一脸懵逼学习Hive的使用以及常用语法(Hive语法即Hql语法)
Hive官网(HQL)语法手册(英文版):https://cwiki.apache.org/confluence/display/Hive/LanguageManual
Hive的数据存储
1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)
2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
(1):db:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
(2):table:在hdfs中表现所属db目录下一个文件夹
(3):external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径
普通表: 删除表后, hdfs上的文件都删了
External外部表删除后, hdfs上的文件没有删除, 只是把文件删除了
(4): partition:在hdfs中表现为table目录下的子目录
(5):bucket:桶, 在hdfs中表现为同一个表目录下根据hash散列之后的多个文件, 会根据不同的文件把数据放到不同的文件中
hive创建数据库操作:
hive提供database的定义,database的主要作用是提供数据分割的作用,方便数据关闭,命令如下所示:
#创建:
create (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES] (property_name=value,name=value...) #显示描述信息:
describe DATABASE|SCHEMA [extended] database_name。 #删除:
DROP DATABASE|SHCEMA [IF EXISTS] database_Name [RESTRICT|CASCADE] #使用:
user database_name;
1:Hive创建数据表:
(1)创建表(DDL操作)
建表语法如下所示:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)] ----指定表的名称和表的具体列信息。
[COMMENT table_comment] ---表的描述信息。
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] ---表的分区信息。
[CLUSTERED BY (col_name, col_name, ...)
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS] ---表的桶信息。
[ROW FORMAT row_format] ---表的数据分割信息,格式化信息。
[STORED AS file_format] ---表数据的存储序列化信息。
[LOCATION hdfs_path] ---数据存储的文件夹地址信息。
创建数据表解释说明:
1、 CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。hive中的表可以分为内部表(托管表)和外部表,区别在于,外部表的数据不是有hive进行管理的,也就是说当删除外部表的时候,外部表的数据不会从hdfs中删除。而内部表是由hive进行管理的,在删除表的时候,数据也会删除。一般情况下,我们在创建外部表的时候会将表数据的存储路径定义在hive的数据仓库路径之外。hive创建表主要有三种方式,第一种直接使用create table命令,第二种使用create table ... as select...(会产生数据)。第三种使用create table tablename like exist_tablename命令。
2、 EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。
3、 LIKE 允许用户复制现有的表结构,但是不复制数据。
4、 ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char]
[MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]
| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value, property_name=property_value, ...)]
用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。如果没有指定 ROW FORMAT 或者 ROW FORMAT DELIMITED,将会使用自带的 SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的 SerDe,Hive通过 SerDe 确定表的具体的列的数据。
5、 STORED AS
SEQUENCEFILE | TEXTFILE | RCFILE
如果文件数据是纯文本,可以使用 STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE。
6、CLUSTERED BY
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
7、create table命令介绍2
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name] table_name LIKE existing_table_orview_name ---指定要创建的表和已经存在的表或者视图的名称。
[LOCATION hdfs_path] ---数据文件存储的hdfs文件地址信息。
8、CREATE [EXTERNAL] TABLE [IF NOT EXISTS]
[db_Name] table_name ---指定要创建的表名称
...指定partition&bucket等信息,指定数据分割符号。
[AS select_statement] ---导入的数据
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User')
