转 部署Zipkin分布式性能追踪日志系统的操作记录
2017年02月27日 11:01:29 https://blog.csdn.net/konglongaa/article/details/58016398
Zipkin是Twitter的一个开源项目,是一个致力于收集Twitter所有服务的监控数据的分布式跟踪系统,它提供了收集数据,和查询数据两大接口服务。
三、Zipkin功能解说
zipkin作用
全链路追踪工具(根据依赖关系)
查看每个接口、每个service的执行速度(定位问题发生点或者寻找性能瓶颈)
zipkin工作原理
创造一些追踪标识符(tracingId,spanId,parentId),最终将一个request的流程树构建出来
zipkin架构
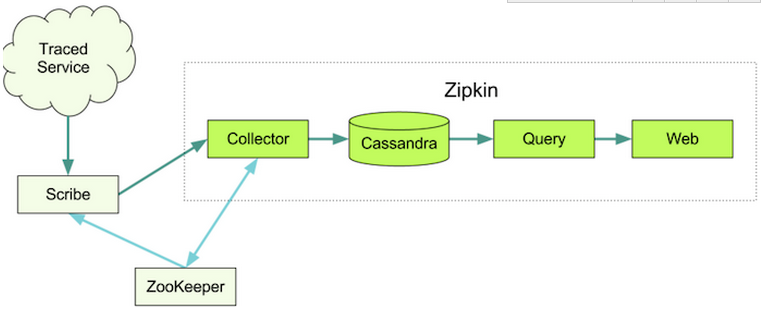
其中:
Collector接收各service传输的数据;
Cassandra作为Storage的一种,也可以是mysql等,默认存储在内存中,配置cassandra可以参考这里;
Query负责查询Storage中存储的数据,提供简单的JSON API获取数据,主要提供给web UI使用;
Web 提供简单的web界面;
zipkin分布式跟踪系统的目的:
zipkin为分布式链路调用监控系统,聚合各业务系统调用延迟数据,达到链路调用监控跟踪;
zipkin通过采集跟踪数据可以帮助开发者深入了解在分布式系统中某一个特定的请求时如何执行的;
假如我们现在有一个用户请求超时,我们就可以将这个超时的请求调用链展示在UI当中;我们可以很快度的定位到导致响应很慢的服务究竟是什么。如果对这个服务细节也很很清晰,那么我们还可以定位是服务中的哪个问题导致超时;
zipkin系统让开发者可通过一个Web前端轻松的收集和分析数据,例如用户每次请求服务的处理时间等,可方便的监测系统中存在的瓶颈。
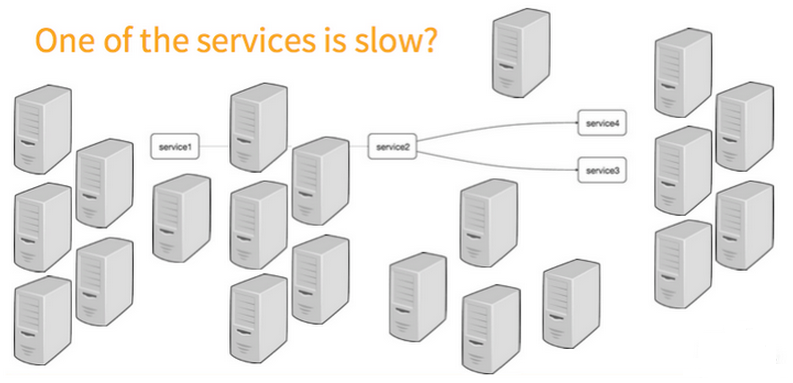
例如下图:
在复杂的调用链路中假设存在一条调用链路响应缓慢,如何定位其中延迟高的服务呢?
