ES--01
ES概念:
垂直搜索(站内搜索)
什么是全文检索和Lucene?
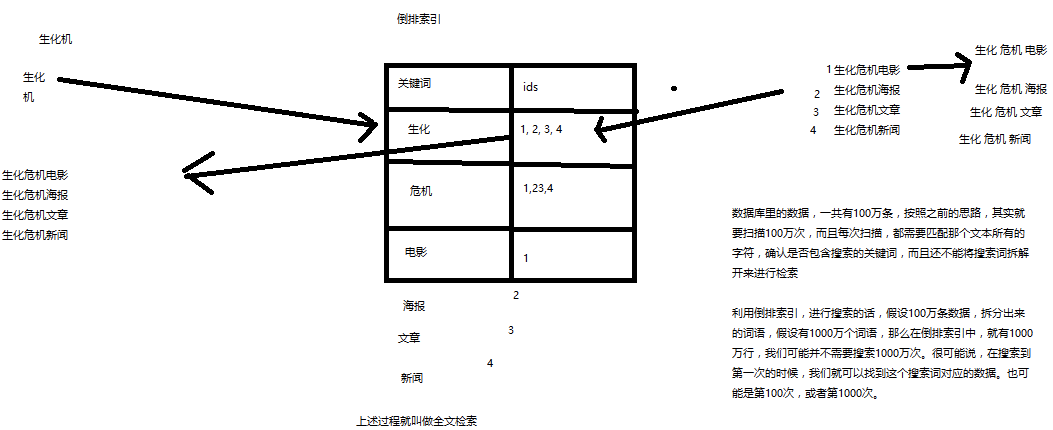
1 全文检索 倒排索引
2 Lucene 就是一个jar包 里面包含了封装好的各种简历倒排索引 以及进行搜索的代码 包括各种算法 我们就用java开发的时候 引入 lucene jar 然后基于lucene的api进行开发 用lucene,将已有的数据建立索引 lucene会在本地磁盘上 给我们组织索引的数据结构
ES的概念:
1、Elasticsearch的功能
(1)分布式的搜索引擎和数据分析引擎
搜索:百度,网站的站内搜索,IT系统的检索
数据分析:电商网站,最近7天牙膏这种商品销量排名前10的商家有哪些;新闻网站,最近1个月访问量排名前3的新闻版块是哪些
分布式,搜索,数据分析
(2)全文检索,结构化检索,数据分析
全文检索:我想搜索商品名称包含牙膏的商品,select * from products where product_name like "%牙膏%"
结构化检索:我想搜索商品分类为日化用品的商品都有哪些,select * from products where category_id='日化用品'
部分匹配、自动完成、搜索纠错、搜索推荐
数据分析:我们分析每一个商品分类下有多少个商品,select category_id,count(*) from products group by category_id
(3)对海量数据进行近实时的处理
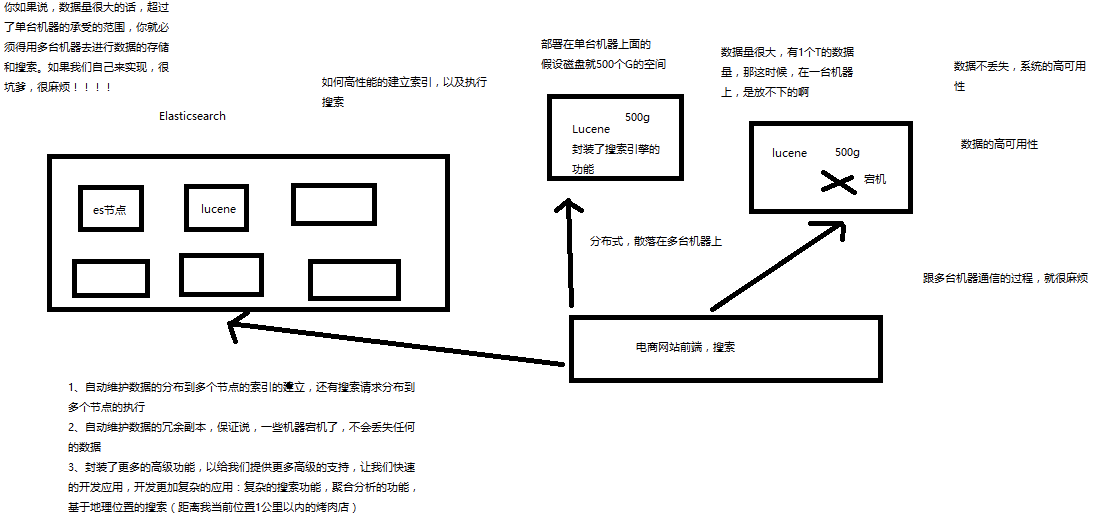
分布式:ES自动可以将海量数据分散到多台服务器上去存储和检索
海联数据的处理:分布式以后,就可以采用大量的服务器去存储和检索数据,自然而然就可以实现海量数据的处理了
近实时:检索个数据要花费1小时(这就不要近实时,离线批处理,batch-processing);在秒级别对数据进行搜索和分析
跟分布式/海量数据相反的:lucene,单机应用,只能在单台服务器上使用,最多只能处理单台服务器可以处理的数据量
2、Elasticsearch的适用场景
国外
(1)维基百科,类似百度百科,牙膏,牙膏的维基百科,全文检索,高亮,搜索推荐
(2)The Guardian(国外新闻网站),类似搜狐新闻,用户行为日志(点击,浏览,收藏,评论)+社交网络数据(对某某新闻的相关看法),数据分析,给到每篇新闻文章的作者,让他知道他的文章的公众反馈(好,坏,热门,垃圾,鄙视,崇拜)
(3)Stack Overflow(国外的程序异常讨论论坛),IT问题,程序的报错,提交上去,有人会跟你讨论和回答,全文检索,搜索相关问题和答案,程序报错了,就会将报错信息粘贴到里面去,搜索有没有对应的答案
(4)GitHub(开源代码管理),搜索上千亿行代码
(5)电商网站,检索商品
(6)日志数据分析,logstash采集日志,ES进行复杂的数据分析(ELK技术,elasticsearch+logstash+kibana)
(7)商品价格监控网站,用户设定某商品的价格阈值,当低于该阈值的时候,发送通知消息给用户,比如说订阅牙膏的监控,如果高露洁牙膏的家庭套装低于50块钱,就通知我,我就去买
(8)BI系统,商业智能,Business Intelligence。比如说有个大型商场集团,BI,分析一下某某区域最近3年的用户消费金额的趋势以及用户群体的组成构成,产出相关的数张报表,**区,最近3年,每年消费金额呈现100%的增长,而且用户群体85%是高级白领,开一个新商场。ES执行数据分析和挖掘,Kibana进行数据可视化
国内
(9)国内:站内搜索(电商,招聘,门户,等等),IT系统搜索(OA,CRM,ERP,等等),数据分析(ES热门的一个使用场景)
3、Elasticsearch的特点
(1)可以作为一个大型分布式集群(数百台服务器)技术,处理PB级数据,服务大公司;也可以运行在单机上,服务小公司
(2)Elasticsearch不是什么新技术,主要是将全文检索、数据分析以及分布式技术,合并在了一起,才形成了独一无二的ES;lucene(全文检索),商用的数据分析软件(也是有的),分布式数据库(mycat)
(3)对用户而言,是开箱即用的,非常简单,作为中小型的应用,直接3分钟部署一下ES,就可以作为生产环境的系统来使用了,数据量不大,操作不是太复杂
(4)数据库的功能面对很多领域是不够用的(事务,还有各种联机事务型的操作);特殊的功能,比如全文检索,同义词处理,相关度排名,复杂数据分析,海量数据的近实时处理;Elasticsearch作为传统数据库的一个补充,提供了数据库所不不能提供的很多功能
ElasticSearch 和 Lucene 的关系
1、lucene和elasticsearch的前世今生
lucene,最先进、功能最强大的搜索库,直接基于lucene开发,非常复杂,api复杂(实现一些简单的功能,写大量的java代码),需要深入理解原理(各种索引结构)
elasticsearch,基于lucene,隐藏复杂性,提供简单易用的restful api接口、java api接口(还有其他语言的api接口)
