《GPU高性能编程CUDA实战》第九章 原子性
▶ 本章介绍了原子操作,给出了基于原子操作的直方图计算的例子。
● 章节代码
#include <stdio.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include "D:\Code\CUDA\book\common\book.h" #define SIZE (100*1024*1024)
#define USE_SHARE_MEMORY true __global__ void histo_kernel(unsigned char *buffer, long size, unsigned int *histo)
{
int i = threadIdx.x + blockIdx.x * blockDim.x; #if USE_SHARE_MEMORY
__shared__ unsigned int temp[];
temp[threadIdx.x] = ;
__syncthreads(); while (i < size)
{
atomicAdd(&temp[buffer[i]], );
i += blockDim.x * gridDim.x;
}
__syncthreads();
atomicAdd(&(histo[threadIdx.x]), temp[threadIdx.x]);
#else
while (i < size)
{
atomicAdd(&histo[buffer[i]], );
i += blockDim.x * gridDim.x;;
}
#endif
return;
} int main(void)
{
int i;
unsigned char *buffer = (unsigned char*)big_random_block(SIZE);// 内置的生成随机字符数组的函数 cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);
cudaEventRecord(start, ); unsigned char *dev_buffer;
unsigned int *dev_histo;
cudaMalloc((void**)&dev_buffer, SIZE);
cudaMemcpy(dev_buffer, buffer, SIZE, cudaMemcpyHostToDevice); cudaMalloc((void**)&dev_histo, * sizeof(int));
cudaMemset(dev_histo, , * sizeof(int)); cudaDeviceProp prop;
cudaGetDeviceProperties(&prop, );
int blocks = prop.multiProcessorCount;// 书:实验表明使用MPS的两倍计算效率最高
histo_kernel << <blocks * , >> >(dev_buffer, SIZE, dev_histo); unsigned int histo[];
cudaMemcpy(histo, dev_histo, * sizeof(int), cudaMemcpyDeviceToHost); cudaEventRecord(stop, );
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
printf("Time to generate: %3.1f ms\n", elapsedTime); long histoCount = ;
for (i = ; i < ; i++)
histoCount += histo[i];
printf("Histogram Sum: %ld\n", histoCount); for (i = ; i < SIZE; i++)// 验证结果
histo[buffer[i]]--;
for (i = ; i < ; i++)
{
if (histo[i] != )
printf("Failure at hist[%d] == %d\n", i,histo[i]);
}
if (i == )
printf("\n\tSucceeded!\n"); cudaFree(dev_histo);
cudaFree(dev_buffer);
free(buffer);
cudaEventDestroy(start);
cudaEventDestroy(stop); getchar();
return ;
}
● 使用全局内存时,只要在每次线程尝试 +1 时使用原子加法即可;使用共享内存时算法分两步,线程先用原子加法往各线程块的共享内存中写入,同步以后,再用原子加法把各共享内存的结果往全局内存中写入。减缓了全局内存的写入冲突。
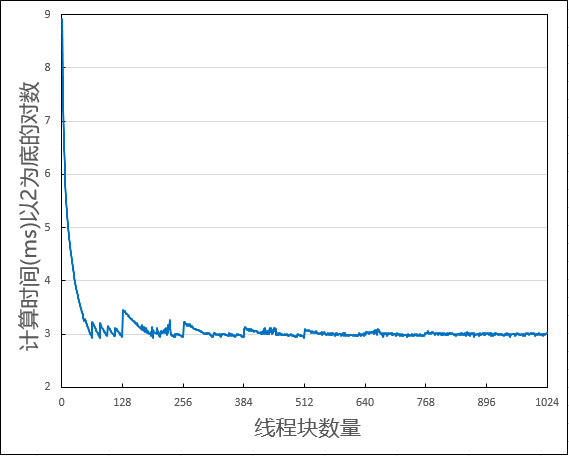
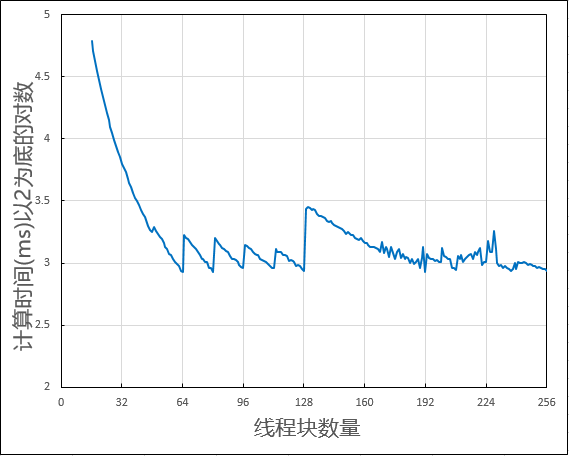
● 代码使用了两倍数量的MPS作为线程块数量,认为这样计算效率最高。在 GTX1070 上 prop.multiProcesser 为 16,程序默认使用 32 个线程块进行计算,我另用 1 到 256 个线程块依次测试,结果如下。
● big_random_block()定义于book.h中
void* big_random_block(int size)
{
unsigned char *data = (unsigned char*)malloc(size);
for (int i = ; i < size; i++)
data[i] = rand();
return data;
}
《GPU高性能编程CUDA实战》第九章 原子性的更多相关文章
- [问题解决]《GPU高性能编程CUDA实战》中第4章Julia实例“显示器驱动已停止响应,并且已恢复”问题的解决方法
以下问题的出现及解决都基于"WIN7+CUDA7.5". 问题描述:当我编译运行<GPU高性能编程CUDA实战>中第4章所给Julia实例代码时,出现了显示器闪动的现象 ...
