节,只支持英文
- GB2312 占2个字节,支持6700+汉字
- GBK GB2312的升级版,支持21000+汉字
- Shift-JIS 日本字符
- ks_c_5601-1987 韩国编码
- TIS-620 泰国编码
由于每个国家都有自己的字符,所以其对应关系也涵盖了自己国家的字符,但是以上编码都存在局限性,即:仅涵盖本国字符,无其他国家字符的对应关系。应运而生出现了万国码,他涵盖了全球所有的文字和二进制的对应关系,
- Unicode 2-4字节 已经收录136690个字符,并还在一直不断扩张中...
Unicode 起到了2个作用:
- 直接支持全球所有语言,每个国家都可以不用再使用自己之前的旧编码了,用unicode就可以了。(就跟英语是全球统一语言一样)
- unicode包含了跟全球所有国家编码的映射关系,为什么呢?后面再讲
Unicode解决了字符和二进制的对应关系,但是使用unicode表示一个字符,太浪费空间。例如:利用unicode表示“Python”需要12个字节才能表示,比原来ASCII表示增加了1倍。
由于计算机的内存比较大,并且字符串在内容中表示时也不会特别大,所以内容可以使用unicode来处理,但是存储和网络传输时一般数据都会非常多,那么增加1倍将是无法容忍的!!!
为了解决存储和网络传输的问题,出现了Unicode Transformation Format,学术名UTF,即:对unicode中的进行转换,以便于在存储和网络传输时可以节省空间!
- UTF-8: 使用1、2、3、4个字节表示所有字符;优先使用1个字符、无法满足则使增加一个字节,最多4个字节。英文占1个字节、欧洲语系占2个、东亚占3个,其它及特殊字符占4个
- UTF-16: 使用2、4个字节表示所有字符;优先使用2个字节,否则使用4个字节表示。