(1)分布式的文档存储引擎
(2)分布式的搜索引擎和分析引擎
(3)分布式,支持PB级数据
开箱即用,优秀的默认参数,不需要任何额外设置,完全开源
2、elasticsearch的核心概念
(1)Near Realtime(NRT):近实时,两个意思,从写入数据到数据可以被搜索到有一个小延迟(大概1秒);基于es执行搜索和分析可以达到秒级
(2)Cluster:集群,包含多个节点,每个节点属于哪个集群是通过一个配置(集群名称,默认是elasticsearch)来决定的,对于中小型应用来说,刚开始一个集群就一个节点很正常
(3)Node:节点,集群中的一个节点,节点也有一个名称(默认是随机分配的),节点名称很重要(在执行运维管理操作的时候),默认节点会去加入一个名称为“elasticsearch”的集群,如果直接启动一堆节点,那么它们会自动组成一个elasticsearch集群,当然一个节点也可以组成一个elasticsearch集群
(4)Document&field:(document相当于一个row field相当于一个字段属性)文档,es中的最小数据单元,一个document可以是一条客户数据,一条商品分类数据,一条订单数据,通常用JSON数据结构表示,每个index下的type中,都可以去存储多个document。一个document里面有多个field,每个field就是一个数据字段。
product document
{
"product_id": "1",
"product_name": "高露洁牙膏",
"product_desc": "高效美白",
"category_id": "2",
"category_name": "日化用品"
}
(5)Index:相当于数据库 db 索引,包含一堆有相似结构的文档数据,比如可以有一个客户索引,商品分类索引,订单索引,索引有一个名称。一个index包含很多document,一个index就代表了一类类似的或者相同的document。比如说建立一个product index,商品索引,里面可能就存放了所有的商品数据,所有的商品document。
(6)Type:相当于表格 table 类型,每个索引里都可以有一个或多个type,type是index中的一个逻辑数据分类,一个type下的document,都有相同的field,比如博客系统,有一个索引,可以定义用户数据type,博客数据type,评论数据type。
商品index,里面存放了所有的商品数据,商品document
但是商品分很多种类,每个种类的document的field可能不太一样,比如说电器商品,可能还包含一些诸如售后时间范围这样的特殊field;生鲜商品,还包含一些诸如生鲜保质期之类的特殊field
type,日化商品type,电器商品type,生鲜商品type
日化商品type:product_id,product_name,product_desc,category_id,category_name
电器商品type:product_id,product_name,product_desc,category_id,category_name,service_period
生鲜商品type:product_id,product_name,product_desc,category_id,category_name,eat_period
每一个type里面,都会包含一堆document
{
"product_id": "2",
"product_name": "长虹电视机",
"product_desc": "4k高清",
"category_id": "3",
"category_name": "电器",
"service_period": "1年"
}
{
"product_id": "3",
"product_name": "基围虾",
"product_desc": "纯天然,冰岛产",
"category_id": "4",
"category_name": "生鲜",
"eat_period": "7天"
}
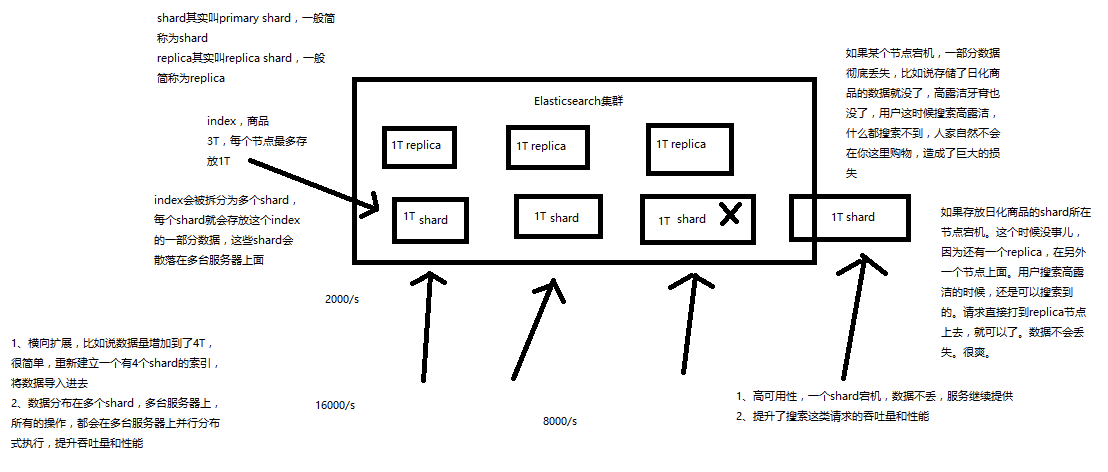
(7)shard:单台机器无法存储大量数据,es可以将一个索引中的数据切分为多个shard,分布在多台服务器上存储。有了shard就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个shard都是一个lucene index。
(8)replica:任何一个服务器随时可能故障或宕机,此时shard可能就会丢失,因此可以为每个shard创建多个replica副本。replica可以在shard故障时提供备用服务,保证数据不丢失,多个replica还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认5个),replica shard(随时修改数量,默认1个),默认每个索引10个shard,5个primary shard,5个replica shard,最小的高可用配置,是2台服务器。
