分布式事务?咱先弄明白本地事务再说 - ACID
过去一段时间面试的同学,对于数据库事务,可以按照配置正常使用,但很多都无法讲清楚和理解数据库事务这个东西真正的意义,以及互联网兴起以后,当今数据库在ACID面前面临怎样的问题和抉择。
事务,是各大单机SQL数据库厂商包括Oracle、IBM DB2等,早在上世纪80年代提出的一个解决 数据并发操作处理的模型 ,旨在满足多用户(多线程、进程)对数据操作的场景下,依然能保证逻辑正确执行,状体持久,且各大厂商提出,并在事务实现上都遵循事务的 ACID 4个特性。
回顾ACID
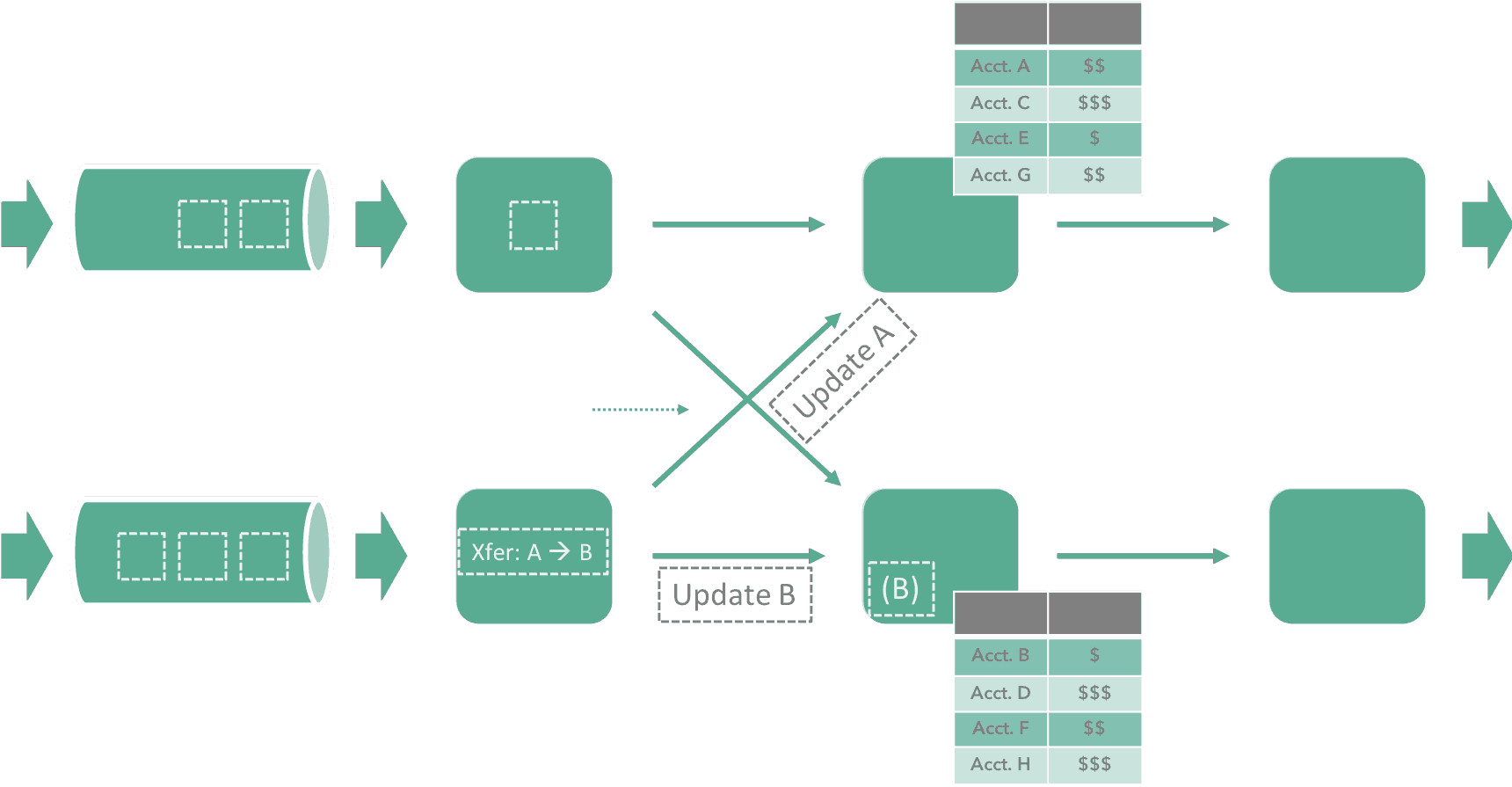
一个模块,是多个独立的功能逻辑的组合,每个功能包含多个操作步骤,包括IO、计算、数据库等操作,必须保证每一步都被执行,且执行正确,这个功能和模块才是可用,可交付的。

那么,如何保证这些操作的完整性,就是Atomic,定义为一个原子操作,全部执行且成功,或者全部失败都不执行(回滚),原子操作如果成功,那状态就必须持久,被称为数据库的Durability,持久性。
原子性A、持久性D,这俩个都比较好理解,定义了事务的边界,行为的开始和行为的结束。
A、D定义了事务的边界,那一致性C、隔离性I,就是对事务中间状态的管理,
一致性,也可以理解为是数据的完整性,数据的有效性,我们举例来说明什么是一致性,以及事务是如何保证一致性的,
- 一个账户减100,另一个账户加100的时候,程序异常crash了,这时候就出现数据的不一致情况,破坏了有效性,这个问题可以由Atomic来保证;
- 一个原子操作在执行的过程中,涉及多个数据变更的中间状态的保护,例如把A账户减100,在加到B账户完成这个原子操作之前,此时,其他线程对A读的操作就有可能获取到A少100的这个中间状态,这种情况是否允许发生,由Isolation来保证;
- 数据库延迟约束,例如数据字段的类型、空值、关系、数据范围、主键唯一性等这些合法性的检查都是由Durability来保证,在事务commit时,发现数据不合法,是无法提交成功的。
所以,综上所述,一致性C,是数据状态的正确变换的保证,AID,是实现C的手段,也是我们真正要追求的目标。