COMMENT 'This is the page view table'
PARTITIONED BY(dt STRING, country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS SEQUENCEFILE;
创建数据表解释如下所示:
# page_view是数据表的名称,注意hive的数据类型和java的数据类型类似,和mysql和oracle等数据库的字段类型不一致。
CREATE TABLE page_view(viewTime INT, userid BIGINT,
page_url STRING, referrer_url STRING,
ip STRING COMMENT 'IP Address of the User') #COMMENT描述,可有可无的。
COMMENT 'This is the page view table' # PARTITIONED BY指定表的分区,可以先不管。
PARTITIONED BY(dt STRING, country STRING) # ROW FORMAT DELIMITED代表一行是一条记录,是自己创建的全部字段和文件的字段对应,一行对应一条记录。
ROW FORMAT DELIMITED #FIELDS TERMINATED BY '\001'代表一行记录中的各个字段以什么隔开,方便创建的数据字段对应文件的一条记录的字段。
FIELDS TERMINATED BY '\001' # STORED AS SEQUENCEFILE;代表对应的文件类型。最常见的是SEQUENCEFILE(以键值对类型格式存储的)类型。TEXTFILE类型。
STORED AS SEQUENCEFILE;
创建如下所示,之前创建的不符合规范,删除了,然后创建一个标准的,查看一下,最后一个指定类型的,可以不指定,默认就是普通的文本类型的:
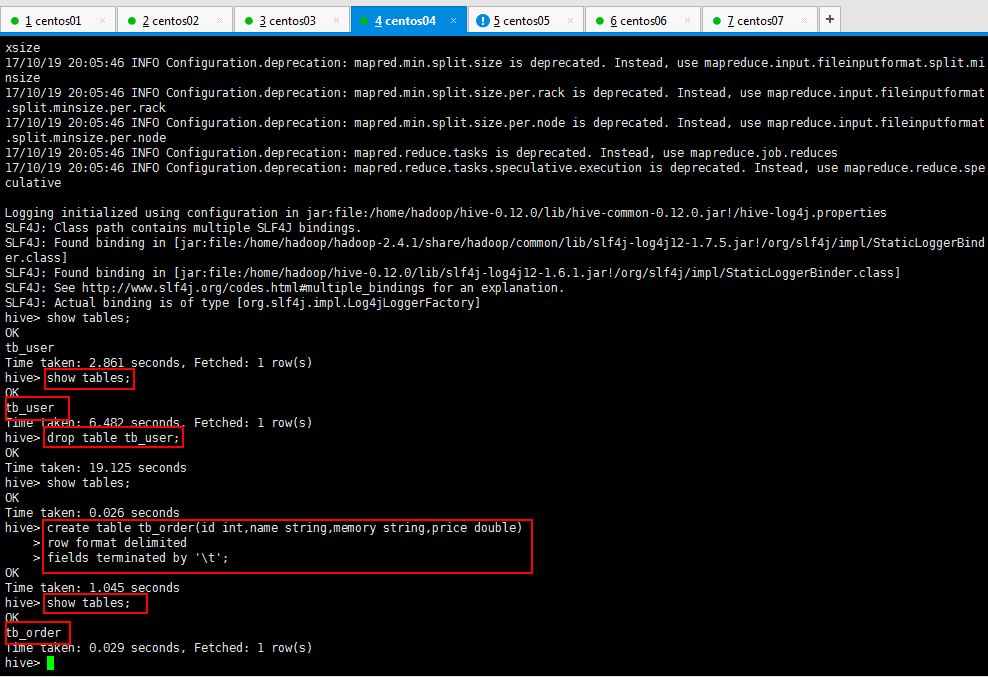
Hive将创建的数据类型写到元数据库,可以使用本地Navicat连接虚拟机的mysql查看数据;可是呢,出现下面的情况,百度呗,解决方法一大推,我贴一下子的解决方法:
错误(贴出来,方便被搜索到,哈哈哈哈。):1130 -Host '192.168.3.132' is not allowed to connect to this MySQL server
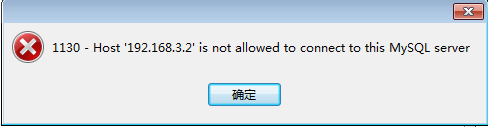
百度方法很多,但是不是每一个都适合你,我就百度了很多没解决我的问题,所以我还是贴一下我的解决方法:
如何开启MySQL的远程帐号(Navicat远程连接自己的mysql数据库):
mysql> GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
再执行下面的语句,方可立即生效(修改的权限即时生效)。
mysql> FLUSH PRIVILEGES;
上面的语句表示将 所有的 数据库的所有权限授权给 root 这个用户,允许 root 用户在 192.168.3.132 这个 IP 进行远程登陆,并设置 root 用户的密码为 123456 。
下面逐一分析所有的参数:
(1)all PRIVILEGES 表示赋予所有的权限给指定用户,这里也可以替换为赋予某一具体的权限,例如select,insert,update,delete,create,drop 等,具体权限间用“,”半角逗号分隔。
(2)*.* 表示上面的权限是针对于哪个表的,*指的是所有数据库,后面的 * 表示对于所有的表,由此可以推理出:对于全部数据库的全部表授权为“*.*”,对于某一数据库的全部表授权为“数据库名.*”,对于某一数据库的某一表授权为“数据库名.表名”。
(3)root 表示你要给哪个用户授权,这个用户可以是存在的用户,也可以是不存在的用户。
(4)192.168.3.132 表示允许远程连接的 IP 地址,如果想不限制链接的 IP 则设置为“%”即可。
(5)123456 为用户的密码。

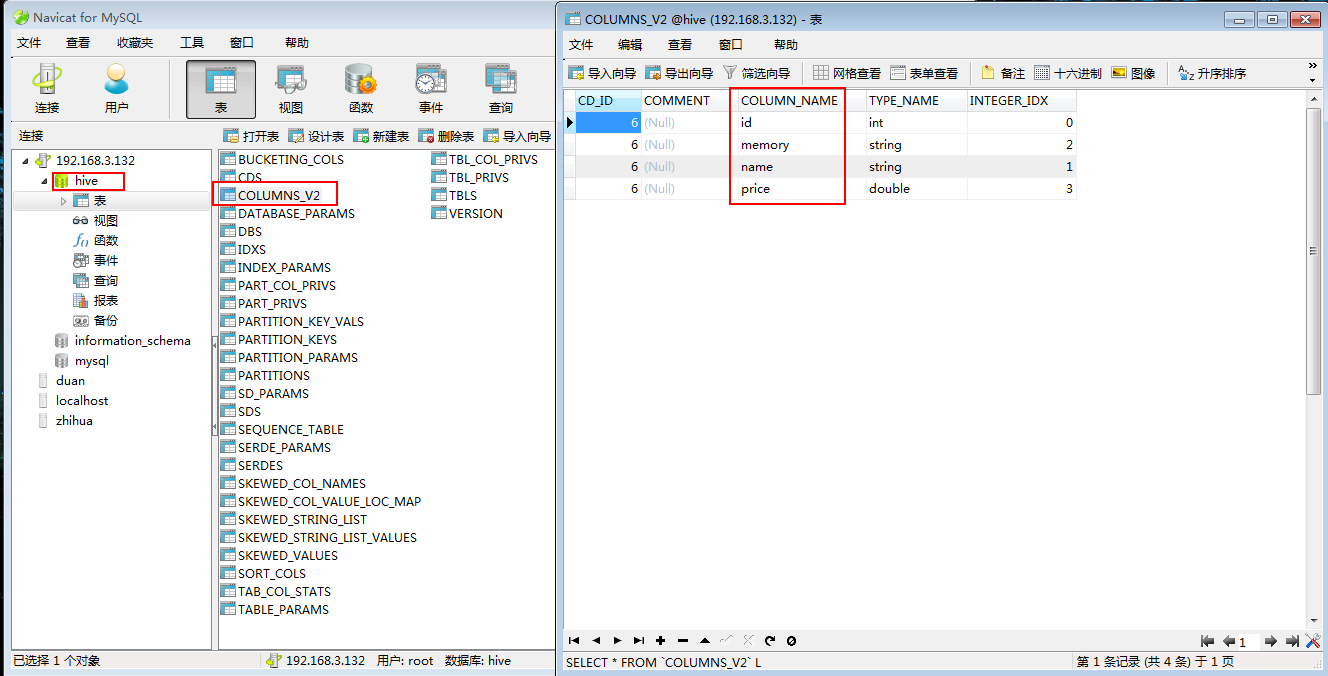
可以使用Navicat工具查看一下自己的创建的数据表(tabs是保存了创建了那些表名):

可以看看自己创建了那些列(在COLUMNS_V2数据表里面):
可以看到有DBS里面保存了哪些数据库:
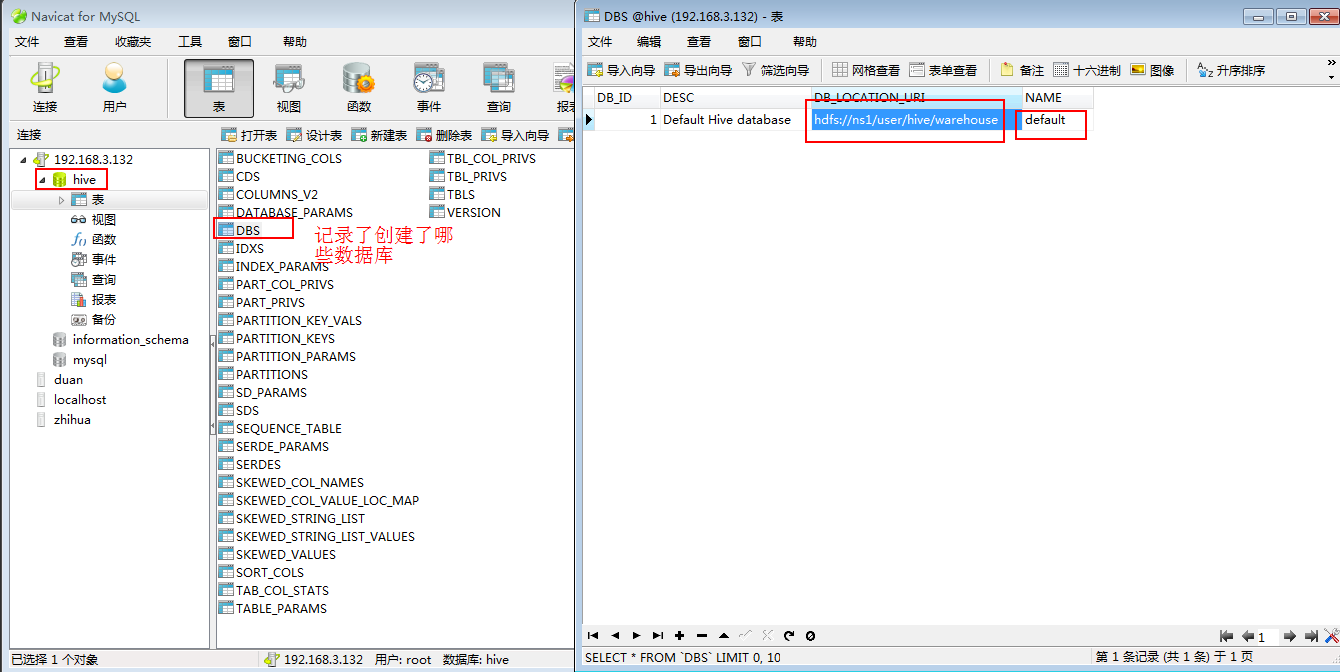
DBS数据表的DB_LOCATION_URI字段保存了路径:hdfs://ns1/user/hive/warehouse
可以去hdfs里看一眼,里面确实保存着数据库(突然发现有点意思了,只可意会,言传不了了,哈哈哈哈~~~~):
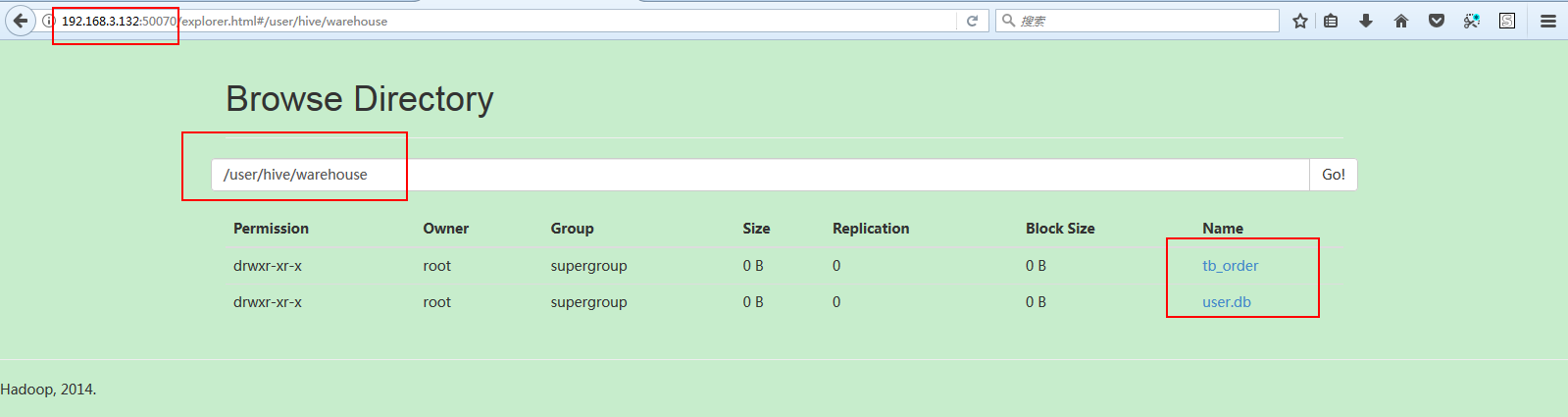
2:创建好数据表,了解了一些基本知识以后,开始插入数据,了解更多的知识:
//create & load(创建好数据表以后导入数据的操作如):
hive> create table tb_order(id int,name string,memory string,price double)
> row format delimited
> fields terminated by '\t';
//从本地导入数据到hive的表中(实质就是将文件上传到hdfs中hive管理目录下)
load data local inpath '/home/hadoop/ip.txt' into table 要导入的表名称;//从hdfs上导入数据到hive表中(实质就是将文件从原始目录移动到hive管理的目录下)
load data inpath 'hdfs://ns1/aa/bb/data.log' into table 要导入的表名称;//使用select语句来批量插入数据
insert overwrite table tab_ip_seq select * from 要导入的表名称;
自己造一组数据,保存一下,如我的,在/home/hadoop/目录下面phoneorder.data,内容如下所示:
[root@slaver3 hadoop]# vim phoneorder.data
