Spark Sort-Based Shuffle具体实现内幕和源码详解
为什么讲解Sorted-Based shuffle?2方面的原因:
一,可能有些朋友看到Sorted-Based Shuffle的时候,会有一个误解,认为Spark基于Sorted-Based Shuffle 它产出的结果是有序的。
二,Sorted-Based Shuffle要排序,涉及到一个排序算法。
Sorted-Based Shuffle 的核心是借助于 ExternalSorter 把每个 ShuffleMapTask 的输出,排序到一个文件中 (FileSegmentGroup),为了区分下一个阶段 Reducer Task 不同的内容,它还需要有一个索引文件 (Index) 来告诉下游 Stage 的并行任务,哪一部份是属于你的。
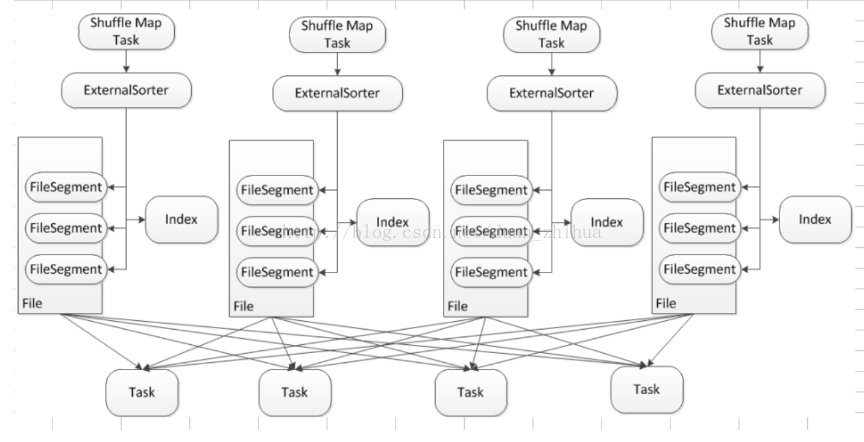
Shuffle Map Task 在ExternalSorter 溢出到磁盘的时候,产生一组 File (File Group是hashShuffle中的概念,理解为一个file文件池,这里为区分,使用File的概念,FileSegment根据PartionID排序)和 一个索引文件,File 里的 FileSegement 会进行排序,在 Reducer 端有4个Reducer Task,下游的 Task 可以很容易跟据索引 (index) 定位到这个 Fie 中的哪部份 FileSegement 是属于下游的,它相当于一个指针,下游的 Task 要向 Driver 去碓定文件在那里,然后到了这个 File 文件所在的地方,实际上会跟 BlockManager 进行沟通,BlockManager 首先会读一个 Index 文件,根据它的命名则进行解析,比如说下一个阶段的第一个 Task,一般就是抓取第一个 Segment,这是一个指针定位的过程。
再次强调 Sort-Based Shuffle 最大的意义是减少临时文件的输出数量,且只会产生两个文件:一个是包含不同内容划分成不同 FileSegment 构成的单一文件 File,另外一个是索引文件 Index。
一件很重要的事情:在Sorted-Shuffle中会排序吗?从测试的结果来看,结果一般不排序。(例如我们可以在spark2.0中做一个wordcount测试,结果是不排序的)
Sort-Based Shuffle Mapper端的 Sort and Spill 的过程 (ApependOnlyMap时不进行排序,Spill 到磁盘的时候再进行排序的)
现在我们从源码的角度去看看到底Sorted-Based Shuffle这个排序实际上是在干什么的。
SparkEnv.scala:默认情况是sort类型,全称org.apache.spark.shuffle.sort.SortShuffleManager
// Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass = shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase, shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
进入org.apache.spark.shuffle.sort.SortShuffleManager,我们怎么去看这个源代码,再看一下上面的架构图

SortShuffleManager中没找到这个ExternalSorter,那我们从ShuffleMapTask中去看怎么写数据的。
看一下ShuffleMapTask中runTask的writer
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val threadMXBean = ManagementFactory.getThreadMXBean
val deserializeStartTime = System.currentTimeMillis()
val deserializeStartCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime
} else 0L
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
_executorDeserializeCpuTime = if (threadMXBean.isCurrentThreadCpuTimeSupported) {
threadMXBean.getCurrentThreadCpuTime - deserializeStartCpuTime
} else 0L
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
manager = SparkEnv.get.shuffleManager是从SparkEnv中通过反射的获取的shuffleManager,就是SortShuffleManager。那 manager.getWriter是SortShuffleManager的getWriter
/** Get a writer for a given partition. Called on executors by map tasks. */
override def getWriter[K, V](
handle: ShuffleHandle,
mapId: Int,
context: TaskContext): ShuffleWriter[K, V] = {
numMapsForShuffle.putIfAbsent(
