python网络爬虫笔记(九)
4.1.1 urllib2 和urllib是两个不一样的模块
urllib2最简单的就是使用urllie2.urlopen函数使用如下
urllib2.urlopen(url[,data[,timeout[,cafile[,capath[,cadefault[,context]]]]]]) 按照文档urllib2.urlopen可以打开HTTP HTTPS FTP协议的URL链接地址,主演使用HTTP协议,他的参数以ca开头的都是跟身份验证有关,不常使用,data参数是post方法提交URL时使用,常用的是timeout参数,url参数是提交网络地址全称,前端是协议名,后端是端口号,timeout是超时时间设置,
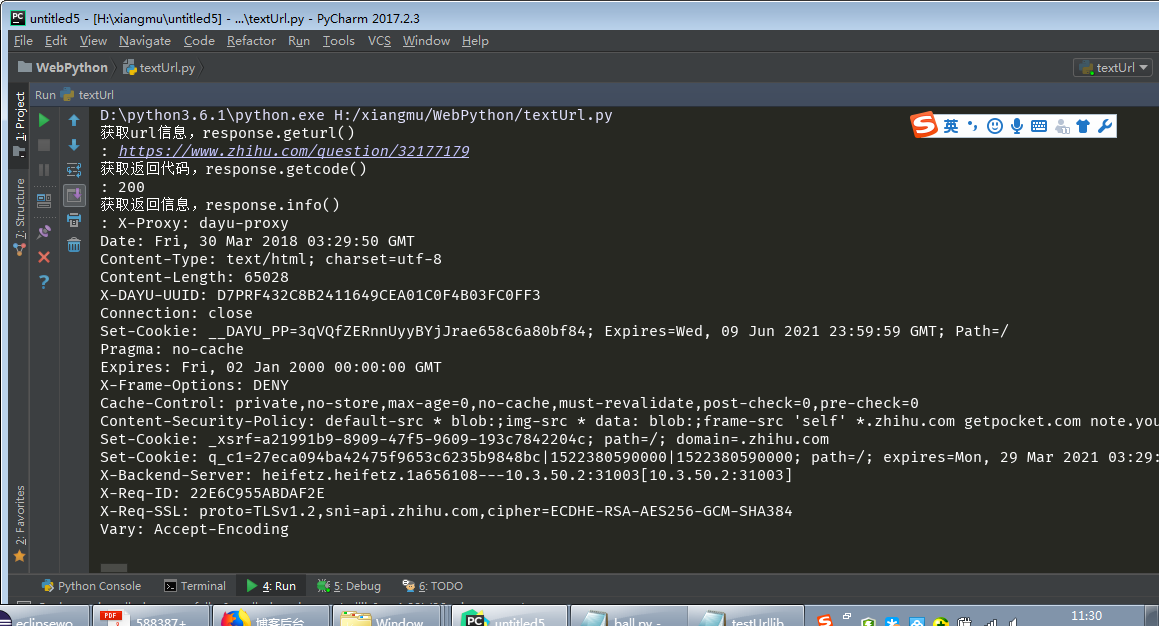
函数返回对象有三个额外使用方法,geturl()函数返回的response的url信息,常用于重定向的情况,info()函数返回的response的基本信息, getcode()函数返回的response的状态代码,200成功, 404页面不存在, 503服务器暂时不可用,
刚开始,导入得模块是urllib2,但是运行出错,因为urllib在python3.0以上的版本使用的模块是urllib.request模块。响应的就要导入词模块。在print中也存在差别,write中使用的是String类型。也要做更改。才能正确执行。
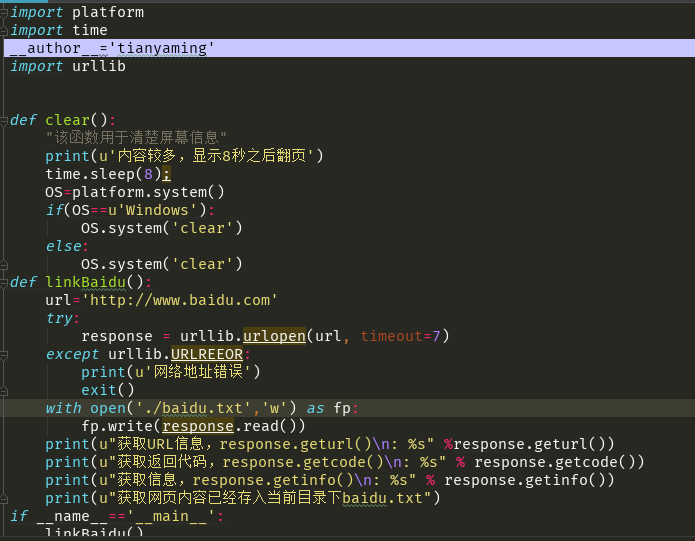
另外就是要说明一点,在Linux中使用的vi 进行编程 前面必须添加声明语句,如果要调用模块必须导入响应的模块、
#!/usr/bin/env python
#-*- coding: utf-8 -*-

package com.tian;
import java.io.*;
import java.util.*;
import javax.swing.*;
import java.awt.Font;
import java.awt.event.*;
public class QuizCardBuilder {
private JTextArea question;
private JTextArea answer;
private JFrame frame;
// private ArrayList<QuizCard> cardList;
public static void main(String[] args) {
// TODO Auto-generated method stub
QuizCardBuilder builder=new QuizCardBuilder();
builder.go();
}
public void go(){
frame=new JFrame("Quiz Card Builder");
JPanel mainPanel=new JPanel();
Font bigFont=new Font("sanserif",Font.BOLD,23);
question=new JTextArea(6,23);
question.setLineWrap(true);
question.setWrapStyleWord(true);
question.setFont(bigFont);
JScrollPane qScroller=new JScrollPane(question);
qScroller.setVerticalScrollBarPolicy(ScrollPaneConstants.VERTICAL_SCROLLBAR_ALWAYS);
qScroller.setHorizontalScrollBarPolicy(ScrollPaneConstants.HORIZONTAL_SCROLLBAR_NEVER);