1)日志:通过分析调用链路上的每个服务日志得到结果
2)zipkin:使用zipkin的web UI可以一眼看出延迟高的服务
各业务系统在彼此调用时,将特定的跟踪消息传递至zipkin,zipkin在收集到跟踪信息后将其聚合处理、存储、展示等,用户可通过web UI方便
获得网络延迟、调用链路、系统依赖等等。
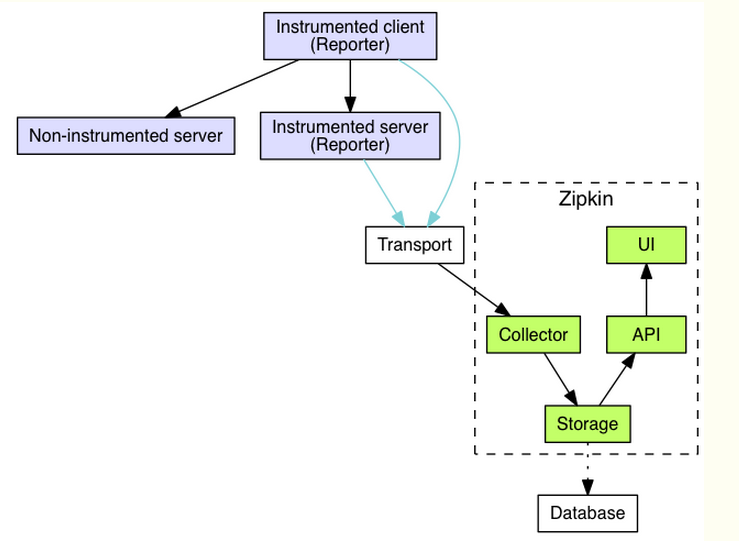
transport作用:收集被trace的services的spans,并将它们转化为zipkin common Span,之后把这些Spans传递的存储层。
有三种主要的transport:
HTTP(默认)
通过http headers来传递追踪信息
header中的key
X-B3-TraceId: 64 encoded bits(id被encode为hex Strings)
X-B3-SpanId: 64 encoded bits
X-B3-ParentSpanId: 64 encoded bits
X-B3-Sampled: Boolean (either “1” or “0”)(下面的调用是否进行采样)
X-B3-Flags: a Long
Scribe
Kafka
zipkin基础架构(4个组件:collector、storage、search、webUI)
collector
作用:zipkin collector会对一个到来的被trace的数据(span)进行验证、存储并设置索引。
storage
in-memory(默认)
仅用于测试,因为采集数据不会持久化
默认使用这个存储,若要使用其他存储,查看:
https://github.com/openzipkin/zipkin/tree/master/zipkin-server
https://github.com/openzipkin/zipkin-dependencies
JDBC (mysql)
如果采集数据量很大的话,查询速度会比较慢
Cassandra
zipkin最初始内建的存储(扩展性好、schema灵活)
This store requires a spark job to aggregate dependency links
Elasticsearch
This store requires a spark job to aggregate dependency links
被设计用于大规模
存储形式为json
search
webUI
zipkin核心数据结构
Annotation(用途:用于定位一个request的开始和结束,cs/sr/ss/cr含有额外的信息,比如说时间点)
cs:Client Start,表示客户端发起请求
一个span的开始
sr:Server Receive,表示服务端收到请求
ss:Server Send,表示服务端完成处理,并将结果发送给客户端
cr:Client Received,表示客户端获取到服务端返回信息
一个span的结束
当这个annotation被记录了,这个RPC也被认为完成了
BinaryAnnotation(用途:提供一些额外信息,一般已key-value对出现)
Span:一个请求(包含一组Annotation和BinaryAnnotation);它是基本工作单元,一次链路调用(可以是RPC,DB等没有特定的限制)创建一个span,通过一个64位ID标识它。
span通过还有其他的数据,例如描述信息,时间戳,key-value对的(Annotation)tag信息,parent-id等,其中parent-id
可以表示span调用链路来源,通俗的理解span就是一次请求信息
Trace:类似于树结构的Span集合,表示一条调用链路,存在唯一标识
Traces are built by collecting all Spans that share a traceId
通过traceId、spanId和parentId,被收集到的span会汇聚成一个tree,从而提供出一个request的整体流程。(这也是zipkin的工作原理)
注意:时间点计算
sr-cs:网络延迟
ss-sr:逻辑处理时间
cr-cs:整个流程时间
Trace identifiers
含义:通过下边3个Id,对数据进行重组
三个Id(64位 long型数据)
TraceId
The overall ID of the trace.