安装运行es
elasticsearch 的安装 head插件:
使用wget 安装head插件
安装后访问localhost://9100显示未连接 停掉head服务 然后编辑es的配置文件 ElasticSearch.yml
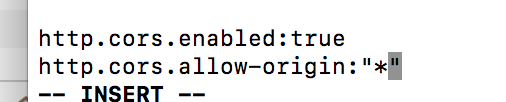
修改后 启动es
然后开启head插件

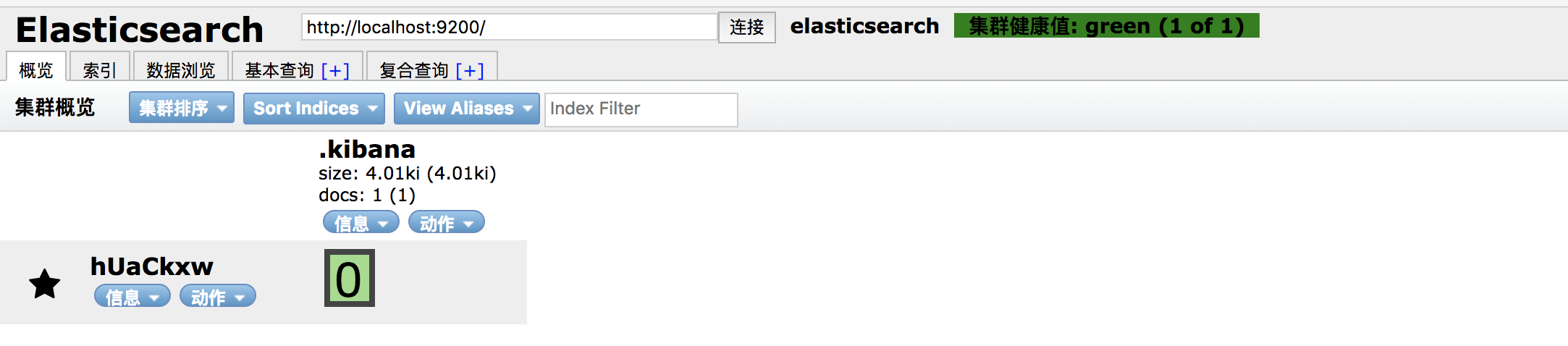
连接状态
启动kibana
使用devtools 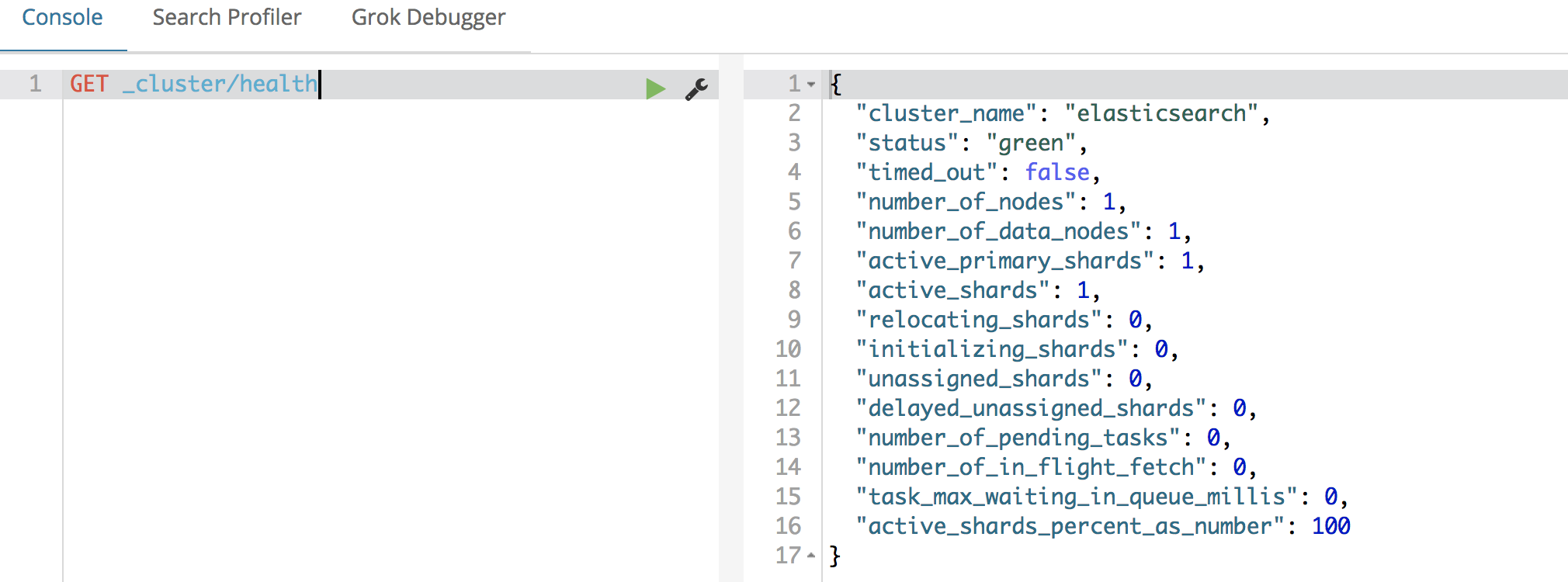
1、document数据格式
面向文档的搜索分析引擎
(1)应用系统的数据结构都是面向对象的,复杂的
(2)对象数据存储到数据库中,只能拆解开来,变为扁平的多张表,每次查询的时候还得还原回对象格式,相当麻烦
(3)ES是面向文档的,文档中存储的数据结构,与面向对象的数据结构是一样的,基于这种文档数据结构,es可以提供复杂的索引,全文检索,分析聚合等功能
(4)es的document用json数据格式来表达
public class Employee {
private String email;
private String firstName;
private String lastName;
private EmployeeInfo info;
private Date joinDate;
}
private class EmployeeInfo {
private String bio; // 性格
private Integer age;
private String[] interests; // 兴趣爱好
}
EmployeeInfo info = new EmployeeInfo();
info.setBio("curious and modest");
info.setAge(30);
info.setInterests(new String[]{"bike", "climb"});
Employee employee = new Employee();
employee.setEmail("zhangsan@sina.com");
employee.setFirstName("san");
employee.setLastName("zhang");
employee.setInfo(info);
employee.setJoinDate(new Date());
employee对象:里面包含了Employee类自己的属性,还有一个EmployeeInfo对象
两张表:employee表,employee_info表,将employee对象的数据重新拆开来,变成Employee数据和EmployeeInfo数据
employee表:email,first_name,last_name,join_date,4个字段
employee_info表:bio,age,interests,3个字段;此外还有一个外键字段,比如employee_id,关联着employee表
{
"email": "zhangsan@sina.com",
"first_name": "san",
"last_name": "zhang",
"info": {
"bio": "curious and modest",
"age": 30,
"interests": [ "bike", "climb" ]
},
"join_date": "2017/01/01"
}
我们就明白了es的document数据格式和数据库的关系型数据格式的区别
案例:
2、电商网站商品管理案例背景介绍
有一个电商网站,需要为其基于ES构建一个后台系统,提供以下功能:
(1)对商品信息进行CRUD(增删改查)操作
(2)执行简单的结构化查询
(3)可以执行简单的全文检索,以及复杂的phrase(短语)检索
(4)对于全文检索的结果,可以进行高亮显示
(5)对数据进行简单的聚合分析
3、简单的集群管理
(1)快速检查集群的健康状况
es提供了一套api,叫做cat api,可以查看es中各种各样的数据
GET /_cat/health?v
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488006741 15:12:21 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent 启动第二个es进程的情况 yellow变成green
1488007113 15:18:33 elasticsearch green 2 2 2 1 0 0 0 0 - 100.0%
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1488007216 15:20:16 elasticsearch yellow 1 1 1 1 0 0 1 0 - 50.0%
如何快速了解集群的健康状况?green、yellow、red?