- 《GPU高性能编程CUDA实战》第十一章 多GPU系统的CUDA C
▶ 本章介绍了多设备胸膛下的 CUDA 编程,以及一些特殊存储类型对计算速度的影响 ● 显存和零拷贝内存的拷贝与计算对比 #include <stdio.h> #include " ...
- 《GPU高性能编程CUDA实战》第五章 线程并行
▶ 本章介绍了线程并行,并给出四个例子.长向量加法.波纹效果.点积和显示位图. ● 长向量加法(线程块并行 + 线程并行) #include <stdio.h> #include &quo ...
- 《GPU高性能编程CUDA实战》第四章 简单的线程块并行
▶ 本章介绍了线程块并行,并给出两个例子:长向量加法和绘制julia集. ● 长向量加法,中规中矩的GPU加法,包含申请内存和显存,赋值,显存传入,计算,显存传出,处理结果,清理内存和显存.用到了 t ...
- 《GPU高性能编程CUDA实战》第七章 纹理内存
▶ 本章介绍了纹理内存的使用,并给出了热传导的两个个例子.分别使用了一维和二维纹理单元. ● 热传导(使用一维纹理) #include <stdio.h> #include "c ...
- 《GPU高性能编程CUDA实战》第六章 常量内存
▶ 本章介绍了常量内存的使用,并给光线追踪的一个例子.介绍了结构cudaEvent_t及其在计时方面的使用. ● 章节代码,大意是有SPHERES个球分布在原点附近,其球心坐标在每个坐标轴方向上分量绝 ...
- 《GPU高性能编程CUDA实战》第三章 CUDA设备相关
▶ 这章介绍了与CUDA设备相关的参数,并给出了了若干用于查询参数的函数. ● 代码(已合并) #include <stdio.h> #include "cuda_runtime ...
- 《GPU高性能编程CUDA实战中文》中第四章的julia实验
在整个过程中出现了各种问题,我先将我调试好的真个项目打包,提供下载. /* * Copyright 1993-2010 NVIDIA Corporation. All rights reserved. ...
- 《GPU高性能编程CUDA实战》附录二 散列表
▶ 使用CPU和GPU分别实现散列表 ● CPU方法 #include <stdio.h> #include <time.h> #include "cuda_runt ...
随机推荐
- hdu1233 还是畅通工程 最小生成树
给出修建边的边权,求连通所有点的最小花费 最小生成树裸题 #include<stdio.h> #include<string.h> #include<algorithm& ...
- 租酥雨的NOIP2018赛前日记
租酥雨的NOIP2018赛前日记 离\(\mbox{NOIP2018}\)只剩下不到一个月的时间辣! 想想自己再过一个月就要退役了,觉得有必要把这段时间的一些计划与安排记录下来. 就从国庆收假开始吧. ...
- CODEFORCES 340 XOR and Favorite Number 莫队模板题
原来我直接学的是假的莫队 原题: Bob has a favorite number k and ai of length n. Now he asks you to answer m queries ...
- 实习第一天:static 声明的 变量和 方法
static 声明的 变量和 方法 既可以用类.变量或者类.方法来调用 order by表格:Store_Information表格 Name Sacles DAteAngeles 1500 19 ...
- GOOGLE高级搜索的秘籍
一.摘要 本文内容来源自互联网,全面的介绍Google搜索的各种功能和技巧. 二.GOOGLE简介 Google(http://www.google.com/)是一个搜索引擎,由两个斯坦福大学博士生L ...
- 用 c 写 CGI 程序简要指南
文章摘要: CGI规定了Web服务器调用其他可执行程序(CGI程 序)的接口协议标准.Web服务器通过调用CGI程序实现和Web浏览器的交互.CGI程序可以用任何程序设计语言编写,如Shell脚本语 ...
- PHP中开启gzip压缩的2种方法
网页开启gzip压缩以后,其体积可以减小20%~90%,可以节省下大量的带宽,从而减少页面响应时间,提高用户体验. php配置改法: 复制代码代码如下: zlib.output_compression ...
- FastAdmin 使用 Git 更新的新用法 (2019-02-28)
FastAdmin 使用 Git 更新的新用法 2019-02-28 新流程 增加一个 fastadmin 的远程仓库. 在项目的开发或主分支. 如果有代码更新将代码提交 commit. git pu ...
- requestAnimationFrame 提高动画性能的原因
与setTimeout相比,requestAnimationFrame最大的优势是由系统来决定回调函数的执行时机.具体一点讲,如果屏幕刷新率是60Hz,那么回调函数就每16.7ms被执行一次,如果刷新 ...
- 关于 BigDecimal 的小数位的入舍去操作
BigDecimal 保留小数 的 入舍操作, 6 中 策略 : RoundingMode 里面的 枚举 和 BigDecimal 的 常量 是等价的 UP(BigDecimal.R ...