数据库入门4 结构化查询语言SQL
知识内容:
1.了解SQL
2.库、表操作及索引
3.select语句及insert语句
4.update语句与delete语句
5.SQL常用函数
6.多表连接及组合查询
7.视图操作及数据控制
参考资料:SQL必知必会及www.w3school.com.cn/sql
关于SQL常用条件操作符:http://www.cnblogs.com/wyb666/p/9051677.html
一、了解SQL
1.数据库基础
数据库:保存有组织的数据的容器
表:某种特定类型数据的结构化清单
模式:关于数据库和表的布局及特性的信息
列:表中的一个字段,所有表都是由一个或多个列组成的
数据类型:所允许的数据的类型,每个表的列都有相应的数据类型,它限制(或允许)该列中存储什么样的数据
行:表中的一个记录
主键:一列(或一组列),其值可以唯一标识表中每一行
关于主键:
- 任意两行都不具有相同的主键值
- 每一行都必须具有一个主键值(主键值不允许为空)
- 主键列中的值不允许修改或更新
- 主键值不能重用(如果某行从表中删除,它的主键不能赋给以后的新行)
2.什么是SQL
SQL:结构化查询语言(Structured Query Language)简称SQL是一种的编程语言,是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。说简单点SQL就是专门用来和数据库沟通的语言
注:
- SQL中不区分大小写,但是一般提倡使用大写
- SQL中注释使用--
3.SQL四大功能
- 查询:select
- 操纵:insert delete update
- 定义:create drop alter
- 控制:grant revoke
4.本篇博客中的SQL命令相关环境
使用的数据库:SqlServer2012
使用到的库为学生信息管理,库在这里:https://pan.baidu.com/s/1rdEWSbix5ZwEDHZHYy9QZw
学生信息管理数据库中的表如下图所示:
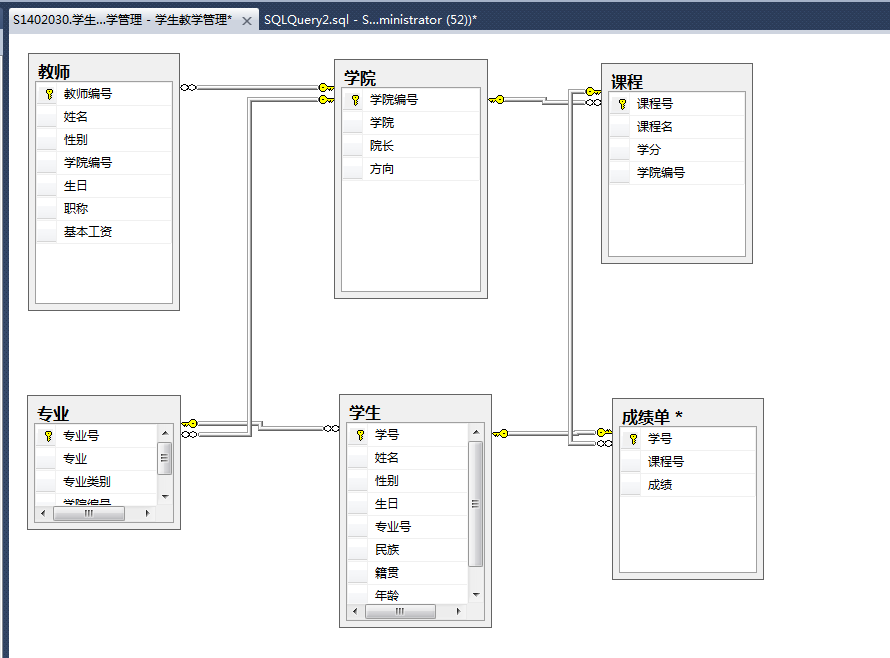


二、库、表相关操作及索引
1.create语句
- CREATE DATABASE database_name -- 创建数据库
- CREATE TABLE 表名称 -- 创建表
- (
- 列名称1 数据类型,
- 列名称2 数据类型,
- 列名称3 数据类型,
- ....
