Hadoop学习笔记(三):java操作Hadoop
1. 启动hadoop服务。
2. hadoop默认将数据存储带/tmp目录下,如下图:

由于/tmp是linux的临时目录,linux会不定时的对该目录进行清除,因此hadoop可能就会出现意外情况。下面对这个配置进行修改。修改core-site.xml文件vim /usr/local/hadoop/etc/hadoop/core-site.xml将这个值修改到/var/hadoop目录下
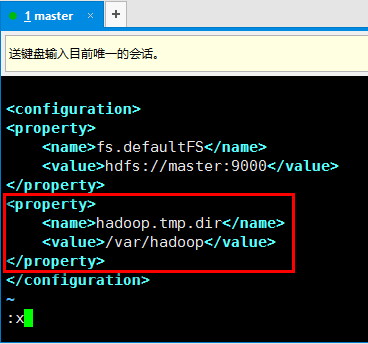
3. 修改完毕后,重启hadoop服务(stop-dfs.sh、start-dfs.sh),然后重新格式化namenode
hdfs namenode -format
4. 使用java来操作hdfs
5. 新建java项目,导入如下几个包:
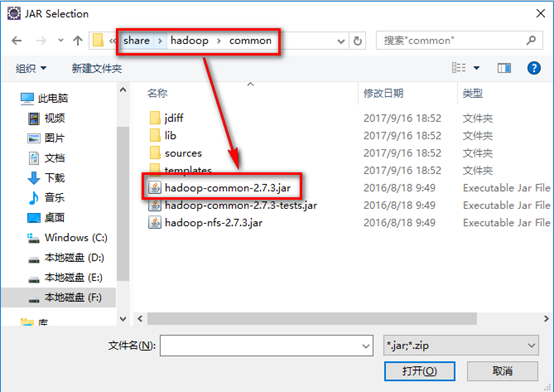
a). hadoop安装目录下share/hadoop/common下的common包
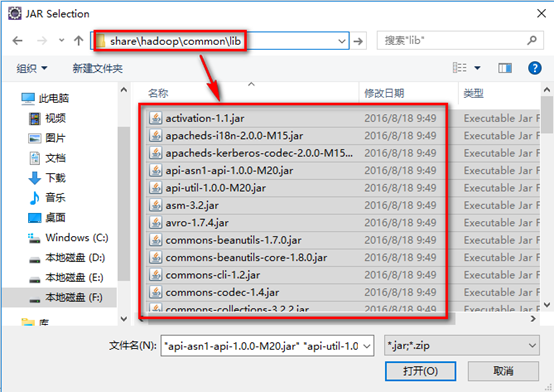
b). hadoop安装目录下share/hadoop/common/lib下的所有包
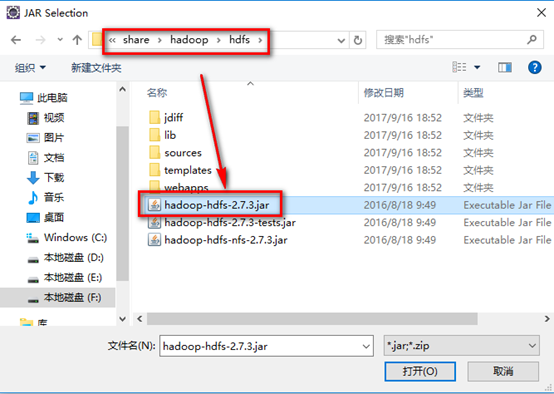
c). hadoop安装目录下share/hadoop/hdfs下的hdfs包
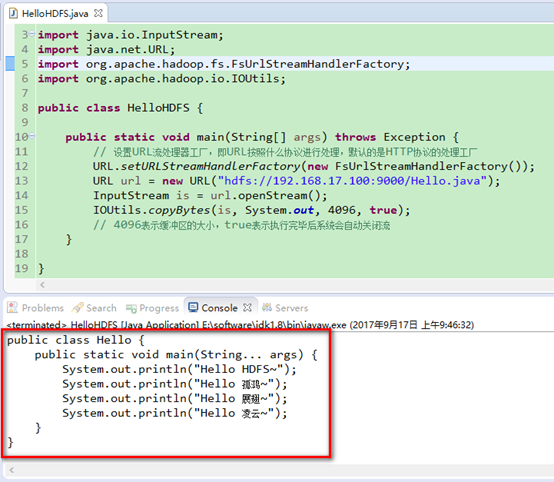
6. 新建java类HelloHDFS.java,测试java程序读取hadoop当中存储的文件。现在我的hadoop集群根目录当中有一个Hello.java文件,下面用java程序来读取它。
import java.io.InputStream;
import java.net.URL;
import org.apache.hadoop.fs.FsUrlStreamHandlerFactory;
import org.apache.hadoop.io.IOUtils; public class HelloHDFS {
public static void main(String[] args) throws Exception {
// 设置URL流处理器工厂,即URL按照什么协议进行处理,默认的是HTTP协议的处理工厂
URL.setURLStreamHandlerFactory(new FsUrlStreamHandlerFactory());
URL url = new URL("hdfs://192.168.17.100:9000/Hello.java");
InputStream is = url.openStream();
IOUtils.copyBytes(is, System.out, 4096, true);
// 4096表示缓冲区的大小,true表示执行完毕后系统会自动关闭流
}
}
7. 运行上述程序,观察结果,发现已经读取到了hadoop当中存储文件。
8. 上述为方式一,下面介绍一种更好用的方式。
// 方式二:
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.17.100:9000");
FileSystem fs = FileSystem.get(conf);
boolean success = fs.mkdirs(new Path("/skyer"));
System.out.println(success);
上述代码为在hadoop根目录下创建一个skyer目录(如果原来就有该目录,会覆盖),并打印创建结果,结果为true。若出现下图错误:
