Puppeteer之爬虫入门
译者按: 本文通过简单的例子介绍如何使用Puppeteer来爬取网页数据,特别是用谷歌开发者工具获取元素选择器值得学习。
- 原文: A Guide to Automating & Scraping the Web with JavaScript (Chrome + Puppeteer + Node JS)
- 译者: Fundebug
为了保证可读性,本文采用意译而非直译。另外,本文版权归原作者所有,翻译仅用于学习。

我们将会学到什么?
在这篇文章,你讲会学到如何使用JavaScript自动化抓取网页里面感兴趣的内容。我们将会使用Puppeteer,Puppeteer是一个Node库,提供接口来控制headless Chrome。Headless Chrome是一种不使用Chrome来运行Chrome浏览器的方式。
如果你不知道Puppeteer,也不了解headless Chrome,那么你只要知道我们将要编写JavaScript代码来自动化控制Chrome就行。
准备工作
你需要安装版本8以上的Node,你可以在这里找到安装方法。确保选择Current版本,因为它是8+。
当你将Node安装好以后,创建一个新的文件夹,将Puppeteer安装在该文件夹下。
npm install --save puppeteer
例1:截屏
当你把Puppeteer安装好了以后,我们来尝试第一个简单的例子。这个例子来自于Puppeteer文档(稍微改动)。我们编写的代码将会把你要访问的网页截屏并保存为png文件。
首先,创建一个test.js文件,并编写如下代码。
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://google.com');
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();
我们来一行一行理解一下代码的含义。