green:每个索引的primary shard和replica shard都是active状态的
yellow:每个索引的primary shard都是active状态的,但是部分replica shard不是active状态,处于不可用的状态
red:不是所有索引的primary shard都是active状态的,部分索引有数据丢失了
为什么现在会处于一个yellow状态?
我们现在就一个笔记本电脑,就启动了一个es进程,相当于就只有一个node。现在es中有一个index,就是kibana自己内置建立的index。由于默认的配置是给每个index分配5个primary shard和5个replica shard,而且primary shard和replica shard不能在同一台机器上(为了容错)。现在kibana自己建立的index是1个primary shard和1个replica shard。当前就一个node,所以只有1个primary shard被分配了和启动了,但是一个replica shard没有第二台机器去启动。
做一个小实验:此时只要启动第二个es进程,就会在es集群中有2个node,然后那1个replica shard就会自动分配过去,然后cluster status就会变成green状态。
(2)快速查看集群中有哪些索引
GET /_cat/indices?v
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg 1 1 1 0 3.1kb 3.1kb
(3)简单的索引操作
创建索引:PUT /test_index?pretty
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open test_index XmS9DTAtSkSZSwWhhGEKkQ 5 1 0 0 650b 650b
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg 1 1 1 0 3.1kb 3.1kb
删除索引:DELETE /test_index?pretty
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
yellow open .kibana rUm9n9wMRQCCrRDEhqneBg 1 1 1 0 3.1kb 3.1kb
4、商品的CRUD操作
(1)新增商品:新增文档,建立索引 version涉及到乐观锁的并发控制策略。
PUT /index/type/id
{
"json数据"
}
PUT /ecommerce/product/1
{
"name" : "gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
PUT /ecommerce/product/2
{
"name" : "jiajieshi yagao",
"desc" : "youxiao fangzhu",
"price" : 25,
"producer" : "jiajieshi producer",
"tags": [ "fangzhu" ]
}
PUT /ecommerce/product/3
{
"name" : "zhonghua yagao",
"desc" : "caoben zhiwu",
"price" : 40,
"producer" : "zhonghua producer",
"tags": [ "qingxin" ]
}
es会自动建立index和type,不需要提前创建,而且es默认会对document每个field都建立倒排索引,让其可以被搜索
(2)查询商品:检索文档
GET /index/type/id
GET /ecommerce/product/1
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"found": true,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": [
"meibai",
"fangzhu"
]
}
}
(3)修改商品:替换文档 version改变了
PUT /ecommerce/product/1
{
"name" : "jiaqiangban gaolujie yagao",
"desc" : "gaoxiao meibai",
"price" : 30,
"producer" : "gaolujie producer",
"tags": [ "meibai", "fangzhu" ]
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": true
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"created": false