- UTF-32: 使用4个字节表示所有字符;
总结:UTF 是为unicode编码 设计 的一种 在存储 和传输时节省空间的编码方案。
字符在硬盘上的存储
无论以什么编码在内存里显示字符,存到硬盘上都是2进制。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
ascii编码(美国): l 0b1101100 o 0b1101111 v 0b1110110 e 0b1100101GBK编码(中国): 老 0b11000000 0b11001111 男 0b11000100 0b11010000 孩 0b10111010 0b10100010Shift_JIS编码(日本): 私 0b10001110 0b10000100 は 0b10000010 0b11001101ks_c_5601-1987编码(韩国): 나 0b10110011 0b10101010 는 0b10110100 0b11000010 TIS-620编码(泰国): ฉัน 0b10101001 0b11010001 0b10111001... |
|
1
|
要注意的是,存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读,要不然就乱了。。 |
编码的转换
虽然国际语言是英语 ,但大家在自己的国家依然说自已的语言,不过出了国, 你就得会英语
编码也一样,虽然有了unicode and utf-8 , 但是由于历史问题,各个国家依然在大量使用自己的编码,比如中国的windows,默认编码依然是gbk,而不是utf-8
基于此,如果中国的软件出口到美国,在美国人的电脑上就会显示乱码,因为他们没有gbk编码。
若想让中国的软件可以正常的在 美国人的电脑上显示,只有以下2条路可走:
- 让美国人的电脑上都装上gbk编码
- 把你的软件编码以utf-8编码
第1种方法几乎不可能实现,第2种方法比较简单。 但是也只能是针对新开发的软件。 如果你之前开发的软件就是以gbk编码的,上百万行代码可能已经写出去了,重新编码成utf-8格式也会费很大力气。
so , 针对已经用gbk开发完毕的项目,以上2种方案都不能轻松的让项目在美国人电脑上正常显示,难道没有别的办法了么?
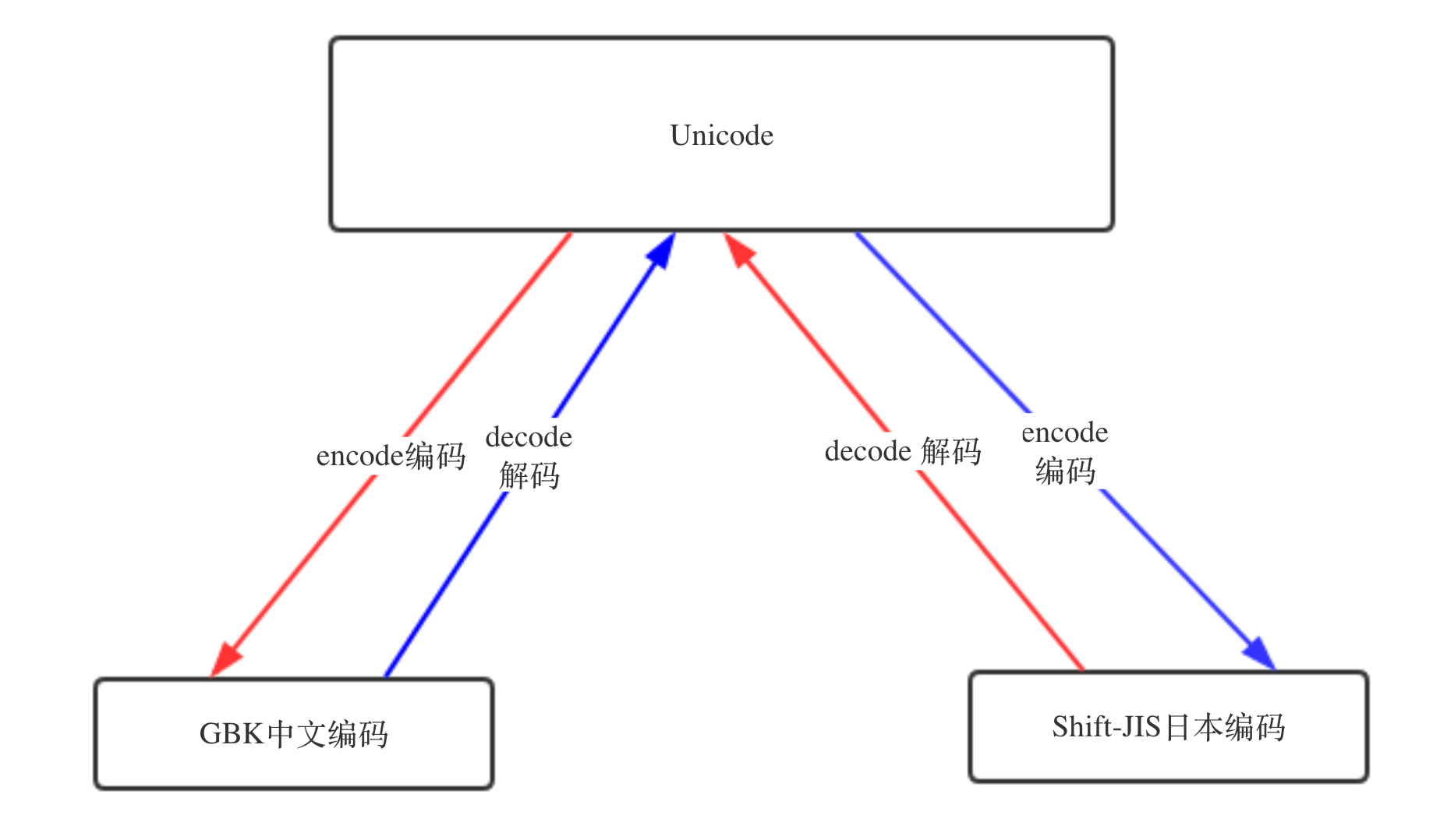
有, 还记得我们讲unicode其中一个功能是其包含了跟全球所有国家编码的映射关系,意思就是,你写的是gbk的“路飞学城”,但是unicode能自动知道它在unicode中的“路飞学城”的编码是什么,如果这样的话,那是不是意味着,无论你以什么编码存储的数据 ,只要你的软件在把数据从硬盘读到内存里,转成unicode来显示,就可以了。
由于所有的系统、编程语言都默认支持unicode,那你的gbk软件放到美国电脑 上,加载到内存里,变成了unicode,中文就可以正常展示啦。
unicode与gbk的映射表 http://www.unicode.org/charts/
Python3的执行过程
在看实际代码的例子前,我们来聊聊,python3 执行代码的过程
- 解释器找到代码文件,把代码字符串按文件头定义的编码加载到内存,转成unicode
- 把代码字符串按照语法规则进行解释,
- 所有的变量字符都会以unicode编码声明
编码转换过程
实际代码演示,在py3上 把你的代码以utf-8编写, 保存,然后在windows上执行,
|
1
2
|
s = '路飞学城'print(s) |
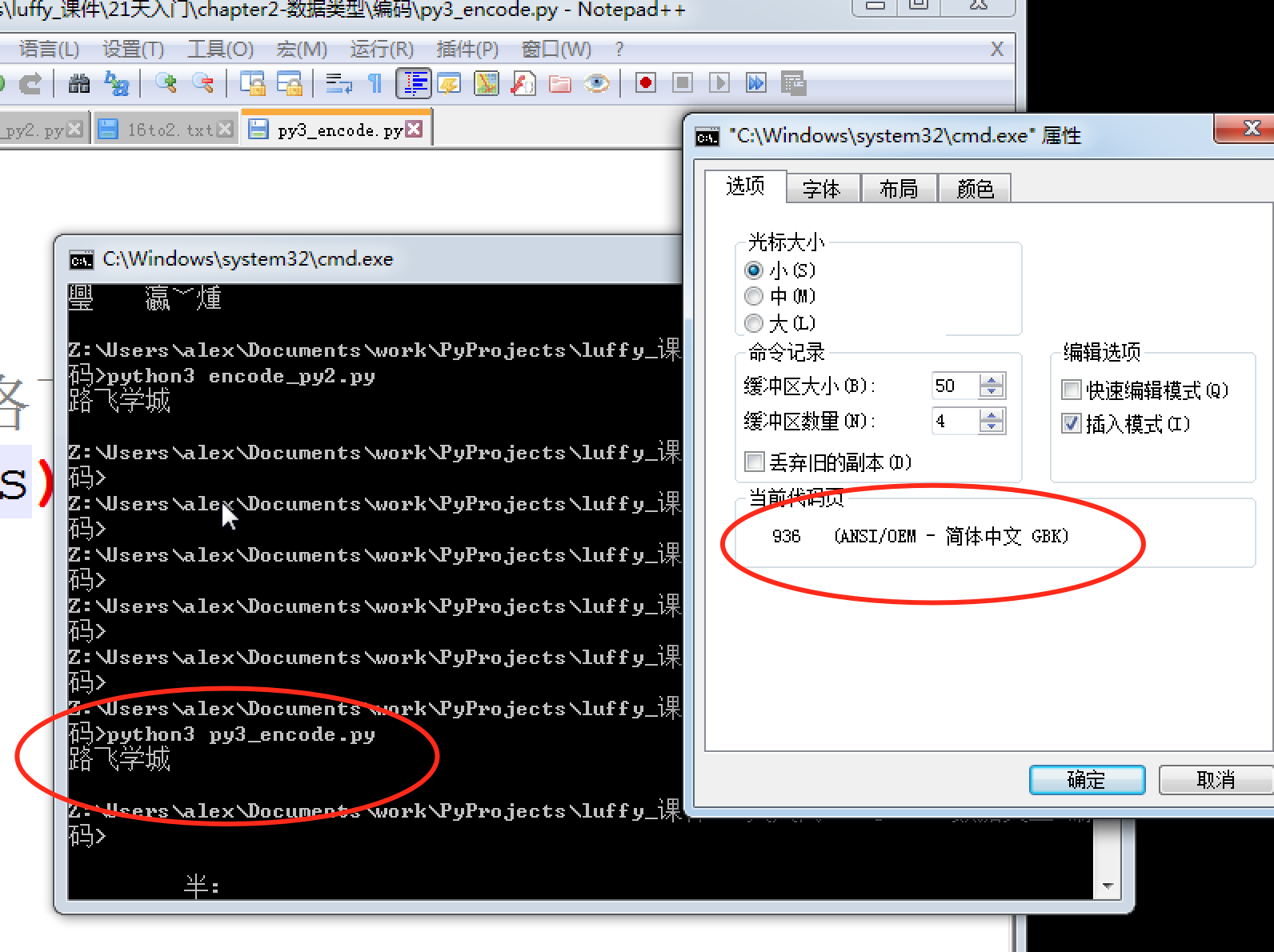
