第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理
1、映射(mapping)介绍
映射:创建索引的时候,可以预先定义字段的类型以及相关属性
elasticsearch会根据json源数据的基础类型猜测你想要的字段映射,将输入的数据转换成可搜索的索引项,mapping就是我们自己定义的字段数据类型,同时告诉elasticsearch如何索引数据以及是否可以被搜索
作用:会让索引建立的更加细致和完善
类型:静态映射和动态映射
2、内置映射类型(也就是数据类型)
string类型:text,keyword两种
text类型:会进行分词,抽取词干,建立倒排索引
keyword类型:就是一个普通字符串,只能完全匹配才能搜索到
数字类型:long,integer,short,byte,double,float
日期类型:date
bool(布尔)类型:boolean
binary(二进制)类型:binary
复杂类型:object,nested
geo(地区)类型:geo-point,geo-shape
专业类型:ip,competion
3、属性介绍
store属性
index属性
null_value属性
analyzer属性
include_in_all属性
format属性

更多属性:https://www.elastic.co/guide/en/elasticsearch/reference/current/mapping-boost.html
4、创建索引(相当于创建数据库)、创建表、创建字段-设置字段类型,添加数据
说明:
#创建索引(设置字段类型)
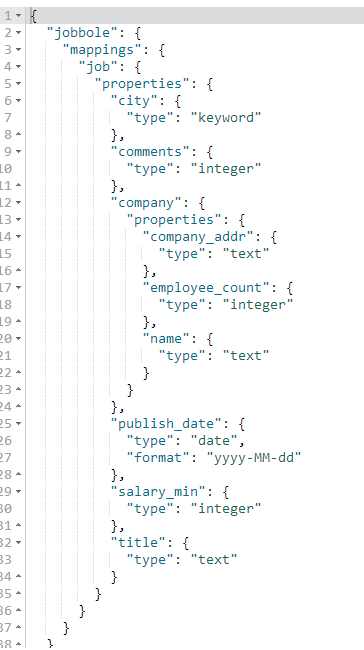
PUT jobbole #创建索引设置索引名称
{
"mappings": { #设置mappings映射字段类型
"job": { #表名称
"properties": { #设置字段类型
"title":{ #title字段
"type": "text" #text类型,text类型可以分词,建立倒排索引
},
"salary_min":{ #salary_min字段
"type": "integer" #integer数字类型
},
"city":{ #city字段
"type": "keyword" #keyword普通字符串类型
},
"company":{ #company字段,是嵌套字段
"properties":{ #设置嵌套字段类型
"name":{ #name字段
"type":"text" #text类型
},
"company_addr":{ #company_addr字段
"type":"text" #text类型
},
"employee_count":{ #employee_count字段
"type":"integer" #integer数字类型
}
}
},
"publish_date":{ #publish_date字段
"type": "date", #date时间类型
"format":"yyyy-MM-dd" #yyyy-MM-dd格式化时间样式
},
"comments":{ #comments字段
"type": "integer" #integer数字类型
}
}
}
}
} #保存文档(相当于数据库的写入数据)
PUT jobbole/job/1 #索引名称/表/id
{
"title":"python分布式爬虫开发", #字段名称:字段值
"salary_min":15000, #字段名称:字段值
"city":"北京", #字段名称:字段值
"company":{ #嵌套字段
"name":"百度", #字段名称:字段值
"company_addr":"北京市软件园", #字段名称:字段值
"employee_count":50 #字段名称:字段值
},
"publish_date":"2017-4-16", #字段名称:字段值
"comments":15 #字段名称:字段值
}
代码:
#创建索引(设置字段类型)
PUT jobbole
{
"mappings": {
"job": {
"properties": {
"title":{
"type": "text"
},
"salary_min":{
"type": "integer"
},
"city":{
"type": "keyword"
},
"company":{
"properties":{
"name":{
"type":"text"
},
"company_addr":{
"type":"text"
},
"employee_count":{
"type":"integer"
}
}
},
"publish_date":{
"type": "date",
"format":"yyyy-MM-dd"
},
"comments":{
"type": "integer"
}
}
}
}
} #保存文档(相当于数据库的写入数据)
PUT jobbole/job/1
{
"title":"python分布式爬虫开发",
"salary_min":15000,
"city":"北京",
"company":{
"name":"百度",
"company_addr":"北京市软件园",
"employee_count":50
},
"publish_date":"2017-4-16",
"comments":15
}
5、获取索引下的mappings映射字段类型
#获取一个索引下的所有表的mappings映射字段类型
GET jobbole/_mapping
#获取一个索引下的指定表的mappings映射字段类型
GET jobbole/_mapping/job
【重点】在创建索引时一旦给字段设置了类型后就不可修改了,如果必须要修改就的重新创建索引,所以在创建索引时就必须确定好字段类型
第三百六十四节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mapping映射管理的更多相关文章
- 第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索的自动补全功能
第三百六十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—用Django实现搜索的自动补全功能 elasticsearch(搜索引擎)提供了自动补全接口 官方说明:https://www.e ...
