Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十)ES6.2.2 Client API
scala版本2.11
java版本1.8
spark版本2.2.1
es版本6.2.2
hadoop版本2.9.0
elasticsearch节点列表:
192.168.0.120
192.168.0.121
192.168.0.122
内容导航:
1)首先,讲解使用elasticsearch client api讲解如何创建(删除、修改、查询)index,type,mapping;对数据进行增删改查。
2)然后,讲解如何使用在spark下写入elasticsearch。
3)最后,讲解如何读取kafka上的数据,然后读取kafka上数据流写入es。
使用elasticsearch client api
Client
Client是一个类,可以通过该类实现对ES集群各种操作:index/get/delete/search操作,以及对ES集群的管理任务。
Client的构造需要基于TransportClient。
TransportClient
TransportClient可以远程连接到ES集群,通过一个传输模块,但是它不真正的连接到集群,只是获取集群的一个或多个初始传输地址,在每次请求动作时,才真正连接到ES集群。
Settgings
Settings类主要是在启动Client之前,配置一些属性参数,主要配置集群名称cluster name,还有其他参数:
client.transport.sniff:是否为传输client添加嗅探功能;
client.transport.ignore_cluster_name 设为true,或略连接点的集群名称验证;
client.transport.ping_timeout 设置ping节点的时间超时时长,默认5s;
client.transport.nodes_sample_interval 设置sample/ping nodes listed间隔时间,默认5s。
初始化client的示例如下:
1)ClientTools.java(单利方式提供TransportClient对象,关于如何创建client参考《https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/transport-client.html》)
package com.dx.es; import java.net.InetAddress;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.TransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient; public class ClientTools {
private static ClientTools instance=null;
private TransportClient client=null; private ClientTools(){
this.client=null;
init();
} public static synchronized ClientTools getInstance(){
if(instance==null){
instance=new ClientTools();
}
return instance;
} public TransportClient get(){
return client;
} public void close(){
if(null != client){
try {
client.close();
} catch (Exception e) {
e.printStackTrace();
}
}
} private void init() {
if(null != this.client){
return;
} try {
Settings settings = Settings.builder()
.put("cluster.name",Config.getInstance().get("cluster.name"))
.put("client.transport.sniff", Boolean.valueOf(Config.getInstance().get("client.transport.sniff")))
.build(); @SuppressWarnings("unchecked")
PreBuiltTransportClient preBuiltTransportClient = new PreBuiltTransportClient(settings); this.client = preBuiltTransportClient;
this.client.addTransportAddress(new TransportAddress(InetAddress.getByName(Config.getInstance().get("host1")), 9300));
this.client.addTransportAddress(new TransportAddress(InetAddress.getByName(Config.getInstance().get("host2")), 9300)); } catch (Exception e) {
e.printStackTrace();
}
}
}
2)(es配置信息管理)
package com.dx.es; import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.InputStream;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
import java.util.Properties; public class Config {
private static Config instance=null;
private Map<String, String> confItems=null; private Config(){
this.confItems=new HashMap<String, String>(); init();
} public static synchronized Config getInstance(){
if(instance==null){
instance=new Config();
}
return instance;
} public String get(String key){
if(!this.confItems.containsKey(key))
return null; return this.confItems.get(key);
} private void init() {
Properties prop = new Properties();
try{
// 读取属性文件conf.properties
InputStream in = new BufferedInputStream (new FileInputStream("E:\\spark_hadoop_cdh\\workspace\\ES_Client_API\\src\\main\\resources\\conf.properties"));
// 加载属性列表
prop.load(in);
Iterator<String> it=prop.stringPropertyNames().iterator();
while(it.hasNext()){
String key=it.next();
System.out.println(key+":"+prop.getProperty(key));
this.confItems.put(key, prop.getProperty(key));
}
in.close();
}
catch(Exception e){
System.out.println(e);
}
}
}
conf.properties配置内容为:
cluster.name=es-application
client.transport.sniff=true
es_ip=192.168.0.120
host1=slave1
host2=slave2
Index API
参考:https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/java-docs-index.html#java-docs-index
package com.dx.es; import java.io.IOException;
import java.util.Date; import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.rest.RestStatus; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get(); XContentBuilder jsonBuilder=null;
try {
jsonBuilder = XContentFactory.jsonBuilder()
.startObject()
.field("user", "kimchy")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject();
} catch (IOException e) {
e.printStackTrace();
} IndexResponse response = client.prepareIndex("twitter","tweet","1")
.setSource(jsonBuilder)
.get(); // Index name
String _index = response.getIndex();
// Type name
String _type = response.getType();
// Document ID (generated or not)
String _id = response.getId();
// Version (if it's the first time you index this document, you will get: 1)
long _version = response.getVersion();
// status has stored current instance statement.