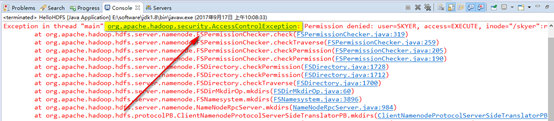
在core-site.xml文件中将dfs.permissions.enabled配置为false,或者输入以下命令hadoop fs -chmod 777 /修改hadoop根目录的权限(危险,不推荐),还有一个方法是在windows机器上配置一个环境变量HADOOP-USER_NAME,还有一种方法是将
FileSystem fs = FileSystem.get(conf);
替换成
FileSystem fs = FileSystem.get(new URI("hdfs://192.168.17.100:9000"),conf,"root");
9. 其他操作hadoop的示例,直接看代码:
public class HelloHDFS {
public static void main(String[] args) throws Exception {
// 方式二:
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://192.168.17.100:9000");
FileSystem fs = FileSystem.get(conf);
boolean success = fs.mkdirs(new Path("/skyer")); // 创建目录
System.out.println(success);
success = fs.exists(new Path("/skyer")); // 判断文件或者目录是否存在
System.out.println(success);
success = fs.delete(new Path("/skyer"), true);
// 删除,第二个参数为true的话会真正的删除文件,为false的话是将该文件放到垃圾桶里
System.out.println(success);
// 上传文件到hadoop
FSDataOutputStream out = fs.create(new Path("/upload.data"), true);
FileInputStream fis = new FileInputStream("E://HelloHDFS.java");
IOUtils.copyBytes(fis, out, 4096, true);
// 列取目录下所有文件和目录的信息
FileStatus[] statuses = fs.listStatus(new Path("/"));
for (FileStatus status : statuses) {
System.out.println(status.getPath());
System.out.println(status.getPermission());
System.out.println(status.getReplication());
}
}
}
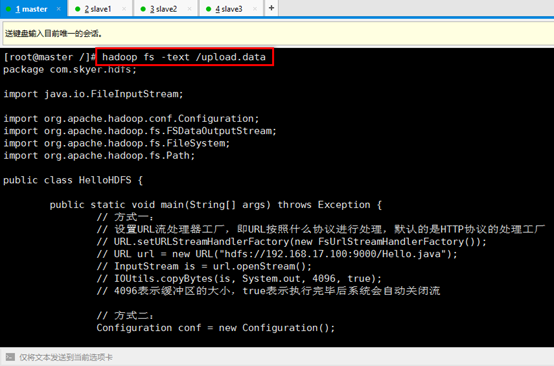
10. 在master机器上输入命令hadoop fs -text /upload.data进行查看示例中上传的文件,类似linux里的cat命令
Hadoop学习笔记(三):java操作Hadoop的更多相关文章
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
- Hadoop学习笔记——入门指令操作
假设Hadoop的安装目录HADOOP_HOME为/home/admin/hadoop. 启动与关闭启动HADOOP1. 进入HADOOP_HOME目录. 2. 执行sh bin/start-all. ...
