论文笔记:Emotion Recognition From Speech With Recurrent Neural Networks
动机(Motivation)
在自动语音识别(Automated Speech Recognition, ASR)中,只是把语音内容转成文字,但是人们对话过程中除了文本还有其它重要的信息,比如语调,情感,响度。这些信息对于语音的理解也是很重要的。本文关注其中一个点,如何识别出语音的情感,即语音情感识别(Speech Emotion Recognition, SER)。
语音情感识别的三个难点
1. 感情是主观的:不同人对于同一段语音,理解出的情感不尽相同,而且存在一定的文化差异。
2. 感情在语音中的划分:给出一句语音,不一定包含一种情感,可能包含多种情感。
3. 收集数据是个问题:如果从大量电影收集,不同电影类型的语音情感存在偏差。如果从新闻收集,大部分新闻的情感都是中立的。可以人工地收集,为了天然地收集,让专业演员来演绎不同的情感语音。还有其它问题,比如语音的情感应该被划分为几类,如何评估语音的情感类别,这些都没有统一的标准。
1. 第一个难点是天然存在的,没法解决。只能按数据集给定的情感标签,没法兼容不同人的理解差异。
2. 第二个难点,本文通过CTC损失函数来解决,CTC可以识别语音中的情感和没有情感的部分。
3. 第三个难点,通过选定合适的数据集后解决,选定数据集后就选定了一个情感标签和划分和评估标准
相关工作(Related works)
大部分工作将语音情感识别视作一个分类问题,一个utterance分配一个label,utterance就是一小段语音,是语音的最小单元。
深度学习之前,大多是提取低层的手工特征,用传统分类器做,比如HMM(隐马尔可夫模型)或GMM(高斯混合模型)。另外有对局部低层特征计算全局统计量,然后用SVM,决策树,KNN分类。
深度学习出现后,有人把utterance分帧计算低层特征,用三层全连接层,对输出概率聚合成utterance水平的特征(用简单的统计量,比如最大值,最小值,平均值等),最后用ELM(Extreme Learning Machine)分类。 还有人在前面这种方法的基础上把全连接层换成RNN或LSTM。这两种方法的缺点是只使用了简单的聚合和ELM,对于后者,Yann Lecun曾对其做了批判。
后面出现了纯深度学习和端到端的架构模型。有人使用Attention CNN,有人用DBN,还有人用迁移学习把语音识别的任务(数据集)迁移到语音情感识别中。
本文提出来的模型效果可以和这些模型分庭抗礼。
数据集和预处理(Data and preprocessing)
IEMOCAP(Interactive Emotional Dyadic Motion Capture)被选作数据集,因为它有详尽的获取方法,免费的学术许可,较长的语音时长和良好的标注。
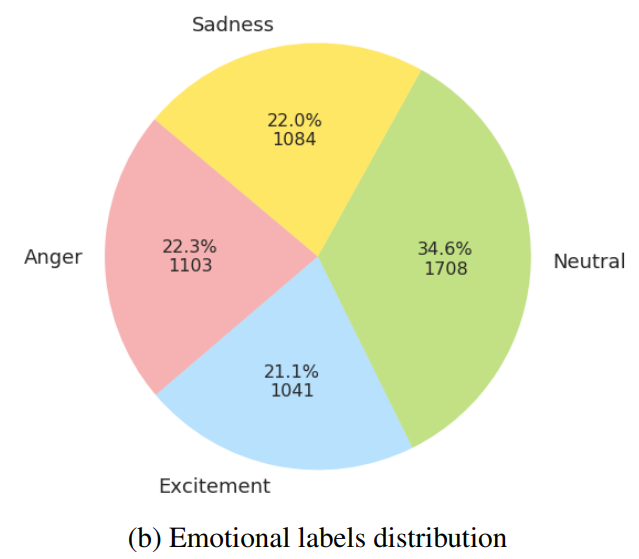
大约包括12个小时,含有视频,音频和人脸关键点的数据。由南加利福尼亚大学戏剧系的10位专业演员表演所得。评估者对每个utterance给出评价(10个情感选项),当一半以上的评估者对某个utterance的评估一致时,该utterance才分配到评估的感情。本文中选取其中4种情感用于分析(生气,兴奋,中立和伤心),只有这些样本才被考虑到本文工作中,下图是标签分布。
