信息摘要算法之二:SHA1算法分析及实现
SHA算法,即安全散列算法(Secure Hash Algorithm)是一种与MD5同源的数据加密算法,该算法经过加密专家多年来的发展和改进已日益完善,现在已成为公认的最安全的散列算法之一,并被广泛使用。
1、概述
SHA算法能计算出一个数位信息所对应到的,长度固定的字串,又称信息摘要。而且如果输入信息有任何的不同,输出的对应摘要不同的机率非常高。因此SHA算法也是FIPS所认证的五种安全杂凑算法之一。原因有两点:一是由信息摘要反推原输入信息,从计算理论上来说是极为困难的;二是,想要找到两组不同的输入信息发生信息摘要碰撞的几率,从计算理论上来说是非常小的。任何对输入信息的变动,都有很高的几率导致的信息摘要大相径庭。
SHA实际上是一系列算法的统称,分别包括:SHA-1、SHA-224、SHA-256、SHA-384以及SHA-512。后面4中统称为SHA-2,事实上SHA-224是SHA-256的缩减版,SHA-384是SHA-512的缩减版。各中SHA算法的数据比较如下表,其中的长度单位均为位:
|
类别 |
SHA-1 |
SHA-224 |
SHA-256 |
SHA-384 |
SHA-512 |
|
消息摘要长度 |
160 |
224 |
256 |
384 |
512 |
|
消息长度 |
小于264位 |
小于264位 |
小于264位 |
小于2128位 |
小于2128位 |
|
分组长度 |
512 |
512 |
512 |
1024 |
1024 |
|
计算字长度 |
32 |
32 |
32 |
64 |
64 |
|
计算步骤数 |
80 |
64 |
64 |
80 |
80 |
SHA-1在许多安全协定中广为使用,包括TLS和SSL、PGP、SSH、S/MIME和IPsec,曾被视为是MD5的后继者。SHA1主要适用于数字签名标准(Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA)。对于长度小于264位的消息,SHA1会产生一个160位的消息摘要。
2、基本原理
前面我们简单的介绍了SHA算法族,接下来我们以SHA-1为例来分析其基本原理。SHA-1是一种数据加密算法,该算法的思想是接收一段明文,然后以一种不可逆的方式将它转换成一段密文,也可以简单的理解为输入一串二进制码,并把它们转化为长度较短、位数固定的输出序列即散列值,也称为信息摘要或信息认证代码的过程。
SHA-1算法输入报文的最大长度不超过264位,产生的输出是一个160位的报文摘要。输入是按512 位的分组进行处理的。SHA-1是不可逆的、防冲突,并具有良好的雪崩效应。
一般来说SHA-1算法包括有如下的处理过程:
(1)、对输入信息进行处理
既然SHA-1算法是对给定的信息进行处理得到相应的摘要,那么首先需要按算法的要求对信息进行处理。那么如何处理呢?对输入的信息按512位进行分组并进行填充。如何填充信息报文呢?其实即使填充报文后使其按512进行分组后,最后正好余448位。那填充什么内容呢?就是先在报文后面加一个1,再加很多个0,直到长度满足对512取模结果为448。到这里可能有人会奇怪,为什么非得是448呢?这是因为在最后会附加上一个64位的报文长度信息,而448+64正好是512。
(2)、填充长度信息
前面已经说过了,最后会补充信息报文使其按512位分组后余448位,剩下的64位就是用来填写报文的长度信息的。至次可能大家也明白了前面说过的报文长度不能超过264位了。填充长度值时要注意必须是低位字节优先。
(3)信息分组处理
经过添加位数处理的明文,其长度正好为512位的整数倍,然后按512位的长度进行分组,可以得到一定数量的明文分组,我们用Y0,Y1,……YN-1表示这些明文分组。对于每一个明文分组,都要重复反复的处理,这些与MD5都是相同的。
而对于每个512位的明文分组,SHA1将其再分成16份更小的明文分组,称为子明文分组,每个子明文分组为32位,我们且使用M[t](t= 0, 1,……15)来表示这16个子明文分组。然后需要将这16个子明文分组扩充到80个子明文分组,我们将其记为W[t](t= 0, 1,……79),扩充的具体方法是:当0≤t≤15时,Wt = Mt;当16≤t≤79时,Wt = ( Wt-3 ⊕ Wt-8⊕ Wt-14⊕ Wt-16) <<< 1,从而得到80个子明文分组。
(4)初始化缓存