handle.shuffleId, handle.asInstanceOf[BaseShuffleHandle[_, _, _]].numMaps)
val env = SparkEnv.get
handle match {
case unsafeShuffleHandle: SerializedShuffleHandle[K @unchecked, V @unchecked] =>
new UnsafeShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
context.taskMemoryManager(),
unsafeShuffleHandle,
mapId,
context,
env.conf)
case bypassMergeSortHandle: BypassMergeSortShuffleHandle[K @unchecked, V @unchecked] =>
new BypassMergeSortShuffleWriter(
env.blockManager,
shuffleBlockResolver.asInstanceOf[IndexShuffleBlockResolver],
bypassMergeSortHandle,
mapId,
context,
env.conf)
case other: BaseShuffleHandle[K @unchecked, V @unchecked, _] =>
new SortShuffleWriter(shuffleBlockResolver, other, mapId, context)
}
}
SortShuffleManager getWriter Handle提供的三种方式
- unsafeShuffleHandle : tungsten深度优化的方式
- bypassMergeSortHandle:Sorted-Shuffle在一定程度上可以退化为hashShuffle的方式
- BaseShuffleHandle:是SortShuffleWriter
再回到之前ShuffleMapTask中,获取shufflemanager getWriter之后,要write写数据。
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
那我们看SortShuffleWriter的write方法(idea按ctrl+F12),代码是非常清晰,简洁的。经过千辛万苦,一步一步追踪,我们终于看到了
ExternalSorter
/** Write a bunch of records to this task's output */
override def write(records: Iterator[Product2[K, V]]): Unit = {
sorter = if (dep.mapSideCombine) {
require(dep.aggregator.isDefined, "Map-side combine without Aggregator specified!")
new ExternalSorter[K, V, C](
context, dep.aggregator, Some(dep.partitioner), dep.keyOrdering, dep.serializer)
} else {
// In this case we pass neither an aggregator nor an ordering to the sorter, because we don't
// care whether the keys get sorted in each partition; that will be done on the reduce side
// if the operation being run is sortByKey.
new ExternalSorter[K, V, V](
context, aggregator = None, Some(dep.partitioner), ordering = None, dep.serializer)
}
sorter.insertAll(records) // Don't bother including the time to open the merged output file in the shuffle write time,
// because it just opens a single file, so is typically too fast to measure accurately
// (see SPARK-3570).
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
try {
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
} finally {
if (tmp.exists() && !tmp.delete()) {
logError(s"Error while deleting temp file ${tmp.getAbsolutePath}")
}
}
}
ExternalSorter.scala中有2个很重要的数据结构:
// Data structures to store in-memory objects before we spill. Depending on whether we have an
// Aggregator set, we either put objects into an AppendOnlyMap where we combine them, or we
// store them in an array buffer.