原始信号的采样率是16kHz,直接使用计算量很大,需要尽量保持信息的同时减小计算量。本文对utterance进行分帧,帧长为200ms,帧移为100ms(关于分帧我在笔记:语音信号和语音情感识别简述中有介绍),在帧上计算声学特征(用了哪些声学特征见下文介绍),然后把这些特征合在一起作为utterance的特征输入到模型。关于帧长的选取,论文从30ms到200ms都做过实验发现效果差别不大,而较长的帧可以导致比较少的帧,能减小计算量,所以使用了200ms。
对于语音信号的特征主要有三种,一是声学特征,也就是声波的一些属性;二是音律特征,指的是停用词,韵律(押韵,平仄),响度,这个特征依赖于说话人,所以没有用这类特征;三是语义学特征,就是语音对应的文字内容的信息。
本文只使用了声学特征,使用的是python库PyAudioAnalysis的API提供的34个特征,主要包括3个时域特征(过零率,能量,能量熵),5个谱特征,13个MFCC特征,13个音阶特征。也就是一帧的声音用34维的向量来表示。
方法
因为一个utterance只对应一个标签,但是有很多帧,有些帧是不包含情感的,所以输入序列和输出序列难以一一对应,为了应对这个问题,可以使用CTC(Connectionist Temporal Classification)的方法。
CTC的阐述需要比较大的篇幅,为了简洁起见,我把CTC的介绍单独写在这篇文章CTC(Connectionist Temporal Classification)介绍中,详情见这篇文章。
CTC模型中的LSTM的输入时间步和输出时间步T为78,因为每个语音样本划分成了78帧。情感标签有4个,加上空白符,得到大小为5的字符集合。真实输出只有一个标签,所以在这些长度为78的输出序列中,经过B转换后能得到一个真实情感标签的那些序列才是我们要的序列,用CTC的方法来使得这些序列产生的概率最大。
实验
度量指标:有两种,一种就是(全局)准确率(Overall accuracy),预测正确的样本数量除以所有的样本数,第二种就是平均类别准确率(Mean class accuracy),分别对每个类单独求一个准确率然后取平均。
Framewise:第一种方法是以一帧作为一个样本,是从每个utterance中挑两个“最大声”的帧,给它们分配utterance的情感标签。预测时根据用多数投票法决定一个utterance的情感归属。分类器用的随机森林。实验发现在短utterance上表现还行,但是在长utterance上会显得不稳定,表现曲线呈现锯齿状。
One-Label:第二个方法是一个utterance作为一个样本,该方法是一个序列到标签的学习,与之相比的CTC方法是序列到序列的学习。前面说了每一帧用34维的特征表示,但是每个utterance有多少个帧是不同的,为了保持相同,短的用0填充,长的缩短,使得每个utterance都由78帧组成(这个78是数据集中”90%“的百分位数得来的)。 使用LSTM作为模型,Adam进行梯度下降。