想了一下,由于学习hive,会有很多测试数据,自己创建一个hivetest目录,专一用于存放hive测试数据,如下所示:
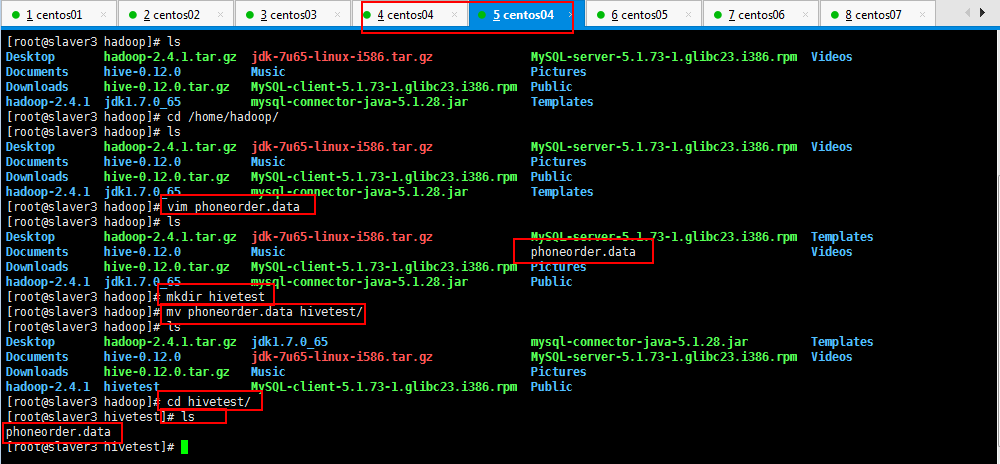
小米1 2G
小米2 4G
小米3 4G
小米4 6G
小米5 6G
小米6 8G
小米7 8G
然后开始导入数据(或者使用hadoop的命令将正确格式数据上传到对应的目录),如下所示:
hive> load data local inpath '/home/hadoop/hivetest/phoneorder.data' into table tb_order;
或者[root@slaver3 hivetest]# hadoop fs -put phoneorder2.data /user/hive/warehouse/tb_order

可以去hdfs看到数据已经上传成功了,如下所示,可以看到一些简单信息:

下面可以使用hive的查询语句进行查询操作;
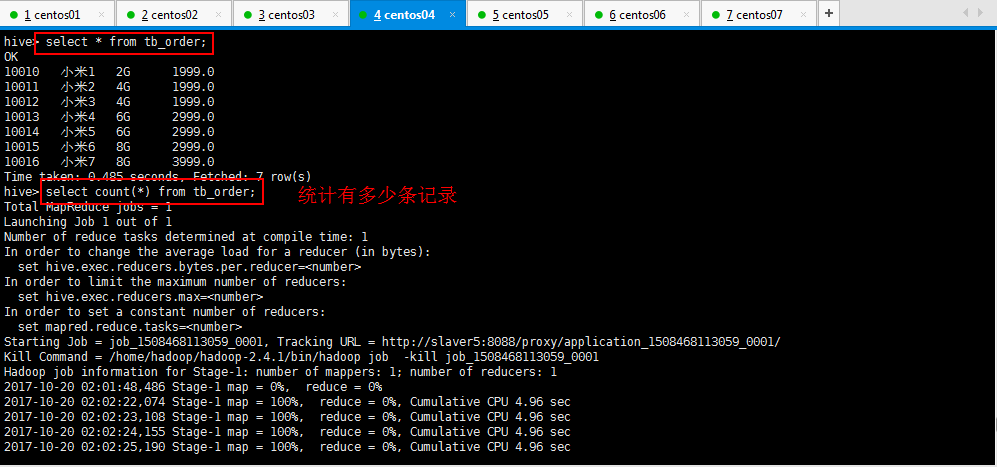
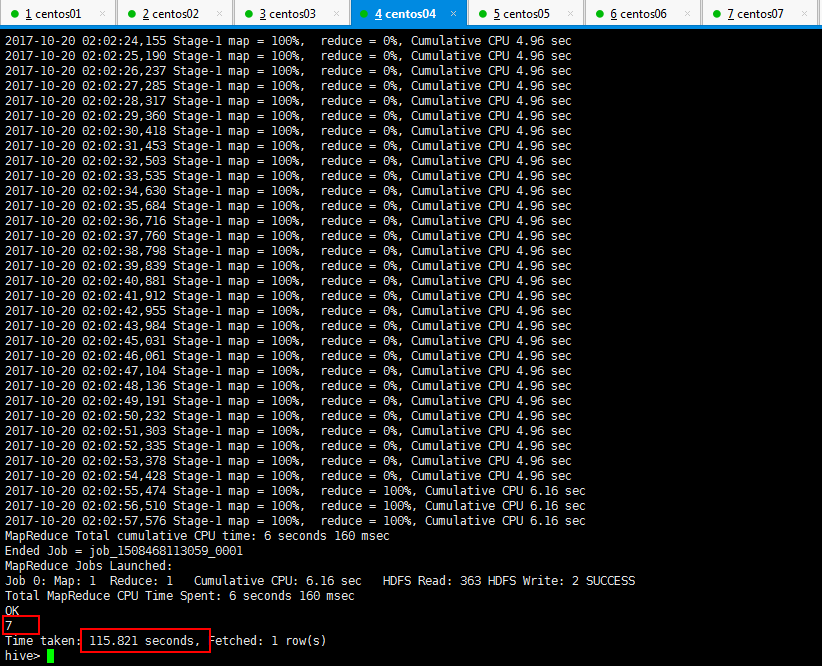
3:Hive的查询语句进行查询操作,统计多少条记录的时候发现很慢很慢,那是启动集群的时候就很慢,最后可以看到一共7条记录,用了一百多秒:
4:external外部表,优点,做数据分析的时候,有的数据是业务系统产生的,或者读或者写这个文件,如果的默认的路径,即在配置文件里面写好了,如果做分析的时候数据表导数据,如果将数据表移动了,,业务系统再读这个文件就不存在了,这个时候使用外部表,外部表不要求数据非到默认的路径下面去,数据可以摆放到任意的hdfs路径下面;
创建外部表的语法:
//external外部表
CREATE EXTERNAL TABLE tab_ip_ext(id int, name string,
ip STRING,
country STRING)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS TEXTFILE
LOCATION '/external/user';
//external外部表
//使用关键字EXTERNAL
CREATE EXTERNAL TABLE 数据表名称(id int, name string,
ip STRING,
country STRING)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE #location指定所在的位置:切记,重点。
LOCATION '/external/user';
然后自己创建一个文件在hdfs,上传一个文件,然后创建一个扩展表和这个hdfs的文件关联起来:
[root@slaver3 hadoop]# cd /home/hadoop/hivetest/
[root@slaver3 hivetest]# cp phoneorder.data phoneorder4.data
[root@slaver3 hivetest]# hadoop fs -mkdir /hive_ext
[root@slaver3 hivetest]# hadoop fs -put phoneorder4.data /hive_ext
然后创建一个扩展表和这个hdfs的文件关联起来:
hive> create external table tb_order_ext(id int,name string,memory string,price double)
> row format delimited
> fields terminated by '\t'
> location '/hive_ext';
具体操作如下所示:
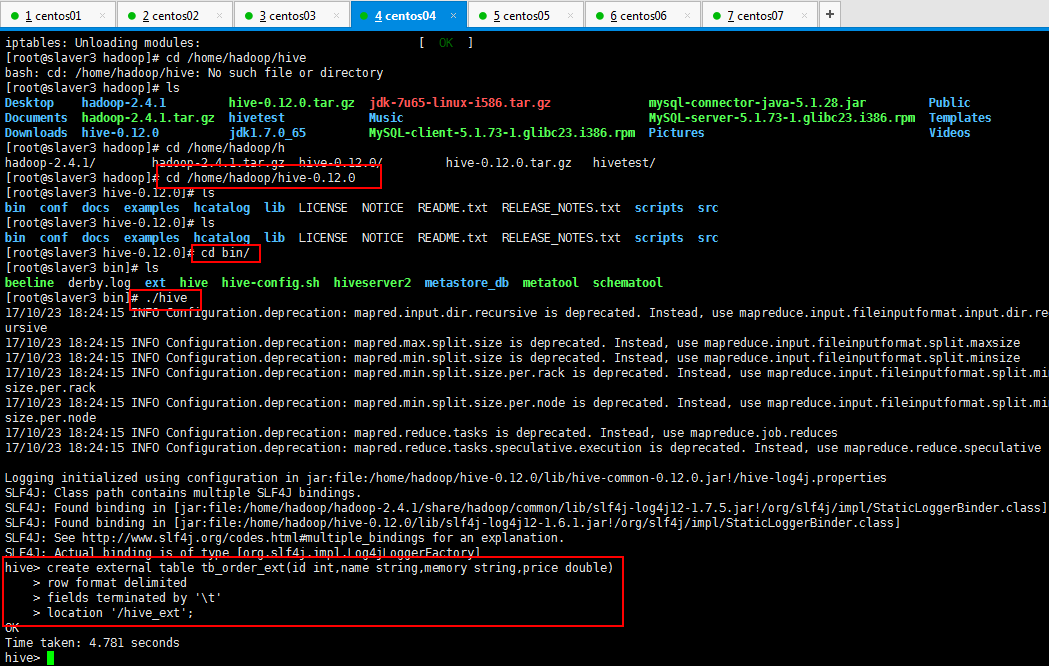
查看一下是否存在数据:
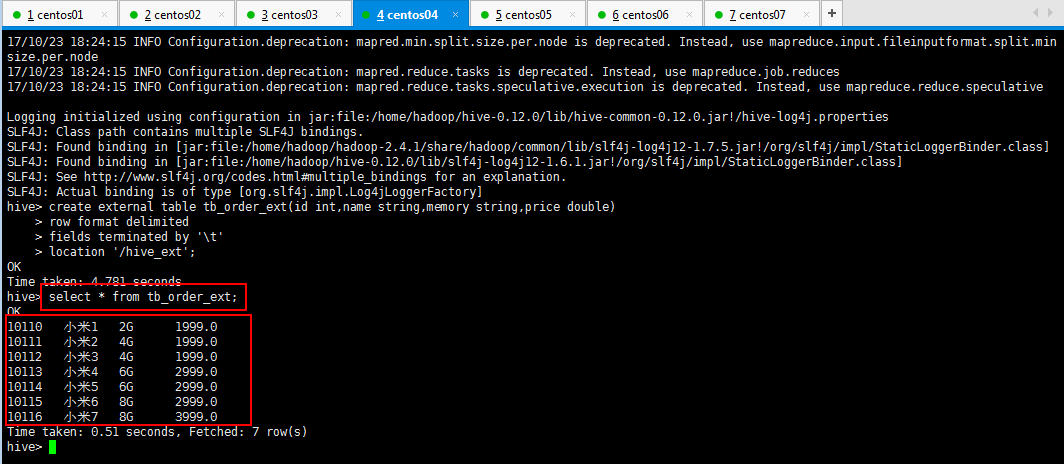
可以查看扩展数据表的数据表结构,如下所示:
hive> desc extended tb_log;
OK
logid int
logname string Detailed Table Information Table(tableName:tb_log, dbName:test, owner:root, createTime:, lastAccessTime:, retention:, sd:StorageDescriptor(cols:[FieldSchema(name:logid, type:int, comment:null), FieldSchema(name:logname, type:string, comment:null)], location:hdfs://master:9000/tb_log_file, inputFormat:org.apache.hadoop.mapred.TextInputFormat, outputFormat:org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat, compressed:false, numBuckets:-1, serdeInfo:SerDeInfo(name:null, serializationLib:org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe, parameters:{serialization.format=,, field.delim=,}), bucketCols:[], sortCols:[], parameters:{}, skewedInfo:SkewedInfo(skewedColNames:[], skewedColValues:[], skewedColValueLocationMaps:{}), storedAsSubDirectories:false), partitionKeys:[], parameters:{EXTERNAL=TRUE, transient_lastDdlTime=1512892171}, viewOriginalText:null, viewExpandedText:null, tableType:EXTERNAL_TABLE)
