BP算法的矩阵推导
目录
1. 需要的微积分知识
1.1 导数
对于一元函数,在导数存在的情况下,在某一点的导数,也就是该点的斜率。
对于多元函数,对于某一点求导,则需要指明方向,两个特殊的方向,1. 偏导:在坐标轴方向的导数 2. 梯度的方向:总有一个方向是变化最快的。
1.2 求导的链式法则
- \(x \in R\), \(z=g(f(x))\), \(y=f(x)\)
\[ \frac{\partial z}{\partial x}=\frac{\partial z}{\partial y} \frac{\partial y}{\partial x}\] - $ x \in R^m $, \(f(x)\)是\(R^M\)到\(R^n\)的映射,\(g(f)\)是\(R^n\)到R的映射
\[ \frac{\partial g}{\partial x_i}=\sum_j^n \frac{\partial g}{\partial f_i} \frac{\partial f_i}{\partial x_i}\]
如果使用向量表示
\[ \nabla_x^z=(\frac{\partial f}{\partial x})^T \nabla_y^z\]
2. 梯度下降法
2.1 梯度
梯度其实本质也是一个向量,对于函数\(f(X,y)\)
在\((W,y)\)这一点的梯度 $ (\frac{\partial f}{\partial X},\frac{\partial f}{\partial y})$
梯度的几何意义:在该点变化增加最快的地方
2.2 梯度算法的解释
图来自吴恩达的机器学习课程
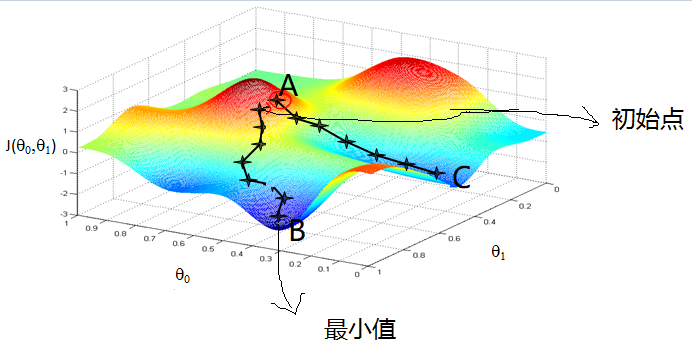
颜色偏红(A)的地方开始,根据梯度的负方向通过9次更新,达到了最小值(B)。
现在给定一个点\(A(\theta_0,\theta_1)\),干嘛呢,我们想从A到B点(最小值点),类似人类下山,需要知道往那个方向吧、走大多一步呢?
方向:梯度的负方向 \(\delta=(\frac{\partial L}{\partial \theta_0},\frac{\partial L}{\partial \theta_1}))\)
步长:学习率(\(\alpha\))
因此,计算一次里目标更近了 \((\theta_0,\theta_1)=(\theta_0,\theta_1)-\alpha \dot (\delta)\)
在重复上两步,直到满意为止。
3.误差反向传播算法
3.1 理论推导

3.1.1 符号说明
上图是一个L层的神经网络,输入层为第一层,隐藏层:2至\(L-1\)层,输出层L
令 输入向量 \(\vec{X}\)
\[ \vec{X} = (x_1,x_2,...,x_{m-1},x_m)\]
输出向量 \(\vec{Y}\)
\[ \vec{Y}=(y_1,y_2,...,y_{n-1},y_n)\]
第j层隐藏层的输出向量 \(\vec{h^{(j)}}\)
\[\vec{h^{(j)}}=(h_1^{(j)},h_2^{{j}},...,h_{t-1}^{(j)},h_tj^{(j)})\]
其中,\(tj\):表示第j的隐藏层个数
第\((l-1)\)层的第i个神经元到第\(l\)层的第j个神经元的连接权重:\(w_{ij}^{(l)}\),则第\((l-1)\)层神经元到第\(l\)层神经元的连接权重矩阵
\[W^{(l)}=\left( \begin{matrix}w_{11}^{(l)}& \cdots & w_{1(tj)}\\
& \dots &\\
w_{s(l-1)}^{l}&\cdots&w_{s(l-1)s(l)}^{l}
\end{matrix}\right)\]
3.1.2 推导过程
3.1.2.1 误差
定义的误差函数,常见的衡量性指标见 戳我,这里选择的误差平方和最小
第\(i\)个输出的误差,假设实际输出\((d(1),d(2),...,d(n))\):,一个输入样本对应的误差
\[E(i)=\frac{1}{2}\sum_{k=1}^n(y(i)-d(i))^2=\frac{1}{2}||y-d||^2\]
所有训练样本(\(N\))的误差:
\[E(i)=\frac{1}{2}\sum_{j=1}^{N}(\sum_{k=1}^n(y(i)-d(i))^2)=\frac{1}{2N}\sum_{j=1}^{N}(||y(i)-d(i)||^2)\]
因此,
\[ E = \frac{1}{2N}\sum_{i=1}^N(||y(i)-d(i)||^2)\]
其实,神经网络的输出是关于节点的复合函数。代价函数是关于\(W\)和\(b\)的函数。
3.1.2.2 正向传播
输入层\(\hat{X}\):
\[ X =(x_1,x_2,x_3,...,x_m)\]
当有\(N\)个训练样本时,可用矩阵表示
\[ X=\left( \begin{matrix}