- 第1行:引入我们需要的库Puppeteer;
- 第3-10行:主函数
getPic()包含了所有的自动化代码; - 第12行:调用
getPic()函数。
这里需要提醒注意getPic()函数是一个async函数,使用了ES 2017 async/await特性。该函数是一个异步函数,会返回一个Promise。如果async最终顺利返回值,Promise则可以顺利reslove,得到结果;否则将会reject一个错误。
因为我们使用了async函数,我们使用await来暂停函数的执行,直到Promise返回。
接下来我们深入理解一下getPic():
第4行:
const broswer = await puppeteer.launch();
这行代码启动puppeteer,我们实际上启动了一个Chrome实例,并且和我们声明的
browser变量绑定起来。因为我们使用了await关键字,该函数会暂停直到Promise完全被解析。也就是说成功创建Chrome实例或则报错。第5行:
const page = await browser.newPage();
我们在浏览器中创建一个新的页面,通过使用await关键字来等待页面成功创建。
第6行:
await page.goto('https://google.com');
使用
page.goto()打开谷歌首页。第7行:
await page.screenshot({path: 'google.png'});
调用
screenshot()函数将当前页面截屏。第9行:
await browser.close();
将浏览器关闭。
执行实例
使用Node执行:
node test.js
下面截取的图片google.png:
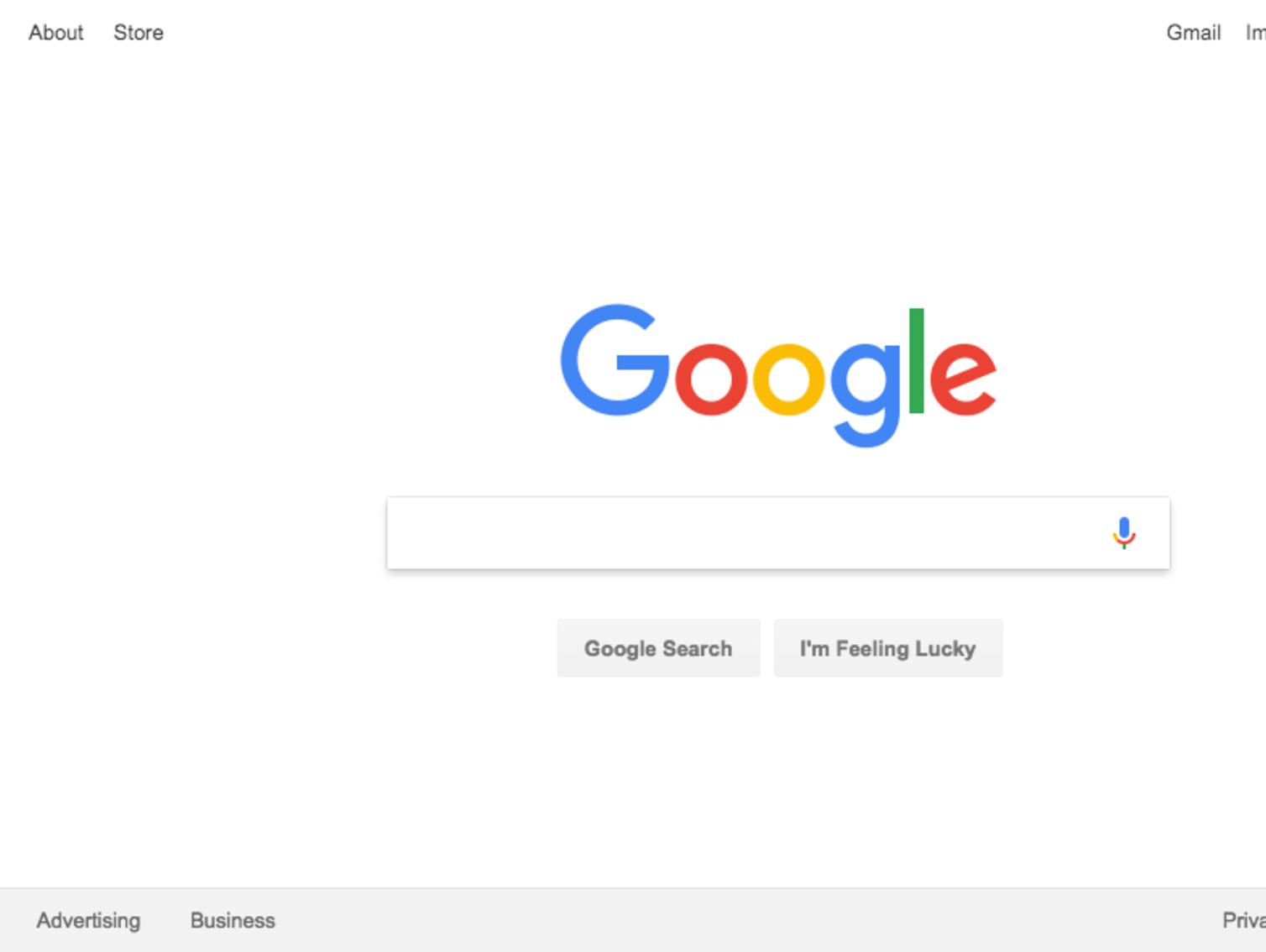
现在我们来使用non-headless模式试试。将第4行代码改为:
const browser = await puppeteer.launch({headless: false});
然后运行试试。你会发现谷歌浏览器打开了,并且导航到了谷歌搜索页面。但是截屏没有居中,我们可以调节一下页面的大小配置。
await page.setViewport({width: 1000, height: 500});
截屏的效果会更加漂亮。
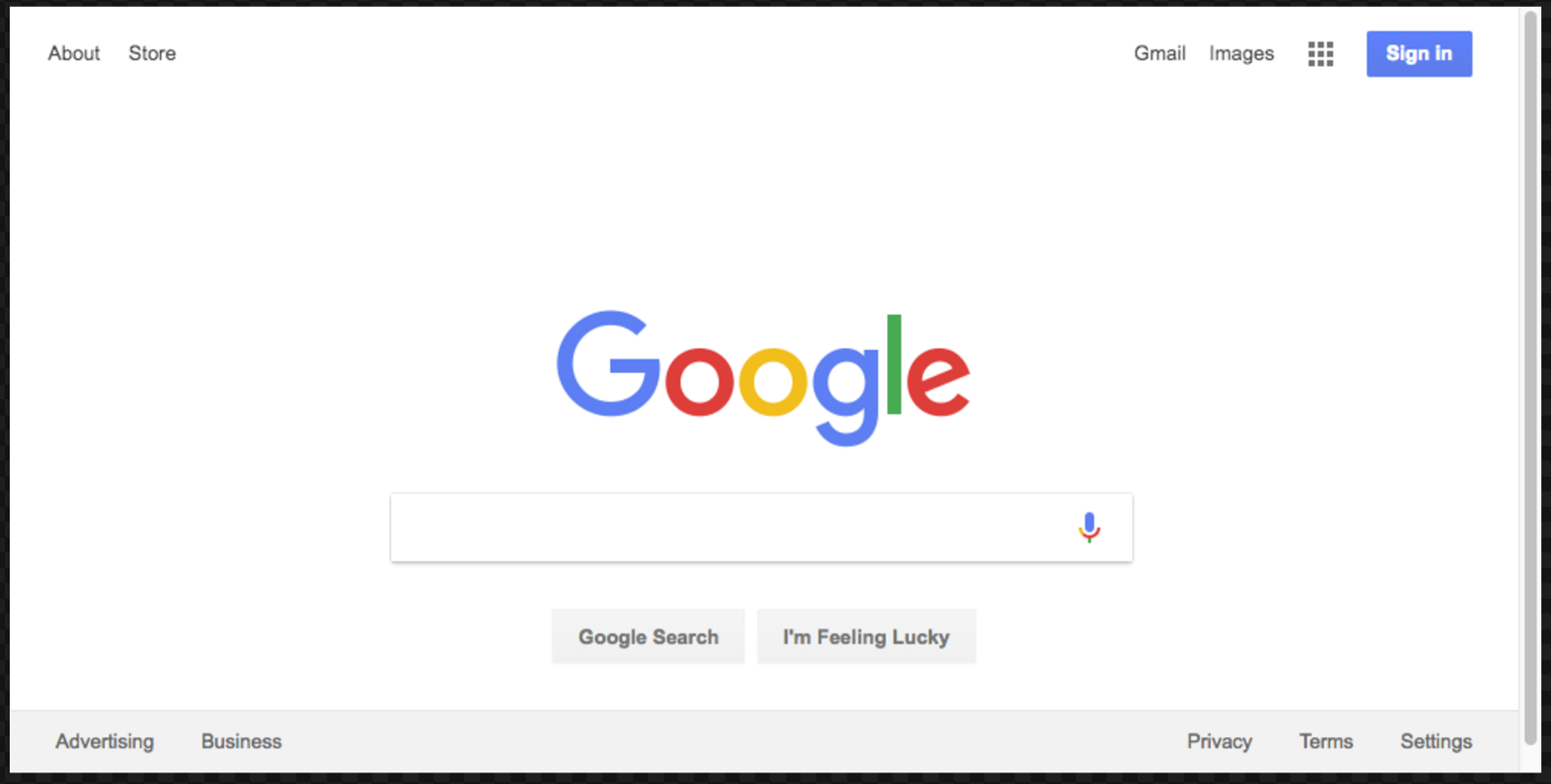
下面是最终版本的代码:
const puppeteer = require('puppeteer');
async function getPic() {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('https://google.com');
await page.setViewport({width: 1000, height: 500})
await page.screenshot({path: 'google.png'});
await browser.close();
}
getPic();
例2:爬取数据
首先,了解一下Puppeteer的API。文档提供了非常丰富的方法不仅支持在网页上点击,而且可以填写表单,读取数据。
接下来我们会爬取Books to Scrape,这是一个伪造的网上书店专门用来练习爬取数据。
在当前目录下,我们创建一个scrape.js文件,输入如下代码:
const puppeteer = require('puppeteer');
let scrape = async () => {
// 爬取数据的代码
// 返回数据
};
scrape().then((value) => {
console.log(value); // 成功!
});
第一步:基本配置
我们首先创建一个浏览器实例,打开一个新页面,并且导航到要爬取数据的页面。
