sklearn特征抽取
特征抽取sklearn.feature_extraction 模块提供了从原始数据如文本,图像等众抽取能够被机器学习算法直接处理的特征向量。

1.特征抽取方法之 Loading Features from Dicts


measurements=[
{'city':'Dubai','temperature':33.},
{'city':'London','temperature':12.},
{'city':'San Fransisco','temperature':18.},
] from sklearn.feature_extraction import DictVectorizer
vec=DictVectorizer()
print(vec.fit_transform(measurements).toarray())
print(vec.get_feature_names()) #[[ 1. 0. 0. 33.]
#[ 0. 1. 0. 12.]
#[ 0. 0. 1. 18.]] #['city=Dubai', 'city=London', 'city=San Fransisco', 'temperature']
2.特征抽取方法之 Features hashing



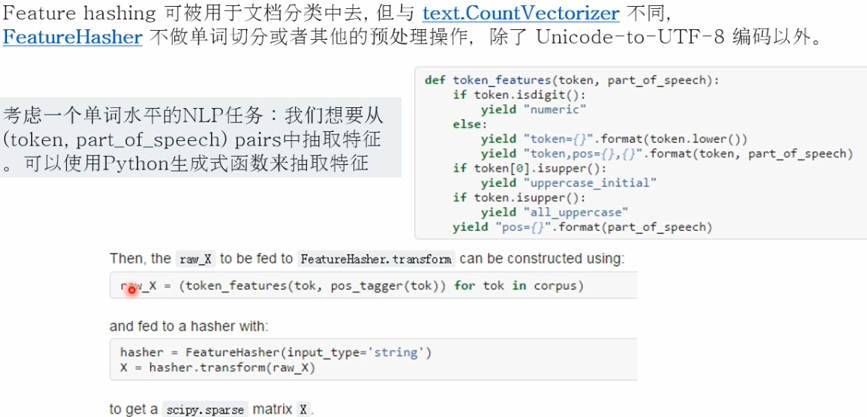
3.特征抽取方法之 Text Feature Extraction
词袋模型 the bag of words represenatation