so ,一切都很美好,到这里,我们关于编码的学习按说就可以结束了。
但是,如生活一样,美好的表面下,总是隐藏着不尽如人意,上面的utf-8编码之所以能在windows gbk的终端下显示正常,是因为到了内存里python解释器把utf-8转成了unicode , 但是这只是python3, 并不是所有的编程语言在内存里默认编码都是unicode,比如 万恶的python2 就不是, 它的默认编码是ASCII,想写中文,就必须声明文件头的coding为gbk or utf-8, 声明之后,python2解释器仅以文件头声明的编码去解释你的代码,加载到内存后,并不会主动帮你转为unicode,也就是说,你的文件编码是utf-8,加载到内存里,你的变量字符串就也是utf-8, 这意味着什么你知道么?。。。意味着,你以utf-8编码的文件,在windows是乱码。
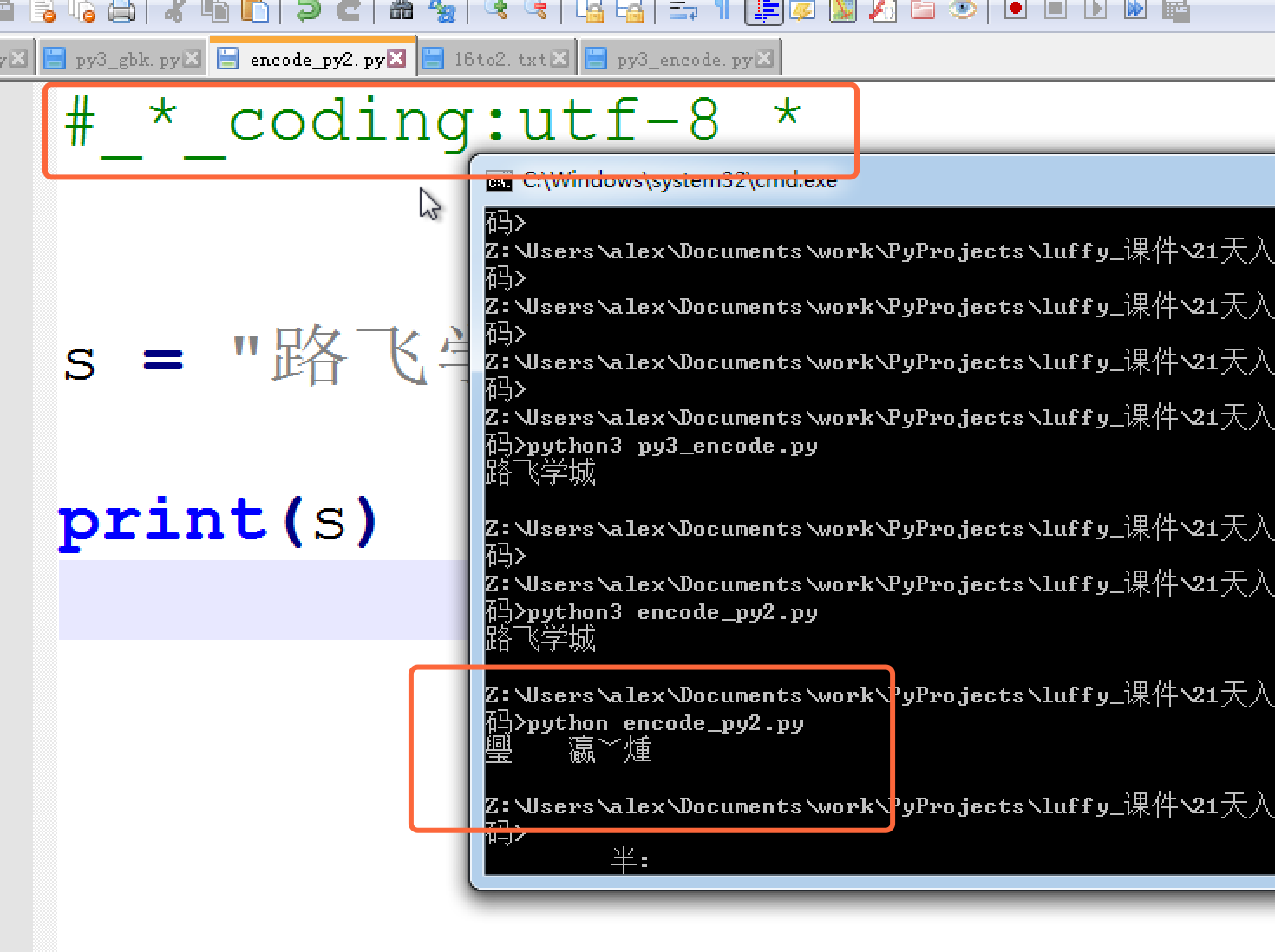
乱是正常的,不乱才不正常,因为只有2种情况 ,你的windows上显示才不会乱
- 字符串以GBK格式显示
- 字符串是unicode编码
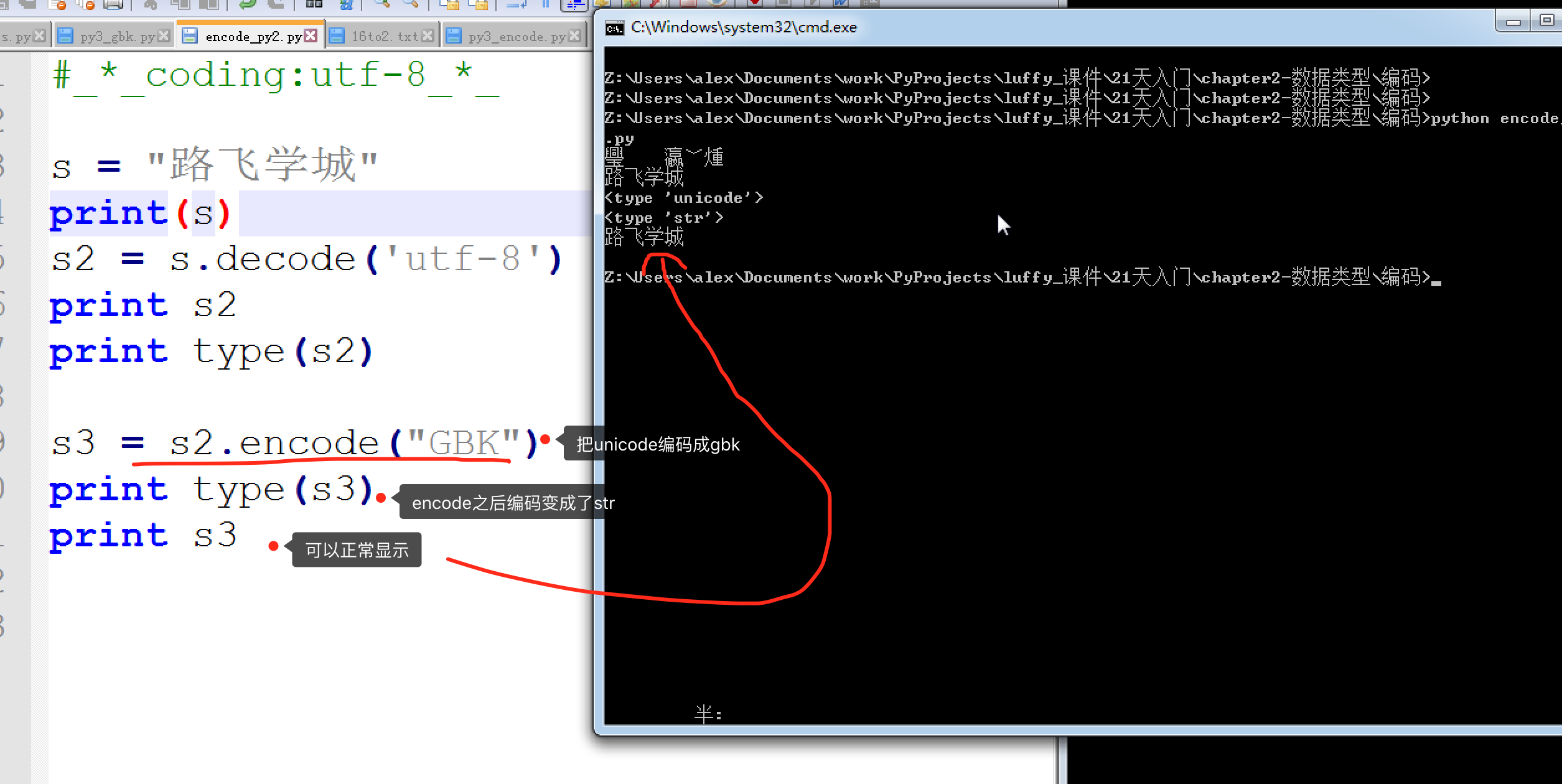
既然Python2并不会自动的把文件编码转为unicode存在内存里, 那就只能使出最后一招了,你自己手动转。Py3 自动把文件编码转为unicode必定是调用了什么方法,这个方法就是,decode(解码) 和encode(编码)
|
1
2
|
UTF-8 --> decode 解码 --> UnicodeUnicode --> encode 编码 --> GBK / UTF-8 .. |
decode示例

encode 示例
记住下图规则
如何验证编码转对了呢?
