python - hadoop,mapreduce demo
Hadoop,mapreduce 介绍
59888745@qq.com
大数据工程师是在Linux系统下搭建Hadoop生态系统(cloudera是最大的输出者类似于Linux的红帽),
把用户的交易或行为信息通过HDFS(分布式文件系统)等存储用户数据文件,然后通过Hbase(类似于NoSQL)等存储数据,再通过Mapreduce(并行计算框架)等计算数据,然后通过hiv或pig(数据分析平台)等分析数据,最后按照用户需要重现出数据.
Hadoop是一个由Apache基金会所开发的开源分布式系统基础架构
Hadoop,最基础的也就是HDFS和Mapreduce了,
HDFS是一个分布式存储文件系统
Mapreduce是一个分布式计算的框架,两者结合起来,就可以很容易做一些分布式处理任务了
大纲:
一、MapReduce 基本原理
二、MapReduce 入门示例 - WordCount 单词统计
三、MapReduce 执行过程分析
实例1 - 自定义对象序列化
实例2 - 自定义分区
实例3 - 计算出每组订单中金额最大的记录
实例4 - 合并多个小文件
实例5 - 分组输出到多个文件
四、MapReduce 核心流程梳理
实例6 - join 操作
实例7 - 计算出用户间的共同好友
五、下载方式
一、MapReduce基本原理
MapReduce是一种编程模型,用于大规模数据集的分布式运算。
1、MapReduce通俗解释
图书馆要清点图书数量,有10个书架,管理员为了加快统计速度,找来了10个同学,每个同学负责统计一个书架的图书数量。
张同学统计 书架1
王同学统计 书架2
刘同学统计 书架3
……
过了一会儿,10个同学陆续到管理员这汇报自己的统计数字,管理员把各个数字加起来,就得到了图书总数。
这个过程就可以理解为MapReduce的工作过程。
2、MapReduce中有两个核心操作
(1)map
管理员分配哪个同学统计哪个书架,每个同学都进行相同的“统计”操作,这个过程就是map。
(2)reduce
每个同学的结果进行汇总,这个过程是reduce。
3、MapReduce工作过程拆解
下面通过一个景点案例(单词统计)看MapReduce是如何工作的。
有一个文本文件,被分成了4份,分别放到了4台服务器中存储
Text1:the weather is good
Text2:today is good
Text3:good weather is good
Text4:today has good weather
现在要统计出每个单词的出现次数。

处理过程
(1)拆分单词
map节点1
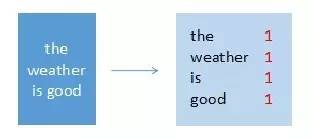
输入:“the weather is good”
输出:(the,1),(weather,1),(is,1),(good,1)
map节点2
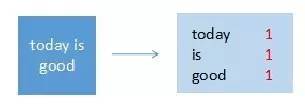
输入:“today is good”
输出:(today,1),(is,1),(good,1)
map节点3
输入:“good weather is good”
输出:(good,1),(weather,1),(is,1),(good,1)

map节点4
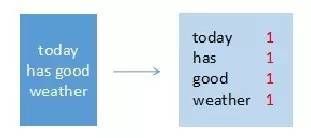
输入:“today has good weather”
输出:(today,1),(has,1),(good,1),(weather,1)
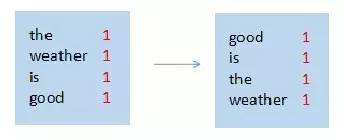
(2)排序
map节点1
map节点2

map节点3

map节点4

(3)合并
map节点1

map节点2

map节点3

map节点4

(4)汇总统计
每个map节点都完成以后,就要进入reduce阶段了。
例如使用了3个reduce节点,需要对上面4个map节点的结果进行重新组合,比如按照26个字母分成3段,分配给3个reduce节点。
Reduce节点进行统计,计算出最终结果。

