L1与L2正则(转)
概念:
L0范数表示向量中非零元素的个数:NP问题,但可以用L1近似代替。
L1范数表示向量中每个元素绝对值的和: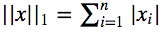
L1范数的解通常是稀疏性的,倾向于选择:1. 数目较少的一些非常大的值 2. 数目较多的insignificant的小值。faster-RCNN里面的smooth-L1 loss就是L1的平滑版本
L2范数即欧氏距离: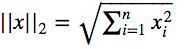
L2范数越小,可以使得w的每个元素都很小,接近于0,但L1范数不同的是他不会让它等于0而是接近于0。
从贝叶斯先验角度看:
L1则相当于设置一个Laplacean先验,去选择MAP(maximum a posteriori)假设。而L2则类似于Gaussian先验
先假设参数 服从一种先验分布
,那么根据贝叶斯公式
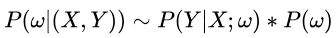 利用极大似然估计求参数
利用极大似然估计求参数 的时候,现在我们的极大似然函数就变成了:
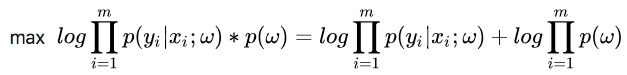
L1范数:
假设我们让 服从的分布为标准拉普拉斯分布,即概率密度函数为
,那么式子(7)多出的项就变成了
,其中C为常数了,重写式子:
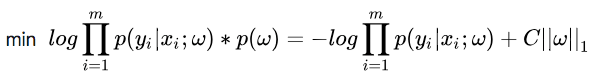
L2范数:
假设我们让 服从的分布为标准正太分布,即概率密度为
,那么式子(7)多出的项就成了
,其中C为常数,重写式子:
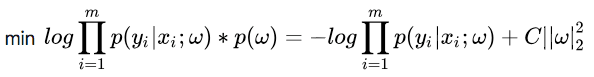
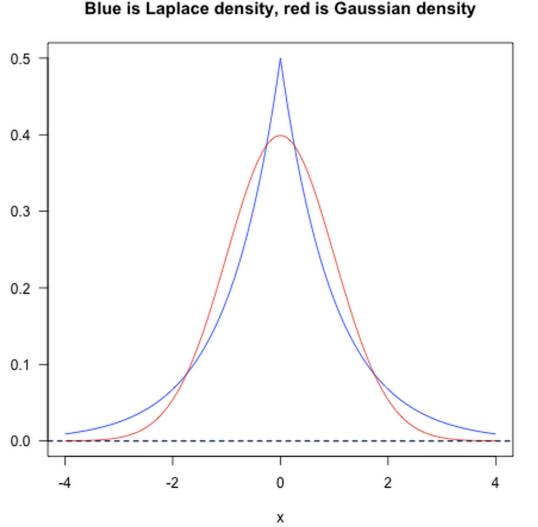
上图中L1后w取0的概率大,L2后w取0附近的概率大。
两种几何上直观的解析
L1和L2的差别,为什么一个让绝对值最小,一个让平方最小,会有那么大的差别呢?
1)下降速度:
我们知道,L1和L2都是规则化的方式,我们将权值参数以L1或者L2的方式放到代价函数里面去。然后模型就会尝试去最小化这些权值参数。而这个最小化就像一个下坡的过程,L1和L2的差别就在于这个“坡”不同,如下图:L1就是按绝对值函数的“坡”下降的,而L2是按二次函数的“坡”下降。所以实际上在0附近根据其梯度,L1的下降速度比L2的下降速度要快。
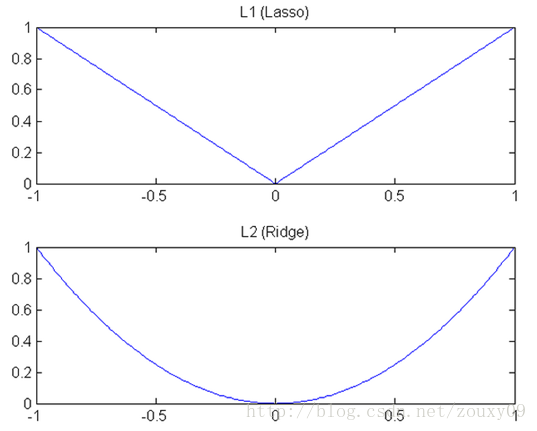
L1在江湖上人称Lasso,L2人称Ridge。
2)模型空间的限制:
实际上,对于L1和L2规则化的代价函数来说,我们可以写成以下形式:
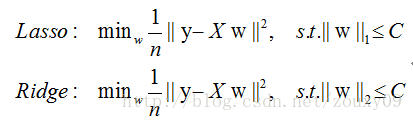
也就是说,我们将模型空间限制在w的一个L1-ball 中。为了便于可视化,我们考虑两维的情况(假设X为一个二维样本,那么要求解参数 也是二维)目标函数曲线等高线(同颜色曲线上,每一组
,