1. 查看数据类型,python 2 里有专门的unicode 类型
2. 查看unicode编码映射表
unicode字符是有专门的unicode类型来判断的,但是utf-8,gbk编码的字符都是str,你如果分辨出来的当前的字符串数据是何种编码的呢? 有人说可以通过字节长度判断,因为utf-8一个中文占3字节,gbk一个占2字节
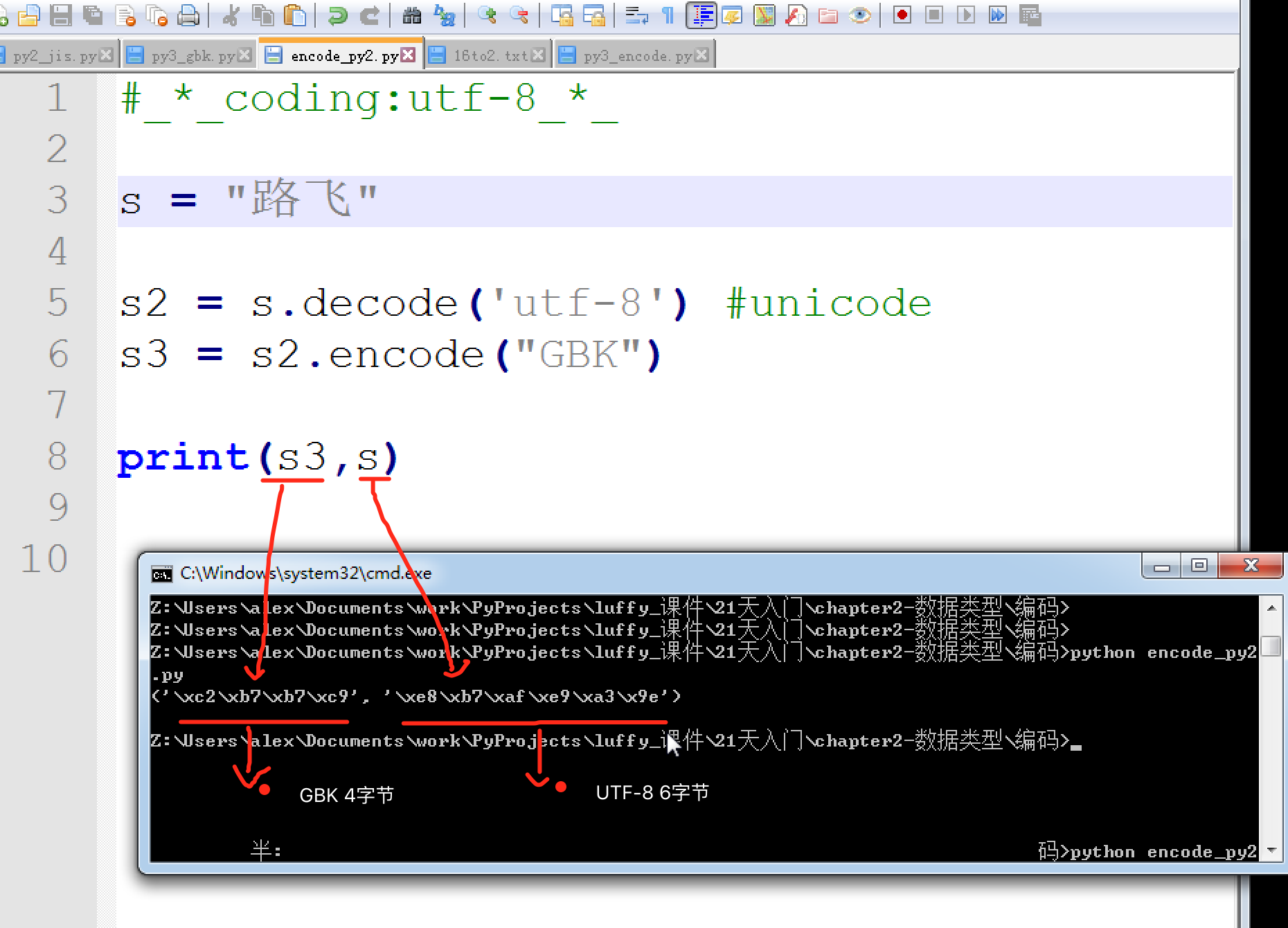
靠上面字节个数,虽然也能大体判断是什么类型,但总觉得不是很专业。
怎么才能精确的验证一个字符的编码呢,就是拿这些16进制的数跟编码表里去匹配。
“路飞学城”的unicode编码的映射位置是 u'\u8def\u98de\u5b66\u57ce' ,‘\u8def’ 就是‘路’,到表里搜一下。
“路飞学城”对应的GBK编码是'\xc2\xb7\xb7\xc9\xd1\xa7\xb3\xc7' ,2个字节一个中文,"路" 的二进制 "\xc2\xb7"是4个16进制,正好2字节,拿它到unicode映射表里对一下, 发现是G0-4237,并不是\xc2\xb7呀。。。擦。演砸了吧。。
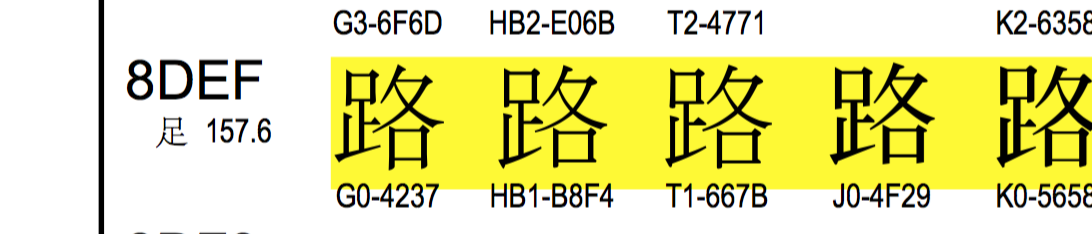
再查下“飞” \u98de ,对应的是G0-3749, 跟\xb7\xc9也对不上。
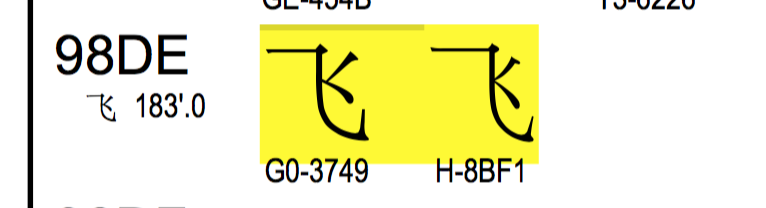
虽然对不上, 但好\xc2\xb7 和G0-4237中的第2位的2和第4位的7对上了,“飞”字也是一样,莫非巧合?
把他们都转成2进制显示试试
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
路C 28 4 2 1 8 4 2 1<strong>1 1 0 0 0 0 1 0</strong>B 78 4 2 1 8 4 2 1<strong>1 0 1 1 0 1 1 1</strong>飞B 78 4 2 1 8 4 2 11 0 1 1 0 1 1 1C 98 4 2 1 8 4 2 11 1 0 0 1 0 0 1 |