x_{11} &x_{12}&...&x_{1m}\\
x_{21} & x_{22}&...&x_{2m}\\
\vdots & \vdots&\dots&\vdots\\
x_{N1} & \vdots&\vdots&x_{Nm}\\
\end{matrix} \right)\]
第二层 \(h^{(2)}\),一共\(s2\)个节点:
第i个节点的计算
\[h^{(2)}(i)=f(\sum_{j=1}^{s2}x(j)*w_{ji}^{(l)}+b_i)=f(x*w(:,i)+b_i)\]
矩阵表示
\[ h^{(2)}=f(x*W^{(l)}+b^{(2)})\]
第i层 矩阵形式
\[ h^{(l)}=f(h^{(l-1)}*W^{(l)}+b)\]
3.1.2.3 反向传播
梯度下降法更新权重,不断迭代到最优解。
对\(w_{ij}\)求导数可得,可更新\(w_{ij}\)更新公式:
\[ w_{ij}=w_{ij}-\alpha \frac{\partial E}{\partial w_{ij}}\]
当然简单的情况下,可直接写出公式,当太复杂的时候,引入BP简化求导
方便书写公式,对于第i的输入\(h^{(i-1)}*W^{(i)}+b^{(i)}\)记作\(net^{(i)}\),其中,第\(i\)的输入和输出的关系,\(输入=f(输出)\)
下面开始推导
首先,对于\(L\)层,
对于\(W^{(L)}\),先看对\(W_{ij}^{(L)}\)求导,
\[ \frac{\partial E}{\partial W_{ij}^{(L)}}
=\frac{\partial E}{\partial y(j)} * \frac{\partial y(i)}{\partial net_{j}^{L}} * \frac{\partial net_{j}^{L}}{\partial W_{ij}^{(L)}}\\
=(y(j)-d(j))*f(x)^{'}|_{x=net_j^{(L)}}h_i^{(L-1)}\]
令\(\delta_i^{(L)}=y(i)-d(i)\)
上述给出了单个分量的求偏导的结果,对于\(W^{(L)}\)
\[
\frac{\partial E}{\partial W^{(L)}}
=\left[\begin{matrix}
\frac{\partial E}{\partial W_{11}^{(L)}} & \frac{\partial E}{\partial W_{12}^{(L)}}&\dots & \frac{\partial E}{\partial W_{1n}^{(L)}}\\
\frac{\partial E}{\partial W_{21}^{(L)}} & \frac{\partial E}{\partial W_{22}^{(L)}}&\dots& \frac{\partial E}{\partial W_{2n}^{(L)}}\\
\vdots& \dots& \dots& \dots\\
\frac{\partial E}{\partial W_{sL,1}^{(L)}} & \frac{\partial E}{\partial W_{sL,2}^{(L)}}&\dots& \frac{\partial E}{\partial W_{sL,n}^{(L)}}
\end{matrix}\right]
\\= \left[
\begin{matrix}
h^{(L-1)}_1\\h^{(L-1)}_2\\ \dots\\h^{(L-1)}_n
\end{matrix}
\right] *\left[\begin{matrix}
\delta_1^{(L)}f(x)^{'}|_{x=net_1^{(L)}}\\
\delta_2^{(L)}f(x)^{'}|_{x=net_2^{(L)}}\\
\dots\\
\delta_n^{(L)}f(x)^{'}|_{x=net_n^{(L)}}
\end{matrix}\right] ^T
=h^{(L-1)}S^{(L)}
\]
其中,
\[
S^{(L)}=\left[\begin{matrix}
\delta_1^{(L)}f(x)^{'}|_{x=net_1^{(L)}}\\
\delta_2^{(L)}f(x)^{'}|_{x=net_2^{(L)}}\\
\dots\\
\delta_n^{(L)}f(x)^{'}|_{x=net_n^{(L)}}
\end{matrix}\right]^T
\]
同理可得,
\[
\frac{\partial E}{\partial b_k^{(L)}}=(y(j)-d(j))*f(x)^{'}|_{x=net_j^{(L)}}
\]
其次,对于隐含层\(L-1\)层,对\(W_{ij}^{(L)}\)求导
\[
\frac{\partial E}{\partial W_{ij}^{(L-1)}}
