15.scrapy中selenium的应用
引入
- 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值。但是通过观察我们会发现,通过浏览器进行url请求发送则会加载出对应的动态加载出的数据。那么如果我们想要在scrapy也获取动态加载出的数据,则必须使用selenium创建浏览器对象,然后通过该浏览器对象进行请求发送,获取动态加载的数据值。
今日详情
1.案例分析:
- 需求:爬取网易新闻的国内板块下的新闻数据
- 需求分析:当点击国内超链进入国内对应的页面时,会发现当前页面展示的新闻数据是被动态加载出来的,如果直接通过程序对url进行请求,是获取不到动态加载出的新闻数据的。则就需要我们使用selenium实例化一个浏览器对象,在该对象中进行url的请求,获取动态加载的新闻数据。
2.selenium在scrapy中使用的原理分析:
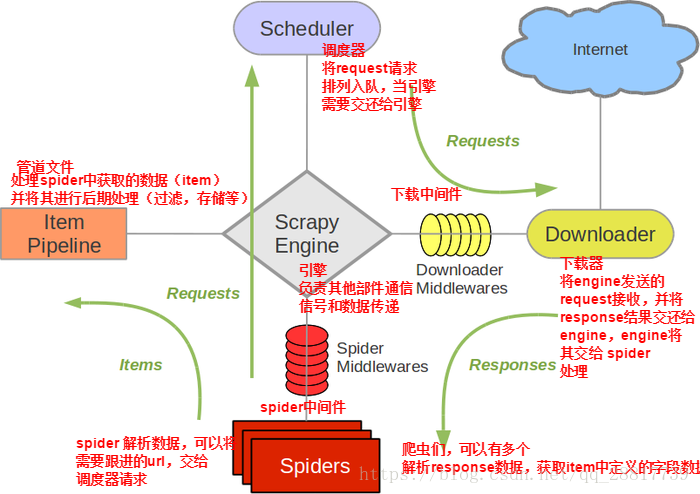
当引擎将国内板块url对应的请求提交给下载器后,下载器进行网页数据的下载,然后将下载到的页面数据,封装到response中,提交给引擎,引擎将response在转交给Spiders。Spiders接受到的response对象中存储的页面数据里是没有动态加载的新闻数据的。要想获取动态加载的新闻数据,则需要在下载中间件中对下载器提交给引擎的response响应对象进行拦截,切对其内部存储的页面数据进行篡改,修改成携带了动态加载出的新闻数据,然后将被篡改的response对象最终交给Spiders进行解析操作。
3.selenium在scrapy中的使用流程:
- 重写爬虫文件的构造方法,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次)
- 重写爬虫文件的closed(self,spider)方法,在其内部关闭浏览器对象。该方法是在爬虫结束时被调用
- 重写下载中间件的process_response方法,让该方法对响应对象进行拦截,并篡改response中存储的页面数据
- 在配置文件中开启下载中间件
4.代码展示:
- 爬虫文件:
class WangyiSpider(RedisSpider):
name = 'wangyi'
#allowed_domains = ['www.xxxx.com']
start_urls = ['https://news.163.com']
def __init__(self):
#实例化一个浏览器对象(实例化一次)
self.bro = webdriver.Chrome(executable_path='/Users/bobo/Desktop/chromedriver')
#必须在整个爬虫结束后,关闭浏览器
def closed(self,spider):
print('爬虫结束')
self.bro.quit()
- 中间件文件:
from scrapy.http import HtmlResponse
#参数介绍:
#拦截到响应对象(下载器传递给Spider的响应对象)
#request:响应对象对应的请求对象
#response:拦截到的响应对象
#spider:爬虫文件中对应的爬虫类的实例
def process_response(self, request, response, spider):
#响应对象中存储页面数据的篡改
if request.url in['http://news.163.com/domestic/','http://news.163.com/world/','http://news.163.com/air/','http://war.163.com/']:
spider.bro.get(url=request.url)
js = 'window.scrollTo(0,document.body.scrollHeight)'
spider.bro.execute_script(js)
time.sleep(2) #一定要给与浏览器一定的缓冲加载数据的时间
#页面数据就是包含了动态加载出来的新闻数据对应的页面数据
page_text = spider.bro.page_source
#篡改响应对象
return HtmlResponse(url=spider.bro.current_url,body=page_text,encoding='utf-8',request=request)
else:
return response
- 配置文件:
DOWNLOADER_MIDDLEWARES = {
'wangyiPro.middlewares.WangyiproDownloaderMiddleware': 543,
}
15.scrapy中selenium的应用的更多相关文章
- 15,scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生如果直接用scrapy对其url发请求,是获取不到那部分动态加载出来的数据值,但是通过观察会发现,通过浏览器 ...