@volatile private var map = new PartitionedAppendOnlyMap[K, C]
@volatile private var buffer = new PartitionedPairBuffer[K, C]
1,在map端进行combine:PartitionedAppendOnlyMap 是map类型的数据结构,map是key-value ,在本地进行聚合,在本地key值不变,Value不断进行更新;PartitionedAppendOnlyMap 底层还是一个数组,基于数组实现map的原因是更节省空间,效率更高。那么直接基于数组怎么实现map:把数组的标记 0 1 2 3 4 .。。。把偶数设置为map的key值,把奇数设置为map的value值。
2,在map端没有combine:使用PartitionedPairBuffer
看一下insertAll方法:
def insertAll(records: Iterator[Product2[K, V]]): Unit = {
// TODO: stop combining if we find that the reduction factor isn't high
val shouldCombine = aggregator.isDefined
if (shouldCombine) {
// Combine values in-memory first using our AppendOnlyMap
val mergeValue = aggregator.get.mergeValue
val createCombiner = aggregator.get.createCombiner
var kv: Product2[K, V] = null
val update = (hadValue: Boolean, oldValue: C) => {
if (hadValue) mergeValue(oldValue, kv._2) else createCombiner(kv._2)
}
while (records.hasNext) {
addElementsRead()
kv = records.next()
map.changeValue((getPartition(kv._1), kv._1), update)
maybeSpillCollection(usingMap = true)
}
} else {
// Stick values into our buffer
while (records.hasNext) {
addElementsRead()
val kv = records.next()
buffer.insert(getPartition(kv._1), kv._1, kv._2.asInstanceOf[C])
maybeSpillCollection(usingMap = false)
}
}
}
首先判断是否聚合shouldCombine:
1,如果聚合,map.changeValue此时key不变,在历史value基础上进行combine。
2,没有聚合,直接在buffer数据结构中插入一条记录。
注意:这个时候没有排序。
继续回到SortShuffleWriter的write方法:
根据dep.shuffleId, mapId获取输出文件output
写数据 根据dep.shuffleId, mapId, partitionLengths, tmp,tmp是中间临时文件写入文件和更新索引。
task运行结束以后返回的mapStatus数据结构,告诉数据放在哪里。
val output = shuffleBlockResolver.getDataFile(dep.shuffleId, mapId)
val tmp = Utils.tempFileWith(output)
try {
val blockId = ShuffleBlockId(dep.shuffleId, mapId, IndexShuffleBlockResolver.NOOP_REDUCE_ID)
val partitionLengths = sorter.writePartitionedFile(blockId, tmp)
shuffleBlockResolver.writeIndexFileAndCommit(dep.shuffleId, mapId, partitionLengths, tmp)
mapStatus = MapStatus(blockManager.shuffleServerId, partitionLengths)
我们看一下writePartitionedFile,分别实现了spill和不spill怎么做。
def writePartitionedFile(
blockId: BlockId,
outputFile: File): Array[Long] = { // Track location of each range in the output file
val lengths = new Array[Long](numPartitions)
val writer = blockManager.getDiskWriter(blockId, outputFile, serInstance, fileBufferSize,
context.taskMetrics().shuffleWriteMetrics) if (spills.isEmpty) {
// Case where we only have in-memory data
val collection = if (aggregator.isDefined) map else buffer
val it = collection.destructiveSortedWritablePartitionedIterator(comparator)
while (it.hasNext) {
val partitionId = it.nextPartition()
while (it.hasNext && it.nextPartition() == partitionId) {
it.writeNext(writer)
}
val segment = writer.commitAndGet()
lengths(partitionId) = segment.length
}
} else {
// We must perform merge-sort; get an iterator by partition and write everything directly.
for ((id, elements) <- this.partitionedIterator) {
if (elements.hasNext) {
for (elem <- elements) {
writer.write(elem._1, elem._2)
}
val segment = writer.commitAndGet()
lengths(id) = segment.length
}
}
} writer.close()
context.taskMetrics().incMemoryBytesSpilled(memoryBytesSpilled)
context.taskMetrics().incDiskBytesSpilled(diskBytesSpilled)
context.taskMetrics().incPeakExecutionMemory(peakMemoryUsedBytes) lengths
}
大家看一下里面有没有排序的事情?可能没有看见,里面有一句很关键的代码:val it = collection.destructiveSortedWritablePartitionedIterator(comparator),生成一个it WritablePartitionedIterator写数据
那我们看一下WritablePartitionedPairCollection
private[spark] trait WritablePartitionedPairCollection[K, V] {
/**
* Insert a key-value pair with a partition into the collection
*/
def insert(partition: Int, key: K, value: V): Unit
/**
* Iterate through the data in order of partition ID and then the given comparator. This may
* destroy the underlying collection.