所谓初始化缓存就是为链接变量赋初值。前面我们实现MD5算法时,说过由于摘要是128位,以32位为计算单位,所以需要4个链接变量。同样SHA-1采用160位的信息摘要,也以32位为计算长度,就需要5个链接变量。我们记为A、B、C、D、E。其初始赋值分别为:A = 0x67452301、B = 0xEFCDAB89、C = 0x98BADCFE、D = 0x10325476、E = 0xC3D2E1F0。
如果我们对比前面说过的MD5算法就会发现,前4个链接变量的初始值是一样的,因为它们本来就是同源的。
(5)计算信息摘要
经过前面的准备,接下来就是计算信息摘要了。SHA1有4轮运算,每一轮包括20个步骤,一共80步,最终产生160位的信息摘要,这160位的摘要存放在5个32位的链接变量中。
在SHA1的4论运算中,虽然进行的就具体操作函数不同,但逻辑过程却是一致的。首先,定义5个变量,假设为H0、H1、H2、H3、H4,对其分别进行如下操作:
(A)、将A左移5为与 函数的结果求和,再与对应的子明文分组、E以及计算常数求和后的结果赋予H0。
(B)、将A的值赋予H1。
(C)、将B左移30位,并赋予H2。
(D)、将C的值赋予H3。
(E)、将D的值赋予H4。
(F)、最后将H0、H1、H2、H3、H4的值分别赋予A、B、C、D
这一过程表示如下:

而在4轮80步的计算中使用到的函数和固定常熟如下表所示:
|
计算轮次 |
计算的步数 |
计算函数 |
计算常数 |
|
第一轮 |
0≤t≤19步 |
ft(B,C,D)=(B&C)|(~B&D) |
Kt=0x5A827999 |
|
第二轮 |
20≤t≤39步 |
ft(B,C,D)=B⊕C⊕D |
Kt=0x6ED9EBA1 |
|
第三轮 |
40≤t≤59步 |
ft(B,C,D)=(B&C)|(B&D)|(C&D) |
Kt=0x8F188CDC |
|
第四轮 |
60≤t≤79步 |
ft(B,C,D)=B⊕C⊕D |
Kt=0xCA62C1D6 |
经过4论80步计算后得到的结果,再与各链接变量的初始值求和,就得到了我们最终的信息摘要。而对于有多个铭文分组的,则将前面所得到的结果作为初始值进行下一明文分组的计算,最终计算全部的明文分组就得到了最终的结果。
3、软件实现
经过前面的分析过程,接下来要具体实现SHA1算法其实已经很简单了!下面来一步步实现它,首先实现初始化函数:
/* SHA1Reset函数用于初始化SHA1的内容值 */
/* 参数:context,SHA的内容值,存储计算结果既初始值,输入输出 */
/* 返回值:SHA错误代码 */
ErrorCode SHA1Reset(SHA1Context *context)
{
if (!context)
{
return shaNull;
} context->Length_Low = ;
context->Length_High = ;
context->Message_Block_Index = ; context->Intermediate_Hash[] = 0x67452301;
context->Intermediate_Hash[] = 0xEFCDAB89;
context->Intermediate_Hash[] = 0x98BADCFE;
context->Intermediate_Hash[] = 0x10325476;
context->Intermediate_Hash[] = 0xC3D2E1F0; context->Computed = ;
context->Corrupted = ; return shaSuccess;
}
接下来实现明文信息的读取及处理函数,该函数读取信息分组,并输入前次计算的结果,对除最后一组信息外的全部分组进行信息摘要计算。
/* SHA1Input函数,将分组的信息读入并进行摘要计算 */
/* 参数: */
/* context,SHA的内容值,存储计算结果既初始值,输入输出 */
/* message_array,待处理的信息分组的字节数组,输入参数 */
/* length,message_array数组中信息的长度 */
/* 返回值:SHA错误代码 */
ErrorCode SHA1Input(SHA1Context *context,const uint8_t *message_array,unsigned length)
{
if (!length)
{
return shaSuccess;
} if (!context || !message_array)
{
return shaNull;
} if (context->Computed)
{