=\sum_{k=1}^{n}\frac{\partial E}{\partial y(k)} * \frac{\partial y(k)}{\partial net_{k}^{L}} * \frac{\partial net_{k}^{L}}{\partial f(net_j^{(L-1)})}*\frac{\partial f(net_j^{(L-1)})}{\partial net_j^{(L-1)}}*\frac{\partial net_j^{(L-1)}}{\partial W_{ij}^{(L-1)}}\\
=\sum_{k=1}^{n} (y(j)-d(j))*f(x)^{'}|_{x=net_j^{(L)}}W_{kj}^{(L)}f(x)^{'}|_{x=net_j^{L-1}}h_i^{L-2}\\
=\sum_{k=1}^{n}S_i^{(L)}W_{kj}^{(L)}f(x)^{'}|_{x=net_j^{L-1}}h_i^{L-2}\\
\]
写出矩阵形式,对\(W^{(L-1)}\)
\[
\frac{\partial E}{\partial W^{(L-1)}}=\left[\begin{matrix} h^{(L-2)}_1\\h^{(L-2)}_2\\\vdots\\h^{(L-2)}_{s(L-2)}\end{matrix}\right] \left[\begin{matrix}
\delta_1^{(L)}f(x)^{'}|_{x=net_1^{(L)}}\\
\delta_2^{(L)}f(x)^{'}|_{x=net_2^{(L)}}\\
\dots\\
\delta_n^{(L)}f(x)^{'}|_{x=net_n^{(L)}}
\end{matrix}\right]^T
\left[\begin{matrix}
W_{11}^{(L)} & W_{12}^{(L)}&\dots & W_{1n}^{(L)}\\
W_{21}^{(L)} & W_{22}^{(L)}&\dots& W_{2n}^{(L)}\\
\vdots& \dots& \dots& \dots\\
W_{s(L-1),1}^{(L)} & W_{s(L-1),2}^{(L)}&\dots& W_{s(L-1),n}^{(L)}
\end{matrix}\right]^T
\\
\left[ \begin{array}{ccc}{f^{'(L-1)}\left(net^{(L-1)}_{(1)}\right)} & {0} & {0}&{0} \\ {0} & {f^{'(L-1)}\left(net^{(L-1)}_{(2)}\right)} & {0} &{0}\\
0 & \dots & \vdots & 0\\{0} & {0} & {0}&{f^{(L-1)}\left(ne t_{s(L-1)}^{(L-1)}\right)}\end{array}\right]\\
=h^{(L-2)}S^{(L-1)}
\]
\[
S^{(L-1)}=\left(\left[\begin{matrix}
f(x)^{'(L)}|_{x=net_1^{(L)}}&0& \dots& 0\\
0&f(x)^{'}|_{x=net_2^{(L)}}0& \dots& 0\\
0&\dots&\dots&0\\
0&0&0&f(x)^{'(L)}|_{x=net_n^{(L)}}
\end{matrix}\right]\left[\begin{matrix} \delta_1^{(L)}\\\delta_2^{(L)}\\\vdots\\\delta_n^{(L)}\end{matrix}\right] \right)^T\\
\left[\begin{matrix}
W_{11}^{(L)} & W_{12}^{(L)}&\dots & W_{1n}^{(L)}\\
W_{21}^{(L)} & W_{22}^{(L)}&\dots& W_{2n}^{(L)}\\
\vdots& \dots& \dots& \dots\\
W_{s(L-1),1}^{(L)} & W_{s(L-1),2}^{(L)}&\dots& W_{s(L-1),n}^{(L)}*
\end{matrix}\right]^T
\left[ \begin{array}{ccc}{f^{'(L-1)}\left(net^{(L-1)}_{(1)}\right)} & {0} & {0}&{0} \\ {0} & {f^{'(L-1)}\left(net^{(L-1)}_{(2)}\right)} & {0} &{0}\\
0 & \dots & \vdots & 0\\{0} & {0} & {0}&{f^{(L-1)}\left(ne t_{s(L-1)}^{(L-1)}\right)}\end{array}\right]\\