这就是最基本的MapReduce处理流程。
4、MapReduce编程思路
了解了MapReduce的工作过程,我们思考一下用代码实现时需要做哪些工作?
在4个服务器中启动4个map任务
每个map任务读取目标文件,每读一行就拆分一下单词,并记下来次单词出现了一次
目标文件的每一行都处理完成后,需要把单词进行排序
在3个服务器上启动reduce任务
每个reduce获取一部分map的处理结果
reduce任务进行汇总统计,输出最终的结果数据
但不用担心,MapReduce是一个非常优秀的编程模型,已经把绝大多数的工作做完了,我们只需要关心2个部分:
map处理逻辑——对传进来的一行数据如何处理?输出什么信息?
reduce处理逻辑——对传进来的map处理结果如何处理?输出什么信息?
编写好这两个核心业务逻辑之后,只需要几行简单的代码把map和reduce装配成一个job,然后提交给Hadoop集群就可以了。
至于其它的复杂细节,例如如何启动map任务和reduce任务、如何读取文件、如对map结果排序、如何把map结果数据分配给reduce、reduce如何把最终结果保存到文件等等,MapReduce框架都帮我们做好了,而且还支持很多自定义扩展配置,例如如何读文件、如何组织map或者reduce的输出结果等等,后面的示例中会有介绍。
二、MapReduce入门示例:WordCount单词统计
WordCount是非常好的入门示例,相当于helloword,下面就开发一个WordCount的MapReduce程序,体验实际开发方式。
example:
#删除已有文件夹
hadoop fs -rmr /chenshaojun/input/example_1
hadoop fs -rmr /chenshaojun/output/example_1
#创建输入文件夹
hadoop fs -mkdir /chenshaojun/input/example_1
#放入输入文件
hadoop fs -put text* /chenshaojun/input/example_1
#查看文件是否放好
hadoop fs -ls /chenshaojun/input/example_1
#本地测试一下map和reduce
head -20 text1.txt | python count_mapper.py | sort | python count_reducer.py
#集群上跑任务
hadoop jar /usr/lib/hadoop-current/share/hadoop/tools/lib/hadoop-streaming-2.7.2.jar \
-file count_mapper.py \ #提交文件到集群
-mapper count_mapper.py \
-file count_reducer.py \
-reducer count_reducer.py \
-input /chenshaojun/input/example_1 \
-output /chenshaojun/output/example_1 # 必须不存在,若存在output会抱错,不会覆盖
count_mapper.py
import sys
# input comes from STDIN (standard input)
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# split the line into words
words = line.split()
# increase counters
for word in words:
# write the results to STDOUT (standard output);
# what we output here will be the input for the
# Reduce step, i.e. the input for reducer.py
#
# tab-delimited; the trivial word count is 1
print '%s\t%s' % (word.lower(), 1)
count_reducer.py
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
# input comes from STDIN
for line in sys.stdin:
# remove leading and trailing whitespace
line = line.strip()
# parse the input we got from mapper.py
word, count = line.split('\t', 1)
# convert count (currently a string) to int
try:
count = int(count)
except ValueError:
# count was not a number, so silently
# ignore/discard this line
continue
# this IF-switch only works because Hadoop sorts map output
# by key (here: word) before it is passed to the reducer
if current_word == word:
current_count += count
else:
if current_word:
# write result to STDOUT
print '%s\t%s' % (current_word, current_count)
current_count = count
current_word = word
# do not forget to output the last word if needed!
if current_word == word:
print '%s\t%s' % (current_word, current_count)
