sift 与 surf 算法
http://blog.csdn.net/cy513/article/details/4414352
SURF算法是SIFT算法的加速版,OpenCV的SURF算法在适中的条件下完成两幅图像中物体的匹配基本实现了实时处理,其快速的基础实际上只有一个——积分图像haar求导,对于它们其他方面的不同可以参考本blog的另外一篇关于SIFT的文章。
不论科研还是应用上都希望可以和人类的视觉一样通过程序自动找出两幅图像里面相同的景物,并且建立它们之间的对应,前几年才被提出的SIFT(尺度不变特征)算法提供了一种解决方法,通过这个算法可以使得满足一定条件下两幅图像中相同景物的某些点(后面提到的关键点)可以匹配起来,为什么不是每一点都匹配呢?下面的论述将会提到。
SIFT算法实现物体识别主要有三大工序,1、提取关键点;2、对关键点附加详细的信息(局部特征)也就是所谓的描述器;3、通过两方特征点(附带上特征向量的关键点)的两两比较找出相互匹配的若干对特征点,也就建立了景物间的对应关系。
日常的应用中,多数情况是给出一幅包含物体的参考图像,然后在另外一幅同样含有该物体的图像中实现它们的匹配。两幅图像中的物体一般只是旋转和缩放的关系,加上图像的亮度及对比度的不同,这些就是最常见的情形。基于这些条件下要实现物体之间的匹配,SIFT算法的先驱及其发明者想到只要找到多于三对物体间的匹配点就可以通过射影几何的理论建立它们的一一对应。首先在形状上物体既有旋转又有缩小放大的变化,如何找到这样的对应点呢?于是他们的想法是首先找到图像中的一些“稳定点”,这些点是一些十分突出的点不会因光照条件的改变而消失,比如角点、边缘点、暗区域的亮点以及亮区域的暗点,既然两幅图像中有相同的景物,那么使用某种方法分别提取各自的稳定点,这些点之间会有相互对应的匹配点,正是基于这样合理的假设,SIFT算法的基础是稳定点。SIFT算法找稳定点的方法是找灰度图的局部最值,由于数字图像是离散的,想求导和求最值这些操作都是使用滤波器,而滤波器是有尺寸大小的,使用同一尺寸的滤波器对两幅包含有不同尺寸的同一物体的图像求局部最值将有可能出现一方求得最值而另一方却没有的情况,但是容易知道假如物体的尺寸都一致的话它们的局部最值将会相同。SIFT的精妙之处在于采用图像金字塔的方法解决这一问题,我们可以把两幅图像想象成是连续的,分别以它们作为底面作四棱锥,就像金字塔,那么每一个截面与原图像相似,那么两个金字塔中必然会有包含大小一致的物体的无穷个截面,但应用只能是离散的,所以我们只能构造有限层,层数越多当然越好,但处理时间会相应增加,层数太少不行,因为向下采样的截面中可能找不到尺寸大小一致的两个物体的图像。有了图像金字塔就可以对每一层求出局部最值,但是这样的稳定点数目将会十分可观,所以需要使用某种方法抑制去除一部分点,但又使得同一尺度下的稳定点得以保存。有了稳定点之后如何去让程序明白它们之间是物体的同一位置?研究者想到以该点为中心挖出一小块区域,然后找出区域内的某些特征,让这些特征附件在稳定点上,SIFT的又一个精妙之处在于稳定点附加上特征向量之后就像一个根系发达的树根一样牢牢的抓住它的“土地”,使之成为更稳固的特征点,但是问题又来了,遇到旋转的情况怎么办?发明者的解决方法是找一个“主方向”然后以它看齐,就可以知道两个物体的旋转夹角了。下面就讨论一下SIFT算法的缺陷。
SIFT/SURT采用henssian矩阵获取图像局部最值还是十分稳定的,但是在求主方向阶段太过于依赖局部区域像素的梯度方向,有可能使得找到的主方向不准确,后面的特征向量提取以及匹配都严重依赖于主方向,即使不大偏差角度也可以造成后面特征匹配的放大误差,从而匹配不成功;另外图像金字塔的层取得不足够紧密也会使得尺度有误差,后面的特征向量提取同样依赖相应的尺度,发明者在这个问题上的折中解决方法是取适量的层然后进行插值。SIFT是一种只利用到灰度性质的算法,忽略了色彩信息,后面又出现了几种据说比SIFT更稳定的描述器其中一些利用到了色彩信息,让我们拭目以待。
最后要提一下,我们知道同样的景物在不同的照片中可能出现不同的形状、大小、角度、亮度,甚至扭曲;计算机视觉的知识表明通过光学镜头获取的图像,对于平面形状的两个物体它们之间可以建立射影对应,对于像人脸这种曲面物体在不同角度距离不同相机参数下获取的两幅图像,它们之间不是一个线性对应关系,就是说我们即使获得两张图像中的脸上若干匹配好的点对,还是无法从中推导出其他点的对应。
http://blog.csdn.net/CXP2205455256/article/details/41747325
首先找到图像中的一些“稳定点”,这些点是一些十分突出的点不会因光照条件的改变而消失,比如角点、边缘点、暗区域的亮点以及亮区域的点,既然两幅图像中有相同的景物,那么使用某种方法分别提取各自的稳定点,这些点之间会有相互对应的匹配点,正是基于这样合理的假设,SIFT算法的基础是稳定点。SIFT算法找稳定点的方法是找灰度图的局部最值,由于数字图像是离散的,想求导和求最值这些操作都是使用滤波器,而滤波器是有尺寸大小的,使用同一尺寸的滤波器对两幅包含有不同尺寸的同一物体的图像求局部最值将有可能出现一方求得最值而另一方却没有的情况,但是容易知道假如物体的尺寸都一致的话它们的局部最值将会相同。SIFT的精妙之处在于采用图像金字塔的方法解决这一问题,我们可以把两幅图像想象成是连续的,分别以它们作为底面作四棱锥,就像金字塔,那么每一个截面与原图像相似,那么两个金字塔中必然会有包含大小一致的物体的无穷个截面,但应用只能是离散的,所以我们只能构造有限层,层数越多当然越好,但处理时间会相应增加,层数太少不行,因为向下采样的截面中可能找不到尺寸大小一致的两个物体的图像。有了图像金字塔就可以对每一层求出局部最值,但是这样的稳定点数目将会十分可观,所以需要使用某种方法抑制去除一部分点,但又使得同一尺度下的稳定点得以保存。(此段文字来自http://blog.csdn.net/cy513/article/details/4414352)
一、尺度空间的构建
1、图像尺度空间