- scrapy中selenium的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- scrapy中 selenium(中间件) + 语言处理 +mysql
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- 14 Scrapy中selenium的应用
在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现,通过 ...
- selenium在scrapy中的使用、UA池、IP池的构建
selenium在scrapy中的使用流程 重写爬虫文件的构造方法__init__,在该方法中使用selenium实例化一个浏览器对象(因为浏览器对象只需要被实例化一次). 重写爬虫文件的closed ...
- Scrapy中集成selenium
面对众多动态网站比如说淘宝等,一般情况下用selenium最好 那么如何集成selenium到scrapy中呢? 因为每一次request的请求都要经过中间件,所以写在中间件中最为合适 from se ...
- 在Scrapy中使用selenium
在scrapy中使用selenium 在scrapy中需要获取动态加载的数据的时候,可以在下载中间件中使用selenium 编码步骤: 在爬虫文件中导入webdrvier类 在爬虫文件的爬虫类的构造方 ...
- selenium在scrapy中的应用
引入 在通过scrapy框架进行某些网站数据爬取的时候,往往会碰到页面动态数据加载的情况发生,如果直接使用scrapy对其url发请求,是绝对获取不到那部分动态加载出来的数据值.但是通过观察我们会发现 ...
- 第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中
第三百五十一节,Python分布式爬虫打造搜索引擎Scrapy精讲—将selenium操作谷歌浏览器集成到scrapy中 1.爬虫文件 dispatcher.connect()信号分发器,第一个参数信 ...
随机推荐
- C# 实现Jwtbearer Authentication
Jwtbearer Authentication 什么是JWT JWT(JSON Web Token), 顾名思义就是在Web上以JSON格式传输的Token(RFC 7519). 该Token被设计 ...
- 微信开发中网页授权access_token与基础支持的access_token异同 【转载、收藏】
问题1:网页授权access_token与分享的jssdk中的access_token一样吗? 答:不一样.网页授权access_token 是一次性的,而基础支持的access_token的是有时间 ...
- Android Studio RecyclerView用法
首先创建一个布局 里面放一个文本 <TextView android:id="@+id/textView" android:layout_width="60dp&q ...
- [android] 隐式意图和显式意图的使用场景
激活系统的某些应用,并且往应用里面填一些数据,比如说短信应用 打开短信应用,查看logcat,找到ActivityManager, 看到Display.com.android.mms/.ui.Comp ...
- SSM+Netty项目结合思路
最近正忙于搬家,面试,整理团队开发计划等工作,所以没有什么时间登陆个人公众号,今天上线看到有粉丝想了解下Netty结合通用SSM框架的案例,由于公众号时间限制,我不能和此粉丝单独沟通,再此写一篇手记分 ...
- 详解Java中对象的软、弱和虚引用的区别
对于大部分的对象而言,程序里会有一个引用变量来引用该对象,这是最常见的引用方法.除此之外,java.lang.ref包下还提供了3个类:SoftReference.WeakReference和Phan ...
- 查看linux 服务器还剩多少空间
df -hl 或者 df -m
- 性能测试 CentOS下结合InfluxDB及Grafana图表实时展示JMeter相关性能数据
CentOS下结合InfluxDB及Grafana图表实时展示JMeter相关性能数据 by:授客 QQ:1033553122 实现功能 1 测试环境 1 环境搭建 2 1.安装influxdb ...
- Android为TV端助力 eclipse出现感叹号的解决办法
当eclipse导入项目出现红叉但无提示错误时,去看:1>菜单路径----Window/Show View/Console2>菜单路径----Window/Show View/Error ...
- Android IPC机制(五)用Socket实现跨进程聊天程序
1.Socket简介 Socket也称作“套接字“,是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用以实现进程在网络中通信.它分为流式套接字和数据包套接 ...