CTC:和One-Label的方法一样,保持每个utterance长度相同,使用78x34维的向量表示一个utterance。也使用LSTM作为模型,输出是78x5维的向量(代码中计算损失时去掉了前两个值,变成76x5,认为RNN的前两个输出没什么作用),5表示4种情感加1个空白符,使用CTC计算损失函数。另外,这里计算的时候使用原始输入序列的长度(不考虑那些padded的位置)。
实验比较
使用了分组的交叉验证方法(Grouped cross-validation),即每个样本有额外的一个组标签,在划分时同一个组的样本不能同时出现在训练集和测试集中。在IEMOCAP中,10个人的语音是通过两人对话录制而成,使用“两人对话”来作为组划分依据,可以留出20%的数据作为测试集。这么做可以防止训练集对说话人的特定说话方式过拟合。
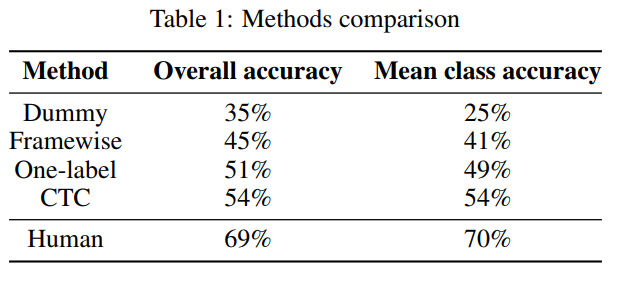
对几个方法进行的了实验对比,下面是五折的分组交叉验证结果。其中Dummy表示每次都用训练集中最多标签的类。Framewise和One-label作为baseline,human performance是作者实验室几个人的人工预测结果。
结果分析
CTC模型的结果分析
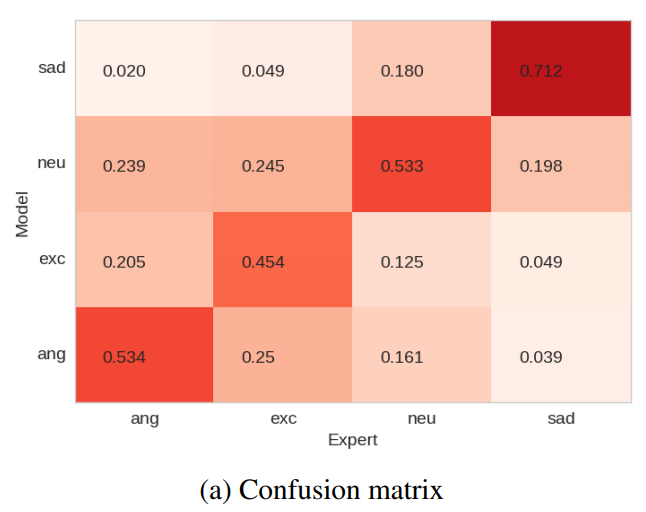
IEMOCAP的评估中,在sadness识别中语音信号起到主要作用。而angry和excitement通过视频信号更容易预测。而CTC方法中也发现了sadness的准确率更高,这很符合IEMOCAP的评估,如下图所示。
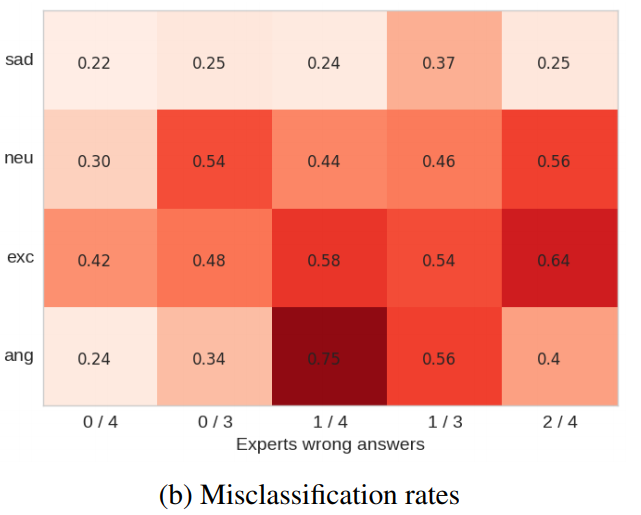
如下图,横坐标表示专家意见(对于情感标注)不一致的个数,颜色越深表示错误率越大。可以看到专家意见越不一致,错误率越大。作者做了实验,当只考虑专家意见(对于情感标注)一致的样本时,准确率可以从54%提升到65%。
作者另外做了实验,如下图所示,其中17%的意思是,最终被标记为anger的标签中有一些不一致标签,这些标签有17%落在四个情感中。51%的意思是模型的答案和专家的不一致答案相一致的百分比。可以看到,被错分到其它三类的占比越大,模型错分到其它三类的百分比也越大。可以看到模型犯错并不是随机的,如果是随机的话模型错分到其他三类的百分比应该是33%,这说明了模型的犯错和人类的犯错具有相似性。

人类表现结果分析
可以看到,人类分辨语音情感也只到达了70%,再次说明了情感带有主观性,模型也很难分类到百分百正确,而且它其实很难超过人类的准确率70%。从上表看出模型的犯错并不是随机的。但是模型犯错的机制是不清楚的,比如很难混淆生气和伤心,但是兴奋和开心却很难分。
这给了我们一个启示,模型的好坏不仅要看它的正确概率,还要看它的错误结构是否和人类判断相似。
论文笔记:Emotion Recognition From Speech With Recurrent Neural Networks的更多相关文章
- 论文翻译:Conditional Random Fields as Recurrent Neural Networks
Conditional Random Fields as Recurrent Neural Networks ICCV2015 cite237 1摘要: 像素级标注的重要性(语义分割 图像理解) ...