answer=new JTextArea(6,20);
answer.setLineWrap(true);
answer.setWrapStyleWord(true);
answer.setFont(bigFont);
JScrollPane aScroller=new JScrollPane(answer);
aScroller.setVerticalScrollBarPolicy(ScrollPaneConstants.VERTICAL_SCROLLBAR_ALWAYS);
aScroller.setHorizontalScrollBarPolicy(ScrollPaneConstants.HORIZONTAL_SCROLLBAR_NEVER);
JButton nextbutton=new JButton("next button");
// cardList=new ArrayList<QuizCard>();
JLabel qLabel=new JLabel("Question");
JLabel aLabel=new JLabel("Answer");
mainPanel.add(qLabel);
mainPanel.add(qScroller);
mainPanel.add(aLabel);
mainPanel.add(aScroller);
mainPanel.add(nextbutton);
nextbutton.addActionListener(new NextCardListener());
JMenuBar menuBar=new JMenuBar();
JMenu fileMenu=new JMenu("File");
JMenuItem newMenuItem=new JMenuItem("new");
JMenuItem saveMenuItem=new JMenuItem("save");
newMenuItem.addActionListener(new NewMenuListener());
saveMenuItem.addActionListener(new SaveMenuListener());
fileMenu.add(newMenuItem);
fileMenu.add(saveMenuItem);
fileMenu.add(fileMenu);
menuBar.add(fileMenu);
frame.setJMenuBar(menuBar);
frame.getContentPane().add(BroderLayout,mainPanel);
frame.setSize(200,200);
frame.setVisible(true);
}
public class NextCardListener implements ActionListener{
public void actionPerformed(ActionListener ev){
QuizCard card=new QuizCard(question.getText(),answer.getText());
cardList.add(card);
clearCard();
}
}
public class SaveMenuListener implements ActionListener{
public void actionPerformed(ActionListener ev){
}
}
}
python网络爬虫笔记(九)的更多相关文章
- Python网络爬虫笔记(五):下载、分析京东P20销售数据
(一) 分析网页 下载下面这个链接的销售数据 https://item.jd.com/6733026.html#comment 1. 翻页的时候,谷歌F12的Network页签可以看到下面 ...