}
PUT /ecommerce/product/1
{
"name" : "jiaqiangban gaolujie yagao"
}
替换方式有一个不好,即使必须带上所有的field,才能去进行信息的修改 如果只带name属性来替换 其他属性就丢失了 只有name属性了
(4)修改商品:更新文档
POST /ecommerce/product/1/_update
{
"doc": {
"name": "jiaqiangban gaolujie yagao"
}
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 8,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
我的风格,其实有选择的情况下,不太喜欢念ppt,或者照着文档做,或者直接粘贴写好的代码,尽量是纯手敲代码
(5)删除商品:删除文档
DELETE /ecommerce/product/1
{
"found": true,
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_version": 9,
"result": "deleted",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
}
}
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"found": false
}
多种搜索方式:
1、query string search
2、query DSL
3、query filter
4、full-text search
5、phrase search
6、highlight search
1、query string search
搜索全部商品:GET /ecommerce/product/_search
took:耗费了几毫秒
timed_out:是否超时,这里是没有
_shards:数据拆成了5个分片,所以对于搜索请求,会打到所有的primary shard(或者是它的某个replica shard也可以)
hits.total:查询结果的数量,3个document
hits.max_score:score的含义,就是document对于一个search的相关度的匹配分数,越相关,就越匹配,分数也高
hits.hits:包含了匹配搜索的document的详细数据
{
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"failed": 0
},
"hits": {
"total": 3,
"max_score": 1,
"hits": [
{
"_index": "ecommerce",
"_type": "product",
"_id": "2",
"_score": 1,
"_source": {
"name": "jiajieshi yagao",
"desc": "youxiao fangzhu",
"price": 25,
"producer": "jiajieshi producer",
"tags": [
"fangzhu"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "1",
"_score": 1,
"_source": {
"name": "gaolujie yagao",
"desc": "gaoxiao meibai",
"price": 30,
"producer": "gaolujie producer",
"tags": [
"meibai",
"fangzhu"
]
}
},
{
"_index": "ecommerce",
"_type": "product",
"_id": "3",
"_score": 1,
"_source": {
"name": "zhonghua yagao",
"desc": "caoben zhiwu",
"price": 40,
"producer": "zhonghua producer",
"tags": [
"qingxin"
]
}
}
]
}
}
query string search的由来,因为search参数都是以http请求的query string来附带的
搜索商品名称中包含yagao的商品,而且按照售价降序排序:GET /ecommerce/product/_search?q=name:yagao&sort=price:desc
适用于临时的在命令行使用一些工具,比如curl,快速的发出请求,来检索想要的信息;但是如果查询请求很复杂,是很难去构建的
在生产环境中,几乎很少使用query string search
2、query DSL
