Spark SQL利器:cacheTable/uncacheTable【转】
转自:http://www.cnblogs.com/yurunmiao/p/4936583.html










Spark SQL利器:cacheTable/uncacheTable【转】的更多相关文章
- Spark SQL利器:cacheTable/uncacheTable
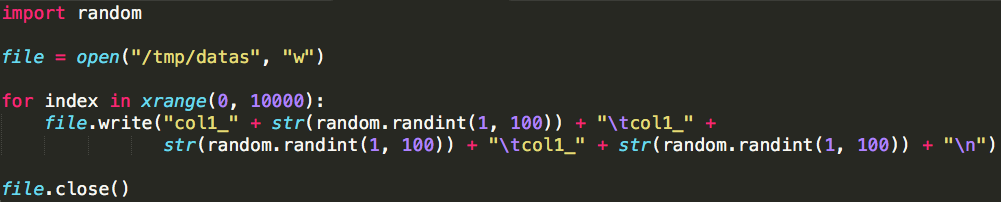
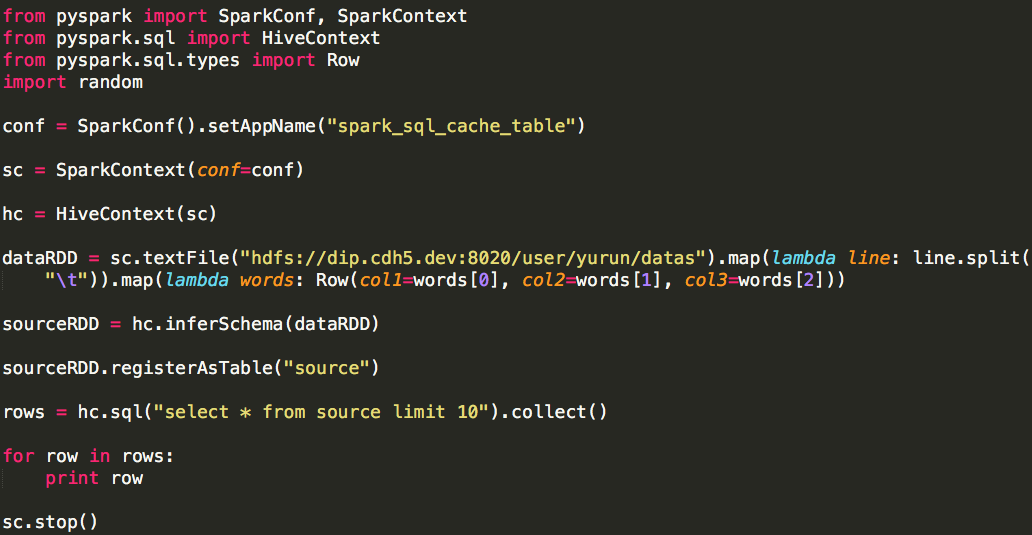
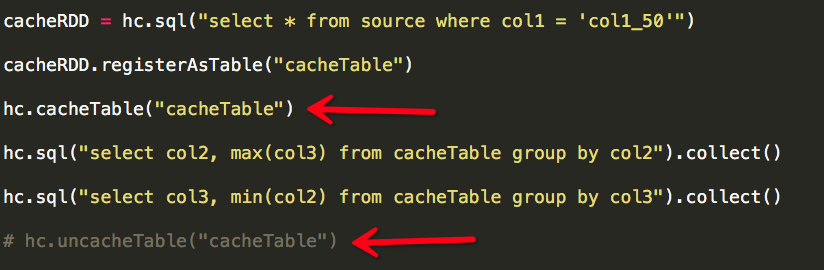
Spark相对于Hadoop MapReduce有一个很显著的特性就是“迭代计算”(作为一个MapReduce的忠实粉丝,能这样说,大家都懂了吧),这在我们的业务场景里真的是非常有用. 假设我们有 ...
- Spark 官方文档(5)——Spark SQL,DataFrames和Datasets 指南
Spark版本:1.6.2 概览 Spark SQL用于处理结构化数据,与Spark RDD API不同,它提供更多关于数据结构信息和计算任务运行信息的接口,Spark SQL内部使用这些额外的信息完 ...