Every span in a trace will share this ID.
SpanId
The ID for a particular span.
This may or may not be the same as the trace id.
ParentId
This is an optional ID that will only be present on child spans.
That is the span without a parent id is considered the root of the trace.
zipkin工作流程图(完整的调用链路)
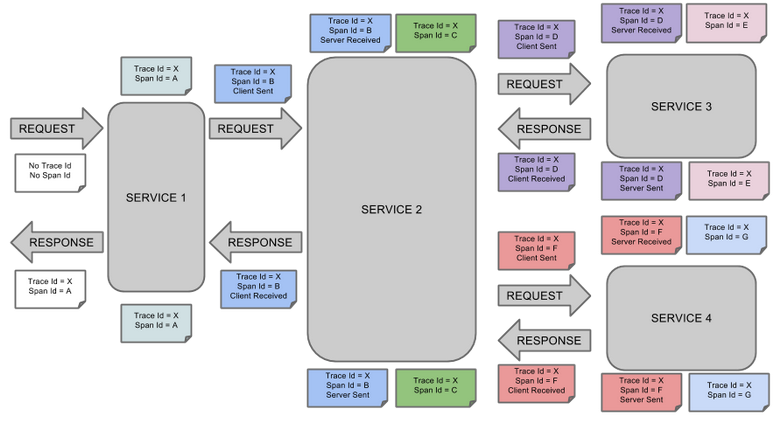
上图说明:X和A可以相等
上图表示一请求链路,一条链路通过Trace Id唯一标识,Span标识发起的请求信息,各span通过parent id关联起来;
父子span关系:
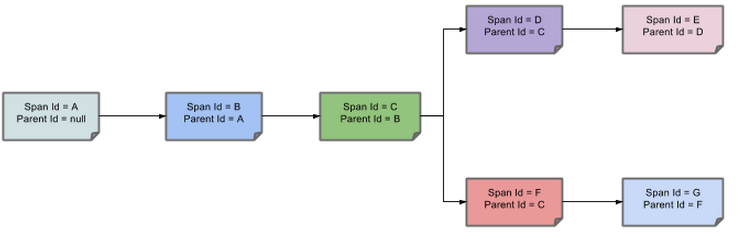
说明:parentId==null,表示该span就是root span。
整个链路的依赖关系如下:

完成链路调用的记录后,如何来计算调用的延迟呢,这就需要利用Annotation信息:

总结两点:
1)使用zipkin,必须使用java8
2)在生产环境,不会对每个请求都进行采样追踪(降低trace对整个服务的性能损耗)
-------------------------------------------------------------------
还可以考虑使用下面的架构:

kafka是使用zookeeper来管理的(kafka在Zookeeper中注册的地址)
在zipkin网页上选择要看的项目后,点击Find Traces查看
转 部署Zipkin分布式性能追踪日志系统的操作记录的更多相关文章
- 部署Zipkin分布式性能追踪日志系统的操作记录
Zipkin是Twitter的一个开源项目,是一个致力于收集Twitter所有服务的监控数据的分布式跟踪系统,它提供了收集数据,和查询数据两大接口服务. 部署Zipkin环境的操作记录:部署Zipki ...
- zipkin分布式链路追踪系统
基于zipkin分布式链路追踪系统预研第一篇 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Inf ...
- spring cloud 2.x版本 Sleuth+Zipkin分布式链路追踪
前言 本文采用Spring cloud本文为2.1.8RELEASE,version=Greenwich.SR3 本文基于前两篇文章eureka-server.eureka-client.eureka ...
- 基于zipkin分布式链路追踪系统预研第一篇
本文为博主原创文章,未经博主允许不得转载. 分布式服务追踪系统起源于Google的论文“Dapper, a Large-Scale Distributed Systems Tracing Infras ...