- ) [in 数据库名]
实例:
- 创建学生表。
- CREATE TABLE 学生(
- 学号 CHAR(18)not null,
- 姓名 CHAR(8),
- 年龄 SMALLINT,
- 性别 CHAR(2),
- 籍贯 CHAR(20),
- 专业号 CHAR(10)
- );
2.alter语句
ALTER TABLE 语句用于在已有的表中添加、删除或修改列
- 在表中添加列:
- ALTER TABLE table_name
- ADD column_name datatype
- 删除表中列:
- ALTER TABLE table_name
- DROP COLUMN column_name
- 改变表中列的数据类型:
- ALTER TABLE table_name
- ALTER COLUMN column_name datatype
实例:
- ALTER TABLE 学生 ADD 电话 CHAR(20) NULL
- ALTER TABLE 学生 ALTER 学号 CHAR (5) primary key
- ALTER TABLE 学生;
- ALTER 年龄 SET CHECK 年龄 >=0;
- ALTER TABLE 学生 DROP column 电话
3.drop语句
通过使用 DROP 语句,可以轻松地删除表和数据库
- DROP TABLE 语句用于删除表(表的结构、属性以及索引也会被删除):
- DROP TABLE 表名称
- DROP DATABASE 语句用于删除数据库:
- DROP DATABASE 数据库名称
- 仅除去表内的数据,但不删除表本身就使用 TRUNCATE TABLE 命令(仅仅删除表格中的数据):
- TRUNCATE TABLE 表名称
实例:
- 删除学生表:
- DROP TABLE 学生
4.索引相关语句
(1)建立索引
索引被创建于已有的表中,它可使对行的定位更快速更有效。可以在表格的一个或者多个列上创建索引,每个索引都会被起个名字。用户无法看到索引,它们只能被用来加速查询
- CREATE [UNIQUE] INDEX 索引名 ON 基表名
- (列名1[ASC/DESC][,列2[ASC/DESC]]…)
- [PCTFREE={10/整数}];
建立索引
- 唯一的索引 (Unique Index):
- 在表格上面创建某个一个唯一的索引。唯一的索引意味着两个行不能拥有相同的索引值。
- CREATE UNIQUE INDEX 索引名称
- ON 表名称 (列名称)
- 注:"列名称" 规定你需要索引的列。
- 简单的索引:
- 在表上创建一个简单的索引。当我们省略关键词 UNIQUE 时,就可以使用重复的值。
- CREATE INDEX 索引名称
- ON 表名称 (列名称)
- 注: "列名称" 规定你需要索引的列。
(2)删除索引
- 可以使用 DROP INDEX 命令删除表格中的索引
- 用于 MS SQL Server 的语法:
- DROP INDEX table_name.index_name 或 DROP INDEX 索引名 ON 基表名;
- 用于 IBM DB2 和 Oracle 语法:
- DROP INDEX index_name
- 用于 MySQL 的语法:
- ALTER TABLE table_name DROP INDEX index_name
(3)索引实例
- 在学生表中按学号降序建立索引:
- CREATE UNIQUE INDEX 学号 ON 学生(学号 DESC);
- 在学生表中删除索引:
- DROP INDEX 学号 ON 学生
三、select语句及insert语句
1.select语句
select语句:
- SELECT [all|distinct|top] 列名1,列名2...
- FROM 表名/视图名
- [WHERE 条件表达式]
- [
- GROUP BY 分组列
- [HAVING 分组筛选条件表达式]
- ]
- [ORDER BY 列名1 [ASC|DESC], 列名2 [ASC|DESC]... ]
- 以上[]中的内容为可选,语法中的第一行用于指定查询结果需要返回的列: 可以逐个列出所有列名
- 也可以用*表示返回所有列
- group by用于对数据进行分组以便于汇总计算; having是group by的可选项,用于对汇总结果进行筛选。汇总计算是指统统计记录的个数、计算某列的平均值等
- ORDER BY用于指定返回结果的记录按某个或某几列的大小排序,ASC->从小到大排序(默认) DESC->从大到小排序
(1)检索语句
- select * from 学生 -- 检索学生表中所有列
- select 籍贯 from 学生 -- 检索单个列
- select 学号,专业号, 籍贯 from 学生 -- 检索多个列
- select distinct 专业号 from 学生; -- 检索不同的值
- select top 5 专业号 from 学生; -- 检索学生表中前五行