- Spark SQL 官方文档-中文翻译
Spark SQL 官方文档-中文翻译 Spark版本:Spark 1.5.2 转载请注明出处:http://www.cnblogs.com/BYRans/ 1 概述(Overview) 2 Data ...
- Spark SQL 之 Performance Tuning & Distributed SQL Engine
Spark SQL 之 Performance Tuning & Distributed SQL Engine 转载请注明出处:http://www.cnblogs.com/BYRans/ 缓 ...
- spark sql cache
1.几种缓存数据的方法 例如有一张hive表叫做activity 1.CACHE TABLE //缓存全表 sqlContext.sql("CACHE TABLE activity" ...
- Spark SQL 初步
已经Spark Submit 2013哪里有介绍Spark SQL.就在很多人都介绍Catalyst查询优化框架.经过一年的发展后,.今年Spark Submit 2014在.Databricks放弃 ...
- Spark SQL笔记——技术点汇总
目录 概述 原理 组成 执行流程 性能 API 应用程序模板 通用读写方法 RDD转为DataFrame Parquet文件数据源 JSON文件数据源 Hive数据源 数据库JDBC数据源 DataF ...
- Apache Spark 2.2.0 中文文档 - Spark SQL, DataFrames and Datasets Guide | ApacheCN
Spark SQL, DataFrames and Datasets Guide Overview SQL Datasets and DataFrames 开始入门 起始点: SparkSession ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
随机推荐
- Spring中Autowired注解,Resource注解和xml default-autowire工作方式异同
前面说到了关于在xml中有提供default-autowire的配置信息,从spring 2.5开始,spring又提供了一个Autowired以及javaEE中标准的Resource注释,都好像可以 ...
- spring 2种下载方式 下载地址 download 地址
spring 在官网只提供 maven 的下载方式,把zip方式的不再提供,两种方法下载: 1.想找回以前版本的spring zip包,如果知道版本号,那么直接在google里输入 ” spring ...
- linux平台下server运维问题分析与定位
结合我工作中碰到的运维问题,总结一下Linux下server常见的运维问题以及定位方式.这里的server主要指自主开发的逻辑server,web srv因为通常采用通用的架构所以问题比较少. 逻辑s ...
- hadoop执行wordcount例子
1:下载hadoop.http://mirror.esocc.com/apache/hadoop/common/hadoop-1.2.1/hadoop-1.2.1.tar.gz 2:解压. tar - ...
- 微信支付服务器CA证书更换服务器安装der证书的方法 DigiCert的根证书
[重要]微信支付服务器证书更换通知,请开发人员验证以免影响交易 尊敬的微信支付商户&服务商: 因微信支付HTTPS服务器证书的根CA证书将于2018年8月23日到期失效,微信支付计划于2018 ...
- MySQL-InnoDB Compact 行记录格式
InnoDB存储引擎提供了compact(5.1后的默认格式)和redundant两个格式来存放行记录数据.redundant格式是为了兼容之前的版本而保留. mysql> show table ...
- 还没被玩坏的robobrowser(3)——简单的spider
背景 做一个简单的spider用来获取python selenium实战教程的一些基本信息.因为python selenium每年滚动开课,所以做这样一个爬虫随时更新最新的开课信息是很有必要的. 预备 ...
- pycharm + selenium + python 提示 Unresolved reference 'webdriver' 解决办法
尝试使用python + selenium + pycharm 做自动化测试, 命令行pip install selenium 安装了selenium.但是使用pycharm 新建一个测试项目后并新建 ...
- Mac office ppt无法正常输入文字的问题解决方案
Mac office ppt无法正常输入文字的问题解决方案 Mac下每次启动office ppt后,在输入文字时会出现输入法文本框快速闪退无法正常录入文字的情况,在PowerPoint中会出现这种 ...
- fdatool的滤波器设计
作者:桂. 时间:2017-08-15 20:28:11 链接:http://www.cnblogs.com/xingshansi/p/7367738.html 前言 本文主要记录滤波器设计的基本流 ...