这个“路”还是跟G0-4237对不上呀,没错, 但如果你把路\xc2\xb7的每个二进制字节的左边第一个bit变成0试试呢, 我擦,加起来就真的是4237了呀。。难道又是巧合???
必然不是,是因为,GBK的编码表示形式决定的。。因为GBK编码在设计初期就考虑到了要兼容ASCII,即如果是英文,就用一个字节表示,2个字节就是中文,但如何区别连在一起的2个字节是代表2个英文字母,还是一个中文汉字呢? 中国人如此聪明,决定,2个字节连在一起,如果每个字节的第1位(也就是相当于128的那个2进制位)如果是1,就代表这是个中文,这个首位是128的字节被称为高字节。 也就是2个高字节连在一起,必然就是一个中文。 你怎么如此笃定?因为0-127已经表示了英文的绝大部分字符,128-255是ASCII的扩展表,表示的都是极特殊的字符,一般没什么用。所以中国人就直接拿来用了。
问:那为什么上面 "\xc2\xb7"的2进制要把128所在的位去掉才能与unicode编码表里的G0-4237匹配上呢?
这只能说是unicode在映射表的表达上直接忽略了高字节,但真正映射的时候 ,肯定还是需要用高字节的哈。
Python bytes类型
在python 2 上写字符串
|
1
2
3
4
5
|
>>> s = "路飞">>> print s路飞>>> s'\xe8\xb7\xaf\xe9\xa3\x9e' |
虽说打印的是路飞,但直接调用变量s,看到的却是一个个的16进制表示的二进制字节,我们怎么称呼这样的数据呢?直接叫二进制么?也可以, 但相比于010101,这个数据串在表示形式上又把2进制转成了16进制来表示,这是为什么呢? 哈,为的就是让人们看起来更可读。我们称之为bytes类型,即字节类型, 它把8个二进制一组称为一个byte,用16进制来表示。
说这个有什么意思呢?
