GBDT理论知识总结
一. GBDT的经典paper:《Greedy Function Approximation:A Gradient Boosting Machine》
Abstract
Function approximation是从function space方面进行numerical optimization,其将stagewise additive expansions和steepest-descent minimization结合起来。而由此而来的Gradient Boosting Decision Tree(GBDT)可以适用于regression和classification,都具有完整的,鲁棒性高,解释性好的优点。
1. Function estimation
在机器学习的任务中,我们一般面对的问题是构造loss function,并求解其最小值。可以写成如下形式:

通常的loss function有:
1. regression:均方误差(y-F)2,绝对误差|y-F|
2. classification:negative binomial log-likelihood log(1+e-2yF)
一般情况下,我们会把F(x)看做是一系列带参数的函数集合 F(x;P),于是进一步将其表示为“additive”的形式:

1.1 Numerical optimizatin
我们可以通过选取一个参数模型F(x;P),来将function optimization问题转化为一个parameter optimization问题:

进一步,我们可以把要优化的参数也表示为“additive”的形式:
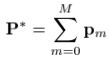
1.2 Steepest-descent
梯度下降是最简单,最常用的numerical optimization method之一。
首先,计算出当前的梯度:

where 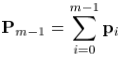
而梯度下降的步长为: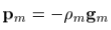
where  ,称为“line search”。
,称为“line search”。
2. Numerical optimization in function space
现在,我们考虑“无参数”模型,转而考虑直接在function space 进行numerical optimization。这时候,我们将在每个数据点x处的函数值F(x)看做是一个“参数”,仍然是来对loss funtion求解最小值。
在function space,为了表示一个函数F(x),理想状况下有无数个点,但在现实中,我们用有限个(N个)离散点来表示它: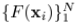 。
。
按照之前的numerical optimization的方式,我们需要求解:
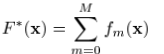
使用steepest-descent,有:

where  ,and
,and 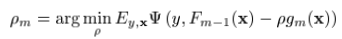
3. Finite data
当我们面对的情况为:用有限的数据集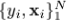 表示x,y的联合分布的时候,上述的方法就有点行不通了。我们可以试试“greedy-stagewise”的方法:
表示x,y的联合分布的时候,上述的方法就有点行不通了。我们可以试试“greedy-stagewise”的方法:
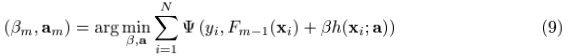
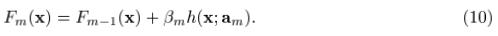
但是对于一般的loss function和base learner来说,(9)式是很难求解的。给定了m次迭代后的当前近似函数Fm-1(x),当步长的direction 是指数函数集合
是指数函数集合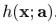 当中的一员时,
当中的一员时,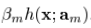 可以看做是在求解最优值上的greedy step,同样,它也可以被看做是相同限制下的steepest-descent step。作为比较,
可以看做是在求解最优值上的greedy step,同样,它也可以被看做是相同限制下的steepest-descent step。作为比较,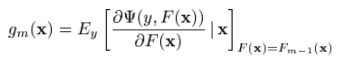 给出了在无限制条件下,在Fm-1(x)处的steepest-descent step direction。一种行之有效的方法就是在求解的时候,把它取为无限制条件下的负梯度方向
给出了在无限制条件下,在Fm-1(x)处的steepest-descent step direction。一种行之有效的方法就是在求解的时候,把它取为无限制条件下的负梯度方向 :
:
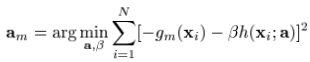
where 
这就把(9)式中较难求解的优化问题转化为了一个基于均方误差的拟合问题。
Gradient Boosting的通用解法如下:

二. 对于GBDT的一些理解
1. Boosting
GBDT的全称是Gradient Boosting Decision Tree,Gradient Boosting和Decision Tree是两个独立的概念。因此我们先说说Boosting。Boosting的概念很好理解,意思是用一些弱分类器的组合来构造一个强分类器。因此,它不是某个具体的算法,它说的是一种理念。和这个理念相对应的是一次性构造一个强分类器。像支持向量机,逻辑回归等都属于后者。通常,我们通过相加来组合分类器,形式如下:
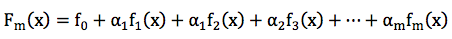
2. Gradient Boosting Modeling(GBM)
给定一个问题,我们如何构造这些弱分类器呢?Gradient Boosting Modeling (GBM) 就是构造 这些弱分类的一种方法。同样,它指的不是某个具体的算法,仍然只是一个理念。在理解 Gradient Boosting Modeling 之前,我们先看看一个典型的优化问题:
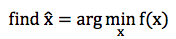
针对这种优化问题,有一个经典的算法叫 Steepest Gradient Descent,也就是最深梯度下降法。 这个算法的过程大致如下:

以上迭代过程可以这么理解:整个寻优的过程就是个小步快跑的过程,每跑一小步,都往函数当前下降最快的那个方向走一点。
这样寻优得到的结果可以表示成加和形式,即:
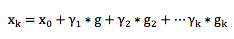
这个形式和以上Fm(x)是不是非常相似? Gradient Boosting 正是由此启发而来。 构造Fm(x)本身也是一个寻优的过程,只不过我们寻找的不是一个最优点,而是一个最优的函数。优化的目标通常都是通过一个损失函数来定义,即:

其中Loss(F(xi), yi)表示损失函数Loss在第i个样本上的损失值,xi和yi分别表示第 i 个样本的特征和目标值。常见的损失函数如平方差函数:
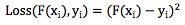
类似最深梯度下降法,我们可以通过梯度下降法来构造弱分类器f1, f2, ... , fm,只不过每次迭代时,令
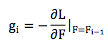
即对损失函数L,以 F 为参考求取梯度。
这里有个小问题,一个函数对函数的求导不好理解,而且通常都无法通过上述公式直接求解 到梯度函数gi。为此,采取一个近似的方法,把函数Fi−1理解成在所有样本上的离散的函数值,即:

不难理解,这是一个 N 维向量,然后计算
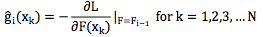
这是一个函数对向量的求导,得到的也是一个梯度向量。注意,这里求导时的变量还是函数F,不是样本xk。
严格来说 ĝi(xk) for k = 1,2, ... , N 只是描述了gi在某些个别点上的值,并不足以表达gi,但我们可以通过函数拟合的方法从ĝi(xk) for k = 1,2, ... , N 构造gi,这样我们就通过近似的方法得到了函数对函数的梯度求导。
因此 GBM 的过程可以总结为如下:

常量函数f0通常取样本目标值的均值,即
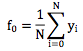
3. Gradient Boosting Decision Tree
以上 Gradient Boosting Modeling 的过程中,还没有说清楚如何通过离散值 ĝi−1(xj) for j = 1,2,3,...N 构造拟合函数gi−1。函数拟合是个比较熟知的概念,有很多现成的方法,不过有一种拟合方法广为应用,那就是决策树 Decision Tree,有关决策树的概念,理解GBDT重点首先是Gradient Boosting,其次才是 Decision Tree。GBDT 是 Gradient Boosting 的一种具体实例,只不过这里的弱分类器是决策树。如果你改用其他弱分类器 XYZ,你也可以称之为 Gradient Boosting XYZ。只不过 Decision Tree 很好用,GBDT 才如此引人注目。
4. 损失函数
谈到 GBDT,常听到一种简单的描述方式:“先构造一个(决策)树,然后不断在已有模型和实际样本输出的残差上再构造一颗树,依次迭代”。其实这个说法不全面,它只是 GBDT 的一种特殊情况,为了看清这个问题,需要对损失函数的选择做一些解释。
从对GBM的描述里可以看到Gradient Boosting过程和具体用什么样的弱分类器是完全独立的,可以任意组合,因此这里不再刻意强调用决策树来构造弱分类器,转而我们来仔细看看弱分类器拟合的目标值,即梯度ĝi−1(xj ),之前我们已经提到过

5. GBDT 和 AdaBoost
Boosting 是一类机器学习算法,在这个家族中还有一种非常著名的算法叫 AdaBoost,是 Adaptive Boosting 的简称,AdaBoost 在人脸检测问题上尤其出名。既然也是 Boosting,可以想象它的构造过程也是通过多个弱分类器来构造一个强分类器。那 AdaBoost 和 GBDT 有什么区别呢?
两者最大的区别在于,AdaBoost 不属于 Gradient Boosting,即它在构造弱分类器时并没有利用到梯度下降法的思想,而是用的Forward Stagewise Additive Modeling (FSAM)。为了理解 FSAM,在回过头来看看之前的优化问题。
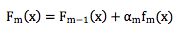
严格来说之前描述的优化问题要求我们同时找出α1, α2, ... , αm和f1, f2, f3 ... , fm,这个问题很 难。为此我们把问题简化为分阶段优化,每个阶段找出一个合适的α 和f 。假设我们已经 得到前 m-1 个弱分类器,即Fm−1(x),下一步在保证Fm−1(x)不变的前提下,寻找合适的 αmfm(x)。按照损失函数的定义,我们可以得到

