03_Spark集群部署
【安装前的环境准备】
Hadoop:2.6.1
Java:jdk-1.7.0
Spark: spark-1.6.0-bin-hadoop2.6.tgz
Scala: scala-2.11.4.tgz
虚拟机:host01,host02,host03; 其中host01是spark集群的主节点master, 其余两台是slave节点
【每台机器上安装Scala】
原因:每台机器上执行Scala代码,Python代码编写的Spark Application,默认Spark也是使用Scala语言
1)拷贝Scala到所有节点,修改文件权限、属主、解压、简化文件夹名称
# chmod scala-2.11..tgz
# chown root:root scala-2.11..tgz
# tar -xzvf scala-2.11..tgz
# rm -rf scala-2.11..tgz
2) 修改/etc/profile环境变量文件
export SCALA_HOME=/usr/local/src/scala-2.11./
export PATH=$PATH:$SCALA_HOME/bin
3)生效环境变量
# source /etc/profile
4)检查Scala是否安装成功

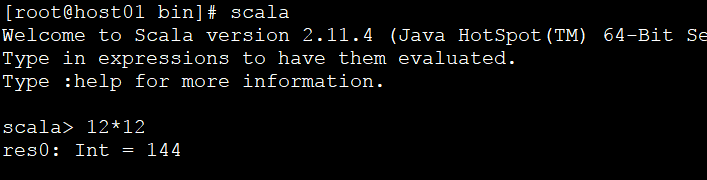
5)在其他节点上同样安装scala
【每台机器上安装Spark】
1、节点一 Host01
1) 拷贝spark安装包到该节点,修改文件权限、属主、解压、简化文件夹名称
# chmod spark-1.6.-bin-hadoop2..tgz
# chown root:root spark-1.6.-bin-hadoop2..tgz
# tar -xzvf spark-1.6.-bin-hadoop2..tgz
# mv spark-1.6.-bin-hadoop2. spark-1.6.
2) 配置/etc/profile环境变量
# SPARK_HOME
export SPARK_HOME=/usr/local/src/spark-1.6./
export PATH=$PATH:$SPARK_HOME/bin
3)环境变量生效
# source /etc/profile
4)配置spark-env.sh
路径:/usr/local/src/spark-1.6.0/conf/
# cp spark-env.sh.template spark-env.sh
# vim spark-env.sh
添加如下配置:
export JAVA_HOME=/usr/local/src/jdk1.7.0/
export SCALA_HOME=/usr/local/src/scala-2.11./
export SPARK_MASTER_IP=host01
export SPARK_DRIVER_MEMORY=1G
export HADOOP_HOME=/usr/local/src/hadoop-2.6./
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop/ # 通过该路径,确定yarn
export SPARK_LOCAL_DIRS=/usr/local/src/spark-1.6./tmp/ # spark进行shuffle,或者RDD持久化时的本地目录
5)配置slaves文件
路径:/usr/local/src/spark-1.6.0/conf/
# cp slaves.template slaves
# vim slaves
修改为如下:
# A Spark Worker will be started on each of the machines listed below.
host02 # 将worker节点,spark集群中的slave角色,写入即可
host03
6)将节点1上的spark目录复制到其他两个节点(host02,host03)
# scp -rp spark-1.6. root@host02:/usr/local/src/
# scp -rp spark-1.6. root@host03:/usr/local/src/
2、节点host02
1)修改/etc/profile, 增加spark环境变量
# SPARK_HOME
export SPARK_HOME=/usr/local/src/spark-1.6./
export PATH=$PATH:$SPARK_HOME/bin
2)环境变量生效
# source /etc/profile
3、节点host03
1)修改/etc/profile, 增加spark环境变量
# SPARK_HOME
export SPARK_HOME=/usr/local/src/spark-1.6./
export PATH=$PATH:$SPARK_HOME/bin
2)环境变量生效
# source /etc/profile
4、启动spark集群,并查看各个节点的Spark进程
【先启动haoop集群】
1) Spark主节点,启动整个集群
路径:/usr/local/src/spark-1.6.0/sbin
# ./start-all.sh
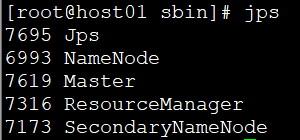
2)Spark主节点进程 Master
# jps
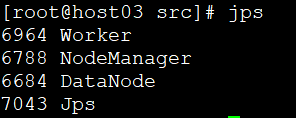
3)Spark从节点进程 Worker
# jps

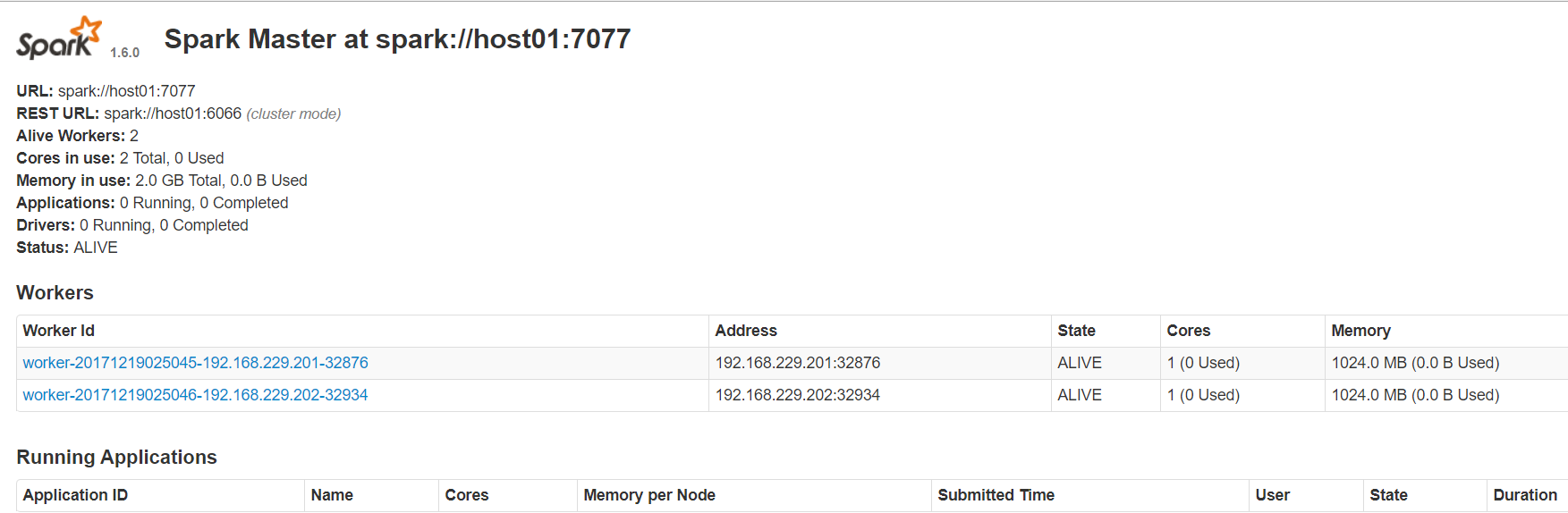
4)Spark UI (http://主节点:8080)
Spark UI: 8080, 运行在Master
Standalone模式下的运行的Spark Application,会在Spark UI显示
Spark集群验证(不同方式提交Spark Application,查看运行情况)
1、本地模式提交自带的示例Spark Application
# ./bin/run-example SparkPi --master local[] //2个线程,本地模式运行,run-example会调用spark-submit进行提交
结果:结果和日志会直接打印到终端