DSL:Domain Specified Language,特定领域的语言
http request body:请求体,可以用json的格式来构建查询语法,比较方便,可以构建各种复杂的语法,比query string search肯定强大多了
查询所有的商品
GET /ecommerce/product/_search
{
"query": { "match_all": {} }
}
查询名称包含yagao的商品,同时按照价格降序排序
GET /ecommerce/product/_search
{
"query" : {
"match" : {
"name" : "yagao"
}
},
"sort": [
{ "price": "desc" }
]
}

分页查询商品,总共3条商品,假设每页就显示1条商品,现在显示第2页,所以就查出来第2个商品
GET /ecommerce/product/_search
{
"query": { "match_all": {} },
"from": 1,
"size": 1
}
指定要查询出来商品的名称和价格就可以
GET /ecommerce/product/_search
{
"query": { "match_all": {} },
"_source": ["name", "price"]
}
更加适合生产环境的使用,可以构建复杂的查询
3、query filter
搜索商品名称包含yagao,而且售价大于25元的商品
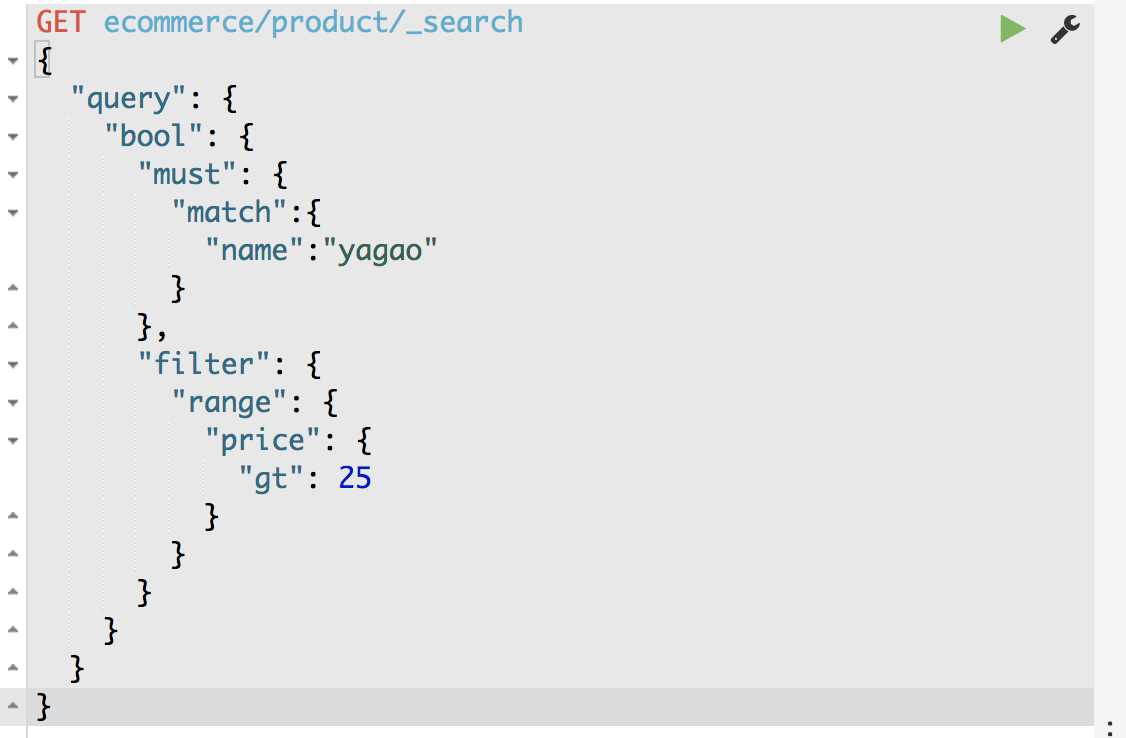
4、full-text search(全文检索) 计算相关度 分数 socre
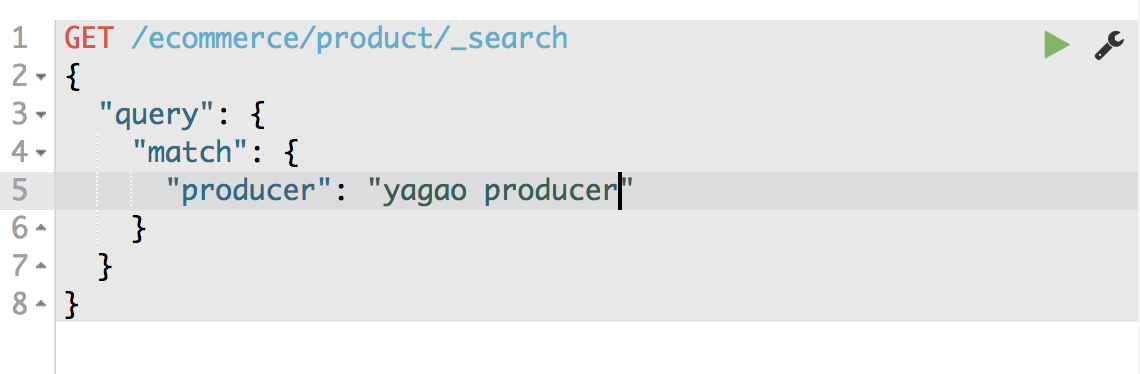
producer这个字段 会被拆解 建立倒排索引
special 4
yagao 4
producer 1,2,3,4
gaolujie 1
zhognhua 3
jiajieshi 2
5、phrase search(短语搜索)
跟全文检索相对应,相反,全文检索会将输入的搜索串拆解开来,去倒排索引里面去一一匹配,只要能匹配上任意一个拆解后的单词,就可以作为结果返回
phrase search,要求输入的搜索串,必须在指定的字段文本中,完全包含一模一样的,才可以算匹配,才能作为结果返回
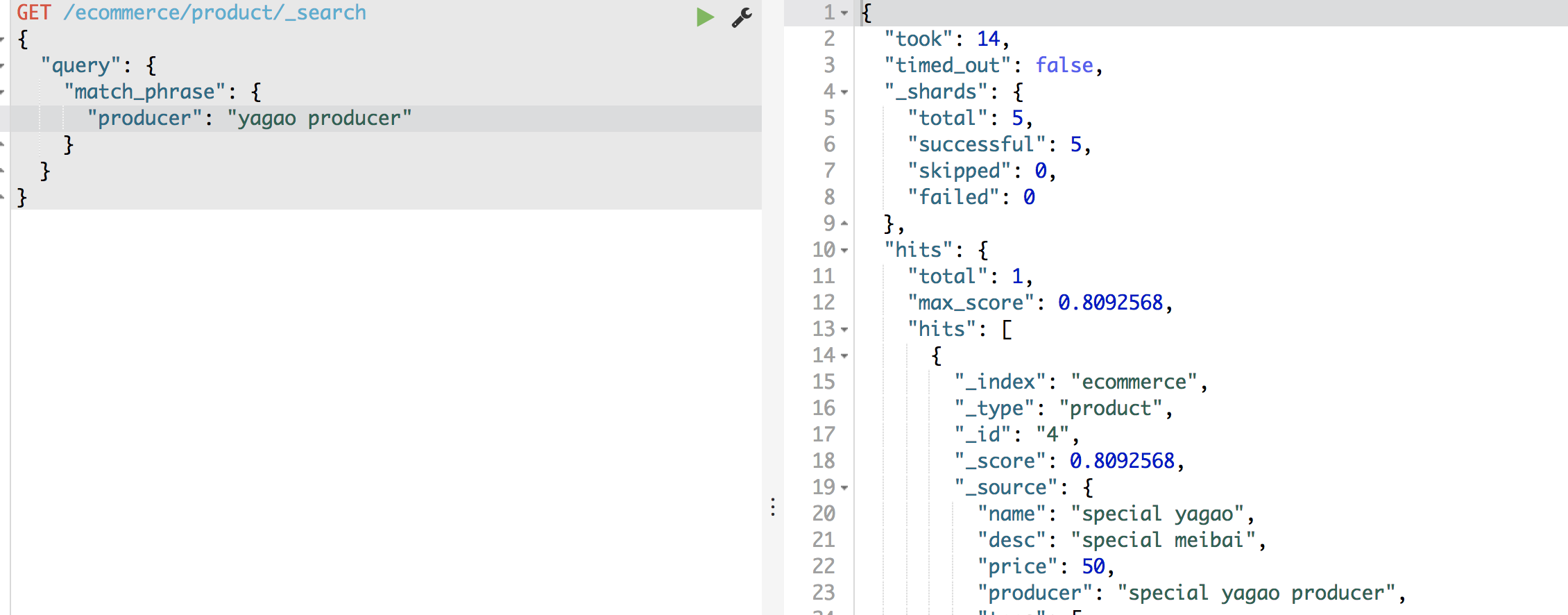
在yagao producer 之间多加几个空格也能匹配 没有空格 或者顺序颠倒都不能匹配
6、highlight search(高亮搜索结果)

嵌套聚合、下钻分析、聚合分析
1、计算每个tag下的商品 聚合:
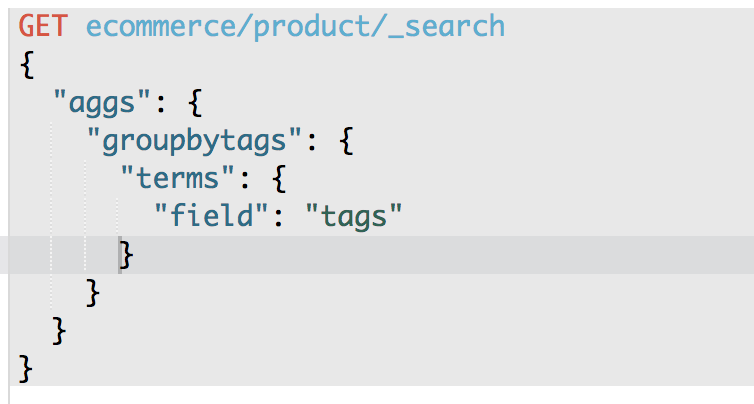
将文本filed的fileddata属性设置为true
PUT /ecommerce/_mapping/product
{
"properties": {
"tags": {
"type": "text",
"fielddata": true
}
}
}

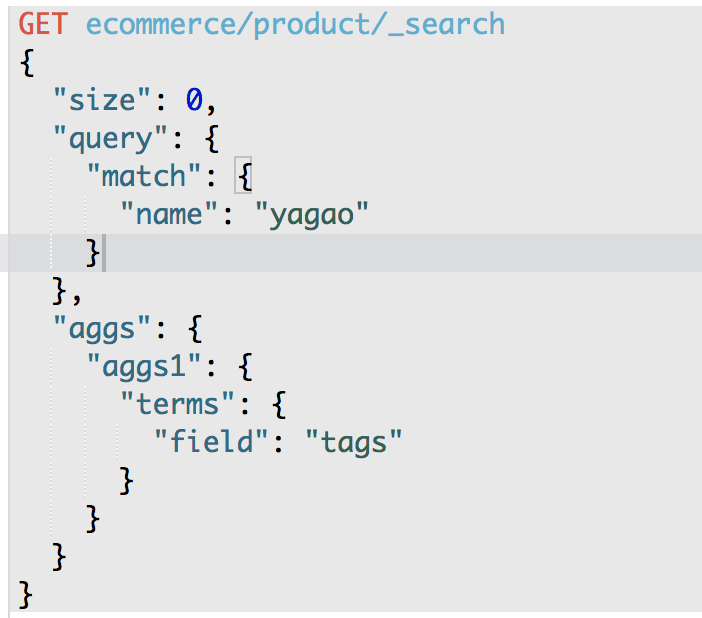
第二个聚合分析的需求:对名称中包含yagao的商品,计算每个tag下的商品数量
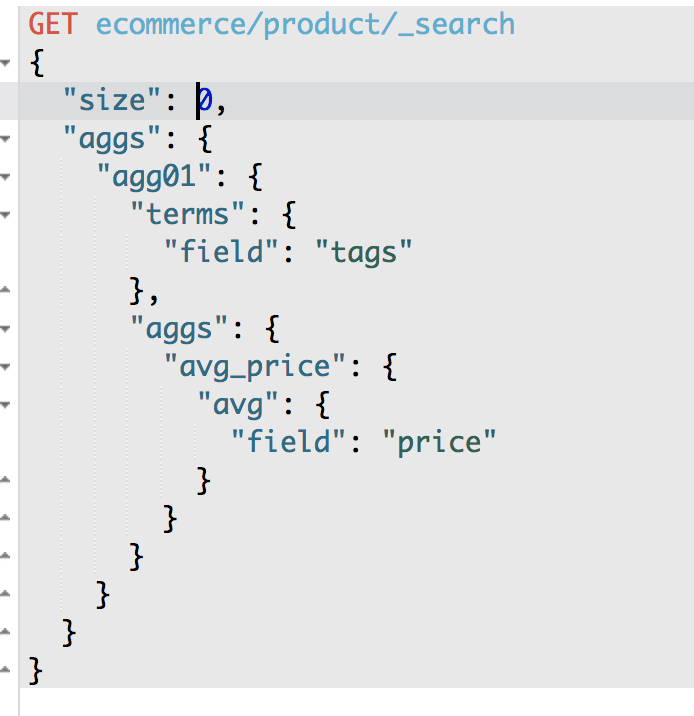
第三个聚合分析的需求:先分组,再算每组的平均值,计算每个tag下的商品的平均价格
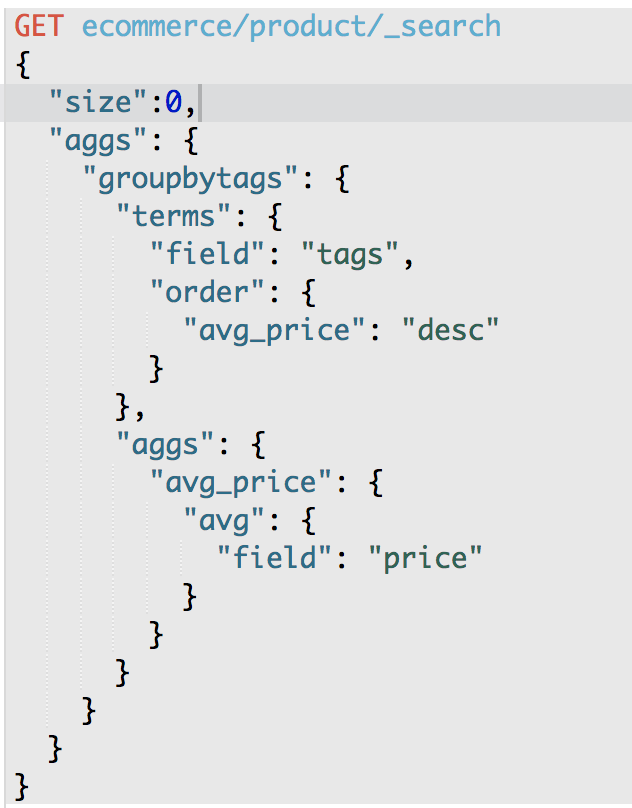
第四个数据分析需求:计算每个tag下的商品的平均价格,并且按照平均价格降序排序
第五个数据分析需求:按照指定的价格范围区间进行分组,然后在每组内再按照tag进行分组,最后再计算每组的平均价格

1、Elasticsearch对复杂分布式机制的透明隐藏特性
2、Elasticsearch的垂直扩容与水平扩容
3、增减或减少节点时的数据rebalance
4、master节点
5、节点对等的分布式架构
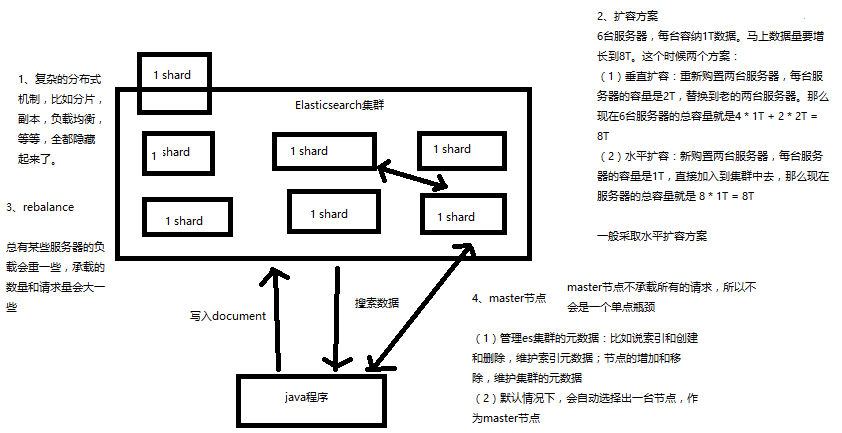
1、Elasticsearch对复杂分布式机制的透明隐藏特性
Elasticsearch是一套分布式的系统,分布式是为了应对大数据量
隐藏了复杂的分布式机制
分片机制(我们之前随随便便就将一些document插入到es集群中去了,我们有没有care过数据怎么进行分片的,数据到哪个shard中去)
cluster discovery(集群发现机制,我们之前在做那个集群status从yellow转green的实验里,直接启动了第二个es进程,那个进程作为一个node自动就发现了集群,并且加入了进去,还接受了部分数据,replica shard)
shard负载均衡(举例,假设现在有3个节点,总共有25个shard要分配到3个节点上去,es会自动进行均匀分配,以保持每个节点的均衡的读写负载请求)