带入值都相同),凸函数3维空间里像一口锅,而约束条件则成为平面上半径为C的一个 norm ball 。等高线与 norm ball 首次相交的地方就是最优解:
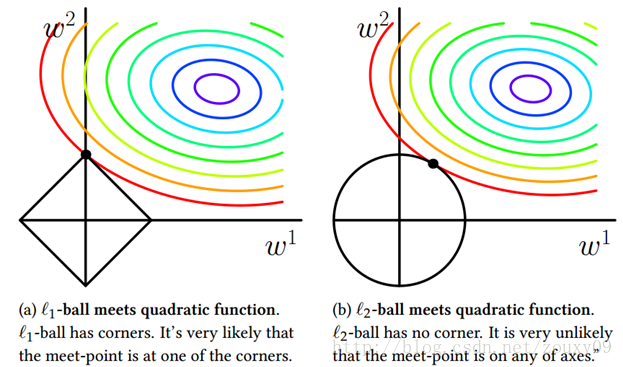
可以看到,L1-ball 与L2-ball 的不同就在于L1在和每个坐标轴相交的地方都有“角”出现,而目标函数大部分时候都会在角的地方相交。注意到在角的位置就会产生稀疏性,例如图中的相交点就有w1=0,而更高维的时候(想象一下三维的L1-ball 是什么样的?)除了角点以外,还有很多边的轮廓也是既有很大的概率成为第一次相交的地方,又会产生稀疏性。
相比之下,L2-ball 就没有这样的性质,因为没有角,所以第一次相交的地方出现在具有稀疏性的位置的概率就变得非常小了。这就从直观上来解释了为什么L1-regularization 能产生稀疏性,而L2-regularization 不行的原因了。
如果不加L1和L2正则化时,对于线性回归这种目标函数凸函数的话,我们最终的结果就是最里边的紫色的小圈圈等高线上的点(锅底)。
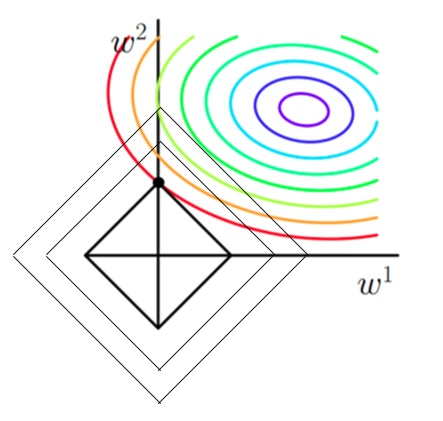
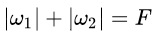 的图像是一个菱形,现在的目标是不仅是原曲线算得值要小(越来越接近中心的紫色圈圈),还要使得这个菱形越小越好(F越小越好)
的图像是一个菱形,现在的目标是不仅是原曲线算得值要小(越来越接近中心的紫色圈圈),还要使得这个菱形越小越好(F越小越好)

两种 regularization 能不能把最优的 x 变成 0,取决于原先的费用函数在 0 点处的导数。如果本来导数不为 0,那么施加 L2 regularization 后导数依然不为 0,最优的 x 也不会变成 0。而施加 L1 regularization 时,只要 regularization 项的系数 C 大于原先费用函数在 0 点处的导数的绝对值,x = 0 就会变成一个极小值点。极小值点的条件是 L1后x=0处左右两边导数异号就行。原函数用f(x)表示,则施加L1后x=0处左右两边导数分别是f'(0)-C和f'(0)+C,只要C>|f'(0)|就能保证异号。事实上 L1 regularization 会使得许多参数的最优值变成 0,这样模型就稀疏了。
因此:L1会趋向于产生少量的特征,而其他的特征都是0,而L2会选择更多的特征,这些特征都会接近于0。Lasso在特征选择时候非常有用,而Ridge就只是一种规则化而已。
转自:zouxy09
L1与L2正则(转)的更多相关文章
- 大白话5分钟带你走进人工智能-第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归
第十五节L1和L2正则几何解释和Ridge,Lasso,Elastic Net回归 上一节中我们讲解了L1和L2正则的概念,知道了L1和L2都会使不重要的维度权重下降得多,重要的维度权重下降得少,引入 ...