Time taken: 0.121 seconds, Fetched: row(s)
hive>
格式化查看扩展表的数据表结构:
hive> desc formatted tb_log;
OK
# col_name data_type comment logid int
logname string # Detailed Table Information
Database: test
Owner: root
CreateTime: Sat Dec :: PST
LastAccessTime: UNKNOWN
Protect Mode: None
Retention:
Location: hdfs://master:9000/tb_log_file
Table Type: EXTERNAL_TABLE
Table Parameters:
EXTERNAL TRUE
transient_lastDdlTime # Storage Information
SerDe Library: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe
InputFormat: org.apache.hadoop.mapred.TextInputFormat
OutputFormat: org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat
Compressed: No
Num Buckets: -
Bucket Columns: []
Sort Columns: []
Storage Desc Params:
field.delim ,
serialization.format ,
Time taken: 0.577 seconds, Fetched: row(s)
hive>
5:创建分区表(分区的好处是可以帮助你统计的时候少统计一些数据,加速数据统计):
hive> create table tb_part(sNo int,sName string,sAge int,sDept string)
> partition //拿不准的单词,可以tab一下进行提示,并不会影响你创建表;谢谢
partition partitioned partitions
> partitioned by (part string)
> row format delimited
> fields terminated by ','
> stored as textfile;
OK
Time taken: 0.351 seconds
并且将本地的数据上传到hive上面:
hive> load data local inpath '/home/hadoop/data_hadoop/tb_part' overwrite into table tb_part partition (part='20171210');
Loading data to table test.tb_part partition (part=)
Partition test.tb_part{part=} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
OK
Time taken: 2.984 seconds
hive> load data local inpath '/home/hadoop/data_hadoop/tb_part' overwrite into table tb_part partition (part='20171211');
Loading data to table test.tb_part partition (part=)
Partition test.tb_part{part=} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
OK
Time taken: 0.566 seconds
hive> show par
parse_url( parse_url_tuple( partition partitioned partitions
hive> show partition
partition partitioned partitions
hive> show partitions tb_part;
OK
part=
part=
Time taken: 0.119 seconds, Fetched: row(s)
hive>
6:创建带桶的数据表,然后将本地创建好测试数据上传到hive上面:
#设置变量,设置分桶为true, 设置reduce数量是分桶的数量个数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces=4;
hive> create table if not exists tb_stud(id int,name string,age int)
> partitioned by(clus string)
> clustered by(id) sorted by(age) into buckets #分桶,根据id进行分桶,分成2个桶。
> row format delimited
> fields terminated by ',';
OK
Time taken: 0.194 seconds
hive> load data local inpath '/home/hadoop/data_hadoop/tb_clustered' overwrite into table tb_stud partition (clus='20171211');
Loading data to table test.tb_stud partition (clus=)
Partition test.tb_stud{clus=} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
OK
Time taken: 0.594 seconds
hive>
7:修改表,增加/删除分区
语法结构
ALTER TABLE table_name ADD [IF NOT EXISTS] partition_spec [ LOCATION 'location1' ] partition_spec [ LOCATION 'location2' ] ...