*/
def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]])
: Iterator[((Int, K), V)]
这个地方看到了排序:以partition ID进行排序,实现快速的写,方便的读操作;关键的一点对KEY进行操作。
看一下继承结构PartitionedAppendOnlyMap
/**
* Implementation of WritablePartitionedPairCollection that wraps a map in which the keys are tuples
* of (partition ID, K)
*/
private[spark] class PartitionedAppendOnlyMap[K, V]
extends SizeTrackingAppendOnlyMap[(Int, K), V] with WritablePartitionedPairCollection[K, V] { def partitionedDestructiveSortedIterator(keyComparator: Option[Comparator[K]])
: Iterator[((Int, K), V)] = {
val comparator = keyComparator.map(partitionKeyComparator).getOrElse(partitionComparator)
destructiveSortedIterator(comparator)
} def insert(partition: Int, key: K, value: V): Unit = {
update((partition, key), value)
}
}
点击destructiveSortedIterator
/**
* Return an iterator of the map in sorted order. This provides a way to sort the map without
* using additional memory, at the expense of destroying the validity of the map.
*/
def destructiveSortedIterator(keyComparator: Comparator[K]): Iterator[(K, V)] = {
destroyed = true
// Pack KV pairs into the front of the underlying array
var keyIndex, newIndex =
while (keyIndex < capacity) {
if (data( * keyIndex) != null) {
data( * newIndex) = data( * keyIndex)
data( * newIndex + ) = data( * keyIndex + )
newIndex +=
}
keyIndex +=
}
assert(curSize == newIndex + (if (haveNullValue) else )) new Sorter(new KVArraySortDataFormat[K, AnyRef]).sort(data, , newIndex, keyComparator) new Iterator[(K, V)] {
var i =
var nullValueReady = haveNullValue
def hasNext: Boolean = (i < newIndex || nullValueReady)
def next(): (K, V) = {
if (nullValueReady) {
nullValueReady = false
(null.asInstanceOf[K], nullValue)
} else {
val item = (data( * i).asInstanceOf[K], data( * i + ).asInstanceOf[V])
i +=
item
}
}
}
}
里面的关键的地方有一个new Sorter
class Sorter[K, Buffer](private val s: SortDataFormat[K, Buffer]) {
private val timSort = new TimSort(s)
/**
* Sorts the input buffer within range [lo, hi).
*/
def sort(a: Buffer, lo: Int, hi: Int, c: Comparator[_ >: K]): Unit = {
timSort.sort(a, lo, hi, c)
}
}
sorter里面使用的是timSort算法
Spark Sort-Based Shuffle具体实现内幕和源码详解的更多相关文章
- [Spark内核] 第40课:CacheManager彻底解密:CacheManager运行原理流程图和源码详解
本课主题 CacheManager 运行原理图 CacheManager 源码解析 CacheManager 运行原理图 [下图是CacheManager的运行原理图] 首先 RDD 是通过 iter ...
- Spark Sort Based Shuffle内存分析
分布式系统里的Shuffle 阶段往往是非常复杂的,而且分支条件也多,我只能按着我关注的线去描述.肯定会有不少谬误之处,我会根据自己理解的深入,不断更新这篇文章. 前言 借用和董神的一段对话说下背景: ...
- dom4j的测试例子和源码详解(重点对比和DOM、SAX的区别)
目录 简介 DOM.SAX.JAXP和DOM4J xerces解释器 SAX DOM JAXP DOM解析器 获取SAX解析器 DOM4j 项目环境 工程环境 创建项目 引入依赖 使用例子--生成xm ...