python - hadoop,mapreduce demo的更多相关文章
- Hadoop(三)通过C#/python实现Hadoop MapReduce
MapReduce Hadoop中将数据切分成块存在HDFS不同的DataNode中,如果想汇总,按照常规想法就是,移动数据到统计程序:先把数据读取到一个程序中,再进行汇总. 但是HDFS存的数据量非 ...
- Writing an Hadoop MapReduce Program in Python
In this tutorial I will describe how to write a simpleMapReduce program for Hadoop in thePython prog ...
- Hadoop:使用原生python编写MapReduce
功能实现 功能:统计文本文件中所有单词出现的频率功能. 下面是要统计的文本文件 [/root/hadooptest/input.txt] foo foo quux labs foo bar quux ...
- 使用Python实现Hadoop MapReduce程序
转自:使用Python实现Hadoop MapReduce程序 英文原文:Writing an Hadoop MapReduce Program in Python 根据上面两篇文章,下面是我在自己的 ...
- Python实现Hadoop MapReduce程序
1.概述 Hadoop Streaming提供了一个便于进行MapReduce编程的工具包,使用它可以基于一些可执行命令.脚本语言或其他编程语言来实现Mapper和 Reducer,从而充分利用Had ...
- 用Python语言写Hadoop MapReduce程序Writing an Hadoop MapReduce Program in Python
In this tutorial I will describe how to write a simple MapReduce program for Hadoop in the Python pr ...
- hadoop MapReduce Yarn运行机制
原 Hadoop MapReduce 框架的问题 原hadoop的MapReduce框架图 从上图中可以清楚的看出原 MapReduce 程序的流程及设计思路: 首先用户程序 (JobClient) ...
- 从分治算法到 Hadoop MapReduce
从分治算法说起 要说 Hadoop MapReduce 就不得不说分治算法,而分治算法其实说白了,就是四个字 分而治之 .其实就是将一个复杂的问题分解成多组相同或类似的子问题,对这些子问题再分,然后再 ...
- hadoop mapreduce 基础实例一记词
mapreduce实现一个简单的单词计数的功能. 一,准备工作:eclipse 安装hadoop 插件: 下载相关版本的hadoop-eclipse-plugin-2.2.0.jar到eclipse/ ...
随机推荐
- Centos 安装GIT 1.7.1
在Linux上安装Git 1.首先,你可以试着输入git,看看系统有没有安装Git: git 2.安装GIT https://git-scm.com/download/linux yum instal ...
- dart --- 更符合程序员编程习惯的javascript替代者
dart是google在2011年推出的一门语言,提供较为丰富的lib,并支持将代码转变为javascript,其demo code 和 demo app 也是以web前端代码来展示的. 其语言特性较 ...
- freeswitch订阅会议相关通知
一. freeswitch订阅会议相关通知 event plain CUSTOM conference::maintenance 这时会收到各种通知,会议创建.成员加入.成员离开.成员开始讲话,成员停 ...
- [转]python pickle模块
持久性就是指保持对象,甚至在多次执行同一程序之间也保持对象.通过本文,您会对 Python对象的各种持久性机制(从关系数据库到 Python 的 pickle以及其它机制)有一个总体认识.另外,还会让 ...
- U811.1接口EAI系列之二-BOM构成-委外BOM构成--VB语言
1.下面代码实现了VB6.0中调用U8EAI-BOM构成服务,以下代码均为项目实际代码,可直接复制应用. 2.在u811.1版本中委外BOM构成与正常的BOM构成是同系列表,不单独存储. 3.是以存货 ...
- Maven:浅析依赖(dependency)关系中 scope 的含义(转)
在 Pom4 中,dependency 元素中引入了 scope 元素,这是一个很重要的属性.在Maven 项目中 Jar 包冲突.类型转换异常的很大原因是由于 scope 元素使用不当造成的. sc ...
- Vue基本概念介绍及vue-cli环境搭建
1 js中初始化一个Vue对象,传的参数就是对象属性. 挂载点.模板.实例之间的关系. var vm = new Vue({ el:"#app", template:'<di ...
- django -- model中只有Field类型的数据才能成为数据库中的列
一.model的定义: from django.db import models # Create your models here. class Person(models.Model): firs ...
- elk 使用中遇到的问题(kafka 重复消费)
问题描述: 在使用过程中,当遇到大量报错的时候,我们到eagle后台看到报错的那个consumer的消费情况到到lag 远远大于0(正常情况应该为0),activie 节点没有,kibana面板上没 ...
- [svc]NFS存储企业场景及nfs最佳实战探究
办公网络里人一般系统用共享,尤其是财务, 他们喜欢直接点开编辑. 而不喜欢ftp nfs在网站架构中的用途 注: 如果pv量少,则放在一台机器上速度更快,如果几千万pv,则存储分布式部署. 网站架构中 ...