- [Python]网络爬虫(九):百度贴吧的网络爬虫(v0.4)源码及解析
转自:http://blog.csdn.net/pleasecallmewhy/article/details/8934726 百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键 ...
- Python网络爬虫笔记(二):链接爬虫和下载限速
(一)代码1(link_crawler()和get_links()实现链接爬虫) import urllib.request as ure import re import urllib.parse ...
- python网络爬虫笔记(八)
一.pthon 序列化json格式 1.将python内置对象转换成json 模块,dumps()方法返回的是一个str,内容是标准的JSON,dump()方法可以直接吧JSON写入一个file-li ...
- python网络爬虫笔记(六)
1.获取属性如果不存在就返回404,通过内置一系列函数,我们可以对任意python对象进行剖析,拿到其内部数据,但是要注意的是,只是在不知道对象信息的时候,我们可以获得对象的信息. 2.实例属性和类属 ...
- python网络爬虫笔记(五)
一.python的类对象的继承 1.所有的父类都是object类,由于类可以起到模块的作用,因此,可以在创建实例的时候,巴西一些认为必须要绑定的属性填写上去,通过定义一个特殊的方法 __init__, ...
- python网络爬虫笔记(四)
一.python中的高阶函数算法 1.sorted()函数的排序 sorted()函数是一个高阶函数,还可以接受一个key函数来实现自定义的函数排序,key指定的函数作用于每个序列元素上,并根据k ...
- python网络爬虫笔记(三)
一.切片和迭代 1.列表生成式 2.生成器的generate,但是generate保存的是算法,所以可以迭代计算,没有必要,每次调用generate 二.iteration 循环 1.凡是作用于for ...
- python网络爬虫笔记(一)
一.查询数据字典型数据 1.先说说dictionary查找和插入的速度极快,不会随着key的增加减慢速度,但是占用的内存大 2.list查找和插入的时间随着元素的增加而增加,但还是占用的空间小,内存浪 ...
随机推荐
- Liunx/RHEL6.5 Oracle11 安装记录[缺少依赖包的解决方案]
1.将镜像文件挂,如/mnt # mount -o loop rhel-server-6.1-x86_64-dvd.iso /mnt#这一步其实有很多实现方法,如可以将镜像文件中的Packages文件 ...
- day 12 - 1 装饰器进阶
装饰器进阶 装饰器的简单回顾 装饰器开发原则:开放封闭原则装饰器的作用:在不改变原函数的调用方式的情况下,在函数的前后添加功能装饰器的本质:闭包函数 装饰器的模式 def wrapper(func): ...
- Solr 7.7.0 部署到Tomcat
第一步 1.Solr 解压后server/solr-webapp下一个webapp目录,它就是Solr的Web项目,把它复制到tomcat的webapps目录下并改名为solr # 进入Solr的se ...
- python实战===教你用微信每天给女朋友说晚安【转】
转自:https://www.cnblogs.com/botoo/p/8622379.html#4081184 但凡一件事,稍微有些重复.我就考虑怎么样用程序来实现它. 这里给各位程序员朋友分享如何每 ...
- workqueue --最清晰的讲解
带你入门: 1.INIT_WORK(struct work_struct *work, void (*function)(void *), void *data) 上面一句只是定义了work和work ...
- k8s技能树
- nginx多虚拟主机优先级location匹配规则及tryfiles的使用
nginx多虚拟主机优先级location匹配规则及tryfiles的使用 .相同server_name多个虚拟主机优先级访问 .location匹配优先级 .try_files使用 .nginx的a ...
- 7-Links
Use the <a> element to define a link Use the href attribute to define the link address Use the ...
- MySQL查询语句练习题,测试基本够用了
Sutdent表的定义 字段名 字段描述 数据类型 主键 外键 非空 唯一 自增 Id 学号 INT(10) 是 否 是 是 是 Name 姓名 VARCHAR(20) 否 否 是 否 否 Sex 性 ...
- django配置发送邮箱
该邮箱配置后台发送邮箱验证使用 settings内配置 # 服务器地址 EMAIL_HOST = 'smtp.163.com' # 端口,邮箱默认动态端口 25 EMAIL_PORT = 25 # 邮 ...