也可以通过Driver上的Application运行期间,提供的WEB UI http://<driver-node>:4040 查看
2、Standalone集群模式提交
# ./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://host01:7077 \
lib/spark-examples-1.6.-hadoop2.6.0.jar \
监控:1)提交作业的终端会打印信息
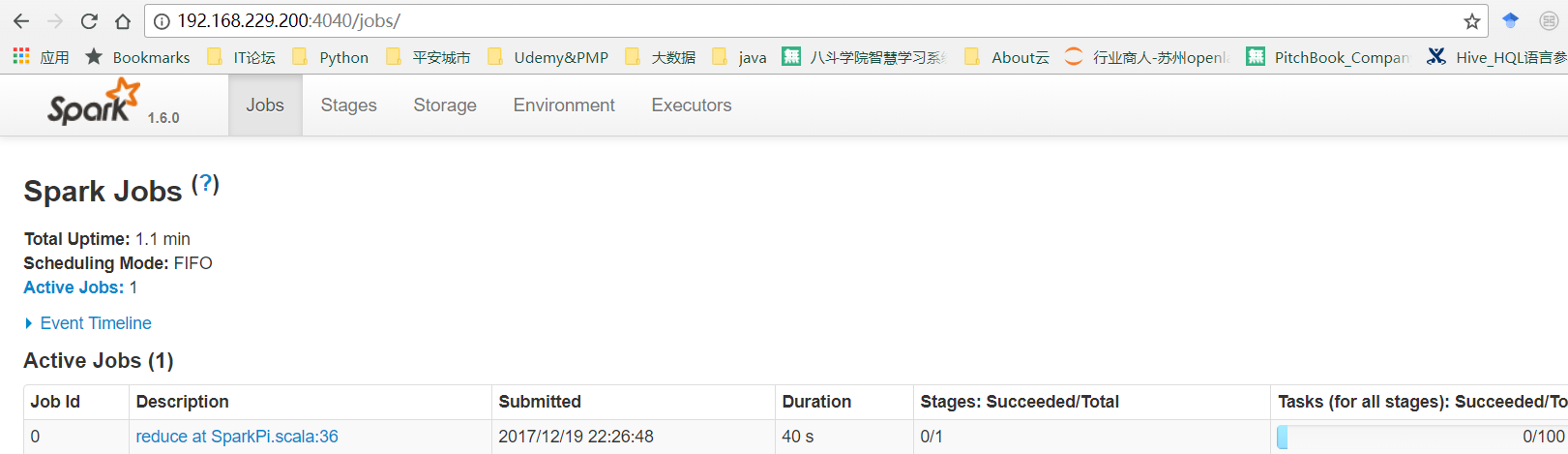
2)Spark UI会出现该Application, Application Detail则会跳转到Driver Programme Web UI(4040)

Spark UI(8080)查看Spark Application

Driver Programme Web UI(4040)
03_Spark集群部署的更多相关文章
- Quartz.net持久化与集群部署开发详解
序言 我前边有几篇文章有介绍过quartz的基本使用语法与类库.但是他的执行计划都是被写在本地的xml文件中.无法做集群部署,我让它看起来脆弱不堪,那是我的罪过. 但是quart.net是经过许多大项 ...
- Openfire 集群部署和负载均衡方案
Openfire 集群部署和负载均衡方案 一. 概述 Openfire是在即时通讯中广泛使用的XMPP协议通讯服务器,本方案采用Openfire的Hazelcast插件进行集群部署,采用Hapro ...
- 基于Tomcat的Solr3.5集群部署
基于Tomcat的Solr3.5集群部署 一.准备工作 1.1 保证SOLR库文件版本相同 保证SOLR的lib文件版本,slf4j-log4j12-1.6.1.jar slf4j-jdk14-1.6 ...
- jstorm集群部署
jstorm集群部署下载 Install JStorm Take jstorm-0.9.6.zip as an example unzip jstorm-0.9.6.1.zip vi ~/.bashr ...
- CAS 集群部署session共享配置
背景 前段时间,项目计划搞独立的登录鉴权中心,由于单独开发一套稳定的登录.鉴权代码,工作量大,最终的方案是对开源鉴权中心CAS(Central Authentication Service)作适配修改 ...