(2)排序检索数据
- select 年龄 from 学生 order by 年龄; -- 排序数据(默认升序排列)
- select 学号, 年龄, 专业号 from 学生 order by 学号, 年龄; -- 按多个列排序(首先按学号排序然后按年龄排序)
- select 学号, 年龄, 专业号 from 学生 order by 年龄 desc; -- 指定降序排序数据
(3)条件查询-过滤数据
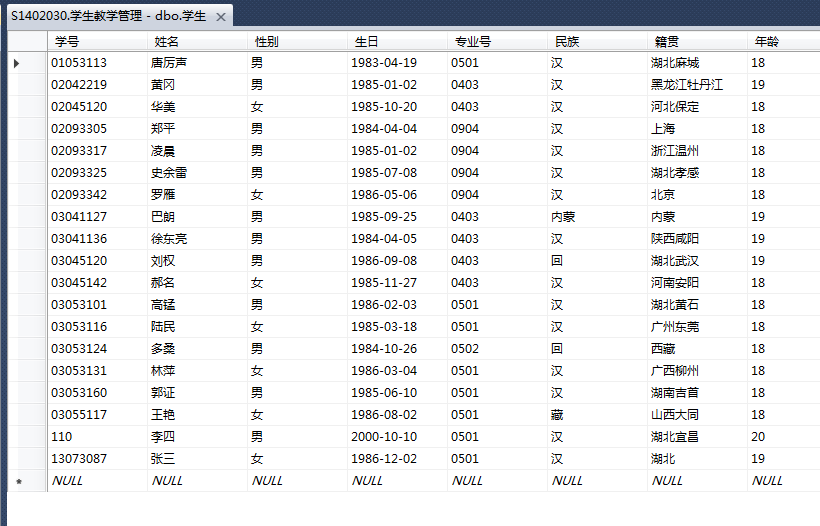
- select 学号, 年龄, 专业号 from 学生 where 年龄 >= 18;
- select 学号, 年龄, 专业号 from 学生 where 年龄 != 18;
- select 学号, 年龄, 专业号 from 学生 where 年龄 between 18 and 19;
- select 学号, 年龄, 专业号, 民族 from 学生 where 年龄 != 18 and 民族 != '汉';
- select 学号, 年龄, 专业号, 民族, 性别 from 学生 where 年龄 > 18 and 性别 = '男';
- select 学号, 年龄, 专业号, 民族 from 学生 where 专业号 = 0501 or 民族 != '汉';
- select 学号,年龄, 专业号, 民族 from 学生 where 专业号 in (0501, 0502) order by 专业号;
- select 学号,年龄, 专业号, 民族 from 学生 where 民族 in ('内蒙', '回', '藏') order by 年龄;
- select 学号,年龄, 专业号, 民族 from 学生 where 专业号 not in (0501, 0502) order by 专业号;
(4)条件查询-用通配符进行过滤 -> %匹配任意字符任意次, _匹配单个字符, []指定字符集从中选一个匹配指定位置的一个字符
- select 学号,年龄, 专业号, 民族 from 学生 where 学号 like '0305%' order by 学号; -- like操作符与%操作符
- select 学号,年龄, 专业号, 民族 from 学生 where 专业号 like '04%' order by 学号; -- like操作符与%操作符
- select 学号,年龄, 专业号, 民族 from 学生 where 学号 like '030531__' order by 学号; -- like操作符与_操作符
- select 学号,年龄, 专业号, 民族 from 学生 where 学号 like '0304[1, 5]%' order by 学号; -- like操作符与[]操作符
(5)使用子查询
- select 学号,姓名,年龄 from 学生 where 学号 in (select 学号 from 成绩单 where 成绩 >= 90);
- select 学号,姓名,年龄 from 学生 where 学号 in ('', '');
- -- 作为子查询的select语句只能查询单个列,企图检索多个列将返回错误!
- select 学号, 姓名, (select COUNT(*) from 成绩单 where 成绩单.学号=学生.学号) as 科目数 from 学生 order by 学号
2.insert语句
INSERT INTO 表名[(列名1[,列名2] …)]
VALUES (常量1[,常量2] …);
或
INSERT INTO 表名[(列名1[,列名2] …)]
例:
- INSERT INTO 员工
- VALUES ("1204","张三","男","12","业务员",1200)
- INSERT INTO employee (emp_no, fname, lname, officeno)
- VALUES (3022, "John", "Smith", 2101)
四、update语句与delete语句
1.update语句
UPDATE 表名
SET 列名1=表达式1[,列名2=表达式2] …
[WHERE 条件表达式];
例:
- update 员工 set 薪金=薪金*1.5
- where 职务 in("总经理","经理","副经理");
- update 学生 set 年龄=年龄+1
- where 性别="男" and 专业号="0403";
2.delete语句
DELETE FROM 表名
[WHERE 条件表达式];
例:
- DELETE FROM 员工 WHERE 姓名=“张三”;
- DELETE FROM CUSTOMER WHERE COUNTRY = “USA”;
- DELETE FROM 学生 WHERE LEFT(学号,4)=“2004” AND 年龄 BETWEEN 18 AND 22;
- 注意,删除数据可能会触发参照完整性的约束规则!