- Hadoop学习笔记(一)Hadoop的单节点安装
要想深入学习Hadoop分布式文件系统,首先需要搭建Hadoop的实验环境,Hadoop有两种安装模式,即单节点集群模式安装(也称为伪分布式)和完全分布式模式安装,本节只介绍单节点模式的安装,参考官方 ...
- hadoop学习笔记(五)hadoop伪分布式集群的搭建
本文原创,如需转载,请注明作者和原文链接 1.集群搭建的前期准备 见 搭建分布式hadoop环境的前期准备---需要检查的几个点 2.解压tar.gz包 [root@node01 ~]# ...
- Hadoop学习笔记三
一.设置HDFS不进行权限检查 默认的HDFS上的文件类似于Linux中的文件,是有权限的.例如test用户创建的文件,root用户如果没有写权限,则不能进行删除. 有2种办法进行修改,修改文件的权限 ...
- Hadoop学习笔记(三) ——HDFS
参考书籍:<Hadoop实战>第二版 第9章:HDFS详解 1. HDFS基本操作 @ 出现的bug信息 @-@ WARN util.NativeCodeLoader: Unable to ...
- Hadoop学习笔记(2)hadoop框架解析
Hadoop是适合大数据的分布式存储与计算平台 HDFS的架构:主从式结构 主节点只有一个NameNode,从节点可以有很多个DataNode. NameNode负责: (1)接收用户操作请求 (2) ...
- Java基础学习笔记三 Java基础语法
Scanner类 Scanner类属于引用数据类型,先了解下引用数据类型. 引用数据类型的使用 与定义基本数据类型变量不同,引用数据类型的变量定义及赋值有一个相对固定的步骤或格式. 数据类型 变量名 ...
- Hadoop学习笔记(4)hadoop集群模式安装
具体的过程参见伪分布模式的安装,集群模式的安装和伪分布模式的安装基本一样,只有细微的差别,写在下面: 修改masers和slavers文件: 在hadoop/conf文件夹中的配置文件中有两个文件ma ...
- Hadoop学习笔记(3)hadoop伪分布模式安装
为了学习这部分的功能,我们这里的linux都是使用root用户登录的.所以每个命令的前面都有一个#符号. 伪分布模式安装步骤: 关闭防火墙 修改ip地址 修改hostname 设置ssh自动登录 安装 ...
随机推荐
- Runtime常用的几个场景
1.给分类动态添加属性 在FDFullscreenPopGesture中给UIViewController的分类里有这么一个属性: @property (nonatomic, copy) _FDVie ...
- 2019.03.25 bzoj4539: [Hnoi2016]树(主席树+倍增)
传送门 题意:给一棵大树,令一棵模板树与这棵树相同,然后进行mmm次操作,每次选择模板树中的一个节点aaa和大树中一个节点bbb,把aaa这棵子树接在bbb上面,节点编号顺序跟aaa中的编号顺序相同. ...
- php数组排序sort
php的数组分为数字索引型的数组,和关键字索引的数组.如果是数字索引的,可以这样使用:$names = ['Tom', 'Rocco','amiona'];sort($names);sort()函数只 ...
- C#运行时通过字符串实例化类对象
备忘,记个C#版本. using System; using System.Collections.Generic; using System.Linq; using System.Text; usi ...
- 记一次需要用到复杂的groupingBy的需求
一:先定义结构 public class Foo { private Integer id; private String name; private BigDecimal amount; publi ...
- table增删改查操作--jq
<!doctype html> <html> <head> <meta charset="utf-8"> <title> ...
- STM32-跑马灯实验
实验环境: STM32开发板 Keil uVision4 FlyMcu.exe 一. 建立文件夹 1.建立跟文件夹"BASE"(名称任意),再在其下建立四个子文件夹 2. 在&qu ...
- 12-Python操作json
1.概述 Python操作json文件在测试中会经常用到,那么python怎么操作json文件呢,今天就来简单了解一下.Python中提供了dumps.dump.loads.load,用于字符串 和 ...
- jQuery-爱奇艺图片切换
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- Javascript高级编程学习笔记(38)—— DOM(4)Text
Text类型 html页面中的纯文本内容就属于Text类型 纯文本内容可以包含转义后的html字符,但不能包括 html 代码 text类型具有以下属性.方法 nodeType:3 nodeName: ...