partition_spec:
: PARTITION (partition_col = partition_col_value, partition_col = partiton_col_value, ...)ALTER TABLE table_name DROP partition_spec, partition_spec,...
具体实例如下所示:
alter table student_p add partition(part='a') partition(part='b');
修改分区和删除分区的操作:
hive> alter table tb_stud add partition(clus='20171215') location '/user/hive/warehouse/test.db' partition(clus='20171216');
OK
Time taken: 1.289 seconds
hive> alter table tb_stud add partition
partition partitioned partitions
hive> alter table tb_stud add partition(clus='20171217');
OK
Time taken: 0.097 seconds
hive> dfs -ls /user/hive/warehouse/test.db
> ;
Found items
drwxr-xr-x - root supergroup -- : /user/hive/warehouse/test.db/tb_log
drwxr-xr-x - root supergroup -- : /user/hive/warehouse/test.db/tb_part
drwxr-xr-x - root supergroup -- : /user/hive/warehouse/test.db/tb_stud
drwxr-xr-x - root supergroup -- : /user/hive/warehouse/test.db/tb_user
hive> show partitions tb_stud;
OK
clus=
clus=
clus=
clus=
Time taken: 0.119 seconds, Fetched: row(s)
hive> alter table tb_stud drop partition
partition partitioned partitions
hive> alter table tb_stud drop partition(clus='20171217');
Dropped the partition clus=
OK
Time taken: 1.433 seconds
hive> show partitions tb_stud;
OK
clus=
clus=
clus=
Time taken: 0.092 seconds, Fetched: row(s)
hive> alter table tb_stud drop partition(clus='20171215'),partition(clus='20171216');
Dropped the partition clus=
Dropped the partition clus=
OK
Time taken: 0.271 seconds
hive> show partitions tb_stud;
OK
clus=
Time taken: 0.094 seconds, Fetched: row(s)
hive>
8:重命名表:
语法结构
ALTER TABLE table_name RENAME TO new_table_name
具体实例 ,如下所示:
hive> show tables;
OK
tb_log
tb_part
tb_stud
tb_user
Time taken: 0.026 seconds, Fetched: row(s)
hive> alter table tb_user rename to tb_user_copy;
OK
Time taken: 0.19 seconds
hive> show tables;
OK
tb_log
tb_part
tb_stud
tb_user_copy
Time taken: 0.05 seconds, Fetched: row(s)
hive>
9:增加/更新列
语法结构
ALTER TABLE table_name ADD|REPLACE COLUMNS (col_name data_type [COMMENT col_comment], ...)注:ADD是代表新增一字段,字段位置在所有列后面(partition列前),REPLACE则是表示替换表中所有字段。
ALTER TABLE table_name CHANGE [COLUMN] col_old_name col_new_name column_type [COMMENT col_comment] [FIRST|AFTER column_name]
具体实例如下所示:
hive> desc tb_user;
OK
id int
name string
Time taken: 0.148 seconds, Fetched: row(s)
hive> alter table tb_user add columns(age int);
OK
Time taken: 0.238 seconds
hive> desc tb_user;
OK
id int
name string
age int
Time taken: 0.088 seconds, Fetched: row(s)
hive> alter table tb_user replace columns(id int,name string,birthday string);
OK
Time taken: 0.132 seconds
hive> desc tb_user;
OK
id int
name string
birthday string
Time taken: 0.083 seconds, Fetched: row(s)
hive>
10:Load,操作只是单纯的复制/移动操作,DML操作
语法结构
LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO
TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)]说明:
1、Load 操作只是单纯的复制/移动操作,将数据文件移动到 Hive 表对应的位置。
2、filepath:
相对路径,例如:project/data1
绝对路径,例如:/user/hive/project/data1
包含模式的完整 URI,列如:
hdfs://namenode:9000/user/hive/project/data1
3、LOCAL关键字
如果指定了 LOCAL, load 命令会去查找本地文件系统中的 filepath。
如果没有指定 LOCAL 关键字,则根据inpath中的uri[如果指定了 LOCAL,那么:
load 命令会去查找本地文件系统中的 filepath。如果发现是相对路径,则路径会被解释为相对于当前用户的当前路径。
load 命令会将 filepath中的文件复制到目标文件系统中。目标文件系统由表的位置属性决定。被复制的数据文件移动到表的数据对应的位置。
如果没有指定
LOCAL 关键字,如果 filepath 指向的是一个完整的 URI,hive 会直接使用这个 URI。 否则:如果没有指定 schema
或者 authority,Hive 会使用在 hadoop 配置文件中定义的 schema 和
authority,fs.default.name 指定了 Namenode 的 URI。
如果路径不是绝对的,Hive 相对于/user/进行解释。
Hive 会将 filepath 中指定的文件内容移动到 table (或者 partition)所指定的路径中。]查找文件4、OVERWRITE 关键字
如果使用了 OVERWRITE 关键字,则目标表(或者分区)中的内容会被删除,然后再将 filepath 指向的文件/目录中的内容添加到表/分区中。
如果目标表(分区)已经有一个文件,并且文件名和 filepath 中的文件名冲突,那么现有的文件会被新文件所替代。
11:Hive的insert操作:
Insert
将查询结果插入Hive表
语法结构
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statementMultiple inserts:
FROM from_statement
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1
[INSERT OVERWRITE TABLE tablename2 [PARTITION ...] select_statement2] ...Dynamic partition inserts:
INSERT OVERWRITE TABLE tablename PARTITION (partcol1[=val1], partcol2[=val2] ...) select_statement FROM from_statement
<!--基本模式插入。-->
hive> load data local inpath '/home/hadoop/data_hadoop/tb_stud' overwrite into table tb_stud partition (clus='');
Loading data to table test.tb_stud partition (clus=)
Partition test.tb_stud{clus=} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
OK
Time taken: 4.336 seconds
hive> select * from tb_stud where clus='';
OK
张三 NULL
lisi NULL
wangwu NULL
zhaoliu NULL
libai NULL
Time taken: 0.258 seconds, Fetched: row(s)
hive> insert overwrite table tb_stud partition(clus='')
> select id,name,age from tb_stud where clus='';
Query ID = root_20171210012734_721f76d9-f670-42ad-bf68-bfb94baf5cda
Total jobs =
Launching Job out of
Number of reduce tasks is set to since there's no reduce operator
Starting Job = job_1512874725514_0005, Tracking URL = http://master:8088/proxy/application_1512874725514_0005/
Kill Command = /home/hadoop/soft/hadoop-2.6./bin/hadoop job -kill job_1512874725514_0005
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 1.44 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1512874725514_0005
Stage- is selected by condition resolver.