RestStatus status = response.status();
if(status==RestStatus.CREATED){
System.out.println("success !!!");
} client.close();
}
}
执行后效果,创建了index.type,和一条记录。
Get API
参考《https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/java-docs-get.html》
package com.dx.es; import java.util.Map; import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.client.transport.TransportClient; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get(); GetResponse response = client.prepareGet("twitter", "tweet", "1").get(); Map<String, Object> fields = response.getSource();
for(Map.Entry<String, Object> kvEntry : fields.entrySet()){
System.out.println(kvEntry.getKey()+":"+kvEntry.getValue());
} client.close();
}
}
打印结果:
postDate:--05T06::.334Z
message:trying out Elasticsearch
user:kimchy
Delete API
参考《https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/java-docs-delete.html》
package com.dx.es; import org.elasticsearch.action.delete.DeleteResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.rest.RestStatus; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get(); DeleteResponse response = client.prepareDelete("twitter", "tweet", "1").get(); if(RestStatus.OK== response.status()){
System.out.println("Success ...");
} client.close();
}
}
通过es-head插件查看index.type依然存储只是数据为空。
Delete By Query API
参考:《https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/java-docs-delete-by-query.html#java-docs-delete-by-query》
package com.dx.es; import java.io.IOException;
import java.util.Date; import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.DeleteByQueryAction; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get();
create(client); BulkByScrollResponse response = DeleteByQueryAction.INSTANCE.newRequestBuilder(client)
.filter(QueryBuilders.matchQuery("gender", "male"))
.source("twitter")
.get();
long deleted = response.getDeleted();
System.out.println(deleted); client.close();
} private static void create(TransportClient client) {
XContentBuilder jsonBuilder = null;
for (int i = 1; i <= 10; i++) {
try {
jsonBuilder = XContentFactory.jsonBuilder()
.startObject()
.field("user", "kimchy"+i)
.field("gender", ((i%2==0) ? "male" : "famale"))
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject();
} catch (IOException e) {
e.printStackTrace();
} IndexResponse response = client.prepareIndex("twitter", "tweet", String.valueOf(i)).setSource(jsonBuilder).get();
}
}
}
新增之后查看出记录:
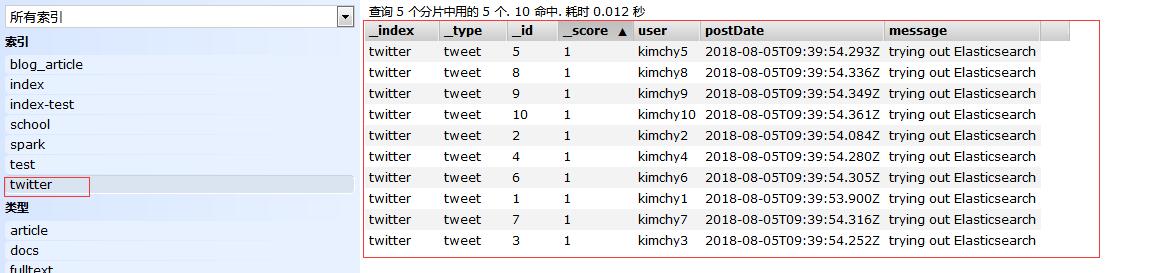
删除之后,数据结果:

如果执行一个耗时删除处理,可以采用异步方式删除,使用execute方法替换get,同事提供监听功能。
package com.dx.es; import java.io.IOException;
import java.util.Date; import org.elasticsearch.action.ActionListener;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.xcontent.XContentBuilder;
import org.elasticsearch.common.xcontent.XContentFactory;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.index.reindex.BulkByScrollResponse;
import org.elasticsearch.index.reindex.DeleteByQueryAction; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get();
// create(client); DeleteByQueryAction.INSTANCE.newRequestBuilder(client)
.filter(QueryBuilders.matchQuery("gender", "male"))
.source("twitter")
.execute(new ActionListener<BulkByScrollResponse>() {
public void onResponse(BulkByScrollResponse response) {
long deleted = response.getDeleted();
System.out.println(deleted);
} public void onFailure(Exception e) {
// Handle the exception
e.printStackTrace();
}
}); try {
Thread.sleep(60000);
} catch (InterruptedException e1) {
e1.printStackTrace();
} client.close();
} private static void create(TransportClient client) {
XContentBuilder jsonBuilder = null;
for (int i = 1; i <= 10; i++) {
try {
jsonBuilder = XContentFactory.jsonBuilder()
.startObject()
.field("user", "kimchy"+i)
.field("gender", ((i%2==0) ? "male" : "famale"))
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject();
} catch (IOException e) {
e.printStackTrace();
} IndexResponse response = client.prepareIndex("twitter", "tweet", String.valueOf(i)).setSource(jsonBuilder).get();
}
}
}
Update API
创建UpdateRequest把它发送给client:
package com.dx.es; import java.io.IOException;