如果 Loss 是平方差函数,则我们有

这里yi − Fm−1(xi)就是当前模型在数据上的残差,可以看出,求解合适的αmfm(x)就是在这 当前的残差上拟合一个弱分类器,且损失函数还是平方差函数。这和 GBDT 选择平方差损失 函数时构造弱分类器的方法恰好一致。
(1)拟合的是“残差”,对应于GBDT中的梯度方向。
(2)损失函数是平方差函数,对应于GBDT中用Decision Tree来拟合“残差”。
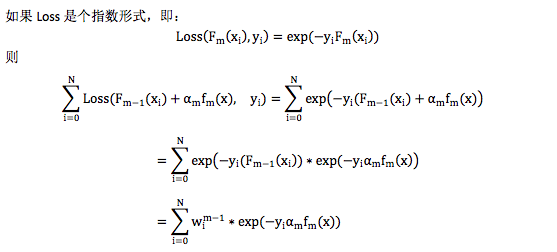
其中 wim−1= exp(−yi(Fm−1(xi))和要求解的αmfm(x)无关,可以当成样本的权重,因此在这种情况下,构造弱分类器就是在对样本设置权重后的数据上拟合,且损失函数还是指数形式。 这个就是 AdaBoost,不过 AdaBoost 最早并不是按这个思路推出来的,相反,是在 AdaBoost 提出 5 年后,人们才开始用 Forward Stagewise Additive Modeling 来解释 AdaBoost 背后的原理。
为什么要把平方差和指数形式 Loss 函数单独拿出来说呢?这是因为对这两个损失函数来说, 按照 Forward Stagewise Additive Modeling 的思路构造弱分类器时比较方便。如果是平方差损 失函数,就在残差上做平方差拟合构造弱分类器; 如果是指数形式的损失函数,就在带权 重的样本上构造弱分类器。但损失函数如果不是这两种,问题就没那么简单,比如绝对差值 函数,虽然构造弱分类器也可以表示成在残差上做绝对差值拟合,但这个子问题本身也不容 易解,因为我们是要构造多个弱分类器的,所以我们当然希望构造弱分类器这个子问题比较 好解。因此 FSAM 思路无法推广到其他一些实用的损失函数上。相比而言,Gradient Boosting Modeling (GBM) 有什么优势呢?GBM 每次迭代时,只需要计算当前的梯度,并在平方差损 失函数的基础上拟合梯度。虽然梯度的计算依赖原始问题的损失函数形式,但这不是问题, 只要损失函数是连续可微的,梯度就可以计算。至于拟合梯度这个子问题,我们总是可以选 择平方差函数作为这个子问题的损失函数,因为这个子问题是一个独立的回归问题。
因此 FSAM 和 GBM 得到的模型虽然从形式上是一样的,都是若干弱模型相加,但是他们求 解弱分类器的思路和方法有很大的差别。只有当选择平方差函数为损失函数时,这两种方法 等同。
6. 为何GBDT受人青睐
以上比较了 GBM 和 FSAM,可以看到 GBM 在损失函数的选择上有更大的灵活性,但这不足以解释GBDT的全部优势。GBDT是拿Decision Tree作为GBM里的弱分类器,GBDT的优势 首先得益于 Decision Tree 本身的一些良好特性,具体可以列举如下:
Decision Tree 可以很好的处理 missing feature,这是他的天然特性,因为决策树的每个节点只依赖一个 feature,如果某个 feature 不存在,这颗树依然可以拿来做决策,只是少一些路径。像逻辑回归,SVM 就没这个好处。
Decision Tree 可以很好的处理各种类型的 feature,也是天然特性,很好理解,同样逻辑回归和 SVM 没这样的天然特性。
对特征空间的 outlier 有鲁棒性,因为每个节点都是 x <
GBDT理论知识总结的更多相关文章
- [笔记]GBDT理论知识总结
一. GBDT的经典paper:<Greedy Function Approximation:A Gradient Boosting Machine> Abstract Function ...
- js中函数的一些理论知识
函数的一些理论知识 1. 函数: 执行一个明确的动作并提供一个返回值的独立代码块.同时函数也是javascript中的一级公民(就是函数和其它变量一样). 2.函数的 ...
- 用VC进行COM编程所必须掌握的理论知识
一.为什么要用COM 软件工程发展到今天,从一开始的结构化编程,到面向对象编程,再到现在的COM编程,目标只有一个,就是希望软件能象积方块一样是累起来的,是组装起来的,而不是一点点编出来的.结构化编程 ...
- 图形学理论知识 BRDF 双向反射分布函数(Bidirectional Reflectance Distribution Function)
图形学理论知识 BRDF 双向反射分布函数 Bidirectional Reflectance Distribution Function BRDF理论 BRDF表示的是双向反射分布函数(Bidire ...