context->Corrupted = shaStateError; return shaStateError;
} if (context->Corrupted)
{
return (ErrorCode)context->Corrupted;
}
while(length-- && !context->Corrupted)
{
context->Message_Block[context->Message_Block_Index++] = (*message_array & 0xFF); context->Length_Low += ;
if (context->Length_Low == )
{
context->Length_High++;
if (context->Length_High == )
{
/* 消息长度超过限值 */
context->Corrupted = ;
}
} if (context->Message_Block_Index == )
{
SHA1ProcessMessageBlock(context);
} message_array++;
} return shaSuccess;
}
然后实现结果输出函数,该函数对信息的最后部分进行处理并返回160位的信息摘要到Message_Digest数组,该数组作为参数有调用者输入。第一个元素存第一个字节,依次20个字节。
/* SHA1Result函数,对信息的最后部分进行处理并输出最终计算结果 */
/* 参数: */
/* context,SHA的内容值,存储计算结果既初始值,输入输出 */
/* Message_Digest,信息摘要的返回值,输出参数 */
/* 返回值:SHA错误代码 */
ErrorCode SHA1Result( SHA1Context *context,uint8_t Message_Digest[SHA1HashSize])
{
int i; if (!context || !Message_Digest)
{
return shaNull;
} if (context->Corrupted)
{
return (ErrorCode)context->Corrupted;
} if (!context->Computed)
{
SHA1PadMessage(context);
for(i=; i<; ++i)
{
/* 处理完毕,清除消息分组 */
context->Message_Block[i] = ;
}
context->Length_Low = ; /* 清除长度数据 */
context->Length_High = ;
context->Computed = ;
} for(i = ; i < SHA1HashSize; ++i)
{
Message_Digest[i] = context->Intermediate_Hash[i>>]>>*(-(i&0x03));
} return shaSuccess;
}
还需要实现消息分组的处理函数。该函数处理存储于Message_Block数组中的,待处理的512位的明文分组,将其处理为80个子明文分组,并进行4轮80步运算,返回相应的摘要值。
/* SHA1ProcessMessageBlock函数,处理消息分组 */
/* 描述: */
/* 参数: */
/* context,SHA的内容值,存储计算结果既初始值,输入输出 */
/* 返回值:无 */
static void SHA1ProcessMessageBlock(SHA1Context *context)
{
/* SHA-1计算中用到的常数定义 */
const uint32_t K[]={0x5A827999,0x6ED9EBA1,0x8F1BBCDC,0xCA62C1D6}; int t; /* 循环变量 */
uint32_t temp; /* 临时变量,存计算值 */
uint32_t W[]; /* 子明文分组数组 */
uint32_t A, B, C, D, E; /* 初始值缓存变量 */ /* 初始化子明文分组W的前16个字 */
for(t = ; t < ; t++)
{
W[t] = context->Message_Block[t * ] << ;
W[t] |= context->Message_Block[t * + ] << ;
W[t] |= context->Message_Block[t * + ] << ;
W[t] |= context->Message_Block[t * + ];
} for(t = ; t < ; t++)