import java.util.concurrent.ExecutionException; import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.xcontent.XContentFactory; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get(); UpdateRequest updateRequest = new UpdateRequest();
updateRequest.index("twitter");
updateRequest.type("tweet");
updateRequest.id("1");
try {
updateRequest.doc(XContentFactory.jsonBuilder()
.startObject()
.field("gender", "male")
.endObject());
} catch (IOException e) {
e.printStackTrace();
} try {
client.update(updateRequest).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} client.close();
}
}
或者使用prepareUpdate()方法:
方式一:
package com.dx.es; import java.util.HashMap;
import java.util.Map; import org.elasticsearch.action.update.UpdateRequestBuilder;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.script.Script; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get(); UpdateRequestBuilder updateRequestBuilder = client.prepareUpdate("twitter", "tweet", "1");
Map<String, Object> params = new HashMap<String, Object>();
updateRequestBuilder.setScript(new Script(Script.DEFAULT_SCRIPT_TYPE, Script.DEFAULT_SCRIPT_LANG, "ctx._source.gender = \"female\"",params));
updateRequestBuilder.get(); client.close();
}
}
方式二:
package com.dx.es; import java.io.IOException; import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.xcontent.XContentFactory; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get(); try {
client.prepareUpdate("twitter", "tweet", "1")
.setDoc(XContentFactory.jsonBuilder().startObject().field("gender", "male").endObject()).get();
} catch (IOException e) {
e.printStackTrace();
} client.close();
}
}
Update by script
package com.dx.es; import java.util.concurrent.ExecutionException; import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.script.Script; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get(); UpdateRequest updateRequest = new UpdateRequest("twitter", "tweet", "1")
.script(new Script("ctx._source.gender = \"female\""));
try {
client.update(updateRequest).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} client.close();
}
}
Update by merging documents
package com.dx.es; import java.io.IOException;
import java.util.concurrent.ExecutionException; import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.xcontent.XContentFactory; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get(); UpdateRequest updateRequest = null;
try {
updateRequest = new UpdateRequest("twitter", "tweet", "1")
.doc(
XContentFactory.jsonBuilder().startObject()
.field("gender", "male")
.endObject()
);
} catch (IOException e) {
e.printStackTrace();
} try {
client.update(updateRequest).get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} client.close();
}
}
Upsert
package com.dx.es; import java.io.IOException;
import java.util.concurrent.ExecutionException; import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.update.UpdateRequest;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.xcontent.XContentFactory; public class ClientAPITest {
public static void main(String[] args) throws IOException, InterruptedException, ExecutionException {
TransportClient client = ClientTools.getInstance().get(); IndexRequest indexRequest = new IndexRequest("twitter", "tweet", "11")
.source(XContentFactory.jsonBuilder()
.startObject()
.field("user", "Joe Smith")
.field("gender", "male")
.endObject()
); UpdateRequest updateRequest = new UpdateRequest("twitter", "tweet", "11")
.doc(XContentFactory.jsonBuilder()
.startObject()
.field("user", "Joe Dalton")
.field("gender", "male")
.endObject()
)
.upsert(indexRequest); client.update(updateRequest).get(); client.close();
}
}
备注:如果对应的id数据已经存储在值则执行update,否则执行index。
Multi Get API
package com.dx.es; import java.io.IOException;
import java.util.concurrent.ExecutionException; import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.get.MultiGetItemResponse;
import org.elasticsearch.action.get.MultiGetResponse;
import org.elasticsearch.client.transport.TransportClient; public class ClientAPITest {
public static void main(String[] args) {
TransportClient client = ClientTools.getInstance().get(); MultiGetResponse multiGetItemResponses = client.prepareMultiGet()
.add("twitter", "tweet", "1")
.add("twitter", "tweet", "2", "3", "4")
.add("twitter", "tweet", "11")