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.waitFor(1000);
// Scrape
browser.close();
return result;
};
注意其中有一行代码让浏览器延时关闭。这行代码本来是不需要的,主要是方便查看页面是否完全加载。
await page.waitFor(1000);
第二步:抓取数据
我们接下来要选择页面上的第一本书,然后获取它的标题和价格。
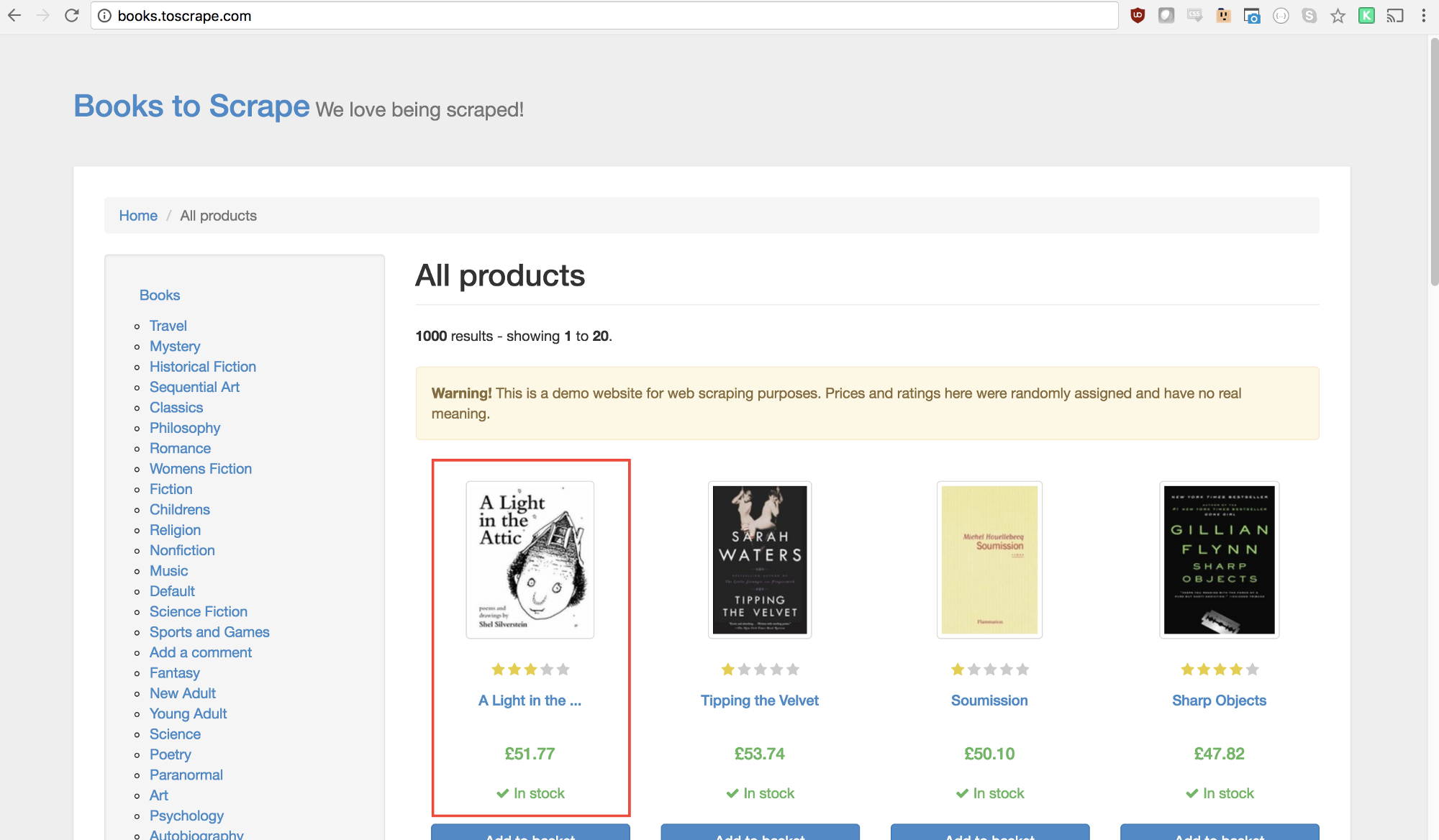
查看Puppeteer API,可以找到定义点击的函数:
page.click(selector[, options])
- selector 一个选择器来指定要点击的元素。如果多个元素满足,那么默认选择第一个。
幸运的是,谷歌开发者工具提供一个可以快速找到选择器元素的方法。在图片上方右击,选择检查(Inspect)选项。

谷歌开发者工具的Elements界面会打开,并且选定部分对应的代码会高亮。右击左侧的三个点,选择拷贝(Copy),然后选择拷贝选择器(Copy selector)。
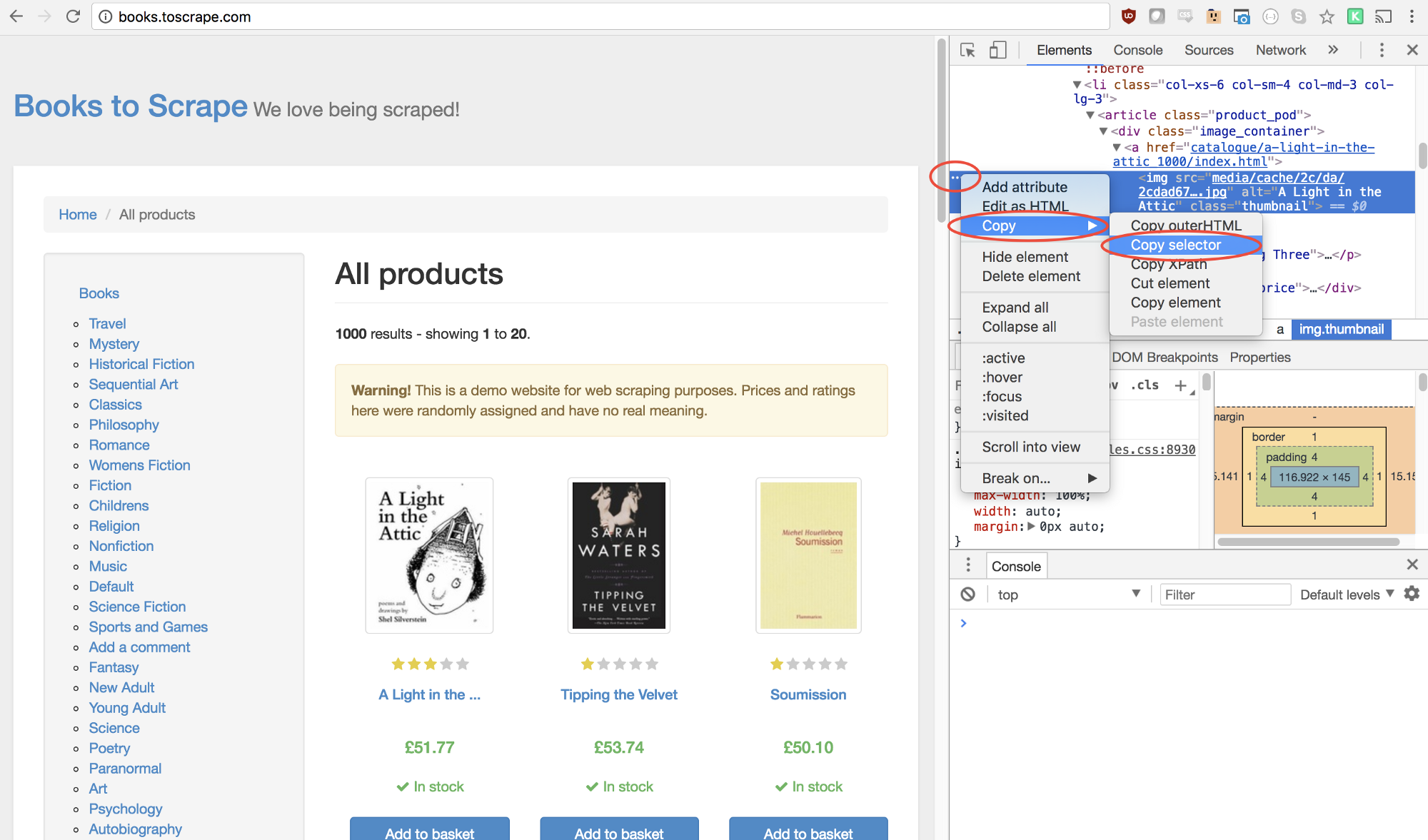
接下来将拷贝的选择器插入到函数中。
await page.click('#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img');
加入了点击事件的代码执行后会直接跳转到详细介绍这本书的页面。而我们则关心它的标题和价格部分。
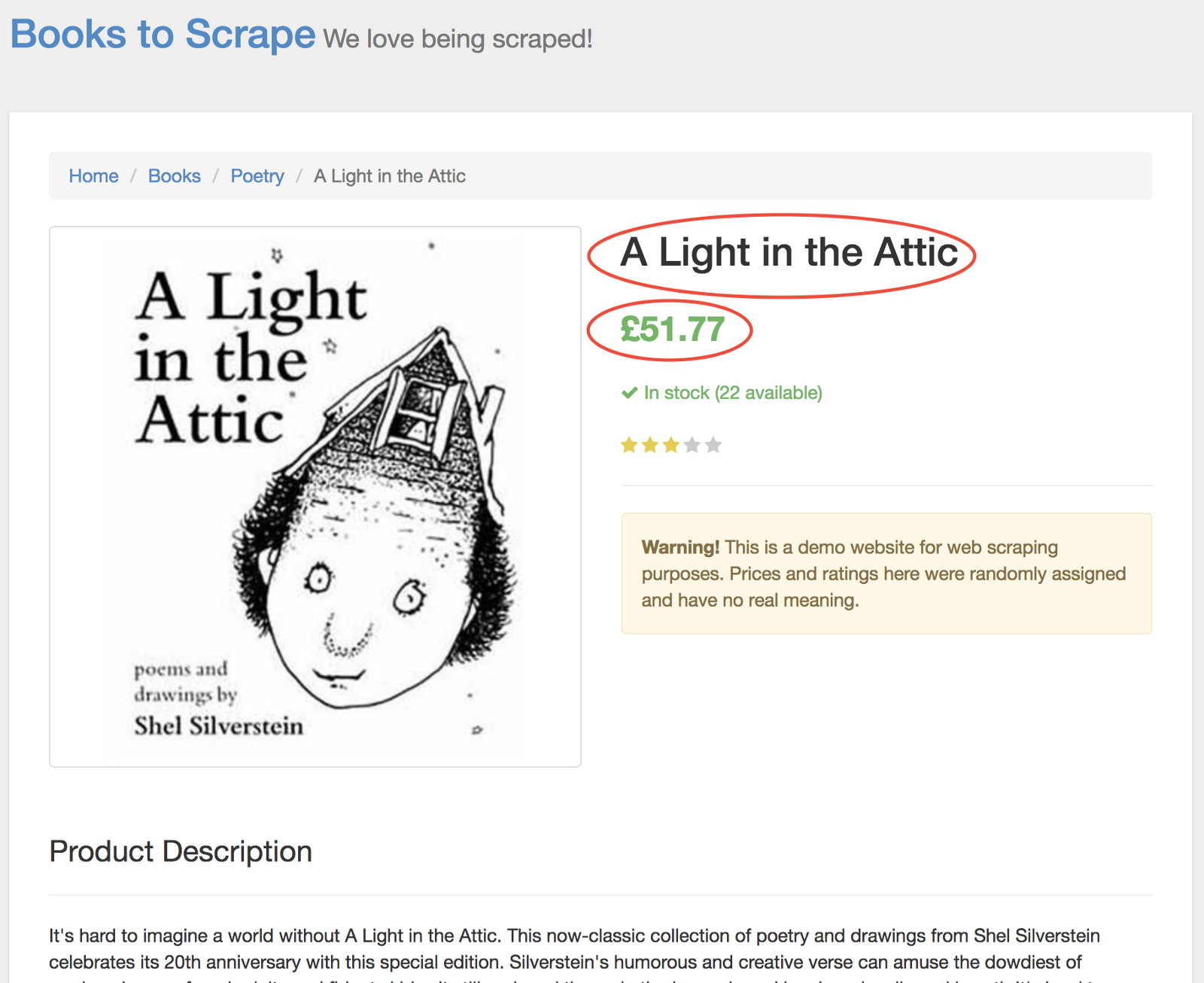
为了获取它们,我们首选需要使用page.evaluate()函数。该函数可以让我们使用内置的DOM选择器,比如querySelector()。
const result = await page.evaluate(() => {
// return something