而,隔离性I的设定,就是对一致性C不同程度的破坏,事实上,如果我们顺序对数据进行读写,ACD是完全可用保证的,但这样效率会非常的低下,那,我们是要严格的一致性,还是更高的效率,数据库专家们把这个决定权交给了用户,所以,我们看到,ACID当中,只有隔离性I是用户可以选择的,可以自定义的。
隔离性包括 串行读、读已提交、重复读、读未提交 等几种策略,性能由低到高,让用户在不同的使用场景,选择合适的隔离策略,在一致性和性能之间平衡,取得最好的综合表现。
小结
本文主要介绍了事务和事务的几个特性,解释了ACID的由来和之间的关系,
总的来说,ACID的核心是C,大家其实都是为得到C而提出的不同纬度的限制和规范,A确定一个功能的完整性,D对状态负责,I可以说是C的等级系数,不同的I的策略,会出现不同的级别的C,AID是数据库本身的功能特性,C由业务层把控,要严格的C,就设置完整的数据库约束和串行隔离,反之,要宽松的C,就放开数据库的约束,使用读未提交的隔离策略,存在即合理,后者更适用于互联网高并发对一致性要求不高的场景,例如分布式的AP系统,可以保证服务整体的响应时间和服务的可用性。
分布式事务?咱先弄明白本地事务再说 - ACID的更多相关文章
- 终于有人把“TCC分布式事务”实现原理讲明白了!
之前网上看到很多写分布式事务的文章,不过大多都是将分布式事务各种技术方案简单介绍一下.很多朋友看了还是不知道分布式事务到底怎么回事,在项目里到底如何使用. 所以这篇文章,就用大白话+手工绘图,并结合一 ...
- 终于有人把“TCC分布式事务”实现原理讲明白了
所以这篇文章,就用大白话+手工绘图,并结合一个电商系统的案例实践,来给大家讲清楚到底什么是 TCC 分布式事务. 首先说一下,这里可能会牵扯到一些 Spring Cloud 的原理,如果有不太清楚的同 ...
- MySQL的本地事务、全局事务、分布式事务
本地事务 事务特性:ACID,其中C一致性是目的,AID是手段. 实现隔离性 写锁:数据加了写锁,其他事务不能写也不能读. 读锁:数据加了读锁,其他事务不能加写锁可以加读锁,可以允许自己升级为写锁. ...
