正则和xpath在网页中匹配字段的效率比较
1. 测试页面是 https://www.hao123.com/,这个是百度的导航
2. 为了避免网络请求带来的差异,我们把网页下载下来,命名为html,不粘贴其代码。
3.测试办法:
我们在页面中找到 百度新闻 关键字的链接,为了能更好的对比,使程序运行10000次,比较时间差异:
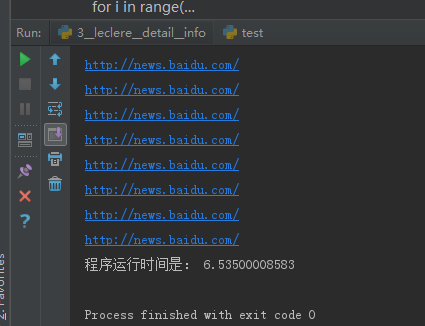
1.正则编码及其时间
start_time = time.time()
for i in range(0,10000):
baidu_news = re.findall('腾讯新闻</a></span><span><a class="sitelink mainlink singglelink" cls="xw,n" alog-custom="ind:xw,sal:0,atd:" href="(.*?)">百度新闻</a>',html)[0]
print baidu_news end_time = time.time()
print "程序运行时间是:",end_time - start_time
运行时间:6.5 秒钟
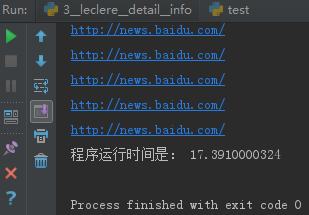
2.xpath 编码及其时间
start_time = time.time()
selector = etree.HTML(html) for i in range(,):
content=selector.xpath('//*[@id="coolsite-top"]/div[4]/span[3]/a/@href')[]
print content end_time = time.time()
print "程序运行时间是:",end_time - start_time
运行时间:17.39 秒钟
总结:其中 selector = etree.HTML(html) 将源码转化为能被XPath匹配的格式,这个过程失比较耗时的。
结论:正则效率优于xpath
如有异议,请联系作者,谢谢
正则和xpath在网页中匹配字段的效率比较的更多相关文章
- 使用Xpath从网页中获取数据
/// <summary> /// 从官方网站中抓取产品信息存放在本地数据库中 /// </summary> /// <returns></returns&g ...
- oracle 正则查询json返回报文中某个字段的值
接口返回报文为json 格式,如下: {"body":{"businessinfo":{"c1rate":"25.00" ...
- python3 利用正则获取网页中的想保存下来的内容
需要获取某个网页中表格部分中某个产品的成份 分析在html中成份的元素代码 <a href="/composition/4c3060178d1184935a48c4e51be4f63f ...
- (转载)MySQL LIKE 用法:搜索匹配字段中的指定内容
(转载)http://www.5idev.com/p-php_mysql_like.shtml MySQL LIKE 语法 LIKE 运算符用于 WHERE 表达式中,以搜索匹配字段中的指定内容,语法 ...
- js正则实现从一段复杂html代码字符串中匹配并处理特定信息
js正则实现从一段复杂html代码字符串中匹配并处理特定信息 问题: 现在要从一个复杂的html代码字符串(包含各种html标签,数字.中文等信息)中找到某一段特别的信息(被一对“|”包裹着),并对他 ...
- 小程序开发-使用xpath解析网页html中的数据
最新有个微信小程序的开发需求,需要从网页中提取一些元素信息,获取有效数据 1. 了解到微信小程序里面不能直接操作dom元素,所以我们需要使用一些其他的npm包 2. 经过查到各方面的文档,最新决定用x ...
- mybitis中对象字段与表中字段名称不匹配(复制)
开发中,实体类中的属性名和对应的表中的字段名不一定都是完全相同的,这样可能会导致用实体类接收返回的结果时导致查询到的结果无法映射到实体类的属性中,那么该如何解决这种字段名和实体类属性名不相同的冲突呢? ...
- python学习笔记——爬虫中提取网页中的信息
1 数据类型 网页中的数据类型可分为结构化数据.半结构化数据.非结构化数据三种 1.1 结构化数据 常见的是MySQL,表现为二维形式的数据 1.2 半结构化数据 是结构化数据的一种形式,并不符合关系 ...
- 一个简单java爬虫爬取网页中邮箱并保存
此代码为一十分简单网络爬虫,仅供娱乐之用. java代码如下: package tool; import java.io.BufferedReader; import java.io.File; im ...
随机推荐
- spring-boot 实现文件上传下载
@Controller public class FileUploadCtrl { @Value("${file.upload.dir}") private String path ...
- shell 截取变量的字符串(转)
来自:http://blog.sina.com.cn/s/blog_7c95e5850100zpch.html 假设有变量 var=http://www.linuxidc.com/test.htm 一 ...
- notepad++一键运行python
打开notepad++,找到菜单栏的run菜单. 子菜单选中run 弹出的小窗口中,输入cmd /k python "$(FULL_CURRENT_PATH)" & ...
- resultType、resultMap
resultType: 作用: 将查询结果按照sql列名pojo属性名一致性映射到pojo中. 场合: 常见一些明细记录的展示,比如用户购买商品明细,将关联查询信息全部展示在页面时,此时可直接使用re ...
- web前端开发,如何提高页面性能优化?
内容方面: 1.减少 HTTP 请求 (Make Fewer HTTP Requests) 2.减少 DOM 元素数量 (Reduce the Number of DOM Elements) 3.使得 ...
- java 截取字符串
java 截取字符串 CreationTime--2018年7月17日16点37分 Author:Marydon 1.去除最后一个字符 方式一:String 方式二:StringBuilder.S ...
- 5、redis之使用spring集成commons-pool
添加spring的依赖 <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://w ...
- 解决BeautifulSoup库运行时报错问题
解决BeautifulSoup库运行时报错问题 运行BeautifulSoup库时可能出现下面的错误,具体错误消息为:To get rid of this warning, change this: ...
- SpringBoot中mybatis配置自动转换驼峰标识没有生效
mybatis提供了一个配置: #开启驼峰命名转换 mybatis.configuration.map-underscore-to-camel-case=true 使用该配置可以让mybatis自动将 ...
- XML制作RSS源
什么是RSS源?看到这片文章的人相信都知道.自己博客首页不就是一个吗? 好吧,先来一个简单点的.直接就是死代码:详细如何使用就看RSS使用标准吧! <?xml version = "1 ...