});
然后,我们使用类似的手段获取标题的选择器。
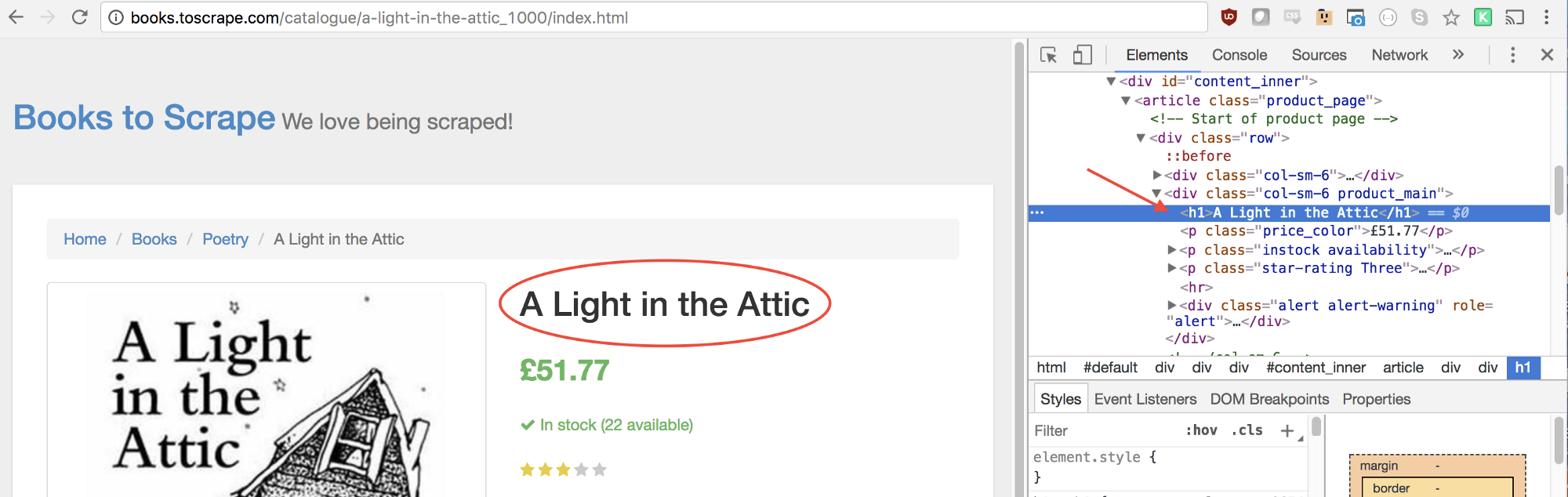
使用如下代码可以获取该元素:
let title = document.querySelector('h1');
但是,我们真正想要的是里面的文本文字。因此,通过.innerText来获取。
let title = document.querySelector('h1').innerText;
价格也可以用相同的方法获取。
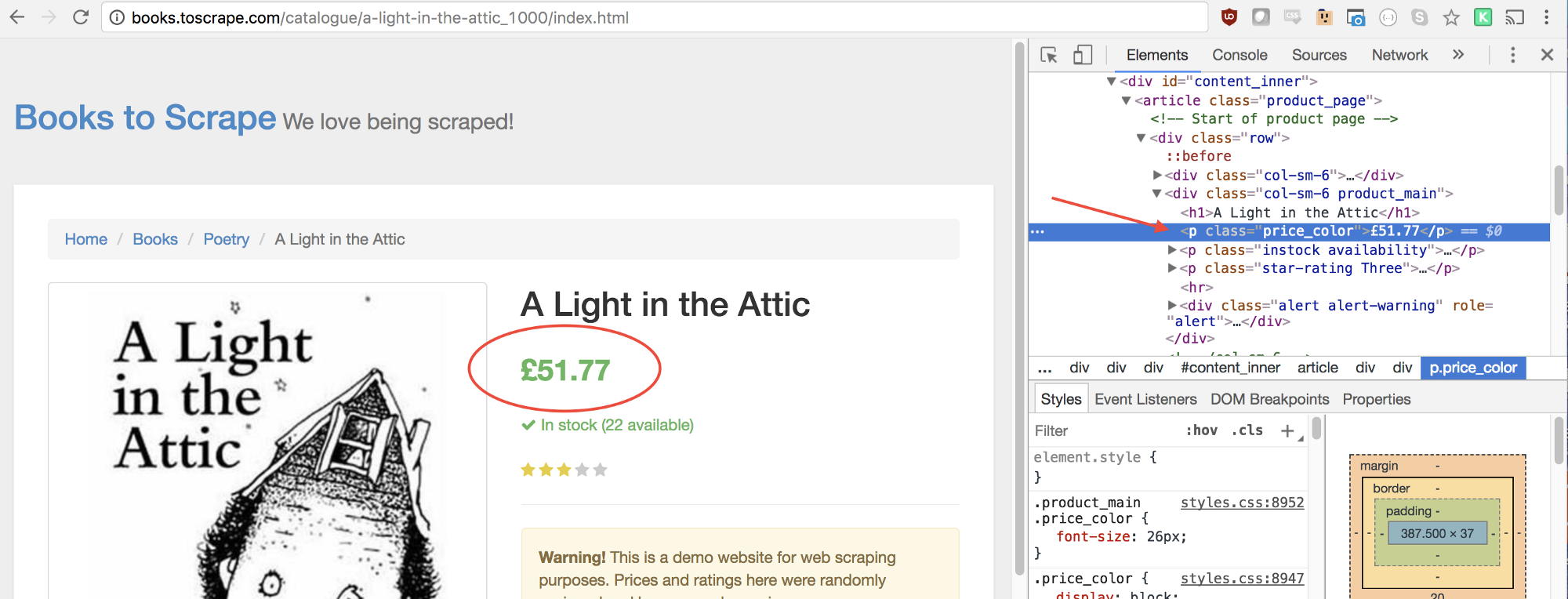
let price = document.querySelector('.price_color').innerText;
最终,将它们一起返回,完整代码如下:
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
所有的代码整合到一起,如下:
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
await page.click('#default > div > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.image_container > a > img');
await page.waitFor(1000);
const result = await page.evaluate(() => {
let title = document.querySelector('h1').innerText;
let price = document.querySelector('.price_color').innerText;
return {
title,
price
}
});
browser.close();
return result;
};