2、高斯差分尺度空间(DOG scale-space)
利用不同尺度的高斯差分核与图像卷积生成:

3、高斯金字塔
图像的金字塔模型是指,将原始图像不断降阶采样,得到一系列大小不一的图像,由大到小,从下到上构成的塔状模型。原图像为金子塔的第一层,每次降采样所得到的新图像为金字塔的一层(每层一张图像),每个金字塔共n 层。为了让尺度体现其连续性,高斯金字塔在简单降采样的基础上加上了高斯滤波。高斯金字塔上一组图像的初始图像(底层图像)是由前一组图像的倒数第三张图像隔点采样得到的。


4、DOG金字塔
2002年Mikolajczyk在详细的实验比较中发现尺度归一化的高斯拉普拉斯函数的极大值和极小值同其它的特征提取函数,例如:梯度,Hessian 或Harris 角特征比较,能够产生最稳定的图像特征。 而Lindeberg 早在1994 年就发现高斯差分函数(Difference of Gaussian ,简称DOG 算子)与尺度归一化的高斯拉普拉斯函数非常近似。
下图反应了两者的关系:

DOG的计算可以由相邻尺度高斯平滑后的图像相减得到:

二、检测DOG尺度空间极值点
SIFT关键点是由DOG空间的局部极值点组成的.以中心点进行3X3X3的相邻点比较,检测其是否是图像域和尺度域的相邻点的极大值或极小值.

在极值比较的过程中,每一组图像的首末两层是无法进行极值比较的,为了满足尺度变化的连续性,在每一组图像的顶层继续用高斯模糊生成了 3 幅图像,高斯金字塔有每组S+3层图像。DOG金字塔每组有S+2层图像:

三、精确定位关键点
1、位置的插值
下图是二维函数离散空间得到的极值点与连续空间极值点的差别:

利用已知的离散空间点插值得到的连续空间极值点的方法叫做子像素插值(Sub-pixel Interpolation).对尺度空间DOG函数进行曲线拟合(子像素插值),利用DOG函数在尺度空间的泰勒展开式:



公式推导如下:




极值点的偏移量的求解如下:

2、去除边缘响应
一个定义不好的高斯差分算子的极值在横跨边缘的地方有较大的主曲率,而在垂直边缘的方向有较小的主曲率。 DOG 算子会产生较强的边缘响应,需要剔除不稳定的边缘响应点。获取特征点处的Hessian 矩阵,主曲率通过一个2x2 的Hessian 矩阵H 求出:

四、特征点方向分配
对上面提取的每个关键点,围绕该点选择一个窗口(圆形区域),窗口内各采样点的梯度方向构成一个方向直方图,根据直方图的峰值确定关键点的方向。关键点的尺度用来选择哪个高斯滤波图像参与计算,还用来决定窗口的大小——为了保证不同尺度下的同一关键点的方向都包含相同的信息量,那么窗口的大小必然不一样:同一个原始图像,尺度越大,窗口应该越大;反之,如果窗口大小不变,尺度越大的图像,该窗口内的信息越少.

做一个梯度方向的直方图,范围是0~360度,其中每10度一个柱,总共36个柱。每个采样点按照其梯度方向θ(x,y)加权统计到直方图,权值为幅度m(x,y )和贡献因子的乘积。贡献因子是采样点到关键点(窗口中心)距离的量度,距离越大,贡献因子越小.直方图的峰值代表了该关键点处邻域梯度的主方向.