=S^{(L)}\left[\begin{matrix}
W_{11}^{(L)} & W_{12}^{(L)}&\dots & W_{1n}^{(L)}\\
W_{21}^{(L)} & W_{22}^{(L)}&\dots& W_{2n}^{(L)}\\
\vdots& \dots& \dots& \dots\\
W_{s(L-1),1}^{(L)} & W_{s(L-1),2}^{(L)}&\dots& W_{s(L-1),n}^{(L)}*
\end{matrix}\right]^T\left[ \begin{array}{ccc}{f^{'(L-1)}\left(net^{(L-1)}_{(1)}\right)} & {0} & {0}&{0} \\ {0} & {f^{'(L-1)}\left(net^{(L-1)}_{(2)}\right)} & {0} &{0}\\
0 & \dots & \vdots & 0\\{0} & {0} & {0}&{f^{(L-1)}\left(ne t_{s(L-1)}^{(L-1)}\right)}\end{array}\right]*\\
\]
对\(1<l<L\),求\(W^{(l)}\)的偏导,
最后,根据上述的推导喔,很容易得出\(S^{(l)}\)和\(S^{(l+1)}\),
\[
S^{(l)}=S^{(l+1)}W^{(l+1)^T}F^{'(l)}(net^{(l)})\\
S^{(L)}=(Y-\hat{Y})F^{'(L)}(net^{(L)})
\]
\[
\frac{\partial E}{\partial W^{(l)}}=\left[\begin{matrix}h^{(l-1)}_1\\h^{(l-1)}_2 \\\dots \\h^{(l-1)}_{sl}\end{matrix}\right]S^{(l+1)}
\left[\begin{matrix}W_{11}^{(l+1)}&W_{12}^{(l+1)} &\dots& W_{2(sl+1)}^{(l+1)}\\
W_{21}^{(l+1)}&W_{22}^{(l+1)} &\dots& W_{2(sl+1)}^{(l+1)}\\
\dots&\dots&\dots&\dots\\
W_{sl1}^{(l+1)}&W_{sl2}^{(l+1)} &\dots& W_{sl(sl+1)}^{(l+1)}\\
\end{matrix} \right]^T\left[\begin{matrix} \partial f^{'(l)}(net_1^{l})&0&\dots & 0\\
0\\0 &\partial f^{'(l)}(net_2^{l})&\dots&0\\
0 & 0&\dots&0\\
0&0&\dots&\partial f^{'(l)}(net_l^{l})\end{matrix}\right]
\]
3.2 BP算法的小结
算法分为两个阶段:前向阶段和后向传播阶段
后向阶段算法:
Step 1: 计算\(\hat{y}^{(L)}\)
Step 2: for l =L:2
计算\(S^{(l)}=S^{(l+1)}W^{(l+1)}F'(net^{(l)})\)
计算 $\Delta W^{(l)}=h^{(l-1)}S^{(l)} $
计算\(W^{(l)}=W^{(l)}-\delta \Delta W^{(l)}\)
3.3 Python实现
3.3.1 最简单三层网络
'''
不用任何框架,自己写一个三层的神经网络
# input-3,hidden-4 output-1
'''
import numpy as np
np.random.seed(1)
# Input Matrix
X = np.array([[0, 0, 1],
[0, 1, 1],
[1, 0 ,1],
[1, 1, 1],])
# Output Matrix
y = np.array([[0],
[1],
[1],
[0]])
# Nonlinear function
def sigmoid(X,derive=False):
if not derive:
return 1 / (1 + np.exp(-X))
else:
return X*(1-X)
# relu
def relu(X,derive = False):
if not derive:
return np.maximum(0,X)
else:
return (X>0).astype(float)
# Weight bias
W1 = 2 * np.random.random((3, 4))-1
b1 = 0.1 * np.ones((4,))
W2 = 2 * np.random.random((4,1))-1
b2 = 0.1 * np.ones((1,))
rate = 0.1
noline = relu
# Training
train_times = 200