- 第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作
第三百六十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的mget和bulk批量操作 注意:前面讲到的各种操作都是一次http请求操作一条数据,如果想 ...
- 第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中
第三百五十八节,Python分布式爬虫打造搜索引擎Scrapy精讲—将bloomfilter(布隆过滤器)集成到scrapy-redis中,判断URL是否重复 布隆过滤器(Bloom Filter)详 ...
- 第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启
第三百五十三节,Python分布式爬虫打造搜索引擎Scrapy精讲—scrapy的暂停与重启 scrapy的每一个爬虫,暂停时可以记录暂停状态以及爬取了哪些url,重启时可以从暂停状态开始爬取过的UR ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询
第三百六十六节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的bool组合查询 bool查询说明 filter:[],字段的过滤,不参与打分must:[] ...
- 第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询
第三百六十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本查询 1.elasticsearch(搜索引擎)的查询 elasticsearch是功能 ...
- 第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念
第三百六十节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)的基本概念 elasticsearch的基本概念 1.集群:一个或者多个节点组织在一起 2.节点 ...
- 第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中
第三百六十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)scrapy写入数据到elasticsearch中 前面我们讲到的elasticsearch( ...
随机推荐
- 非常详尽的 Shiro 架构解析
Shiro是什么? Apache Shiro是一个强大而灵活的开源安全框架,它干净利落地处理身份认证,授权,企业会话管理和加密. Apache Shiro的首要目标是易于使用和理解.安全有时候是很复杂 ...
- 每日英语:Are Smartphones Turning Us Into Bad Samaritans?
In late September, on a crowded commuter train in San Francisco, a man shot and killed 20-year-old s ...
- Kali Linux安装Remmina无法加载RDP插件
原因是确少匹配的 libfreerdp库 可以到这里下载 http://ftp.de.debian.org/debian/pool/main/f/freerdp/ 我的电脑是64位的 我下载的是ht ...
- Office_Visio_Pro_2007
Office_Visio_Pro_2007http://pan.baidu.com/share/link?shareid=473782&uk=3474501992 解压后在文件夹里找到密钥[一 ...
- Python 操作redis 常用方法
Python 操作redis 1.字符串 #!/usr/bin/env python # -*- coding:utf-8 -*- import redis # python 操作str class ...
- 利用cmd代码一次性提取电脑登陆过的wifi密码到桌面
for /f "skip=10 tokens=1,2 delims=:" %i in ('netsh wlan show profiles') do @for /f "t ...
- Eval与DataBinder.Eval的区别
DataBinder.Eval的基本格式 DataBinder.Eval(Container.DataItem,"XXX","{0}") <%# Data ...
- # Writing your first Django app, part 2
创建admin用户 D:\desktop\todoList\Django\mDjango\demoSite>python manage.py createsuperuser 然后输入密码 进入a ...
- android App抓包工具的应用(转)
安装好 fiddler ,手头有一部Android 手机,同时 还要有无线网,手机和 电脑在同一个无线网络.这些条件具备,我们就可以 开始下面的步骤了. 正题 :Fiddler 主菜单 Tools - ...
- 使用Task代替ThreadPool和Thread
转载:改善C#程序的建议9:使用Task代替ThreadPool和Thread 一:Task的优势 ThreadPool相比Thread来说具备了很多优势,但是ThreadPool却又存在一些使用上的 ...