Lowe指出,直方图的峰值确定以后,任何大于峰值80%的方向(柱)创建一个具有该方向的关键点,因此,对于多峰值(幅值大小接近)的情形,在同一位置和尺度就会产生多个具有不同方向的关键点。虽然这样的点只占15%,但是它们却能显著地提高匹配的稳定性。用每个峰值和左右两个幅值拟合二次曲线,以定位峰值的实际位置(抛物线的最高点)。峰值方向的精度高于10度。

所以,关键点的方向分配步骤如下:

五、描述符的生成

SIFT 描述子是关键点领域高斯图像梯度统计结果的一种表示。通过对关键点周围图像区域分块,计算块内梯度直方图,生成具有独特性的向量,这个向量是该区域图像信息的一种抽象,具有唯一性。 Lowe 建议描述子使用在关键点尺度空间内4×4的窗口中计算的8 个方向的梯度信息,共4×4×8 =128维向量表征.
1、确定计算描述子所需的图像区域

计算结果四舍五入取整。
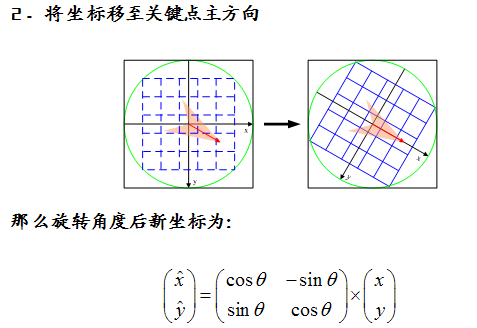
2、将坐标轴旋转为关键点的方向,以确保旋转不变性

旋转后领域内采样点的新坐标为:

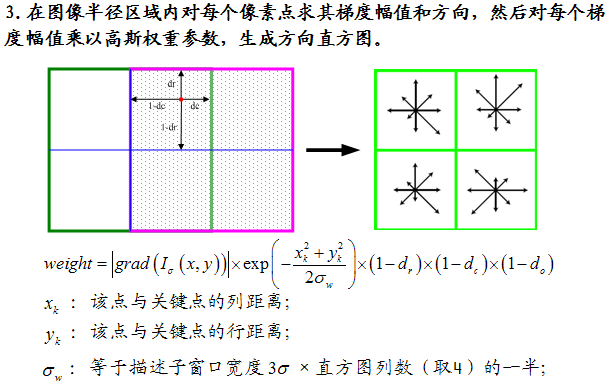
3、将领域内的采样点分配到对应的子区域内,将子区域内的梯度值分配到8 个方向上,计算其权值


4、插值计算每个种子点八个方向的梯度

如上图所示,将所得采样点在子区域中的下标(x'',y'')(图中蓝色窗口内红色点)线性插值,计算其对每个种子点的贡献。如图中的红色点,落在第0 行和第1 行之间,对这两行都有贡献。对第0 行第3 列种子点的贡献因子为dr,对第1 行第3 列的贡献因子为1-dr,同理,对邻近两列的贡献因子为dc 和1-dc,对邻近两个方向的贡献因子为do 和1-do。则最终累加在每个方向上的梯度大小为:

5、描述符向量元素门限化
即把方向直方图每个方向上梯度幅值限制在一定门限值一下(门限一般取0.2)
6、描述符向量元素归一化
特征向量形成后,为了去除光照变化的影响,需要对它们进行归一化处理,对于图像灰度值整体漂移,图像各点的梯度是邻域像素相减得到,所以也能去除。


六、匹配
采用关键点描述子的欧式距离来作为两幅图像的关键点的相似性度量。

七、SIFT算法的缺陷
(1)SIFT在求主方向阶段太过于依赖局部区域像素的梯度方向,有可能使得找到的主方向不准确,后面的特征向量提取以及匹配都严重依赖于主方向,即使不大偏差角度也可以造成后面特征匹配的放大误差,从而匹配不成功;
(2)图像金字塔的层取得不足够紧密也会使得尺度有误差,后面的特征向量提取同样依赖相应的尺度,发明者在这个问题上的折中解决方法是取适量的层然后进行插值。
(3)我们知道同样的景物在不同的照片中可能出现不同的形状、大小、角度、亮度,甚至扭曲;计算机视觉的知识表明通过光学镜头获取的图像,对于平面形状的两个物体它们之间可以建立射影对应,对于像人脸这种曲面物体在不同角度距离不同相机参数下获取的两幅图像,它们之间不是一个线性对应关系,就是说我们即使获得两张图像中的脸上若干匹配好的点对,还是无法从中推导出其他点的对应。
八、SIFT的后续发展