for time in range(train_times):
# Layer one
A1 = np.dot(X,W1)+b1
Z1 = noline(A1)
# Layer two
A2 = np.dot(Z1, W2)+b2
Z2 = noline(A2)
cost = -y+Z2
# Calc deltas
S2= cost*noline(A2,True)
delta_W2 = np.dot(Z1.T,S2)
bias2 = S2.sum(axis=0)
S1 = np.dot(S2, W2.T)*noline(A1,True)
delta_W1= np.dot(X.T, S1)
bias1 = S1.sum(axis=0)
# update
W1 = W1-rate*delta_W1
b1 = b1-rate*bias1
W2 = W2-rate*delta_W2
b2 = b2-rate*bias2
print('error',np.mean(((y-Z2)*(y-Z2))**2))
print("prediction",Z2)3.4 附录:
| Name | Abbreviation |
|---|---|
| Mean absolute percentage error | MAPE |
| Root mean squares percentage error | RMSPE |
| Mean absolute percentage error | MAE |
| Mean squares error | MSE |
| Index of agreement | IA |
| Theil U statistic 1 | U1 |
| Theil U statistic 2 | U2 |
| Correlation coefficient | R |
MAPE = \(\frac{1}{n} \sum_{k=1}^{n}\left|\frac{x^{(0)}(k)-\hat{x}^{(0)}(k)}{x^{(0)}(k)}\right| \times 100\)
RMSPE = \(\sqrt{\frac{1}{n} \sum_{k=1}^{n}\left(\frac{\hat{x}^{(0)}(k)-x^{(0)}(k)}{x^{(0)}(k)}\right)^{2}} \times 100\)
MAE = \(\frac{1}{n} \sum_{k=1}^{n}\left|\hat{x}^{(0)}(k)-x^{(0)}(k)\right|\)
MSE = \(\frac{1}{n} \sum_{k=1}^{n}\left(\hat{x}^{(0)}(k)-x^{(0)}(k)\right)^{2}\)
IA = \(1-\frac{\sum_{k=1}^{n}\left(\hat{x}^{(0)}(k)-x^{(0)}(k)\right)^{2}}{\sum_{k=1}^{n} \left( \left| \hat{x}^{(0)}(k)-\overline{x} \right|+\left| x^{(0)}(k)-\overline{x}\right| \right)^{2}}\)
U1 = \(\frac{\sqrt{\frac{1}{n} \sum_{k=1}^{n}\left(x^{(0)}(k)-x^{(0)}(k)\right)^{2}}}{\sqrt{\frac{1}{n} \sum_{k=1}^{n} x^{(0)}(k)^{2}}+\sqrt{\frac{1}{n} \sum_{k=1}^{n} x^{(0)}(k)^{2}}}\)
U2 = \(\frac{\left[\sum_{k=1}^{n}\left(\hat{x}^{(0)}(k)-x^{(0)}(k)\right)^{2}\right]^{1 / 2}}{\left[\sum_{k=1}^{n} x^{(0)}(k)^{2}\right]^{1 / 2}}\)
R = \(\frac{\operatorname{Cov}(\hat{x}^{(0)}, x^{(0)})}{\sqrt{\operatorname{Var}[\hat{x}^{(0)}] \operatorname{Var}[x^{(0)}]}}\)
BP算法的矩阵推导的更多相关文章
- 深度学习——前向传播算法和反向传播算法(BP算法)及其推导
1 BP算法的推导 图1 一个简单的三层神经网络 图1所示是一个简单的三层(两个隐藏层,一个输出层)神经网络结构,假设我们使用这个神经网络来解决二分类问题,我们给这个网络一个输入样本,通过前向运算得到 ...
- 人工神经网络反向传播算法(BP算法)证明推导
为了搞明白这个没少在网上搜,但是结果不尽人意,最后找到了一篇很好很详细的证明过程,摘抄整理为 latex 如下. (原文:https://blog.csdn.net/weixin_41718085/a ...