scrape().then((value) => {
console.log(value); // Success!
});
运行node scrape.js即可返回数据
{ title: 'A Light in the Attic', price: '£51.77' }
例3:进一步优化
从主页获取所有书籍的标题和价格,然后将它们返回。

提示
和例2的区别在于我们需要用一个循环来获取所有书籍的信息。
const result = await page.evaluate(() => {
let data = []; // Create an empty array
let elements = document.querySelectorAll('xxx'); // 获取所有书籍元素
// 循环处理每一个元素
// 获取标题
// 获取价格
data.push({title, price}); // 将结果存入数组
return data; // 返回数据
});
解法
const puppeteer = require('puppeteer');
let scrape = async () => {
const browser = await puppeteer.launch({headless: false});
const page = await browser.newPage();
await page.goto('http://books.toscrape.com/');
const result = await page.evaluate(() => {
let data = []; // 初始化空数组来存储数据
let elements = document.querySelectorAll('.product_pod'); // 获取所有书籍元素
for (var element of elements){ // 循环
let title = element.childNodes[5].innerText; // 获取标题
let price = element.childNodes[7].children[0].innerText; // 获取价格
data.push({title, price}); // 存入数组
}
return data; // 返回数据
});
browser.close();
return result;
};
scrape().then((value) => {
console.log(value); // Success!
});
关于Fundebug
Fundebug专注于JavaScript、微信小程序、微信小游戏、支付宝小程序、React Native、Node.js和Java实时BUG监控。 自从2016年双十一正式上线,Fundebug累计处理了7亿+错误事件,得到了Google、360、金山软件、百姓网等众多知名用户的认可。欢迎免费试用!

版权声明
转载时请注明作者Fundebug以及本文地址:
https://blog.fundebug.com/2017/11/01/guide-to-automating-scraping-the-web-with-js
Puppeteer之爬虫入门的更多相关文章
- Python简单爬虫入门三
我们继续研究BeautifulSoup分类打印输出 Python简单爬虫入门一 Python简单爬虫入门二 前两部主要讲述我们如何用BeautifulSoup怎去抓取网页信息以及获取相应的图片标题等信 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- Python简单爬虫入门二
接着上一次爬虫我们继续研究BeautifulSoup Python简单爬虫入门一 上一次我们爬虫我们已经成功的爬下了网页的源代码,那么这一次我们将继续来写怎么抓去具体想要的元素 首先回顾以下我们Bea ...