{
W[t] = SHA1CircularShift(,W[t-] ^ W[t-] ^ W[t-] ^ W[t-]);
} A = context->Intermediate_Hash[];
B = context->Intermediate_Hash[];
C = context->Intermediate_Hash[];
D = context->Intermediate_Hash[];
E = context->Intermediate_Hash[]; /*第1轮20步计算*/
for(t = ; t < ; t++)
{
temp = SHA1CircularShift(,A)+((B & C) | ((~B) & D)) + E + W[t] + K[];
E = D;
D = C;
C = SHA1CircularShift(,B);
B = A;
A = temp;
} /*第2轮20步计算*/
for(t = ; t < ; t++)
{
temp = SHA1CircularShift(,A) + (B ^ C ^ D) + E + W[t] + K[];
E = D;
D = C;
C = SHA1CircularShift(,B);
B = A;
A = temp;
} /*第3轮20步计算*/
for(t = ; t < ; t++)
{
temp = SHA1CircularShift(,A)+((B & C) | (B & D) | (C & D)) + E + W[t] + K[];
E = D;
D = C;
C = SHA1CircularShift(,B);
B = A;
A = temp;
} /*第4轮20步计算*/
for(t = ; t < ; t++)
{
temp = SHA1CircularShift(,A) + (B ^ C ^ D) + E + W[t] + K[];
E = D;
D = C;
C = SHA1CircularShift(,B);
B = A;
A = temp;
} context->Intermediate_Hash[] += A;
context->Intermediate_Hash[] += B;
context->Intermediate_Hash[] += C;
context->Intermediate_Hash[] += D;
context->Intermediate_Hash[] += E; context->Message_Block_Index = ;
}
还需要实现一个对消息进行补位和追加消息长度并进行处理的函数。根据标准,消息必须被填充到一个剩至512位。第一个填充位必须是'1'。最后64位表示原始消息的长度。中间的所有位都应该是0。该函数将根据这些规则填充消息,并相应地填充Message_Block数组。
/* SHA1PadMessage函数,补全消息,并添加长度,计算最终结果 */
/* 参数: */
/* context,SHA的内容值,存储计算结果既初始值,输入输出 */
/* 返回值:无 */
static void SHA1PadMessage(SHA1Context *context)
{
/* 检查当前的消息分组,如果小于等于55个字节,则直接添加补位和长度信息。否则,如果大于55个字节,我们填充块到512位,并处理它,然后继续填充到第二个块中直道448位,最后填写长度信息。*/
if (context->Message_Block_Index > )
{
context->Message_Block[context->Message_Block_Index++] = 0x80;
while(context->Message_Block_Index < )
{
context->Message_Block[context->Message_Block_Index++] = ;
} SHA1ProcessMessageBlock(context); while(context->Message_Block_Index < )
{
context->Message_Block[context->Message_Block_Index++] = ;
}
}
else
{
context->Message_Block[context->Message_Block_Index++] = 0x80;
while(context->Message_Block_Index < )
{