- Windows下ELK环境搭建(单机多节点集群部署)
1.背景 日志主要包括系统日志.应用程序日志和安全日志.系统运维和开发人员可以通过日志了解服务器软硬件信息.检查配置过程中的错误及错误发生的原因.经常分析日志可以了解服务器的负荷,性能安全性,从而及时 ...
- 理解 OpenStack + Ceph (1):Ceph + OpenStack 集群部署和配置
本系列文章会深入研究 Ceph 以及 Ceph 和 OpenStack 的集成: (1)安装和部署 (2)Ceph RBD 接口和工具 (3)Ceph 物理和逻辑结构 (4)Ceph 的基础数据结构 ...
- HBase集成Zookeeper集群部署
大数据集群为了保证故障转移,一般通过zookeeper来整体协调管理,当节点数大于等于6个时推荐使用,接下来描述一下Hbase集群部署在zookeeper上的过程: 安装Hbase之前首先系统应该做通 ...
- SolrCloud-5.2.1 集群部署及测试
一. 说明 Solr5内置了Jetty服务,所以不用安装部署到Tomcat了,网上部署Tomcat的资料太泛滥了. 部署前的准备工作: 1. 将各主机IP配置为静态IP(保证各主机可以正常通信,为避免 ...
随机推荐
- 高性能MySQL中的三星索引
高性能MySQL中的三星索引 我对此提出了深深的疑问: 一星:相关的记录指的是什么??(相关这个词很深奥,“相关部门”是什么部门) 二星:如果建立了B-Tree(B+Tree)索引,数据就有序了.三星 ...
- 十天精通CSS3(7)
:enabled选择器 在Web的表单中,有些表单元素有可用(“:enabled”)和不可用(“:disabled”)状态,比如输入框,密码框,复选框等.在默认情况之下,这些表单元素都处在可用状态.那 ...
- 十天精通CSS3(3)
颜色之RGBA RGB是一种色彩标准,是由红(R).绿(G).蓝(B)的变化以及相互叠加来得到各式各样的颜色.RGBA是在RGB的基础上增加了控制alpha透明度的参数. 语法: color:rgba ...
- python2与python3之间的主要区别
python2与python3之间的主要区别 print py2:print语句,语句就意味着可以直接跟要打印的东西,如果后面接的是一个元组对象,直接打印 py3:print函数,函数就以为这必须要加 ...
- Python随机数生成方法
假设你对在Python生成随机数与random模块中最经常使用的几个函数的关系与不懂之处.以下的文章就是对Python生成随机数与random模块中最经常使用的几个函数的关系,希望你会有所收获,以下就 ...
- openstack 部署笔记--neutron计算节点
控制节点 # vim /etc/neutron/neutron.conf [DEFAULT] # ... transport_url = rabbit://openstack:root@control ...
- oracle怎么恢复被覆盖的存储过程
在oracle数据库中,如果覆盖了之前的存储过程,那得赶紧闪回,时长越长闪回的可能性越小. 原理很简单,存储过程的定义就是数据字典,修改数据字典跟修改普通表的数据没有区别,此时会把修改前的内容放到un ...
- 【笔记】DataTable或IList使用GroupBy方法的lamda表达式
DataTable GroupBy的用法 var result = dt.AsEnumerable(). GroupBy(g => new { StaffID = g.Field<stri ...
- 【VS Hacks】定制VS
# Hack 24 定制快捷键 VS能够做很多键盘的配置,其实在VS中目前已经发现有很多的快捷键了,但是在这个技巧篇里会学到如何创建新的快捷键,以及编辑已有的快捷键.VS中包含很多的命令,只有其中 ...
- 能让程序做的事情坚决不用人来做——批量修复markdownlint MD034警告
欢迎和大家交流技术相关问题: 邮箱: jiangxinnju@163.com 博客园地址: http://www.cnblogs.com/jiangxinnju GitHub地址: https://g ...