PG数据库基本命令——查询(笔记)
1、插入数据(insert 语句)
语法:
INSERT INTO TABLE_NAME (column1, column2, column3,...columnN)
VALUES (value1, value2, value3,...valueN);
实例:
INSERT INTO employees( ID, NAME, AGE, ADDRESS, SALARY)
VALUES
(1, 'Maxsu', 25, '海口市人民大道2880号', 109990.00 ),
(2, 'minsu', 25, '广州中山大道 ', 125000.00 ),
(3, '李洋', 21, '北京市朝阳区', 185000.00),
(4, 'Manisha', 24, 'Mumbai', 65000.00),
(5, 'Larry', 21, 'Paris', 85000.00);
2、查询数据(SELECT语句)
语法:
SELECT "column1", "column2"..."columnN" FROM "table_name";
SELECT * FROM "table_name";
3、更新数据(UPDATE语句)
语法:
UPDATE table_name
SET column1 = value1, column2 = value2...., columnN = valueN
WHERE [condition];
4、删除数据(DELETE语句)
语法:
DELETE FROM table_name
WHERE [condition];
实例:
DELETE FROM EMPLOYEES
WHERE ID = 1;
5、ORDER BY子句
语法:
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
实例:
SELECT *
FROM EMPLOYEES
ORDER BY AGE ASC;
6、分组(GROUP BY子句)
语法:
SELECT column-list
FROM table_name
WHERE [conditions ]
GROUP BY column1, column2....columnN
ORDER BY column1, column2....columnN
实例:
SELECT NAME, SUM(SALARY)
FROM EMPLOYEES
GROUP BY NAME;
在上面的例子中,当我们使用GROUP BY NAME时,重复的名字数据记录被合并。 它指定GROUP BY减少冗余。
7、Having子句
语法:
SELECT column1, column2
FROM table1, table2
WHERE [ conditions ]
GROUP BY column1, column2
HAVING [ conditions ]
ORDER BY column1, column2
实例:
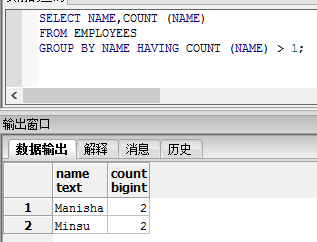
执行以下查询表“EMPLOYEES”中name字段值计数大于1的名称。
SELECT NAME,COUNT (NAME)
FROM EMPLOYEES
GROUP BY NAME HAVING COUNT (NAME) > 1;
8、条件查询
条件查询有:
- AND 条件
- OR 条件
- AND & OR 条件
- NOT 条件
- LIKE 条件
- IN 条件
- NOT IN 条件
- BETWEEN 条件
1)AND条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition]
AND [search_condition];
实例:
SELECT *
FROM EMPLOYEES
WHERE SALARY > 120000
AND ID <= 4;
2) OR条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition]
OR [search_condition];
实例:
SELECT *
FROM EMPLOYEES
WHERE NAME = 'Minsu'
OR ADDRESS = 'Noida';
3)AND & OR条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] AND [search_condition]
OR [search_condition];
实例:
SELECT *
FROM EMPLOYEES
WHERE (NAME = 'Minsu' AND ADDRESS = 'Delhi')
OR (ID>= 8);
4)NOT条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] NOT [condition];
实例:
查询那些地址不为 NULL 的记录信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE address IS NOT NULL ;
查询那些年龄不是21和24的所有记录,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE age NOT IN(21,24) ;
5)LIKE条件
like 与 where 子句一起,用于从指定条件满足 like 条件的表中获取数据。
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] LIKE [condition];
实例:
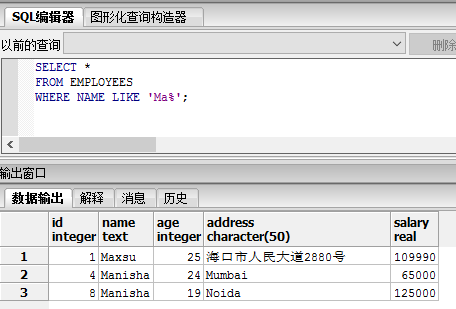
查询名字以 Ma 开头的数据记录,如下查询语句:
SELECT *
FROM EMPLOYEES
WHERE NAME LIKE 'Ma%';
执行结果如下图:
查询名字以su结尾的数据记录,如下查询语句:
SELECT *
FROM EMPLOYEES
WHERE NAME LIKE '%su';
6)IN条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] IN [condition];
实例:
查询employee表中那些年龄为19,21的员工信息,执行以下查询:
SELECT *
FROM EMPLOYEES
WHERE AGE IN (19, 21);
7)NOT IN条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] NOT IN [condition];
8)BETWEEN条件
语法:
SELECT column1, column2, ..... columnN
FROM table_name
WHERE [search_condition] BETWEEN [condition];
实例:
SELECT *
FROM EMPLOYEES
WHERE AGE BETWEEN 24 AND 27;
PG数据库基本命令——查询(笔记)的更多相关文章
- 【MySQL笔记】数据库的查询
数据库的查询 注:文中 [ ...] 代表该部分可以去掉. 理论基础:对表对象的一组关系运算,即选择(selection).投影(projection)和连接(join) 1.select语句 子语句 ...