context->Message_Block[context->Message_Block_Index++] = ;
}
} /* 将明文长度填入到最后8个字节中 */
context->Message_Block[] = context->Length_High >> ;
context->Message_Block[] = context->Length_High >> ;
context->Message_Block[] = context->Length_High >> ;
context->Message_Block[] = context->Length_High;
context->Message_Block[] = context->Length_Low >> ;
context->Message_Block[] = context->Length_Low >> ;
context->Message_Block[] = context->Length_Low >> ;
context->Message_Block[] = context->Length_Low; SHA1ProcessMessageBlock(context);
}
至此SHA1散列算法就全部实现完了,需要说明一下的是相应的结构体定义和错误代码的定义如下:
/* 定义SHA-1内容保存结构体 */
typedef struct SHA1Context
{
uint32_t Intermediate_Hash[SHA1HashSize/]; /* 信息摘要 */ uint32_t Length_Low; /* 按位计算的信息长度低字 */
uint32_t Length_High; /* 按位计算的信息长度高字 */ int_least16_t Message_Block_Index; /* 信息分组数组的索引 */
uint8_t Message_Block[]; /* 512位信息分组 */ int Computed; /* 摘要计算标识 */
int Corrupted; /* 信息摘要损坏标识 */
} SHA1Context; typedef enum
{
shaSuccess = , /* 处理成功 */
shaNull, /* 指针参数为NUll */
shaInputTooLong, /* 输入消息长度超范围 */
shaStateError /* 在处理完毕后,未经初始化直接调用输入处理 */
}ErrorCode;
4、总结
我们已经实现了SHA1这一散列算法,接下来我们验证一下它的效果如何。首先我们输入信息“abcdef”,计算结果,并使用通用工具验算。
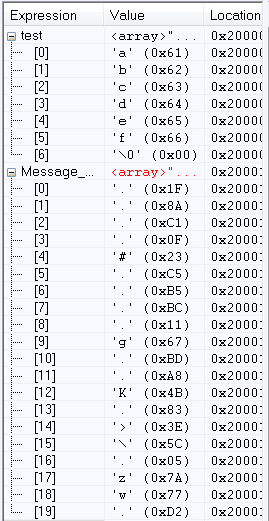

以上2图我们可以看到结果是一致的,接下来我们输入信息:“a1b23c4d5e6f7g8h9i0j”,计算结果如下:
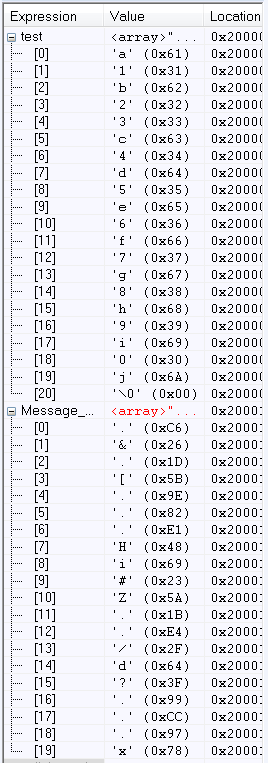

对比上述2图的结果也是一致的。接下来我们分别测试长度448位、长度超过448位、长度超过512位的明文信息,所得的结果也是正确的,说明我们的实现没有问题。
前面我说了SHA-1与MD5是同源的散列算法,那他们究竟有何区别于联系呢?接下来我们简单的比较一下这两种算法:
(1)、因为二者均由MD4导出,SHA-1和MD5彼此很相似。相应的,他们的强度和其他特性也是相似,但还有以下几点不同:
(2)、对强行供给的安全性:最显著和最重要的区别是SHA-1摘要比MD5摘要长32 位。使用强行技术,产生任何一个报文使其摘要等于给定报摘要的难度对MD5是2^128数量级的操作,而对SHA-1则是2^160数量级的操作。这样,SHA-1对强行攻击有更大的强度。
(3)、对密码分析的安全性:由于MD5的设计,易受密码分析的攻击,SHA-1显得不易受这样的攻击。
(4)、速度:在相同的硬件上,SHA-1的运行速度比MD5慢。
欢迎关注:

信息摘要算法之二:SHA1算法分析及实现的更多相关文章
- 信息摘要算法之五:HMAC算法分析与实现
MAC(Message Authentication Code,消息认证码算法)是含有密钥散列函数算法,兼容了MD和SHA算法的特性,并在此基础上加上了密钥.因此MAC算法也经常被称作HMAC算法. ...
- 信息摘要算法之三:SHA256算法分析与实现
前面一篇中我们分析了SHA的原理,并且以SHA1为例实现了相关的算法,在这一片中我们将进一步分析SHA2并实现之. 1.SHA简述 前面的篇章中我们已经说明过,SHA实际包括有一系列算法,分别是SHA ...