想告诉你一个事实, 就是,python2的字符串其实更应该称为字节串。 通过存储方式就能看出来, 但python2里还有一个类型是bytes呀,难道又叫bytes又叫字符串? 嗯 ,是的,在python2里,bytes == str , 其实就是一回事
除此之外呢, python2里还有个单独的类型是unicode , 把字符串解码后,就会变成unicode
|
1
2
3
4
5
6
|
>>> s'\xe8\xb7\xaf\xe9\xa3\x9e' #utf-8>>> s.decode('utf-8')u'\u8def\u98de' #unicode 在unicode编码表里对应的位置>>> print(s.decode('utf-8'))路飞 #unicode 格式的字符 |
由于Python创始人在开发初期认知的局限性,其并未预料到python能发展成一个全球流行的语言,导致其开发初期并没有把支持全球各国语言当做重要的事情来做,所以就轻佻的把ASCII当做了默认编码。 当后来大家对支持汉字、日文、法语等语言的呼声越来越高时,Python于是准备引入unicode,但若直接把默认编码改成unicode的话是不现实的, 因为很多软件就是基于之前的默认编码ASCII开发的,编码一换,那些软件的编码就都乱了。所以Python 2 就直接 搞了一个新的字符类型,就叫unicode类型,比如你想让你的中文在全球所有电脑上正常显示,在内存里就得把字符串存成unicode类型
|
1
2
3
4
5
6
7
8
|
>>> s = "路飞">>> s'\xe8\xb7\xaf\xe9\xa3\x9e'>>> s2 = s.decode("utf-8")>>> s2u'\u8def\u98de'>>> type(s2)<type 'unicode'> |
时间来到2008年,python发展已近20年,创始人龟叔越来越觉得python里的好多东西已发展的不像他的初衷那样,开始变得臃肿、不简洁、且有些设计让人摸不到头脑,比如unicode 与str类型,str 与bytes类型的关系,这给很多python程序员造成了困扰。
龟叔再也忍不了,像之前一样的修修补补已不能让Python变的更好,于是来了个大变革,Python3横空出世,不兼容python2,python3比python2做了非常多的改进,其中一个就是终于把字符串变成了unicode,文件默认编码变成了utf-8,这意味着,只要用python3,无论你的程序是以哪种编码开发的,都可以在全球各国电脑上正常显示,真是太棒啦!
PY3 除了把字符串的编码改成了unicode, 还把str 和bytes 做了明确区分, str 就是unicode格式的字符, bytes就是单纯二进制啦。
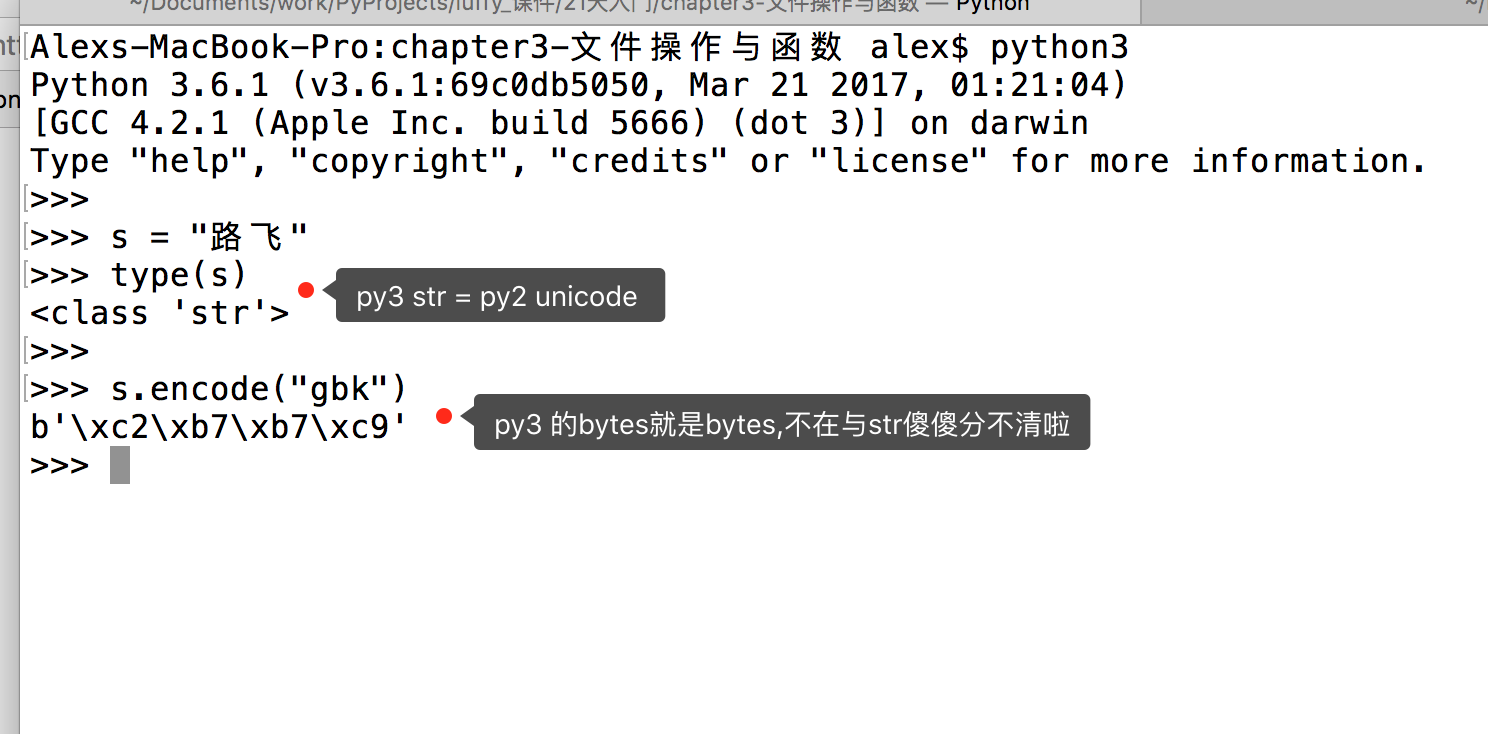
最后一个问题,为什么在py3里,把unicode编码后,字符串就变成了bytes格式? 你直接给我直接打印成gbk的字符展示不好么?我想其实py3的设计真是煞费苦心,就是想通过这样的方式明确的告诉你,想在py3里看字符,必须得是unicode编码,其它编码一律按bytes格式展示。
最后再提示一下,Python只要出现各种编码问题,无非是哪里的编码设置出错了
常见编码错误的原因有:
- Python解释器的默认编码
- Python源文件文件编码
- Terminal使用的编码
- 操作系统的语言设置
掌握了编码之前的关系后,挨个排错就好啦
Python中编码的详细讲解的更多相关文章
- python编写shell脚本详细讲解
python编写shell脚本详细讲解 那,python可以做shell脚本吗? 首先介绍一个函数: os.system(command) 这个函数可以调用shell运行命令行command并且返回它 ...