五、SQL常用函数
----统计函数----
- AVG --求平均值
- COUNT --统计数目
- MAX --求最大值
- MIN --求最小值
- SUM --求和
实例如下:
(1)简单使用
- select 学号,avg(成绩) as 平均成绩 from 成绩单 group by 学号;
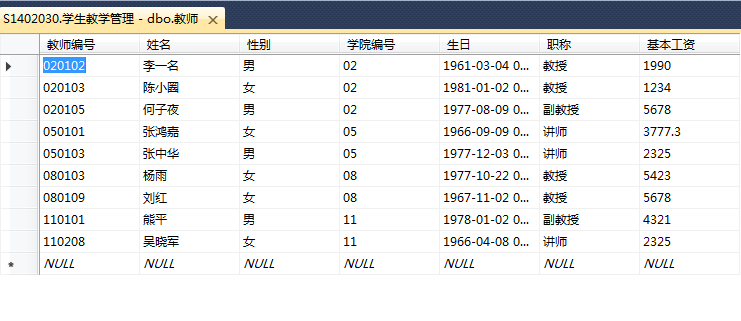
- select count(*) as 人数 from 教师;
- select 学院编号,count(教师编号) as 人数 from 教师 group by 学院编号;
(2)汇总数据
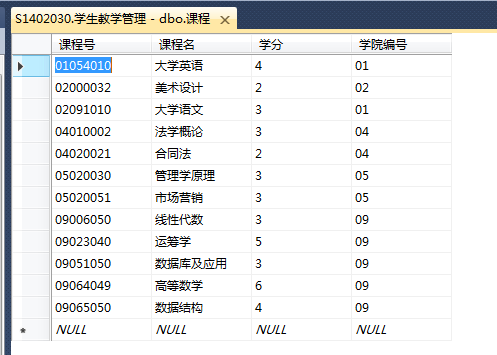
- 1 select avg(成绩) as avg from 成绩单 where 课程号 = 01054010; -- avg函数
- 2 select count(*) as num_cust from 成绩单; -- count函数
- 3 select count(课程号) as num_cust from 成绩单; -- count函数
- 4 select max(成绩) as max_grade from 成绩单; -- max函数
- 5 select min(成绩) as min_grade from 成绩单; -- min函数
- 6 select sum(基本工资) as sum_salary from 教师 where 职称='教授'; --sum函数
- 7 select sum(基本工资) as sum_salary from 教师 where 职称='副教授'; --sum函数
- 8 select sum(基本工资) as sum_salary from 教师 where 职称='讲师'; --sum函数
- 9 select avg(distinct 成绩) as avg from 成绩单 where 课程号 = 01054010; -- distinct
- 10 select avg(成绩) as avg, max(成绩) as max, min(成绩) as min from 成绩单 where 课程号 = 01054010; -- 组合聚集函数
(3)分组数据
- 1 select count(*) as num_prods from 学生 where 学号 like '0305%'; -- 数据分组
- 2 select 年龄, count(*) as num_prods from 学生 group by 年龄; -- 创建分组
- 3 select 年龄, count(*) as num_prods from 学生 group by 年龄 order by 年龄 desc; -- 创建分组并以年龄降序排列
- 4 select 年龄, count(*) as num_prods from 学生 group by 年龄 having count(*) >= 3; -- 过滤分组
- 5 select 年龄, count(*) as num_prods from 学生 where 民族 = '汉' group by 年龄 having count(*)>=3; -- having和where同时使用
group和having:
- GROUP BY〈组合列表〉[,〈组合列表〉…]:分组查询。
- 查询中的行组取决于一个或多个列的值。〈组合列表〉可以是普通数据库字段名,一个包含SQL字段函数的字段成一个指定查询结果中数据库的列位置的数值表达式,但不能是字段表达式。
- HAVING 〈过滤条件〉与GROUP BY一起使用指定查询结果中的组必须满足的条件。
- 可以根据需要设置多个过滤条件,彼此间用AND或OR连接。还可用NOT求反。
注意下面图中的问题:

六、多表连接及组合查询
1.多表连接
SQL中使用inner join进行多表连接
实例:
- 查询学生管理数据库中有成绩的学生的姓名、性别、籍贯、课程编号以及成绩。
- Select 学生.学号,姓名,籍贯,课程号,成绩
- From 成绩单 inner join 学生 On 学生.学号=成绩单.学号
- 查询选择课程”高等数学”的学生姓名、所在专业以及成绩.