#词袋模型
from sklearn.feature_extraction.text import CountVectorizer
#查看默认的参数
vectorizer=CountVectorizer(min_df=1)
print(vectorizer) """
CountVectorizer(analyzer='word', binary=False, decode_error='strict',
dtype=<class 'numpy.int64'>, encoding='utf-8', input='content',
lowercase=True, max_df=1.0, max_features=None, min_df=1,
ngram_range=(1, 1), preprocessor=None, stop_words=None,
strip_accents=None, token_pattern='(?u)\\b\\w\\w+\\b',
tokenizer=None, vocabulary=None) """ corpus=["this is the first document.",
"this is the second second document.",
"and the third one.",
"Is this the first document?"]
x=vectorizer.fit_transform(corpus)
print(x) """
(0, 1) 1
(0, 2) 1
(0, 6) 1
(0, 3) 1
(0, 8) 1
(1, 5) 2
(1, 1) 1
(1, 6) 1
(1, 3) 1
(1, 8) 1
(2, 4) 1
(2, 7) 1
(2, 0) 1
(2, 6) 1
(3, 1) 1
(3, 2) 1
(3, 6) 1
(3, 3) 1
(3, 8) 1
"""
默认是可以识别的字符串至少为2个字符
analyze=vectorizer.build_analyzer()
print(analyze("this is a document to anzlyze.")==
(["this","is","document","to","anzlyze"])) #True
在fit阶段被analyser发现的每一个词语都会被分配一个独特的整形索引,该索引对应于特征向量矩阵中的一列
print(vectorizer.get_feature_names()==(
["and","document","first","is","one","second","the","third","this"]
))
#True
print(x.toarray())
"""
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]
"""
获取属性
print(vectorizer.vocabulary_.get('document'))
#
对于一些没有出现过的字或者字符,则会显示为0
vectorizer.transform(["somthing completely new."]).toarray()
"""
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]
"""
在上边的语料库中,第一个和最后一个单词是一模一样的,只是顺序不一样,他们会被编码成相同的特征向量,所以词袋表示法会丢失了单词顺序的前后相关性信息,为了保持某些局部的顺序性,可以抽取2个词和一个词
bigram_vectorizer=CountVectorizer(ngram_range=(1,2),token_pattern=r"\b\w+\b",min_df=1)
analyze=bigram_vectorizer.build_analyzer()
print(analyze("Bi-grams are cool!")==(['Bi','grams','are','cool','Bi grams',
'grams are','are cool'])) #True
x_2=bigram_vectorizer.fit_transform(corpus).toarray()
print(x_2) """
[[0 0 1 1 1 1 1 0 0 0 0 0 1 1 0 0 0 0 1 1 0]
[0 0 1 0 0 1 1 0 0 2 1 1 1 0 1 0 0 0 1 1 0]
[1 1 0 0 0 0 0 0 1 0 0 0 1 0 0 1 1 1 0 0 0]
[0 0 1 1 1 1 0 1 0 0 0 0 1 1 0 0 0 0 1 0 1]]
"""
sklearn特征抽取的更多相关文章
- 《机学一》特征工程1 ——文本处理:sklearn抽取、jieba中文分词、TF和IDF抽取
零.机器学习整个实现过程: 一.机器学习数据组成 特征值: 目标值: 二.特征工程和文本特征提取 1.概要: 1.特征工程是什么 2.特征工程的意义:直接影响预测结果 3.scikit-learn库 ...
- python 机器学习(一)机器学习概述与特征工程
一.机器学习概述 1.1.什么是机器学习? 机器学习是从数据中自动分析获得规律(模型),并利用规律对未知数据进行预测 1.2.为什么需要机器学习? 解放生产力,智能客服,可以不知疲倦的24小时作业 ...
- 特征抽取: sklearn.feature_extraction.FeatureHasher
sklearn.feature_extraction.FeatureHasher(n_features=1048576, input_type="dict", dtype=< ...
- 特征抽取: sklearn.feature_extraction.DictVectorizer
sklearn.featture_extraction.DictVectorizer: 将特征与值的映射字典组成的列表转换成向量. DictVectorizer通过使用scikit-learn的est ...
- 利用sklearn进行tfidf计算
转自:http://blog.csdn.net/liuxuejiang158blog/article/details/31360765?utm_source=tuicool 在文本处理中,TF-IDF ...
- AI学习---特征工程【特征抽取、特征预处理、特征降维】
学习框架 特征工程(Feature Engineering) 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已 什么是特征工程: 帮助我们使得算法性能更好发挥性能而已 sklearn主 ...
- sklearn多分类问题
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- sklearn文本特征提取
http://cloga.info/2014/01/19/sklearn_text_feature_extraction/ 文本特征提取 词袋(Bag of Words)表征 文本分析是机器学习算法的 ...
- sklearn算法库的顶层设计
sklearn监督学习的各个模块 neighbors近邻算法,svm支持向量机,kernal_ridge核岭回归,discriminant_analysis判别分析,linear_model广义线性模 ...
随机推荐
- C++多线程中调用python api函数
错误场景:一直等待全局锁. 解决方法: 一.首先定义一个封装类,主要是保证PyGILState_Ensure, PyGILState_Release配对使用,而且这个类是可以嵌套使用的. #inclu ...
- android中清空一个表---类似truncate table 表名 这样的功能 android sqlite 清空数据库的某个表
public void clearFeedTable(){ String sql = "DELETE FROM " + FEED_TABLE_NAME +";" ...
- Winform控件学习笔记【第六天】——TreeView
TreeView控件用来显示信息的分级视图,如同Windows里的资源管理器的目录.TreeView控件中的各项信息都有一个与之相关的Node对象.TreeView显示Node对象的分层目录结构,每个 ...
- 记一次艰难的IBM X3850重装系统和系统备份经验
[贴心话] 刚刚把一切都搞定了,回到电脑前立马就写下的这篇文章,写的很细节,大家就耐心看看,有些细节是网上没有的,共享一下,仅供参考,以减少大家装机时遇到的困难. [面临处境] 机器型号:IBM X3 ...
- 7款效果惊人的HTML5/CSS3应用
今天是周末,我为大家收集7个比较经典的HTML5/CSS3应用,每一个都提供源代码,效果非常惊人. 1.CSS3/jQuery创意盒子动画菜单 作为前端开发者,各种各样的jQuery菜单见过不少,这款 ...
- ubuntu14.04_64位安装tensorflow-gpu
第一步(可直接跳到第二步):安装nvidia显卡驱动 linux用户可以通过官方ppa解决安装GPU驱动的问题.使用如下命令添加Graphic Drivers PPA: sudo add-apt-re ...
- 删除mac系统win10启动选择项
打开终端输入:diskutil list找到EFI这个分区,挂载EFI分区diskutil mount /dev/disk0s1 回到Finder 删除除apple之外的两个文件夹就可以了(删除win ...
- windows xp\2003 之上的操作系统多启动(多系统)引导
概要技术: 微软自windows vista以来的操作系统引导bootmgr是真的很强大,只是因为其全底层的命令操作,且不友好的命令帮助让人望而却步! 基本技术概要提点: boot.ini 支持:xp ...
- h5文件(.h5和.hdf5)
HDF5 (.h5, .hdf5) HDF 是 Hierarchical Data Format(分层数据格式)的缩写 HDF 版本 5不与 HDF 版本 4 及早期版本兼容. HDF5 (.h5, ...
- Python 程序员都会喜欢的 6 个库
在编程时,小挫折可能与大难题一样令人痛苦.没人希望在费劲心思之后,只是做到弹出消息窗口或是快速写入数据库.因此,程序员都会喜欢那些能够快速处理这些问题,同时长远来看也很健壮的解决方案. 下面这6个Py ...