- bytes类型和python中编码的转换方法
一.bytes类型 bytes类型是指一堆字节的集合,在python中以b开头的字符串都是bytes类型.例如: >>> a = "中国" >>> ...
- 【转】python中的闭包详细解析
一.什么是闭包? 如果一个内嵌函数访问外部嵌套函数作用域的变量,并返回这个函数,则这个函数就是闭包 闭包必须满足三个条件: 1. 必须有一个内嵌函数 2. 内嵌函数必须引用外部嵌套函数中的变量 ...
- python中的类简单讲解
类似其它的语言, Python 中的函数使用小括号( () )调用.函数在调用之前必须先定义.如果函数中没有 return 语句, 就会自动返回 None 对象. Python 是通过引用调 ...
- python中编码问题
各种编码在内存中所占的大小: ascii: 英文:8bit (1B) uft-: 英文:8bit (1B) 中文:24bit (3B) GBK: 英文:8bit (1B) 中文:16bit (2B) ...
- python 中 property 属性的讲解及应用
Python中property属性的功能是:property属性内部进行一系列的逻辑计算,最终将计算结果返回 property属性的有两种方式: 1. 装饰器 即:在方法上应用装饰器 2. 类属性 即 ...
- python中heapq堆的讲解
堆的定义: 堆是一种特殊的数据结构,它的通常的表示是它的根结点的值最大或者是最小. python中heapq的使用 列出一些常见的用法: heap = []#建立一个常见的堆 heappush(hea ...
- Python中字典的详细用法
#字典 #字典是Python中唯一内建的映射类型.字典中没有特殊的顺序,但都是存储在一个特定的键(key)下面,键可以是数字,字符串,甚至是元组 #一.字典的使用 #在某些情况下,字典比列表更加适用: ...
- Python中编码和字符串
编码和字符串 编码 在学习回顾中总结一下ASCII编码.Unicode编码和utf-8编码. 计算机中只能处理数字,我们若要处理文本的话就要将文件转换为数字.所以,这就涉及该怎样转换的问题,也就是编码 ...
随机推荐
- Python-字符串及列表操作-Day2
1.数据类型 1.1 变量引出数据类型 变量:用来记录状态变量值的变化就是状态的变化,程序运行的本质就是来处理一系列的变化 1.2 五大基本数据类型: 数字 字符串 列表 元组 字典 1.2.1 数字 ...
- JAVA中的Log4j
Log4j的简介: 使用异常处理机制==>异常 使用debug调试(必须掌握) System.out.Print(); 001.控制台行数有限制 002.影响性能 ...
- HTTP协议扫盲(七)请求报文之 GET、POST-FORM 和 POST-FILE
一.get 1.页面代码 2.请求报文 3.小结 get请求没有报文体,所以请求报文没有content-type url上的query参数param11=val11¶m12=val12 ...
- Linux实战案例(4)CentOS清除用户登录记录和命令历史方法
CentOS清除用户登录记录和命令历史方法 清除登陆系统成功的记录[root@localhost root]# echo > /var/log/wtmp //此文件默认打开时乱码,可查到ip等信 ...
- OAuth2.0学习(1-10)新浪开放平台微博认证-手机应用授权和refresh_token刷新access_token
1.当你是使用微博官方移动SDK的移动应用时,授权返回access_token的同时,还会多返回一个refresh_token: JSON 1 2 3 4 5 6 { "access ...
- 使用TortoiseSVN打Tag
参考了 https://blog.csdn.net/liuzx32/article/details/9123401. 值得注意的点是: 选择路径的时候,不要先点进去自己建好叶子节点路径再选择该路径,会 ...
- 记录下项目中常用到的JavaScript/JQuery代码二(大量实例)
记录下项目中常用到的JavaScript/JQuery代码一(大量实例) 1.input输入框监听变化 <input type="text" style="widt ...
- python常见异常
- ubuntu16.04安装jdk1.8
首先去Oracle官网下载JDK1.8的tar.gz压缩包. 然后下载下来的包的默认位置应该是在~/下载/下. 执行如下命令解压缩并安装JDK. cd ~/下载/ tar -zxvf jdk-8u16 ...
- [python]_ELVE_pip2和pip3如何共存
作者:匿名用户链接:https://www.zhihu.com/question/21653286/answer/95532074来源:知乎著作权归作者所有,转载请联系作者获得授权. 想学习Pytho ...