- Select 课程名,姓名,专业,成绩
- From ((课程 inner join 成绩单 on 课程.课程号=成绩单.课程号) inner join 学生 on 学生.学号=成绩单.学号) inner join 专业 on 专业.专业号=学生.专业号 where 课程名=‘高等数学’
2.组合查询
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
注意UNION 内部的 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每条 SELECT 语句中的列的顺序必须相同。
- UNION 语法
- SELECT column_name(s) FROM table_name1
- UNION
- SELECT column_name(s) FROM table_name2
- 注:默认UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL
- UNION ALL 语法
- SELECT column_name(s) FROM table_name1
- UNION ALL
- SELECT column_name(s) FROM table_name2
- 另外UNION 结果集中的列名总是等于 UNION 中第一个 SELECT 语句中的列名
七、视图操作及数据控制
1.视图的定义
视图(View)是从一个或几个基表(或视图)导出的表。一个用户可以定义若干个视图,因此,对于某一用户而言,它的外模式是由若干基表和若干视图组成的
2.视图操作
(1)建立视图
- CREATE VIEW 视图名 [(字段名[,字段名…])
- AS 查询语句
- [WITH CHECK OPTION];
(2)删除视图
- DROP VIEW 视图名;
(3)视图实例
- 建立性别为男的写生信息视图。
- CREATE VIEW 男生
- AS SELECT *
- FROM 学生
- WHERE 性别=‘男’
- 视图查询:
- select *
- from 男生
- where 专业号=‘0403’
- 视图的更新:
- update 男生
- set 年龄=年龄+1
- 数据库将其转换为对基表的更新
- update 学生
- set 年龄=年龄+1
- where 性别=‘男’
注:视图是一个虚表,在视图上不能建立索引;视图的更新最终要转换成对基表的更新
3.视图的优点
- 视图对于数据库的重构造提供了一定程度的逻辑独立性
- 简化用户操作
- 使用户以不同的方式看待同一数据
- 对机密数据提供了自动的安全保护功能
4.数据控制功能
SQL语言的数据控制功能是指控制数据库用户对数据的存取权力。实际上数据库中的数据控制包括数据的安全性、完整性、并发控制和数据恢复。
在这里仅讨论数据的安全性控制功能,DBMS须具有以下功能:
- 把授权的决定告知系统,这是由SQL的GRANT和REVOKE语句完成的
- 把授权的结果存入数据字典
- 当用户提出操作请求时,根据授权情况进行检查,以决定是执行操作请求还是拒绝它
GRANT语句:授权
REVOKE语句:回收授权
- 授权语句
- GRANT 权力1[,权力2…][ON 对象类型 对象名]TO 用户1[,用户2…][WITH GRANT OPTION];
- 回收授权语句
- REVOKE 权力1[,权力2…] [ON 对象类型 对象名] FROM 用户1[,用户2…];
视图(View)是从一个或几个基表(或视图)导出的表。一个用户可以定义若干个视图,因此,对于某一用户而言,它的外模式是由若干基表和若干视图组成的
事务控制语句:
- BEGIN TRANSACTION: 启动一个新事务
- ROLLBACK: 回滚事务,结束当前事务
- COMMIT: 提交事务,当前事务正式完成
数据库入门4 结构化查询语言SQL的更多相关文章
- 结构化查询语言-SQL
结构化查询语言(Structured Query Language)简称SQL(发音:/ˈes kjuː ˈel/ "S-Q-L"),是一种特殊目的的编程语言,是一种数据库查询和程 ...
- (三) 结构化查询语言SQL——1
1. SQL概述 SQL,结构化查询语言,重要性不必在赘述了,基本上开发软件没有不用到的,此外在一些大数据也有广泛的应用.SQL主要包含数据定义语言(DDL).数据操纵语言(DML)以及数据控制语言( ...
- 结构化查询语言(SQL)数据类型
简要描述一下结构化查询语言中的五种数据类型:字符型,文本型,数值型,逻辑型和日期型. 字符型 VARCHARVS CHAR VARCHAR型和CHAR型数据的这个差别是细微的,但是非常重要.他们都是用 ...