Stage- is filtered out by condition resolver.
Stage- is filtered out by condition resolver.
Moving data to: hdfs://master:9000/user/hive/warehouse/test.db/tb_stud/clus=20171218/.hive-staging_hive_2017-12-10_01-27-34_894_112189266881641464-1/-ext-10000
Loading data to table test.tb_stud partition (clus=)
Partition test.tb_stud{clus=} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
MapReduce Jobs Launched:
Stage-Stage-: Map: Cumulative CPU: 1.44 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: seconds msec
OK
Time taken: 64.66 seconds
hive> select * from tb_stud where clus='';
OK
张三 NULL
lisi NULL
wangwu NULL
zhaoliu NULL
libai NULL
Time taken: 0.085 seconds, Fetched: row(s)
hive> <!--多插入模式。-->
hive> show partitions tb_stud;
OK
clus=
clus=
Time taken: 0.153 seconds, Fetched: row(s)
hive> alter table tb_stud add partition(clus='');
OK
Time taken: 0.143 seconds
hive> alter table tb_stud add partition(clus='');
OK
Time taken: 0.399 seconds
hive> alter table tb_stud add partition(clus='');
OK
Time taken: 0.139 seconds
hive> from tb_stud
> insert overwrite table tb_stud partition(clus='')
> select id,name,age where clus=''
> insert overwrite table tb_stud partition(clus='')
> select id,name,age where clus='';
Query ID = root_20171210013655_0c4a1d78-88e2-4de0-99ca-074c9eed81a4
Total jobs =
Launching Job out of
Number of reduce tasks is set to since there's no reduce operator
Starting Job = job_1512874725514_0007, Tracking URL = http://master:8088/proxy/application_1512874725514_0007/
Kill Command = /home/hadoop/soft/hadoop-2.6./bin/hadoop job -kill job_1512874725514_0007
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 1.46 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1512874725514_0007
Stage- is selected by condition resolver.
Stage- is filtered out by condition resolver.
Stage- is filtered out by condition resolver.
Stage- is selected by condition resolver.
Stage- is filtered out by condition resolver.
Stage- is filtered out by condition resolver.
Moving data to: hdfs://master:9000/user/hive/warehouse/test.db/tb_stud/clus=20171213/.hive-staging_hive_2017-12-10_01-36-55_602_8039889333976698612-1/-ext-10000
Moving data to: hdfs://master:9000/user/hive/warehouse/test.db/tb_stud/clus=20171214/.hive-staging_hive_2017-12-10_01-36-55_602_8039889333976698612-1/-ext-10002
Loading data to table test.tb_stud partition (clus=)
Loading data to table test.tb_stud partition (clus=)
Partition test.tb_stud{clus=} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
Partition test.tb_stud{clus=} stats: [numFiles=, numRows=, totalSize=, rawDataSize=]
MapReduce Jobs Launched:
Stage-Stage-: Map: Cumulative CPU: 1.57 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: seconds msec
OK
Time taken: 81.536 seconds
hive> select * from tb_stud where clus='';
OK
张三 NULL
lisi NULL
wangwu NULL
zhaoliu NULL
libai NULL
Time taken: 0.138 seconds, Fetched: row(s)
hive> select * from tb_stud where clus='';
OK
张三 NULL
lisi NULL
wangwu NULL
zhaoliu NULL
libai NULL
Time taken: 0.075 seconds, Fetched: row(s)
hive> <!--自动分区模式。-->
12:导出表数据
语法结构
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 SELECT ... FROM ...multiple inserts:
FROM from_statement
INSERT OVERWRITE [LOCAL] DIRECTORY directory1 select_statement1
[INSERT OVERWRITE [LOCAL] DIRECTORY directory2 select_statement2] ...具体实例
、导出文件到本地。
说明:
数据写入到文件系统时进行文本序列化,且每列用^A来区分,\n为换行符。用more命令查看时不容易看出分割符,可以使用: sed -e 's/\x01/|/g' filename[]来查看。 hive> insert overwrite local directory '/home/hadoop/data_hadoop/get_tb_stud'
> select * from tb_stud;
Query ID = root_20171210014640_4c499323-760e--946b-5ffad8fb3789
Total jobs =
Launching Job out of
Number of reduce tasks is set to since there's no reduce operator
Starting Job = job_1512874725514_0008, Tracking URL = http://master:8088/proxy/application_1512874725514_0008/
Kill Command = /home/hadoop/soft/hadoop-2.6./bin/hadoop job -kill job_1512874725514_0008
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 7.13 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1512874725514_0008
Copying data to local directory /home/hadoop/data_hadoop/get_tb_stud
Copying data to local directory /home/hadoop/data_hadoop/get_tb_stud
MapReduce Jobs Launched:
Stage-Stage-: Map: Cumulative CPU: 7.13 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: seconds msec
OK
Time taken: 47.258 seconds
hive> <!--导出数据到HDFS。-->
hive> insert overwrite directory 'hdfs://192.168.199.130:9000/user/hive/warehouse/tb_stud_get'
> select * from tb_stud;
Query ID = root_20171210015229_b0a323b1-b1dc-4f31-b932-cb8126bac2ff
Total jobs =
Launching Job out of
Number of reduce tasks is set to since there's no reduce operator
Starting Job = job_1512874725514_0009, Tracking URL = http://master:8088/proxy/application_1512874725514_0009/
Kill Command = /home/hadoop/soft/hadoop-2.6./bin/hadoop job -kill job_1512874725514_0009
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 2.65 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1512874725514_0009
Stage- is filtered out by condition resolver.
Stage- is selected by condition resolver.
Stage- is filtered out by condition resolver.