- 多层神经网络BP算法 原理及推导
首先什么是人工神经网络?简单来说就是将单个感知器作为一个神经网络节点,然后用此类节点组成一个层次网络结构,我们称此网络即为人工神经网络(本人自己的理解).当网络的层次大于等于3层(输入层+隐藏层(大于 ...
- 一文彻底搞懂BP算法:原理推导+数据演示+项目实战(上篇)
欢迎大家关注我们的网站和系列教程:http://www.tensorflownews.com/,学习更多的机器学习.深度学习的知识! 反向传播算法(Backpropagation Algorithm, ...
- 人工智能起步-反向回馈神经网路算法(BP算法)
人工智能分为强人工,弱人工. 弱人工智能就包括我们常用的语音识别,图像识别等,或者为了某一个固定目标实现的人工算法,如:下围棋,游戏的AI,聊天机器人,阿尔法狗等. 强人工智能目前只是一个幻想,就是自 ...
- 误差逆传播(error BackPropagation, BP)算法推导及向量化表示
1.前言 看完讲卷积神经网络基础讲得非常好的cs231后总感觉不过瘾,主要原因在于虽然知道了卷积神经网络的计算过程和基本结构,但还是无法透彻理解卷积神经网络的学习过程.于是找来了进阶的教材Notes ...
- 神经网络 误差逆传播算法推导 BP算法
误差逆传播算法是迄今最成功的神经网络学习算法,现实任务中使用神经网络时,大多使用BP算法进行训练. 给定训练集\(D={(x_1,y_1),(x_2,y_2),......(x_m,y_m)} ...
- BP算法基本原理推导----《机器学习》笔记
前言 多层网络的训练需要一种强大的学习算法,其中BP(errorBackPropagation)算法就是成功的代表,它是迄今最成功的神经网络学习算法. 今天就来探讨下BP算法的原理以及公式推导吧. 神 ...
- BP算法推导python实现
def sigmoid(inX): return 1.0/(1+exp(-inX)) '''标准bp算法每次更新都只针对单个样例,参数更新得很频繁sdataSet 训练数据集labels 训练 ...
随机推荐
- nfs与dhcp服务
NFS服务端概述 NFS,是Network File System的简写,即网络文件系统.网络文件系统是FreeBSD支持的文件系统中的一种,也被称为NFS: NFS允许一个系统在网络上与他人共享目录 ...
- 搭建zookeeper+kafka集群
搭建zookeeper+kafka集群 一.环境及准备 集群环境: 软件版本: 部署前操作: 关闭防火墙,关闭selinux(生产环境按需关闭或打开) 同步服务器时间,选择公网ntpd服务器或 ...
- python 模拟百度搜索
import urllib.request def Url(url): flag = input("请输入要搜索的关键字:") headers_ = { "User-Ag ...
- bootstrap-datetimepicker.js的漢化注意點
1.要引入bootstrap.css ,datetime.picker.css 2.引入的JS文件如下: <script type="text/javascript" src ...
- Ajax学习笔记——基本原理
Ajax(Asynchronous JavaScript + XML)不是语音,不是框架,也不能算是一种技术,而是一种模式.通过这种模式实现不重新加载整个页面的情况下,与服务器交换数据并更新部分网页内 ...
- [CSS3]环形进度条
来源:https://codepen.io/eZ0/pen/eZXNzd 点击上面链接有源码有示例. .ko-progress-circle { width: 120px; height: 120px ...
- Django2.X报错-------ModuleNotFoundError: No module named 'django.core.urlresolvers'
django2.0 把原来的 django.core.urlresolvers 包 更改为了 django.urls包.所以将导入的包修改为django.urls.
- python之路:模块初识
python王者开发之路:模块初识 模块初识我现在讲的确有点早.不过没关系,后面我会详细说模块. 模块,也就是库,是python三剑客之一.这三剑客,函数.库和类,都是由程序编写而成的.之所以我先说模 ...
- LevelDB源码分析-Version
Version VersionSet类 VersionSet管理整个LevelDB的当前状态: class VersionSet { public: // ... // Apply *edit to ...
- Git自学笔记
Git是什么? Git是目前世界上最先进的分布式版本控制系统,用于敏捷高效地处理任何或小或大的项目. Git与SVN的区别有哪些? ① Git是分布式的,SVN不是.这是Git和其它非分布式版本控制系 ...