参考:
http://blog.csdn.net/abcjennifer/article/details/7639681
http://blog.csdn.net/cy513/article/details/4414352
http://wenku.baidu.com/view/87270d2c2af90242a895e52e.html?re=view
http://underthehood.blog.51cto.com/2531780/658350/
http://blog.csdn.net/abcjennifer/article/details/7639681/
SIFT(Scale-invariant feature transform)是一种检测局部特征的算法,该算法通过求一幅图中的特征点(interest points,or corner points)及其有关scale 和 orientation 的描述子得到特征并进行图像特征点匹配,获得了良好效果,详细解析如下:
算法描述
SIFT特征不只具有尺度不变性,即使改变旋转角度,图像亮度或拍摄视角,仍然能够得到好的检测效果。整个算法分为以下几个部分:
1. 构建尺度空间
这是一个初始化操作,尺度空间理论目的是模拟图像数据的多尺度特征。
高斯卷积核是实现尺度变换的唯一线性核,于是一副二维图像的尺度空间定义为:

其中 G(x,y,σ) 是尺度可变高斯函数 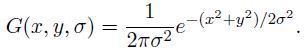
(x,y)是空间坐标,是尺度坐标。σ大小决定图像的平滑程度,大尺度对应图像的概貌特征,小尺度对应图像的细节特征。大的σ值对应粗糙尺度(低分辨率),反之,对应精细尺度(高分辨率)。为了有效的在尺度空间检测到稳定的关键点,提出了高斯差分尺度空间(DOG scale-space)。利用不同尺度的高斯差分核与图像卷积生成。
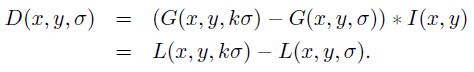
下图所示不同σ下图像尺度空间:
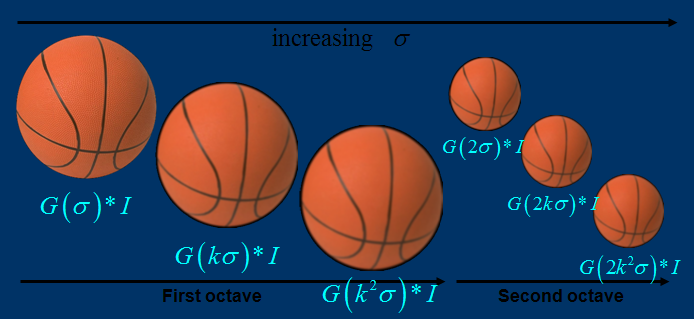
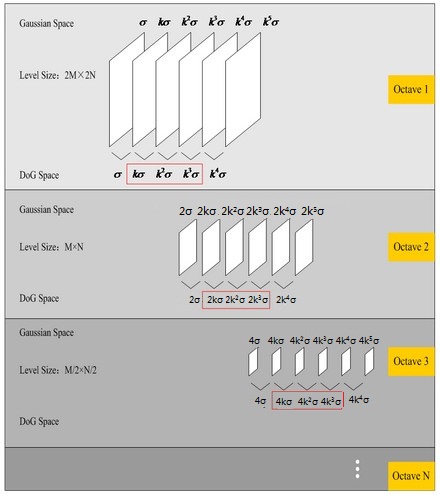
关于尺度空间的理解说明:2kσ中的2是必须的,尺度空间是连续的。在 Lowe的论文中 ,将第0层的初始尺度定为1.6(最模糊),图片的初始尺度定为0.5(最清晰). 在检测极值点前对原始图像的高斯平滑以致图像丢失高频信息,所以 Lowe 建议在建立尺度空间前首先对原始图像长宽扩展一倍,以保留原始图像信息,增加特征点数量。尺度越大图像越模糊。
图像金字塔的建立:对于一幅图像I,建立其在不同尺度(scale)的图像,也成为子八度(octave),这是为了scale-invariant,也就是在任何尺度都能够有对应的特征点,第一个子八度的scale为原图大小,后面每个octave为上一个octave降采样的结果,即原图的1/4(长宽分别减半),构成下一个子八度(高一层金字塔)。

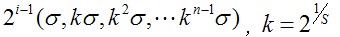
尺度空间的所有取值,i为octave的塔数(第几个塔),s为每塔层数
由图片size决定建几个塔,每塔几层图像(S一般为3-5层)。0塔的第0层是原始图像(或你double后的图像),往上每一层是对其下一层进行Laplacian变换(高斯卷积,其中σ值渐大,例如可以是σ, k*σ, k*k*σ…),直观上看来越往上图片越模糊。塔间的图片是降采样关系,例如1塔的第0层可以由0塔的第3层down sample得到,然后进行与0塔类似的高斯卷积操作。
2. LoG近似DoG找到关键点<检测DOG尺度空间极值点>
为了寻找尺度空间的极值点,每一个采样点要和它所有的相邻点比较,看其是否比它的图像域和尺度域的相邻点大或者小。如图所示,中间的检测点和它同尺度的8个相邻点和上下相邻尺度对应的9×2个点共26个点比较,以确保在尺度空间和二维图像空间都检测到极值点。 一个点如果在DOG尺度空间本层以及上下两层的26个领域中是最大或最小值时,就认为该点是图像在该尺度下的一个特征点,如图所示。
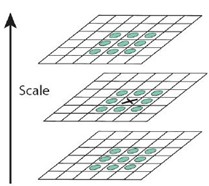
同一组中的相邻尺度(由于k的取值关系,肯定是上下层)之间进行寻找
s=3的情况
使用Laplacian of Gaussian能够很好地找到找到图像中的兴趣点,但是需要大量的计算量,所以使用Difference of Gaussian图像的极大极小值近似寻找特征点.DOG算子计算简单,是尺度归一化的LoG算子的近似,有关DOG寻找特征点的介绍及方法详见http://blog.csdn.net/abcjennifer/article/details/7639488,极值点检测用的Non-Maximal Suppression。
3. 除去不好的特征点
这一步本质上要去掉DoG局部曲率非常不对称的像素。
通过拟和三维二次函数以精确确定关键点的位置和尺度(达到亚像素精度),同时去除低对比度的关键点和不稳定的边缘响应点(因为DoG算子会产生较强的边缘响应),以增强匹配稳定性、提高抗噪声能力,在这里使用近似Harris Corner检测器。
①空间尺度函数泰勒展开式如下: ,对上式求导,并令其为0,得到精确的位置, 得
,对上式求导,并令其为0,得到精确的位置, 得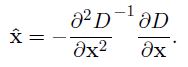
②在已经检测到的特征点中,要去掉低对比度的特征点和不稳定的边缘响应点。去除低对比度的点:把公式(2)代入公式(1),即在DoG Space的极值点处D(x)取值,只取前两项可得:

若 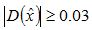 ,该特征点就保留下来,否则丢弃。
,该特征点就保留下来,否则丢弃。
③边缘响应的去除
一个定义不好的高斯差分算子的极值在横跨边缘的地方有较大的主曲率,而在垂直边缘的方向有较小的主曲率。主曲率通过一个2×2 的Hessian矩阵H求出:
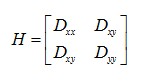
导数由采样点相邻差估计得到。
D的主曲率和H的特征值成正比,令α为较大特征值,β为较小的特征值,则
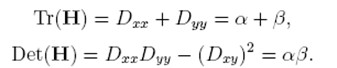
令α=γβ,则
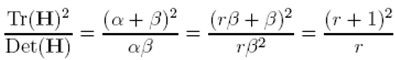
(r + 1)2/r的值在两个特征值相等的时候最小,随着r的增大而增大,因此,为了检测主曲率是否在某域值r下,只需检测
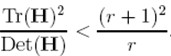
if (α+β)/ αβ> (r+1)2/r, throw it out. 在Lowe的文章中,取r=10。
4. 给特征点赋值一个128维方向参数
上一步中确定了每幅图中的特征点,为每个特征点计算一个方向,依照这个方向做进一步的计算, 利用关键点邻域像素的梯度方向分布特性为每个关键点指定方向参数,使算子具备旋转不变性。
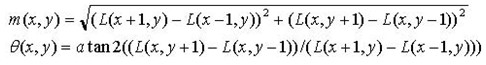
为(x,y)处梯度的模值和方向公式。其中L所用的尺度为每个关键点各自所在的尺度。至此,图像的关键点已经检测完毕,每个关键点有三个信息:位置,所处尺度、方向,由此可以确定一个SIFT特征区域。
在实际计算时,我们在以关键点为中心的邻域窗口内采样,并用直方图统计邻域像素的梯度方向。梯度直方图的范围是0~360度,其中每45度一个柱,总共8个柱, 或者每10度一个柱,总共36个柱。Lowe论文中还提到要使用高斯函数对直方图进行平滑,减少突变的影响。直方图的峰值则代表了该关键点处邻域梯度的主方向,即作为该关键点的方向。
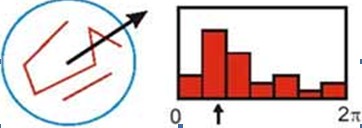
直方图中的峰值就是主方向,其他的达到最大值80%的方向可作为辅助方向
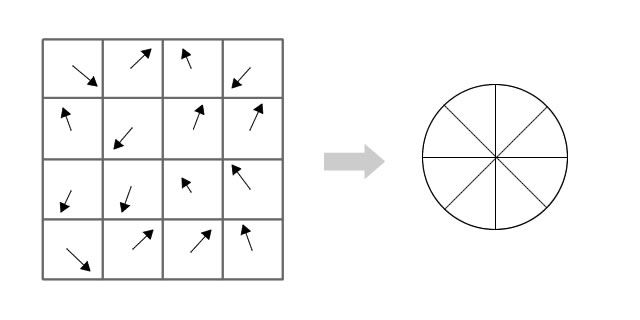
由梯度方向直方图确定主梯度方向
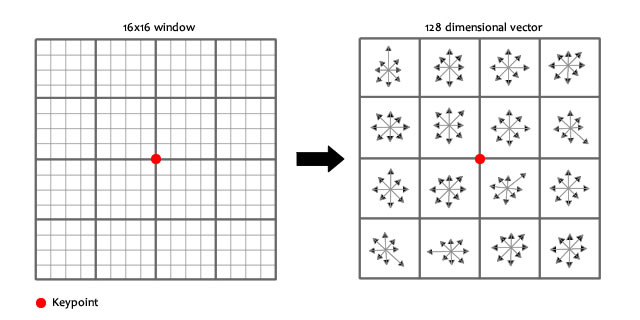
该步中将建立所有scale中特征点的描述子(128维)
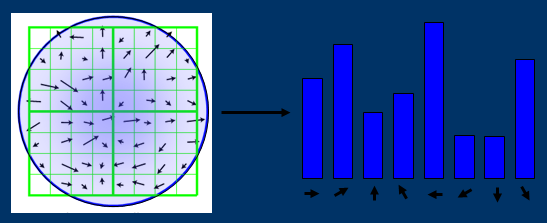
关键点描述子的生成步骤