- Oracle数据库语言——结构化查询语言SQL
一.数据定义语言DDL 1.创建表空间:CREAT TABLESPACE lyy DATAFILE 'C:/app/lyy.dbf' SIZE 10M;(创建一个10M的表空间,存放在C盘app文件夹 ...
- (五) 结构化查询语言SQL——3
4. 数据更新 1)增 对应INSERT语句.格式为INSERT INTO T[(A1,…,Ak)] VALUES (C1,…,Ck),其中A代表表T的属性,C代表常量,A可以缺省,此时C必须严格按 ...
- (四) 结构化查询语言SQL——2
3)ORDER BY排序语句 通常,查询的结果是以无序的方式显示的,有时需要将查询结果按照一定次序来进行排序.ORDER BY就可以用上了,例如查询课程号为202的课程成绩的所有信息,并按照成绩降序排 ...
- SQL 数据库结构化查询语言
1.数据库 常见数据库 MySQL:开源免费的数据库,小型的数据库. Oracle:收费的大型数据库,Oracle 公司的产品 DB2:IBM 公司收费的数据库,常应用在银行系统中 SQLServer ...
- SQL Structured Query Language(结构化查询语言) 数据库
SQL是Structured Query Language(结构化查询语言)的缩写. SQL是专为数据库而建立的操作命令集,是一种功能齐全的数据库语言. 在使用它时,只需要发出“做什么”的命令,“怎么 ...
- SQL 结构化查询语言
SQL 结构化查询语言 一.数据库的必要性: >>作用:存储数据.检索数据.生成新的数据 1)可以有效结构化存储大量的数据信息,方便用户进行有效的检索和访问. 2)可以有效地保持数据信息的 ...
随机推荐
- 最小二乘法 及 梯度下降法 分别对存在多重共线性数据集 进行线性回归 (Python版)
网上对于线性回归的讲解已经很多,这里不再对此概念进行重复,本博客是作者在听吴恩达ML课程时候偶然突发想法,做了两个小实验,第一个实验是采用最小二乘法对数据进行拟合, 第二个实验是采用梯度下降方法对数据 ...
- shell 脚本实战笔记(10)--spark集群脚本片段念念碎
前言: 通过对spark集群脚本的研读, 对一些重要的shell脚本技巧, 做下笔记. *). 取当前脚本的目录 sbin=`dirname "$0"` sbin=`cd &quo ...
- CentOS 7关闭图形桌面开启文本界面
1,命令模式systemctl set-default multi-user.target 2,图形模式systemctl set-default graphical.target CentOS 7 ...
- 20155117王震宇 2016-2017-2 《Java程序设计》第七周学习总结
教材学习内容总结 时间度量 格林尼治标准时间(GMT):现在GMT已不作为标准时间使用. 世界时(UT):借助观测远方星体跨过子午线而得,受地球自转速度影响. 国际原子时(TAI):铯原子辐射振动幅度 ...
- 2018-2019-2 20165212 《网络对抗技术》Exp3 免杀原理与实践
2018-2019-2 20165212 <网络对抗技术>Exp3 免杀原理与实践 一.实验内容 正确使用msf编码器,msfvenom生成如jar之类的其他文件,veil-evasion ...
- 初次实践数据库--SQL Server2016
初学数据库使用 安装了SQL Server2016的开发者版本,本来以为就可以愉快地开始数据库的挖坑了,发现开出来之后除了创建数据库.选择数据库以外,并没有什么操作. 后来才发现还需要再安装SSMS( ...
- streamsets k8s 部署试用
使用k8s 进行 streamsets的部署(没有使用持久化存储) k8s deploy yaml 文件 deploy.yaml apiVersion: extensions/v1beta1 kind ...
- TensorFlow笔记-01-开篇概述
人工智能实践:TensorFlow笔记-01-开篇概述 从今天开始,从零开始学习TensorFlow,有相同兴趣的同志,可以互相学习笔记,本篇是开篇介绍 Tensorflow,已经人工智能领域的一些名 ...
- 使用EntityFramework6完成增删查改CRUD和事务
使用EntityFramework6完成增删查改和事务 上一节我们已经学习了如何使用EF连接MySQL数据库,并简单演示了一下如何使用EF6对数据库进行操作,这一节我来详细讲解一下. 使用EF对数据库 ...
- ORACLE expdp/impdp详解
ORCALE10G提供了新的导入导出工具,数据泵.Oracle官方对此的形容是:Oracle DataPump technology enables Very High-Speed movement ...