shard副本,请求路由,集群扩容,shard重分配
2、Elasticsearch的垂直扩容与水平扩容
垂直扩容:采购更强大的服务器,成本非常高昂,而且会有瓶颈,假设世界上最强大的服务器容量就是10T,但是当你的总数据量达到5000T的时候,你要采购多少台最强大的服务器啊
水平扩容:业界经常采用的方案,采购越来越多的普通服务器,性能比较一般,但是很多普通服务器组织在一起,就能构成强大的计算和存储能力
普通服务器:1T,1万,100万
强大服务器:10T,50万,500万
扩容对应用程序的透明性
3、增减或减少节点时的数据rebalance
保持负载均衡
4、master节点
(1)创建或删除索引
(2)增加或删除节点
5、节点平等的分布式架构
(1)节点对等,每个节点都能接收所有的请求
(2)自动请求路由
(3)响应收集
请求转发
接收到请求的shard 自动将请求转发到目标document的shard 并且返回给client
第十讲:
1、shard&replica机制再次梳理
2、图解单node环境下创建index是什么样子的
------------------------------------------------------------------------------------------------
1、shard&replica机制再次梳理
(1)index包含多个shard
(2)每个shard都是一个最小工作单元,承载部分数据,lucene实例,完整的建立索引和处理请求的能力
(3)增减节点时,shard会自动在nodes中负载均衡
(4)primary shard和replica shard,每个document肯定只存在于某一个primary shard以及其对应的replica shard中,不可能存在于多个primary shard
(5)replica shard是primary shard的副本,负责容错,以及承担读请求负载
(6)primary shard的数量在创建索引的时候就固定了,replica shard的数量可以随时修改
(7)primary shard的默认数量是5,replica默认是1,默认有10个shard,5个primary shard,5个replica shard
(8)primary shard不能和自己的replica shard放在同一个节点上(否则节点宕机,primary shard和副本都丢失,起不到容错的作用),但是可以和其他primary shard的replica shard放在同一个节点上
------------------------------------------------------------------------------------------------
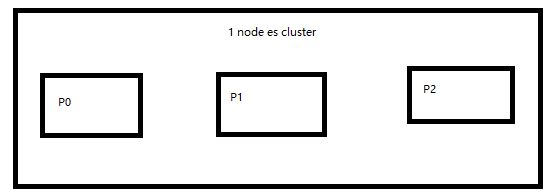
2、图解单node环境下创建index是什么样子的
(1)单node环境下,创建一个index,有3个primary shard,3个replica shard
(2)集群status是yellow
(3)这个时候,只会将3个primary shard分配到仅有的一个node上去,另外3个replica shard是无法分配的
(4)集群可以正常工作,但是一旦出现节点宕机,数据全部丢失,而且集群不可用,无法承接任何请求
PUT /test_index
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}

每个shard都是一个最小的单元 就是一个lucene实例 自动把shard均匀分布
每个document存在于一个primary shard 和它对应的replicate shard中
primaryshard的数量最开始固定了就不能变了 replica shard 的数量能改变
ES--01的更多相关文章
- ES 01 - Elasticsearch入门 + 基础概念学习
目录 1 Elasticsearch概述 1.1 Elasticsearch是什么 1.2 Elasticsearch的优点 1.3 Elasticsearch的相关产品 1.4 Elasticsea ...
- ES.01.Elasticsearch安装配置
Windows版 提纲: 1. 安装Elasticsearch 1.1. 下载Elasticsearch: https://www.elastic.co/cn/downloads/elastics ...
- [OpenGL ES 03]3D变换:模型,视图,投影与Viewport
[OpenGL ES 03]3D变换:模型,视图,投影与Viewport 罗朝辉 (http://blog.csdn.net/kesalin) 本文遵循“署名-非商业用途-保持一致”创作公用协议 系列 ...
- OpenGL ES教程系列(经典合集)