- 论文笔记:分形网络(FractalNet: Ultra-Deep Neural Networks without Residuals)
FractalNet: Ultra-Deep Neural Networks without Residuals ICLR 2017 Gustav Larsson, Michael Maire, Gr ...
- 论文笔记——Channel Pruning for Accelerating Very Deep Neural Networks
论文地址:https://arxiv.org/abs/1707.06168 代码地址:https://github.com/yihui-he/channel-pruning 采用方法 这篇文章主要讲诉 ...
- 论文笔记(7):Constrained Convolutional Neural Networks for Weakly Supervised Segmentation
UC Berkeley的Deepak Pathak 使用了一个具有图像级别标记的训练数据来做弱监督学习.训练数据中只给出图像中包含某种物体,但是没有其位置信息和所包含的像素信息.该文章的方法将imag ...
- 论文翻译:2020_WaveCRN: An efficient convolutional recurrent neural network for end-to-end speech enhancement
论文地址:用于端到端语音增强的卷积递归神经网络 论文代码:https://github.com/aleXiehta/WaveCRN 引用格式:Hsieh T A, Wang H M, Lu X, et ...
- 论文翻译:2020_Lightweight Online Noise Reduction on Embedded Devices using Hierarchical Recurrent Neural Networks
论文地址:基于分层递归神经网络的嵌入式设备轻量化在线降噪 引用格式:Schröter H, Rosenkranz T, Zobel P, et al. Lightweight Online Noise ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- 《The Unreasonable Effectiveness of Recurrent Neural Networks》阅读笔记
李飞飞徒弟Karpathy的著名博文The Unreasonable Effectiveness of Recurrent Neural Networks阐述了RNN(LSTM)的各种magic之处, ...
- cs231n spring 2017 lecture10 Recurrent Neural Networks 听课笔记
(没太听明白,下次重新听一遍) 1. Recurrent Neural Networks
随机推荐
- Docker定制容器镜像(利用Dockerfile文件)
1.创建Dockerfile文件 新建一个目录,在里面新建一个dockerfile文件(新建一个的目录,主要是为了和以防和其它dockerfile混乱 ) [root@docker01 myfiles ...
- npm使用报错解决办法
在使用脚手架工具进行项目搭建的时候,很多时候会用到npm ,最近用npm的时候遇到一个错误: 'CALL "I:\Program Files\nodejs\\node.exe" & ...
- Qt qDebug() 的使用方法
在Qt程序调试的时候,经常需要打印一些变量,那么我们就需要使用qDebug()函数,这种函数有两种使用方法,如下所示: QString s = "Jack"; qDebug() & ...
- 浙江工业大学校赛 小M和天平
小M和天平 Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Total Subm ...
- ubuntu16.04下安装ros-kinetic
参考:http://wiki.ros.org/kinetic/Installation/Ubuntu 1.添加ROS软件源 ~$ sudo sh -c 'echo "deb http://p ...
- 2.0CNN
介绍 https://www.youtube.com/watch?v=jajksuQW4mc https://www.youtube.com/watch?v=2-Ol7ZB0MmU https://w ...
- hihocoder 1323 - 回文字符串 - [hiho一下162周][区间dp]
用dp[i][j]表示把[i,j]的字符串str改写成回文串需要的最小操作步数. 并且假设所有dp[ii][jj] (ii>i , jj<j)都为已知,即包括dp[i+1][j].dp[i ...
- 如何快速创建提交一个项目到Github
1.https://github.com创建一个repository 2.本地创建一个文件夹A 3.命令行转到新文件夹A,执行git init使其能被git管理,并生成.git隐藏文件 4.如内容,应 ...
- UIGestureRecognizer和UITouch
UIGestureRecognizer和UITouch是分别判断的,如果判定了是手势,那就不再触发UITouch事件,如果两者并存,则会先执行UITouch事件,之后如果确认是手势,不再执行UITou ...
- 《前端JavaScript面试技巧》笔记一
思考: 拿到一个面试题,你第一时间看到的是什么 -> 考点 又如何看待网上搜出来的永远也看不完的题海 -> 不变应万变 如何对待接下来遇到的面试题 -> 题目到知识再到题目 知识体系 ...