- Centos7下部署两套python版本并存环境的操作记录
需求说明:centos7.2系统的开发机器上已经自带了python2.7版本,但是开发的项目中用的是python3.5版本,为了保证Centos系统的正常运行,以及节省机器资源(不想因此再申请另外一台 ...
- .NetCore 使用Zipkin 分布式服务追踪监控服务性能
参考资料 https://zipkin.io/ https://github.com/openzipkin/zipkin/ https://github.com/openzipkin/zipkin4n ...
- Mysql之binlog日志说明及利用binlog日志恢复数据操作记录
众所周知,binlog日志对于mysql数据库来说是十分重要的.在数据丢失的紧急情况下,我们往往会想到用binlog日志功能进行数据恢复(定时全备份+binlog日志恢复增量数据部分),化险为夷! 一 ...
- 【转】Mysql之binlog日志说明及利用binlog日志恢复数据操作记录
众所周知,binlog日志对于mysql数据库来说是十分重要的.在数据丢失的紧急情况下,我们往往会想到用binlog日志功能进行数据恢复(定时全备份+binlog日志恢复增量数据部分),化险为夷! 废 ...
- NTP系统时间同步-操作记录
在初始化一台linux服务器后,发现这台服务器的时间不对[root@dev ~]# date2016年 10月 11日 星期二 07:04:34 CST Linux时钟分为系统时钟 (System C ...
随机推荐
- 带你走进EJB--将EJB发布为Webservice(4)
接下来的我们将会自定义一个对象,然后看看EJB是如何对复杂的参数发布成WebService的. 代码如下:在第一个版本的基础之上加上增加用户的方法,参数为User. package com.tgb.e ...
- AndroidStudio不自己主动加入新创建的文件到VCS
从远程仓库下载了一份源代码,版本号控制是用的SVN.但发现了一个问题.改动和删除文件时,版本号管理都有记录. 可是假设我新建一个文件时.却发现没有自己主动关联到VCS,也不能手动加入到VCS中,这样我 ...
- Array相关的属性和方法
这里只是做了相关的列举,具体的使用方法,请参考网址. Array 对象属性 constructor 返回对创建此对象的数组函数的引用. var test=new Array(); if (test.c ...
- Python——UnicodeWarning: Unicode equal comparison failed to convert both arguments to Unicode - interpreting them as being unequal
当字符串比较中有中文时,需要在中文字符串前加 u 转为unicode编码才可以正常比较. str == u"中文"
- HTML拾遗
一:标签 1:强调 <strong>加醋.<em>斜体 2:单独样式 <span>如果不加样式,那它包围的文字就是普通文字,可以在span中增加样式,就所包围的内容 ...
- cocos2d-js 入门 (主要是HTML5)
cocos2d-js是cocos2d-x的JavaScript版本,真正跨全平台的游戏引擎,采用原生JavaScript语言,可发布到包括Web平台,iOS,Android,Windows Phone ...
- Flash:彻底理解crossdomain.xml、跨swf调用。
安全域.crossdomain.xml,到处都有各种各种零碎的基础解释,所以这里不再复述这些概念. 本文目的是整理一下各种跨域加载的情况.什么时候会加载crossdomain,什么时候不加载. 1 ...
- org.apache.commons.lang.exception包的ExceptionUtils工具类获取getFullStackTrace
/* * Licensed to the Apache Software Foundation (ASF) under one or more * contributor license agreem ...
- 体验cygwin纪实
在windows快速体验linux,借助Cygwin很不错的体验(占用空间小),win10应用商店目前集成ubuntu.fedora...系统... 00.安装源,直接下载的是init(仅仅是下载器) ...
- 给X240换上了三键触摸板
X240自带的触摸板非常不好用, 对于我这样的指点杆重度用户, 每次要按下整块板真的是太费力了, 而且在夜里声音很吵. 在淘宝上买了三键的X250的触摸板换上了. 这是购买的触摸板的型号 换的时候, ...