- [Qt Creator 快速入门] 第2章 Qt程序编译和源码详解
一.编写 Hello World Gui程序 Hello World程序就是让应用程序显示"Hello World"字符串.这是最简单的应用,但却包含了一个应用程序的基本要素,所以 ...
- Arouter核心思路和源码详解
前言 阅读本文之前,建议读者: 对Arouter的使用有一定的了解. 对Apt技术有所了解. Arouter是一款Alibaba出品的优秀的路由框架,本文不对其进行全面的分析,只对其最重要的功能进行源 ...
- go map数据结构和源码详解
目录 1. 前言 2. go map的数据结构 2.1 核心结体体 2.2 数据结构图 3. go map的常用操作 3.1 创建 3.2 插入或更新 3.3 删除 3.4 查找 3.5 range迭 ...
- jdbc-mysql测试例子和源码详解
目录 简介 什么是JDBC 几个重要的类 使用中的注意事项 使用例子 需求 工程环境 主要步骤 创建表 创建项目 引入依赖 编写jdbc.prperties 获得Connection对象 使用Conn ...
- cglib测试例子和源码详解
目录 简介 为什么会有动态代理? 常见的动态代理有哪些? 什么是cglib 使用例子 需求 工程环境 主要步骤 创建项目 引入依赖 编写被代理类 编写MethodInterceptor接口实现类 编写 ...
- DBCP2的使用例子和源码详解(不包括JNDI和JTA支持的使用)
目录 简介 使用例子 需求 工程环境 主要步骤 创建项目 引入依赖 编写jdbc.prperties 获取连接池和获取连接 编写测试类 配置文件详解 数据库连接参数 连接池数据基本参数 连接检查参数 ...
随机推荐
- 【linux系列】centos安装vsftp
一.检查vsftpd软件 如果发现上不了网可以修改配置文件中的ONBOOT=no改为yes,然后重启服务试试
- update select 多字段
update Countrys set ( Abbreviation_cn, Abbreviation_en, Two_code,Three_code, Number_code)= (select [ ...
- 题目1005:Graduate Admission(录取算法)
题目链接:http://ac.jobdu.com/problem.php?pid=1005 详解链接:https://github.com/zpfbuaa/JobduInCPlusPlus 参考代码: ...
- Pyqt中富文本编辑器
对于文本编辑,qt提供了很多控件 QLineEdit:单行文本输入,比如用户名密码等简单的较短的或者具有单一特征的字符串内容输入.使用text.settext读写 QTextEdit:富文本编辑器,支 ...
- 对crf++的template的理解 ©seven_clear
这是以前的一篇草稿,当初没写完,今天发出来,但总觉得水平有限,越学越觉得自己菜,写的博客水准低,发完这篇以后就谨慎发博了,毕竟自己菜,不能老吹B,下面是原稿. 好久没更了,本来年前想写篇关于爬虫的总结 ...
- 【巷子】---vue基于mint-ui三级联动---【vue】
一.基本配置 https://github.com/modood/Administrative-divisions-of-China 三级联动数据地址 二.vue基本配置 1.cnpm install ...
- GitHub 终端加速最佳实践
终端加速 GitHub 方法的前置条件, 一是购买了加速服务或者租用 VPS 搭建加速服务, 二是系统是 macOS, 三是终端是 iTerm, 四是 Shell 是 zsh. 终端加速 GitHub ...
- TFS二次开发10——分组(Group)和成员(Member)
TFS SDK 10 ——分组(Group)和成员(Member) 这篇来介绍怎样读取TFS服务器上的用户信息 首先TFS默认有如下分组(Group): SharePoint Web Applicat ...
- php中调用这个功能可以在web页面中显示hello world这个经典单词
php程序写的时间长了,自然对他所提供的功能了如指掌,他所提供的一大堆功能,真是觉得很好用,但有时候会发现php也缺少一些功能,自己总是会产生为php添加一些自定义的功能的想法.久而久之,终于今天憋不 ...
- Linq 多连接及 left join 实例 记录
var retList = from d in mbExList.Cast<MaterialBaseEx>().ToList() join c in umcList.Cast<Cla ...