为了搞透播放器的开发,花了些时间收集这些资料,虽然我已经搞定opengles渲染视频的内容,但是想玩玩opengles,往深里玩,图像处理这块是个好的方向,所以opengles是值得好好学的. O ...
- 笔谈OpenGL ES(二)
昨晚回家也看了OpenGL ES 2.0 iOS教程的第一篇,对于其中涉及的一些基本知识罗列下,虽然自己做iOS开发一年多了,但是对于一些细节没有注意,真正的把自己当成“应用”工程师了 ,不仅要会用, ...
- [OpenGL ES 02]OpenGL ES渲染管线与着色器
[OpenGL ES 02]OpenGL ES渲染管线与着色器 罗朝辉 (http://www.cnblogs.com/kesalin/) 本文遵循"署名-非商业用途-保持一致"创 ...
- Percona XtraBackup User Manual 阅读笔记
XtraBackup XtraBackup 2 安装XtraBackup 2.1 安装XtraBackup binary版本 2.1.1 yum的安装方法: 2.1.2 直接下载rpm包安装 3 Xt ...
- xtrabackup原理1
http://www.cnblogs.com/Amaranthus/archive/2014/08/19/3922570.html Percona XtraBackup User Manual 阅读笔 ...
- 实战OpenGLES--iOS平台使用OpenGLES渲染YUV图片
上一篇文章 实战FFmpeg--iOS平台使用FFmpeg将视频文件转换为YUV文件 演示了如何将视频文件转换为yuv文件保存,现在要做的是如何将yuv文件利用OpenGLES渲染展示出图像画面.要将 ...
- OpenGL ES crash notes 01 - Nice to meet you
这篇笔记完全参照<OpenGL.ES.3.0.Programming.Guide.2nd.Edition>,摘出部分内容只为学习参考. 为什么要用英文:无论是D3D的SDK还是OES的Sp ...
随机推荐
- 牛客网数据库SQL实战(此处只有答案,没有表内容)
1.查找最晚入职员工的所有信息 select * from employees order by hire_date desc limit 1; --limit n表示输出前n条数据,limit ...
- mysql创建用户与pymsql模块
mysql 创建用户及增删改查 创建mysql 用户 with grant option 表示用户不存在自主创建 grant [ select ……,insert ……| all ] on 库名.表名 ...
- spring中整合memcached,以及创建memcache的put和get方法
spring中整合memcached,以及创建memcache的put和get方法: 1:在项目中导入memcache相关的jar包 2:memcache在spring.xml的配置: 代码: < ...
- CSS3 transform-origin 属性
<!DOCTYPE html> <html> <head> <style> #div1 { position: relative; height: 20 ...
- C#生成Guid,SqlServer生成Guid
https://www.cnblogs.com/che109/p/6808143.html工作中需要用到全球唯一标识符,在.net当中 微软已经为我们添加了此方法,我们只需要直接调用即可.代码如下: ...
- solr window环境安装配置和管理页面基本使用
solr介绍 来自官网http://lucene.apache.org/solr/解释: Solr is highly reliable, scalable and fault tolerant, p ...
- java实现数据缓存
摘抄自java并发实战 有时候需要对数据缓存.用Map缓存数据比较合适.但是由于对吞吐量,一致性,计算性能的要求,对数据进行缓存的设计还是需要慎重考虑的. 一.利用HashMap加同步 (1)说明 把 ...
- JS/javaScript 获取div内容
jquery: 例如<div id="abc"><a>内容</a></div>$("#abc").html(); ...
- Bootstrap响应式导航
<nav class="navbar navbar-default" role="navigation"> <div class=" ...
- 从一个数组对象中取key 和value组成一个新的对象
const type = [ {key:'TimeWeiDu',value:'时间维度'}, {key:'TranType',value:'交易类型'}, {key:'OrderType',value ...