- 后端分布式系列:分布式存储-MySQL 数据库事务与复制
好久没有写技术文章了,因为一直在思考 「后端分布式」这个系列到底怎么写才合适.最近基本想清楚了,「后端分布式」包括「分布式存储」和 「分布式计算」两大类.结合实际工作中碰到的问题,以寻找答案的方式来剖 ...
- java事务(二)——本地事务
本地事务 事务类型 事务可以分为本地事务和分布式事务两种类型.这两种事务类型是根据访问并更新的数据资源的多少来进行区分的.本地事务是在单个数据源上进行数据的访问和更新,而分布式事务是跨越多个数据源来进 ...
- Java中的事务——全局事务与本地事务
转载,原文来源 http://www.hollischuang.com Java事务的类型有三种:JDBC事务.JTA(Java Transaction API)事务.容器事务.这是从事务的实现角度区 ...
- Spring3.0+Hibernate+Atomikos集成构建JTA的分布式事务--解决多数据源跨库事务
一.概念 分布式事务分布式事务是指事务的参与者.支持事务的服务器.资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上.简言之,同时操作多个数据库保持事务的统一,达到跨库事务的效果. JTA ...
- JMS学习五(ActiveMQ的本地事务)
1.ActiveMQ的本地事务 在一个JMS客户端,可以使用本地事务来组合消息的发送和接收.JMS Session接口提供了commit和rollback方法.事务提交意味着生产的所有消息被发送,消费 ...
- 超干货!为了让你彻底弄懂MySQL事务日志,我通宵肝出了这份图解!
还记得刚上研究生的时候,导师常挂在嘴边的一句话,"科研的基础不过就是数据而已."如今看来,无论是人文社科,还是自然科学,或许都可在一定程度上看作是数据的科学. 倘若剥开研究领域的外 ...
随机推荐
- netstat常见基本用法(转)
netstat 简介 Netstat 是一款命令行工具,可用于列出系统上所有的网络套接字连接情况,包括 tcp, udp 以及 unix 套接字,另外它还能列出处于监听状态(即等待接入请求)的套接字. ...
- Java编制至今总结和学习报告
日期:2018.8.19 星期日 博客期:006 说个事,本来想把博客园做一个交流平台的,可是交流度有点少...嗯...我看我还是把这个平台当作经验传授平台和自己的作品发布平台吧!Java的知识详解, ...
- xilinx_all_version.lic
INCREMENT ISE_Vivado_Seth xilinxd -dec- uncounted \ C25FB036D304 VENDOR_STRING=License_Type:Bought H ...
- 自定义Web框架
http协议 HTTP简介 HTTP协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW:World Wide Web )服务器传输超文本到本 ...
- TypeError: $(…).tooltip is not a function
问题描述:改了一个页面,发现进入这个页面的时候就一直在load···,F12看了一下,发现报了这个错误TypeError: $(…).tooltip is not a function,然后我就百度了 ...
- mysql中有多种存储引擎,每种引擎都有自己的特色
mysql中有多种存储引擎,每种引擎都有自己的特色. 用途: MyISAM:快读, Memory:内存数据, InnoDB:完整的事务支持 锁: MyISAM:全表锁定, Memory:全表锁定, I ...
- java----DOS命令
dir /? 查看帮助 dir /s 查看当前的目录,以及子目录
- 如何使用Scrapy框架实现网络爬虫
现在用下面这个案例来演示如果爬取安居客上面深圳的租房信息,我们采取这样策略,首先爬取所有租房信息的链接地址,然后再根据爬取的地址获取我们所需要的页面信息.访问次数多了,会被重定向到输入验证码页面,这个 ...
- 各厂商服务器存储默认管理口登录信息(默认IP、用户名、密码)收集
666:https://blog.csdn.net/xiezuoyong/article/details/84997917
- C#学习-方法
方法是由方法签名和一系列语句的代码块组成. 其中方法签名包括方法的访问级别(比如public或private).可修饰符(例如abstract关键字).方法名称和参数. C#也支持方法重载.方法重载指 ...