- GJM : Python简单爬虫入门(二) [转载]
感谢您的阅读.喜欢的.有用的就请大哥大嫂们高抬贵手"推荐一下"吧!你的精神支持是博主强大的写作动力以及转载收藏动力.欢迎转载! 版权声明:本文原创发表于 [请点击连接前往] ,未经 ...
- 爬虫入门系列(二):优雅的HTTP库requests
在系列文章的第一篇中介绍了 HTTP 协议,Python 提供了很多模块来基于 HTTP 协议的网络编程,urllib.urllib2.urllib3.httplib.httplib2,都是和 HTT ...
- 爬虫入门系列(三):用 requests 构建知乎 API
爬虫入门系列目录: 爬虫入门系列(一):快速理解HTTP协议 爬虫入门系列(二):优雅的HTTP库requests 爬虫入门系列(三):用 requests 构建知乎 API 在爬虫系列文章 优雅的H ...
- 【爬虫入门01】我第一只由Reuests和BeautifulSoup4供养的Spider
[爬虫入门01]我第一只由Reuests和BeautifulSoup4供养的Spider 广东职业技术学院 欧浩源 1.引言 网络爬虫可以完成传统搜索引擎不能做的事情,利用爬虫程序在网络上取得数据 ...
- 【网络爬虫入门02】HTTP客户端库Requests的基本原理与基础应用
[网络爬虫入门02]HTTP客户端库Requests的基本原理与基础应用 广东职业技术学院 欧浩源 1.引言 实现网络爬虫的第一步就是要建立网络连接并向服务器或网页等网络资源发起请求.urllib是 ...
- 【爬虫入门手记03】爬虫解析利器beautifulSoup模块的基本应用
[爬虫入门手记03]爬虫解析利器beautifulSoup模块的基本应用 1.引言 网络爬虫最终的目的就是过滤选取网络信息,因此最重要的就是解析器了,其性能的优劣直接决定这网络爬虫的速度和效率.Bea ...
随机推荐
- [转] 如何用kaldi训练好的模型做特定任务的在线识别
转自:http://blog.csdn.net/inger_h/article/details/52789339 在已经训练好模型的情况下,需要针对一个新任务做在线识别应该怎么做呢? 一种情况是,用已 ...
- Kali学习笔记21:缓冲区溢出实验(漏洞发现)
上一篇文章,我已经做好了缓冲区溢出实验的准备工作: https://www.cnblogs.com/xuyiqing/p/9835561.html 下面就是Kali虚拟机对缓冲区溢出的测试: 已经知道 ...
- Error running 'Unnamed': Address localhost:1099 is already in use
当使用idea运行项目时,出现‘Error running 'Unnamed': Address localhost:1099 is already in use’. 解决方案: 1.打开任务管理器 ...
- Python中parameters与argument区别
定义(define)一个带parameters的函数: def addition(x,y): return (x+y) 这里的x,y就是parameter 调用addition(3,4) 调用(cal ...
- LeetCode20:validParentheses
validParentheses 题目描述 Given a string containing just the characters '(', ')', '{', '}', '[' and ']', ...
- python(leetcode)-344反转字符串
编写一个函数,其作用是将输入的字符串反转过来.输入字符串以字符数组 char[] 的形式给出. 不要给另外的数组分配额外的空间,你必须原地修改输入数组.使用 O(1) 的额外空间解决这一问题. 你可以 ...
- 基于python的OpenCV图像1
目录 1. 读入图片并显示 import cv2 img = cv2.imread("longmao.jpg") cv2.imshow("longmao", i ...
- 1.Git起步-Git的三种状态以及三种工作区域、CVCS与DVCS的区别、Git基本工作流程
1.Git基础 版本控制系统是一种用于记录一个或多个文件内容变化,以便将来查阅恢复特定版本修订情况的系统. Git是一种分布式版本控制系统(Distributed Version Control Sy ...
- [译]ASP.NET Core Web API 中使用Oracle数据库和Dapper看这篇就够了
[译]ASP.NET Core Web API 中使用Oracle数据库和Dapper看这篇就够了 本文首发自:博客园 文章地址: https://www.cnblogs.com/yilezhu/p/ ...
- mybatis框架(3)---SqlMapConfig.xml解析
SqlMapConfig.xml SqlMapConfig.xml是Mybatis的全局配置参数,关于他的具体用的有专门的MyBatis - API文档,这里面讲的非常清楚,所以我这里就挑几个讲下: ...