Launching Job out of
Number of reduce tasks is set to since there's no reduce operator
Starting Job = job_1512874725514_0010, Tracking URL = http://master:8088/proxy/application_1512874725514_0010/
Kill Command = /home/hadoop/soft/hadoop-2.6./bin/hadoop job -kill job_1512874725514_0010
Hadoop job information for Stage-: number of mappers: ; number of reducers:
-- ::, Stage- map = %, reduce = %
-- ::, Stage- map = %, reduce = %, Cumulative CPU 1.43 sec
MapReduce Total cumulative CPU time: seconds msec
Ended Job = job_1512874725514_0010
Moving data to: hdfs://192.168.199.130:9000/user/hive/warehouse/tb_stud_get
MapReduce Jobs Launched:
Stage-Stage-: Map: Cumulative CPU: 2.65 sec HDFS Read: HDFS Write: SUCCESS
Stage-Stage-: Map: Cumulative CPU: 1.43 sec HDFS Read: HDFS Write: SUCCESS
Total MapReduce CPU Time Spent: seconds msec
OK
Time taken: 202.508 seconds
hive> dfs -ls /user/hive/warehouse/tb_stud_get;
Found items
-rwxr-xr-x root supergroup -- : /user/hive/warehouse/tb_stud_get/000000_0
hive>
13:SELECT,基本的Select操作
语法结构
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
]
[LIMIT number]注:1、order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
2、sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,则sort by只保证每个reducer的输出有序,不保证全局有序。
3、distribute by根据distribute by指定的内容将数据分到同一个reducer。
4、Cluster by 除了具有Distribute by的功能外,还会对该字段进行排序。因此,常常认为cluster by = distribute by + sort by5、分桶表的最大的意思:最大的作用是用来提高join操作的效率;
6、思考这个问题:
select a.id,a.name,b.addr from a join b on a.id = b.id;
如果a表和b表已经是分桶表,而且分桶的字段是id字段
做这个join操作时,还需要全表做笛卡尔积吗?答案:不需要,因为相同的id就在同一个桶里面。
14:删除hive的内部表和外部表的区别:
删除内部表是将元数据(TABL表),以及hdfs上面的文件夹以及文件一起删除;
删除外部表只是删除元数据(TABL表),hdfs上面的文件夹以及文件不删除。
15:创建一个新表根据老表(用来做一些中间结果的存储,再做后一步的处理,):
注意:用于创建一些临时表存储中间结果;
hive> create table tb_order_new
> as
> select id,name,memory,price
> from tb_order;

16:insert from select 通过select语句批量插入数据到别的表(用于向临时表中追加中间结果数据):
//创建一个表
create table tab_ip_like like tab_ip; //批量插入数据,批量插入已经存在表
insert overwrite table tab_ip_like
select * from tab_ip;
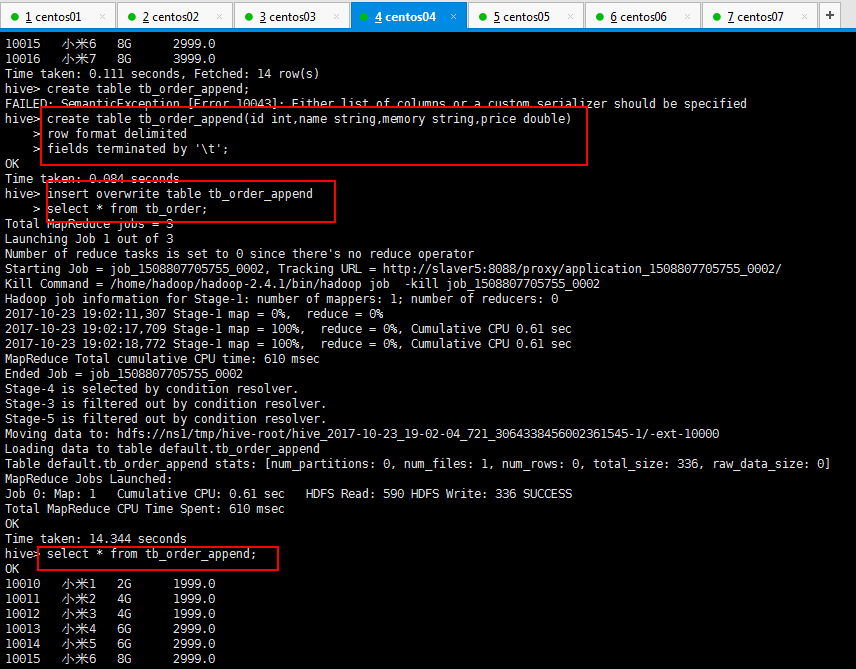
hive> create table tb_order_append(id int,name string,memory string,price double)
> row format delimited
> fields terminated by '\t'; hive> insert overwrite table tb_order_append
> select * from tb_order; hive> select * from tb_order_append;
操作如下所示:
17:PARTITION ,分区表(partition),分区统计,可以对数据操作加快速度:
查询分区:hive> show partitions part; #show partitions 数据表名称;
删除分区:hive> alter table part drop partition(date='20180512');
添加分区:hive> alter table part add partition(date='20180512');
hive> create table tb_order_part(id int,name string,memory string,salary double)
> partitioned by (month string)
> row format delimited
> fields terminated by '\t';
OK
Time taken: 0.13 seconds
然后将数据导入这个新建的分区里面(所谓分区就是在文件夹下面创建一个文件夹,把数据放到这个文件夹下面),如下所示:
hive> load data local inpath '/home/hadoop/hivetest/phoneorder.data' into table tb_order_part partition(month='201401');
hive> load data local inpath '/home/hadoop/hivetest/phoneorder2.data' into table tb_order_part partition(month='201402');

可以根据分区查询一下数据:
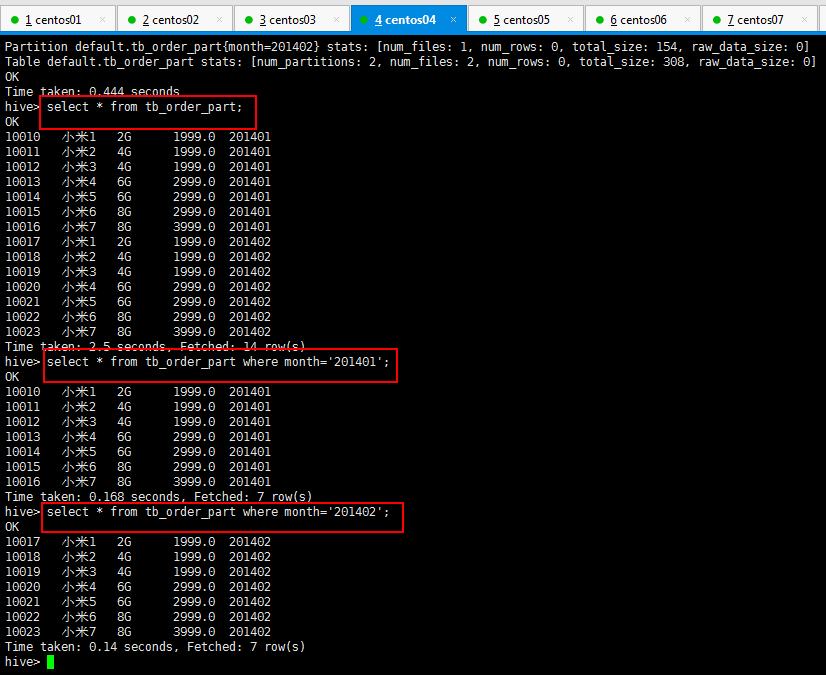
18:write to hdfs,将结果写入到hdfs的文件中:
hive> insert overwrite local directory '/home/hadoop/hivetest/test.txt'
> select * from tb_order_part
> where month="201401";
19:Hive的Join使用:
语法结构
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
Hive 支持等值连接(equality joins)、外连接(outer joins)和(left/right joins)。Hive 不支持非等值的连接,因为非等值连接非常难转化到 map/reduce 任务。
另外,Hive 支持多于 个表的连接。
写 join 查询时,需要注意几个关键点:
. 只支持等值join
例如:
SELECT a.* FROM a JOIN b ON (a.id = b.id)
SELECT a.* FROM a JOIN b
ON (a.id = b.id AND a.department = b.department)
是正确的,然而:
SELECT a.* FROM a JOIN b ON (a.id>b.id)
是错误的。 . 可以 join 多于 个表。
例如
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
如果join中多个表的 join key 是同一个,则 join 会被转化为单个 map/reduce 任务,例如:
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c
ON (c.key = b.key1)
被转化为单个 map/reduce 任务,因为 join 中只使用了 b.key1 作为 join key。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1)
JOIN c ON (c.key = b.key2)
而这一 join 被转化为 个 map/reduce 任务。因为 b.key1 用于第一次 join 条件,而 b.key2 用于第二次 join。 .join 时,每次 map/reduce 任务的逻辑:
reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统。这一实现有助于在 reduce 端减少内存的使用量。实践中,应该把最大的那个表写在最后(否则会因为缓存浪费大量内存)。例如:
SELECT a.val, b.val, c.val FROM a
JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
所有表都使用同一个 join key(使用 次 map/reduce 任务计算)。Reduce 端会缓存 a 表和 b 表的记录,然后每次取得一个 c 表的记录就计算一次 join 结果,类似的还有:
SELECT a.val, b.val, c.val FROM a
JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
这里用了 次 map/reduce 任务。第一次缓存 a 表,用 b 表序列化;第二次缓存第一次 map/reduce 任务的结果,然后用 c 表序列化。 .LEFT,RIGHT 和 FULL OUTER 关键字用于处理 join 中空记录的情况
例如:
SELECT a.val, b.val FROM
a LEFT OUTER JOIN b ON (a.key=b.key)
对应所有 a 表中的记录都有一条记录输出。输出的结果应该是 a.val, b.val,当 a.key=b.key 时,而当 b.key 中找不到等值的 a.key 记录时也会输出:
a.val, NULL
所以 a 表中的所有记录都被保留了;
“a RIGHT OUTER JOIN b”会保留所有 b 表的记录。 Join 发生在 WHERE 子句之前。如果你想限制 join 的输出,应该在 WHERE 子句中写过滤条件——或是在 join 子句中写。这里面一个容易混淆的问题是表分区的情况:
SELECT a.val, b.val FROM a
LEFT OUTER JOIN b ON (a.key=b.key)
WHERE a.ds='2009-07-07' AND b.ds='2009-07-07'
会 join a 表到 b 表(OUTER JOIN),列出 a.val 和 b.val 的记录。WHERE 从句中可以使用其他列作为过滤条件。但是,如前所述,如果 b 表中找不到对应 a 表的记录,b 表的所有列都会列出 NULL,包括 ds 列。也就是说,join 会过滤 b 表中不能找到匹配 a 表 join key 的所有记录。这样的话,LEFT OUTER 就使得查询结果与 WHERE 子句无关了。解决的办法是在 OUTER JOIN 时使用以下语法:
SELECT a.val, b.val FROM a LEFT OUTER JOIN b
ON (a.key=b.key AND
b.ds='2009-07-07' AND
a.ds='2009-07-07')
这一查询的结果是预先在 join 阶段过滤过的,所以不会存在上述问题。这一逻辑也可以应用于 RIGHT 和 FULL 类型的 join 中。 Join 是不能交换位置的。无论是 LEFT 还是 RIGHT join,都是左连接的。
SELECT a.val1, a.val2, b.val, c.val
FROM a
JOIN b ON (a.key = b.key)
LEFT OUTER JOIN c ON (a.key = c.key)
先 join a 表到 b 表,丢弃掉所有 join key 中不匹配的记录,然后用这一中间结果和 c 表做 join。这一表述有一个不太明显的问题,就是当一个 key 在 a 表和 c 表都存在,但是 b 表中不存在的时候:整个记录在第一次 join,即 a JOIN b 的时候都被丢掉了(包括a.val1,a.val2和a.key),然后我们再和 c 表 join 的时候,如果 c.key 与 a.key 或 b.key 相等,就会得到这样的结果:NULL, NULL, NULL, c.val
长风破浪会有时,腰酸背痛颈椎疼。~~~~~
一脸懵逼学习Hive的使用以及常用语法(Hive语法即Hql语法)的更多相关文章
- 一脸懵逼学习Hive的元数据库Mysql方式安装配置
1:要想学习Hive必须将Hadoop启动起来,因为Hive本身没有自己的数据管理功能,全是依赖外部系统,包括分析也是依赖MapReduce: 2:七个节点跑HA集群模式的: 第一步:必须先将Zook ...
- 一脸懵逼学习Hive(数据仓库基础构架)
Hive是什么?其体系结构简介*Hive的安装与管理*HiveQL数据类型,表以及表的操作*HiveQL查询数据***Hive的Java客户端** Hive的自定义函数UDF* 1:什么是Hive(一 ...
- 一脸懵逼学习Hadoop中的序列化机制——流量求和统计MapReduce的程序开发案例——流量求和统计排序
一:序列化概念 序列化(Serialization)是指把结构化对象转化为字节流.反序列化(Deserialization)是序列化的逆过程.即把字节流转回结构化对象.Java序列化(java.io. ...
- 一脸懵逼学习Hive的安装(将sql语句翻译成MapReduce程序的一个工具)
Hive只在一个节点上安装即可: 1.上传tar包:这个上传就不贴图了,贴一下上传后的,看一下虚拟机吧: 2.解压操作: [root@slaver3 hadoop]# tar -zxvf hive-0 ...
- 一脸懵逼学习基于CentOs的Hadoop集群安装与配置
1:Hadoop分布式计算平台是由Apache软件基金会开发的一个开源分布式计算平台.以Hadoop分布式文件系统(HDFS)和MapReduce(Google MapReduce的开源实现)为核心的 ...
- 一脸懵逼学习Storm---(一个开源的分布式实时计算系统)
Storm的官方网址:http://storm.apache.org/index.html 1:什么是Storm? Storm是一个开源的分布式实时计算系统,可以简单.可靠的处理大量的数据流.被称作“ ...
- 一脸懵逼学习HBase的搭建(注意HBase的版本)
1:Hdfs分布式文件系统存的文件,文件存储. 2:Hbase是存储的数据,海量数据存储,作用是缓存的数据,将缓存的数据满后写入到Hdfs中. 3:hbase集群中的角色: ().一个或者多个主节点, ...
- 一脸懵逼学习HBase---基于HDFS实现的。(Hadoop的数据库,分布式的,大数据量的,随机的,实时的,非关系型数据库)
1:HBase官网网址:http://hbase.apache.org/ 2:HBase表结构:建表时,不需要指定表中的字段,只需要指定若干个列族,插入数据时,列族中可以存储任意多个列(即KEY-VA ...
- 一脸懵逼学习Hadoop分布式集群HA模式部署(七台机器跑集群)
1)集群规划:主机名 IP 安装的软件 运行的进程master 192.168.199.130 jdk.hadoop ...
随机推荐
- python 实现神经网络算法
注: Scratch是一款由麻省理工学院(MIT) 设计开发的一款面向少年的简易编程工具.这里写链接内容 本文翻译自“IMPLEMENTING A NEURAL NETWORK FRO ...
- 【转】Python之向日志输出中添加上下文信息
[转]Python之向日志输出中添加上下文信息 除了传递给日志记录函数的参数(如msg)外,有时候我们还想在日志输出中包含一些额外的上下文信息.比如,在一个网络应用中,可能希望在日志中记录客户端的特定 ...
- Python3-lamba表达式、zip函数
lambda表达式 学习条件运算时,对于简单的 if else 语句,可以使用三元运算来表示,即: # 普通条件语句 == : name = 'wupeiqi' else: name = 'alex' ...
- js学习笔记--基础部分
自增 自增 ++ 通过自增可以使变量在自身的基础上增加1 对于一个变量自增以后,原变量的值会立即自增1 无论使a++, 还是++a,都会立即使原变量的值自增1. 不同的是a++ 和++a的值不同. a ...
- leetcode327 Count of Range Sum
问题描述: 给定一个整数数组nums,返回其所有落在[low, upper]范围内(包含边界)的区间和的数目. 区间和sums(i, j)的定义为所有下标为i到j之间(i ≤ j)的元素的和,包含边界 ...
- 游记-NOIP2018
Day -3 受蛊惑跑到理工大去试机,意外发现home里的noilinux账户下有个压缩包,而且还试对了密码,怀着 激动 紧张的心情,打开来看,里面写着 (写出来我就会被禁赛了): asdfasdra ...
- struts2框架之国际化(参考第二天学习笔记)
国际化 1. 回忆之前的国际化 1). 资源包(key=字符串) > 命名:基本名称+local部分.properties,res_zh.properties,res_zh_CN.propert ...
- Winform按键捕获
参考:http://blog.csdn.net/zhensoft163/article/details/4239796 下载链接 方法1:使用窗体的 KeyDown 事件 private void F ...
- 35)django-验证码
一:验证码原理 第一次访问GET,后台: 1.创建一张图片 2.在图片中写入随机字符串 3.将图片写到制定文件 4.打开指定目录文件,读取内容 5.把生成的验证码保存在session中 6. 通过Ht ...
- web.xml详细选项配置
Web.xml常用元素 <web-app> <display-name></display-name>定义了WEB应用的名字 <description> ...