5. 关键点描述子的生成
首先将坐标轴旋转为关键点的方向,以确保旋转不变性。以关键点为中心取8×8的窗口。
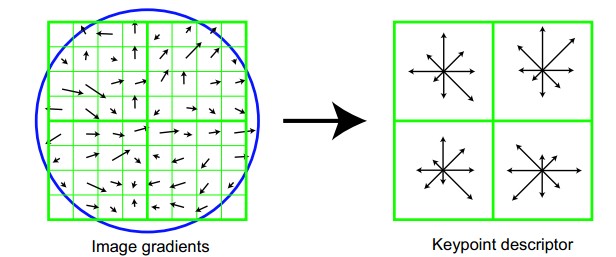
Figure.16*16的图中其中1/4的特征点梯度方向及scale,右图为其加权到8个主方向后的效果。
图左部分的中央为当前关键点的位置,每个小格代表关键点邻域所在尺度空间的一个像素,利用公式求得每个像素的梯度幅值与梯度方向,箭头方向代表该像素的梯度方向,箭头长度代表梯度模值,然后用高斯窗口对其进行加权运算。
图中蓝色的圈代表高斯加权的范围(越靠近关键点的像素梯度方向信息贡献越大)。然后在每4×4的小块上计算8个方向的梯度方向直方图,绘制每个梯度方向的累加值,即可形成一个种子点,如图右部分示。此图中一个关键点由2×2共4个种子点组成,每个种子点有8个方向向量信息。这种邻域方向性信息联合的思想增强了算法抗噪声的能力,同时对于含有定位误差的特征匹配也提供了较好的容错性。
在每个4*4的1/16象限中,通过加权梯度值加到直方图8个方向区间中的一个,计算出一个梯度方向直方图。
这样就可以对每个feature形成一个4*4*8=128维的描述子,每一维都可以表示4*4个格子中一个的scale/orientation. 将这个向量归一化之后,就进一步去除了光照的影响。
5. 根据SIFT进行Match
生成了A、B两幅图的描述子,(分别是k1*128维和k2*128维),就将两图中各个scale(所有scale)的描述子进行匹配,匹配上128维即可表示两个特征点match上了。
实际计算过程中,为了增强匹配的稳健性,Lowe建议对每个关键点使用4×4共16个种子点来描述,这样对于一个关键点就可以产生128个数据,即最终形成128维的SIFT特征向量。此时SIFT特征向量已经去除了尺度变化、旋转等几何变形因素的影响,再继续将特征向量的长度归一化,则可以进一步去除光照变化的影响。 当两幅图像的SIFT特征向量生成后,下一步我们采用关键点特征向量的欧式距离来作为两幅图像中关键点的相似性判定度量。取图像1中的某个关键点,并找出其与图像2中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离少于某个比例阈值,则接受这一对匹配点。降低这个比例阈值,SIFT匹配点数目会减少,但更加稳定。为了排除因为图像遮挡和背景混乱而产生的无匹配关系的关键点,Lowe提出了比较最近邻距离与次近邻距离的方法,距离比率ratio小于某个阈值的认为是正确匹配。因为对于错误匹配,由于特征空间的高维性,相似的距离可能有大量其他的错误匹配,从而它的ratio值比较高。Lowe推荐ratio的阈值为0.8。但作者对大量任意存在尺度、旋转和亮度变化的两幅图片进行匹配,结果表明ratio取值在0. 4~0. 6之间最佳,小于0. 4的很少有匹配点,大于0. 6的则存在大量错误匹配点。(如果这个地方你要改进,最好给出一个匹配率和ration之间的关系图,这样才有说服力)作者建议ratio的取值原则如下:
ratio=0. 4 对于准确度要求高的匹配;
ratio=0. 6 对于匹配点数目要求比较多的匹配;
ratio=0. 5 一般情况下。
也可按如下原则:当最近邻距离<200时ratio=0. 6,反之ratio=0. 4。ratio的取值策略能排分错误匹配点。
当两幅图像的SIFT特征向量生成后,下一步我们采用关键点特征向量的欧式距离来作为两幅图像中关键点的相似性判定度量。取图像1中的某个关键点,并找出其与图像2中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离少于某个比例阈值,则接受这一对匹配点。降低这个比例阈值,SIFT匹配点数目会减少,但更加稳定。
实验结果:



- import cv2
- import numpy as np
- #import pdb
- #pdb.set_trace()#turn on the pdb prompt
- #read image
- img = cv2.imread('D:\privacy\picture\little girl.jpg',cv2.IMREAD_COLOR)
- gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
- cv2.imshow('origin',img);
- #SIFT
- detector = cv2.SIFT()
- keypoints = detector.detect(gray,None)
- img = cv2.drawKeypoints(gray,keypoints)
- #img = cv2.drawKeypoints(gray,keypoints,flags = cv2.DRAW_MATCHES_FLAGS_DRAW_RICH_KEYPOINTS)
- cv2.imshow('test',img);
- cv2.waitKey(0)
- cv2.destroyAllWindows()
C实现:
- // FeatureDetector.cpp : Defines the entry point for the console application.
- //
- // Created by Rachel on 14-1-12.
- // Copyright (c) 2013年 ZJU. All rights reserved.
- //
- #include "stdafx.h"
- #include "highgui.h"
- #include "cv.h"
- #include "vector"
- #include "opencv\cxcore.hpp"
- #include "iostream"
- #include "opencv.hpp"
- #include "nonfree.hpp"
- #include "showhelper.h"
- using namespace cv;
- using namespace std;
- int _tmain(int argc, _TCHAR* argv[])
- {
- //Load Image
- Mat c_src1 = imread( "..\\Images\\3.jpg");
- Mat c_src2 = imread("..\\Images\\4.jpg");
- Mat src1 = imread( "..\\Images\\3.jpg", CV_LOAD_IMAGE_GRAYSCALE);
- Mat src2 = imread( "..\\Images\\4.jpg", CV_LOAD_IMAGE_GRAYSCALE);
- if( !src1.data || !src2.data )
- { std::cout<< " --(!) Error reading images " << std::endl; return -1; }
- //sift feature detect
- SiftFeatureDetector detector;
- std::vector<KeyPoint> kp1, kp2;
- detector.detect( src1, kp1 );
- detector.detect( src2, kp2 );
- SiftDescriptorExtractor extractor;
- Mat des1,des2;//descriptor
- extractor.compute(src1,kp1,des1);
- extractor.compute(src2,kp2,des2);
- Mat res1,res2;
- int drawmode = DrawMatchesFlags::DRAW_RICH_KEYPOINTS;
- drawKeypoints(c_src1,kp1,res1,Scalar::all(-1),drawmode);//在内存中画出特征点
- drawKeypoints(c_src2,kp2,res2,Scalar::all(-1),drawmode);
- cout<<"size of description of Img1: "<<kp1.size()<<endl;
- cout<<"size of description of Img2: "<<kp2.size()<<endl;
- //write the size of features on picture
- CvFont font;
- double hScale=1;
- double vScale=1;
- int lineWidth=2;// 相当于写字的线条
- cvInitFont(&font,CV_FONT_HERSHEY_SIMPLEX|CV_FONT_ITALIC, hScale,vScale,0,lineWidth);//初始化字体,准备写到图片上的
- // cvPoint 为起笔的x,y坐标
- IplImage* transimg1 = cvCloneImage(&(IplImage) res1);
- IplImage* transimg2 = cvCloneImage(&(IplImage) res2);
- char str1[20],str2[20];
- sprintf(str1,"%d",kp1.size());
- sprintf(str2,"%d",kp2.size());
- const char* str = str1;
- cvPutText(transimg1,str1,cvPoint(280,230),&font,CV_RGB(255,0,0));//在图片中输出字符
- str = str2;
- cvPutText(transimg2,str2,cvPoint(280,230),&font,CV_RGB(255,0,0));//在图片中输出字符
- //imshow("Description 1",res1);
- cvShowImage("descriptor1",transimg1);
- cvShowImage("descriptor2",transimg2);
- BFMatcher matcher(NORM_L2);
- vector<DMatch> matches;
- matcher.match(des1,des2,matches);
- Mat img_match;
- drawMatches(src1,kp1,src2,kp2,matches,img_match);//,Scalar::all(-1),Scalar::all(-1),vector<char>(),drawmode);
- cout<<"number of matched points: "<<matches.size()<<endl;
- imshow("matches",img_match);
- cvWaitKey();
- cvDestroyAllWindows();
- return 0;
- }
===============================
辅助资料:


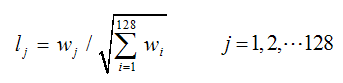
===============================
Reference:
Lowe SIFT 原文:http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf
SIFT 的C实现:https://github.com/robwhess/opensift/blob/master/src
MATLAB 应用Sift算子的模式识别方法:http://blog.csdn.net/abcjennifer/article/details/7372880
http://blog.csdn.NET/abcjennifer/article/details/7365882
http://en.wikipedia.org/wiki/Scale-invariant_feature_transform#David_Lowe.27s_method
http://blog.sciencenet.cn/blog-613779-475881.html
http://www.cnblogs.com/linyunzju/archive/2011/06/14/2080950.html
http://www.cnblogs.com/linyunzju/archive/2011/06/14/2080951.html
http://blog.csdn.net/ijuliet/article/details/4640624
http://www.cnblogs.com/cfantaisie/archive/2011/06/14/2080917.html (部分图片有误,以本文中的图片为准)
sift 与 surf 算法的更多相关文章
- 在OpenCV3.1.0中使用SIFT,SURF算法
写在前边: 1.我使用的是python2.7 + OpenCV3.1.0 2.OpenCV3.0.0+的文档有很大问题,很多文档写的还是OpenCV2.0+, OpenCV3.0+根本用不了,其中有一 ...
- Opencv Sift和Surf特征实现图像无缝拼接生成全景图像
Sift和Surf算法实现两幅图像拼接的过程是一样的,主要分为4大部分: 1. 特征点提取和描述 2. 特征点配对,找到两幅图像中匹配点的位置 3. 通过配对点,生成变换矩阵,并对图像1应用变换矩阵生 ...
- opencv3.0中contrib模块的添加+实现SIFT/SURF算法
平台:win10 x64 +VS 2015专业版 +opencv-3.x.+CMake+Anaconda3(python3.7.0) Issue说明:Opencv3.0版本已经发布了有一段时间,在这段 ...
- SURF算法与源码分析、上
如果说SIFT算法中使用DOG对LOG进行了简化,提高了搜索特征点的速度,那么SURF算法则是对DoH的简化与近似.虽然SIFT算法已经被认为是最有效的,也是最常用的特征点提取的算法,但如果不借助于硬 ...
- SURF算法与源码分析、下
上一篇文章 SURF算法与源码分析.上 中主要分析的是SURF特征点定位的算法原理与相关OpenCV中的源码分析,这篇文章接着上篇文章对已经定位到的SURF特征点进行特征描述.这一步至关重要,这是SU ...
- SURF算法
一.原理: Sift算法的优点是特征稳定,对旋转.尺度变换.亮度保持不变性,对视角变换.噪声也有一定程度的稳定性:缺点是实时性不高,并且对于边缘光滑目标的特征点提取能力较弱. Surf(Speeded ...
- 特征点检测学习_2(surf算法)
依旧转载自作者:tornadomeet 出处:http://www.cnblogs.com/tornadomeet 特征点检测学习_2(surf算法) 在上篇博客特征点检测学习_1(sift算法) 中 ...
- surf算法解析
surf构造的金字塔图像与sift有很大的不同,sift采用的是DOG图像,surf采用的是hessian矩阵行列式近似值图像,hessian矩阵是surf算法的核心,构建hessian矩阵的目的是为 ...
- 图像处理检测方法 — SIFT和SURF
0.特征与匹配方法总结汇总对比 参考网址:http://simtalk.cn/2017/08/18/%E7%89%B9%E5%BE%81%E4%B8%8E%E5%8C%B9%E9%85%8D/#ORB ...
随机推荐
- 不同.NET Framework版本下ASP.NET FormsAuthentication的兼容性
假设站点A加密使用.NET Framework 2.0,站点B解密使用.NET Framework 4.0,除了保持MachineKey相同外还需要进行如下设置: 1.Web.config的<a ...
- kvm虚拟机的重命名
1.查看所有的kvm虚拟机 [root@5201351_kvm ~]# virsh list --all 2.重命名kvm虚拟机最好是将虚拟机先关机,然后再导出其xml文件 [root@5201351 ...
- jmeter中Implementation中几个选项的区别
在jmeter发送http请求时,Implementation下拉框中有几个选项,如下: 那到底有什么区别呢?发送http请求改用哪种方法呢.百度后查之,没答案.我们还是看官方文档吧.官方文档解释如下 ...
- 基于Spring-Boot框架的Elasticsearch搜索服务器配置
一.相关包maven配置 <!-- https://mvnrepository.com/artifact/org.springframework.data/spring-data-elastic ...
- python操作数据库PostgreSQL
1.简述 python可以操作多种数据库,诸如SQLite.MySql.PostgreSQL等,这里不对所有的数据库操作方法进行赘述,只针对目前项目中用到的PostgreSQL做一下简单介绍,主要包括 ...
- 记一次centos7内核可能意外丢失(测试直接干掉)恢复方法
本次是虚拟机装的centos7的内核不知原因以外丢失造成无法开机,开机显示找不到内核! 恢复方法: 挂载新的ISO文件,然后进入bios选择dvd启动. 启动后进入Troublesshooting,然 ...
- POJ-1926 Pollution
Pollution Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 4049 Accepted: 1076 Description ...
- MapReduce的分区
第一部分 分区简述(比如国家由省市来划分) 分区:map的输出经过partitioner分区进行下一步的reducer.一个分区对应一个reducer,就会使得reducer并行化处理任务.默认为1 ...
- Pandas的append方法
相当于添加一行记录,这个方法也是比较管用的: # 测试pandas.append方法 def use_pd_append(): df = pd.DataFrame([[1, 2], [3, 4]], ...
- redux+react-redux+示例的快速上手体验
刚学习redux的同学提供一些可供参考的例子. 之前用vue用了很久 vue的语法糖用起来是真的舒服 react 其实毕竟他们都是类似的框架, 虽然语法大不同, 但是有些地方的思想还是很像的, 废话 ...