- 信息摘要算法之四:SHA512算法分析与实现
前面一篇中我们分析了SHA256的原理,并且实现了该算法,在这一篇中我们将进一步分析SHA512并实现之. 1.SHA简述 尽管在前面的篇章中我们介绍过SHA算法,但出于阐述的完整性我依然要简单的说明 ...
- 信息摘要算法之六:HKDF算法分析与实现
HKDF是一种特定的键衍生函数(KDF),即初始键控材料的功能,KDF从其中派生出一个或多个密码强大的密钥.在此我们想要描述的是基于HMAC的HKDF. 1.HKDF概述 密钥派生函数(KDF)是密码 ...
- 信息摘要算法之一:MD5算法解析及实现
MD5即Message-Digest Algorithm 5(信息-摘要算法5),用于确保信息传输完整一致.是计算机广泛使用的杂凑算法之一(又译摘要算法.哈希算法),主流编程语言普遍已有MD5实现. ...
- 信息摘要算法 MessageDigestUtil
package com.xgh.message.digest.test; import java.math.BigInteger; import java.security.MessageDigest ...
- OpenSSL实现了5种信息摘要算法有哪些?
OpenSSL实现了5种信息摘要算法,分别是MD2.MD5.MDC2.SHA(SHA1)和RIPEMD.SHA算法事实上包括了SHA和SHA1两种信息摘要算法.此外,OpenSSL还实现了DSS标准中 ...
- 20145204&20145212信息安全系统实验二
20145204&20145212信息安全系统实验二 链接
- MD5加密算法(信息摘要算法)、Base64算法
1 什么是MD5 信息摘要算法,可以将字符进行加密,每个加密对象在进行加密后都是等长的 应用场景:将用户密码经过MD5加密后再存储到数据库中,这样即使是超级管理员也没有能力知道用户的具体密码是多少:因 ...
随机推荐
- Spring整合redis配置文件详解
<?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http://www.sp ...
- GCC编译器原理(三)------编译原理三:编译过程---预处理
Gcc的编译流程分为了四个步骤: 预处理,生成预编译文件(.文件):gcc –E hello.c –o hello.i 编译,生成汇编代码(.s文件):gcc –S hello.i –o hello. ...
- springboot使用jpa+mongodb时,xxxRepository不能Autowired的问题
springboot启动类: @SpringBootApplication public class MainApp { public static void main(String[] args) ...
- CentOS7.2通过Yum安装MySQL5.7
1 下载源 wget http://dev.mysql.com/get/mysql57-community-release-el7-8.noarch.rpm 2安装源 yum localinstall ...
- python基础学习11天,作业题
1. 文件a.txt内容:每一行内容分别为商品名字,价钱,个数. apple 10 3 tesla 100000 1 mac 3000 2 lenovo 30000 3 chicken 10 3 通过 ...
- Python Django CBV下的通用视图函数
ListView TemplateView DetailView 之前的代码实例基本上都是基于FBV的模式来撰写的,好处么,当然就是简单粗暴..正如: def index(request): retu ...
- F - Auxiliary Set HDU - 5927 (dfs判断lca)
题目链接: F - Auxiliary Set HDU - 5927 学习网址:https://blog.csdn.net/yiqzq/article/details/81952369题目大意一棵节点 ...
- python练习 之 实践出真知 中心扩展法求最大回文子串 (leetcode题目)
1 问题,给定一个字符串,求字符串中包含的最大回文子串,要求O复杂度小于n的平方. 首先需要解决奇数偶数的问题,办法是:插入’#‘,aba变成#a#b#a#,变成奇数个,aa变成#a#a#,变成奇数个 ...
- pythonの信号量
#!/usr/bin/env python import threading,time def run(n): # 申请锁 semaphore.acquire() time.sleep(1) prin ...
- 第四节:tensorflow图的基本操作
基本使用 使用图(graph)来表示计算任务 激活会话(Session)执行图 使用张量(tensor)表示数据 定义变量(Variable) 使用feed可以任意赋值或者从中获取数据,通常与占位符一 ...