- JPA连接PG数据库时间类型查询报错的修改
PG数据库中的时间格式规范: https://blog.csdn.net/sky_limitless/article/details/79527665 to_data 转换为 普通的时间格式 to_t ...
- mySQl数据库的学习笔记
mySQl数据库的学习笔记... ------------------ Dos命令--先在记事本中写.然后再粘贴到Dos中去 -------------------------------- mySQ ...
- Mysql数据库基础学习笔记
Mysql数据库基础学习笔记 1.mysql查看当前登录的账户名以及数据库 一.单表查询 1.创建数据库yuzly,创建表fruits 创建表 ) ) ,) NOT NULL,PRIMARY KEY( ...
- 数据库MySQL学习笔记高级篇
数据库MySQL学习笔记高级篇 写在前面 学习链接:数据库 MySQL 视频教程全集 1. mysql的架构介绍 mysql简介 概述 高级Mysql 完整的mysql优化需要很深的功底,大公司甚至有 ...
- 通过redash query results 数据源实现跨数据库的查询
redash 提供了一个简单的 query results 可以帮助我们进行跨数据源的查询处理 底层数据的存储是基于sqlite的,期望后期有调整(毕竟处理能力有限),同时 query results ...
- MySQL数据操作与查询笔记 • 【目录】
持续更新中- 我的大学笔记>>> 章节 内容 第1章 MySQL数据操作与查询笔记 • [第1章 MySQL数据库基础] 第2章 MySQL数据操作与查询笔记 • [第2章 表结构管 ...
- 30多条mysql数据库优化方法,千万级数据库记录查询轻松解决(转载)
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- Neo4j图数据库管理系统开发笔记之一:Neo4j Java 工具包
1 应用开发概述 基于数据传输效率以及接口自定义等特殊性需求,我们暂时放弃使用Neo4j服务器版本,而是在Neo4j嵌入式版本的基础上进行一些封装性的开发.封装的重点,是解决Neo4j嵌入式版本Emb ...
随机推荐
- 统计数字(关联容器map)
题目描述 某次科研调查时得到了n个自然数,每个数均不超过1500000000(1.5*109).已知不相同的数不超过10000个,现在需要统计这些自然数各自出现的次数,并按照自然数从小到大的顺序输出统 ...
- sql base and plsql and database
sql base: http://www.runoob.com/sql/sql-tutorial.html Oracle系统表整理+常用SQL语句收集: https://www.cnblogs.co ...
- QT+VS2013 * 获取网络时间
使用qt函数获取网络时间 现在Qt Project Setting中的Qt Modules勾选NetWork,再导入头文件我也忘了叫什么了 QStringList net_time; QTcpSock ...
- SQL Sever 2012版本数据库的完全安装流程
首先安装SQL Sever 2012数据库,我们要下载好安装包.将安装包存储在磁盘中. 安装前将杀毒软件和相关安全的软件等退出,以免造成安装中的错误. 安装环境:Win7 64位操作系统 注:SQL ...
- Ubuntu 下超简单的安装指定版本的nodejs
第一步 指定版本源 执行 curl -sL https://deb.nodesource.com/setup_6.x | sudo -E bash - setup_5.x 需要安装的版本号,替换数字就 ...
- PythonStudy——PyCharm使用技巧 Column Selection Mode(列选择模式)
PyCharm的Column Selection Mode提供了列选择功能. 使用: 在当前文件右键->Column Selection Mode->用鼠标垂直选择文本 快捷键:Alt + ...
- Networked Graphics: Building Networked Games and Virtual Environments (Anthony Steed / Manuel Fradinho Oliveira 著)
PART I GROUNDWORK CHAPTER 1 Introduction CHAPTER 2 One on One (101) CHAPTER 3 Overview of the Intern ...
- ubuntu 安装kafka
下载 wget http://mirrors.hust.edu.cn/apache/kafka/2.0.0/kafka_2.12-2.0.0.tgz 解压 tar -zxf kafka_2.12-2. ...
- IMPALA部署和架构(一)
IMPALA部署和架构(一) 一,概要 因公司业务需求,需要一个查询引擎满足快速查询TB级别的数据,所以我们找到了presto和impala,presto在前面讲过今天只说impala,impala ...
- KiCad 一款强大的 BOM 和 装配图生成插件
KiCad 一款强大的 BOM 和 装配图生成插件 可以生成 BOM 和在线的图形. https://github.com/openscopeproject/InteractiveHtmlBom In ...