- TestNG学习-001-基础理论知识
此 文主要讲述用 TestNG 的基础理论知识,TestNG 的特定,编写测试过程三步骤,与 JUnit4+ 的差异,以此使亲对 TestNG 测试框架能够有一个简单的认知. 希望能对初学 TestN ...
- [转] DDD领域驱动设计(三) 之 理论知识收集汇总
最近一直在学习领域驱动设计(DDD)的理论知识,从网上搜集了一些个人认为比较有价值的东西,贴出来和大家分享一下: 我一直觉得不要盲目相信权威,比如不能一谈起领域驱动设计,就一定认为国外的那个Eric ...
- Winsock网络编程笔记(4)----基本的理论知识
前面的笔记记录了Winsock的入门编程,领略了Winsock编程的乐趣..但这并不能算是掌握了Winsock,加深理论知识的理解才会让后续学习更加得心应手..因此,这篇笔记将记录一些有关Winsoc ...
- Android初级教程对大量数据的做分页处理理论知识
有时候要加载的数据上千条时,页面加载数据就会很慢(数据加载也属于耗时操作).因此就要考虑分页甚至分批显示.先介绍一些分页的理论知识.对于具体用在哪里,会在后续博客中更新. 分页信息 1,一共多少条数据 ...
- Android初级教程理论知识(第四章内容提供器)
之前第三章理论知识写到过数据库.数据库是在程序内部自己访问自己.而内容提供器是访问别的程序数据的,即跨程序共享数据.对访问的数据也无非就是CRUD. 内容提供者 应用的数据库是不允许其他应用访问的 内 ...
随机推荐
- 前端开发利器 Emmet 介绍与基础语法教程
在前端开发的过程中,编写 HTML.CSS 代码始终占据了很大的工作比例.特别是手动编写 HTML 代码,效率特别低下,因为需要敲打各种“尖括号”.闭合标签等.而现在 Emmet 就是为了提高代码编写 ...
- 【LOJ6254】最优卡组 堆(模拟搜索)
[LOJ6254]最优卡组 题面 题解:常用的用堆模拟搜索套路(当然也可以二分).先将每个卡包里的卡从大到小排序,然后将所有卡包按(最大值-次大值)从小到大排序,并提前处理掉只有一张卡的卡包. 我们将 ...
- iOS - 网址、链接、网页地址、下载链接等正则表达式匹配(解决url包含中文不能编码的问题)
DNS规定,域名中的标号都由英文字母和数字组成,每一个标号不超过63个字符,也不区分大小写字母.标号中除连字符(-)外不能使用其他的标点符号.级别最低的域名写在最左边,而级别最高的域名写在最右边.由多 ...
- maven常用的plugin
maven-compiler-plugin 编译Java源码,一般只需设置编译的jdk版本 <plugin> <groupId>org.apache.maven.plugi ...
- Python 核心编程
第3章 Python 基础 1.语句和语法: 注释(#): 继续换句话说跨行(\):有两种例外情况一个语句不使用反斜线也可以跨行.在使用闭合操作符时,单一语句可以跨多行,如小括号.中括号,花括号等,另 ...
- pandas 数据类型转换
数据处理过程的数据类型 当利用pandas进行数据处理的时候,经常会遇到数据类型的问题,当拿到数据的时候,首先需要确定拿到的是正确类型的数据,一般通过数据类型的转化,这篇文章就介绍pandas里面的数 ...
- 世界时区和Java时区详解
0.引言 Druid中时区的问题一直困扰着我们,所以我专门去研究了一下世界时区和Java中的时区,对使用Druid很用帮助. 1.UTC时间&GMT时间 UTC时间是时间标准时间(Univer ...
- linux写文件,追加内容
覆盖文件 echo "hello" > filename 追加文件 echo "haha" >> filename
- SSH客户端提示 用户密钥未在远程主机上注册
今天在一台使用已久的内网服务器上面帮一位新同事添加账户,添加完成之后就把账号交付于他,过了10分钟他告诉我说无法登陆,觉得很诧异 这么轻车熟路的 这么会 登陆不上去了,自己也用Xshell 登陆了一下 ...
- POJ-1088 滑雪 (记忆化搜索,dp)
滑雪 Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 86318 Accepted: 32289 Description Mich ...
- [笔记]GBDT理论知识总结