- 大白话5分钟带你走进人工智能-第十四节过拟合解决手段L1和L2正则
第十四节过拟合解决手段L1和L2正则 第十三节中, ...
- 【笔记】简谈L1正则项L2正则和弹性网络
L1,L2,以及弹性网络 前情提要: 模型泛化与岭回归与LASSO 正则 ridge和lasso的后面添加的式子的格式上其实和MSE,MAE,以及欧拉距离和曼哈顿距离是非常像的 虽然应用场景不同,但是 ...
- L1和L2正则
https://blog.csdn.net/jinping_shi/article/details/52433975
- L1 正则 和 L2 正则的区别
L1,L2正则都可以看成是 条件限制,即 $\Vert w \Vert \leq c$ $\Vert w \Vert^2 \leq c$ 当w为2维向量时,可以看到,它们限定的取值范围如下图: 所以它 ...
- 【机器学习】--鲁棒性调优之L1正则,L2正则
一.前述 鲁棒性调优就是让模型有更好的泛化能力和推广力. 二.具体原理 1.背景 第一个更好,因为当把测试集带入到这个模型里去.如果测试集本来是100,带入的时候变成101,则第二个模型结果偏差很大, ...
- 过拟合是什么?如何解决过拟合?l1、l2怎么解决过拟合
1. 过拟合是什么? https://www.zhihu.com/question/264909622 那个英文回答就是说h1.h2属于同一个集合,实际情况是h2比h1错误率低,你用h1来训练, ...
- 机器学习(二十三)— L0、L1、L2正则化区别
1.概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数的平方的和的开方值. 2.问题 1)实现参数的稀疏有什么好处吗? 一个好处是可以简化 ...
- L1和L2正则化(转载)
[深度学习]L1正则化和L2正则化 在机器学习中,我们非常关心模型的预测能力,即模型在新数据上的表现,而不希望过拟合现象的的发生,我们通常使用正则化(regularization)技术来防止过拟合情况 ...
随机推荐
- vue后台项目记录
1.当我们用axios进行接口访问时,必须同时使用Qs,否则后端接收不到所传的数据! npm 安装qs,然后引用 import Qs from 'qs' // 创建axios实例 const serv ...
- MongoDB 的 upsert
MongoDB 的update 方法的三个参数是upsert,这个参数是个布尔类型,默认是false.当它为true的时候,update方法会首先查找与第一个参数匹配的记录,在用第二个参数更新之,如果 ...
- requests库入门11-重定向和请求历史
默认情况下,除了head请求,requests会自动处理重定向 重定向就是会把url重新指定到另一个.比如github,使用http会自动重定向到https.一些公司也会使用网关啥的做重定向. r = ...
- with语法
上下文管理协议 要使用 with 语句,首先要明白上下文管理器这一概念.有了上下文管理器,with 语句才能工作. 下面是一组与上下文管理器和with 语句有关的概念. 上下文管理协议(Context ...
- 关于session,cookie,Cache
昨天看了<ASP.NET 页面之间传值的几种方式>之后,对session,cookie,Cache有了更近一步的了解,以下是相关的内容 一.Session 1.Session基本操作 a. ...
- SharePoint 2013 SqlException (0x80131904):找不到Windows NT 用户或组xxxx\administrator
过程描述: 在SharePoint 2013里配置创建搜索服务应用程序时报错: 配置 Search Service 应用程序期间遇到错误. System.Data.SqlClient.SqlExcep ...
- 制作ecc证书(linux命令行)
生成ECC证书.Debian:/home/test# openssl ecparam -out EccCA.key -name prime256v1 -genkeyDebian:/home/test# ...
- 判断鼠标进入容器的方向小Demo
参考资料: 贤心博客:http://sentsin.com/web/112.html, Math.atan2(y,x) 解释 :http://www.w3school.com.cn/jsref/jsr ...
- 【原创】大数据基础之Logstash(1)简介、安装、使用
Logstash 6.6.2 官方:https://www.elastic.co/products/logstash 一 简介 Centralize, Transform & Stash Yo ...
- 【原创】大叔经验分享(33)hive select count为0
hive建表后直接将数据文件拷贝到table目录下,select * 可以查到数据,但是select count(1) 一直返回0,这个是因为hive中有个配置 hive.stats.autogath ...