.get(); for (MultiGetItemResponse itemResponse : multiGetItemResponses) {
GetResponse response = itemResponse.getResponse();
if (response.isExists()) {
String json = response.getSourceAsString();
System.out.println(json);
}
} client.close();
}
}
返回打印结果:
{"user":"kimchy1","gender":"male","postDate":"2018-08-05T10:04:26.631Z","message":"trying out Elasticsearch"}
{"user":"kimchy2","gender":"male","postDate":"2018-08-05T10:04:26.673Z","message":"trying out Elasticsearch"}
{"user":"kimchy3","gender":"famale","postDate":"2018-08-05T10:04:26.720Z","message":"trying out Elasticsearch"}
{"user":"kimchy4","gender":"male","postDate":"2018-08-05T10:04:26.730Z","message":"trying out Elasticsearch"}
{"user":"Joe Dalton","gender":"male"}
Bulk API
package com.dx.es; import java.io.IOException;
import java.util.Date; import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.get.MultiGetItemResponse;
import org.elasticsearch.action.get.MultiGetResponse;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.xcontent.XContentFactory; public class ClientAPITest {
public static void main(String[] args) throws IOException {
TransportClient client = ClientTools.getInstance().get();
BulkRequestBuilder bulkRequest = client.prepareBulk(); // either use client#prepare, or use Requests# to directly build index/delete requests
bulkRequest.add(client.prepareIndex("twitter", "tweet", "12")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("user", "auth")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
)
); bulkRequest.add(client.prepareIndex("twitter", "tweet", "13")
.setSource(XContentFactory.jsonBuilder()
.startObject()
.field("user", "judy")
.field("postDate", new Date())
.field("message", "another post")
.endObject()
)
); BulkResponse bulkResponse = bulkRequest.get();
if (bulkResponse.hasFailures()) {
// process failures by iterating through each bulk response item
System.out.println( bulkResponse.buildFailureMessage());
} MultiGetResponse multiGetItemResponses = client.prepareMultiGet()
.add("twitter", "tweet", "12", "13")
.get(); for (MultiGetItemResponse itemResponse : multiGetItemResponses) {
GetResponse response = itemResponse.getResponse();
if (response.isExists()) {
String json = response.getSourceAsString();
System.out.println(json);
}
} client.close();
}
}
Using Bulk Processor
参考:《https://www.elastic.co/guide/en/elasticsearch/client/java-api/6.2/java-docs-bulk-processor.html#java-docs-bulk-processor》
package com.dx.es; import java.io.IOException;
import java.util.Date; import org.elasticsearch.action.bulk.BackoffPolicy;
import org.elasticsearch.action.bulk.BulkProcessor;
import org.elasticsearch.action.bulk.BulkRequest;
import org.elasticsearch.action.bulk.BulkResponse;
import org.elasticsearch.action.delete.DeleteRequest;
import org.elasticsearch.action.get.GetResponse;
import org.elasticsearch.action.get.MultiGetItemResponse;
import org.elasticsearch.action.get.MultiGetResponse;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.unit.ByteSizeUnit;
import org.elasticsearch.common.unit.ByteSizeValue;
import org.elasticsearch.common.unit.TimeValue;
import org.elasticsearch.common.xcontent.XContentFactory; public class ClientAPITest {
public static void main(String[] args) throws IOException {
TransportClient client = ClientTools.getInstance().get(); BulkProcessor bulkProcessor = BulkProcessor.builder(
client,
new BulkProcessor.Listener() {
public void beforeBulk(long executionId, BulkRequest request) { } public void afterBulk(long executionId, BulkRequest request, BulkResponse response) { } public void afterBulk(long executionId, BulkRequest request, Throwable failure) { }
})
.setBulkActions(10000)
.setBulkSize(new ByteSizeValue(5, ByteSizeUnit.MB))
.setFlushInterval(TimeValue.timeValueSeconds(5))
.setConcurrentRequests(1)
.setBackoffPolicy(BackoffPolicy.exponentialBackoff(TimeValue.timeValueMillis(100), 3))
.build(); bulkProcessor.add(new DeleteRequest("twitter", "tweet", "1"));
bulkProcessor.add(new DeleteRequest("twitter", "tweet", "2")); bulkProcessor.add(new IndexRequest("twitter", "tweet", "12")
.source(XContentFactory.jsonBuilder()
.startObject()
.field("user", "auth")
.field("postDate", new Date())
.field("message", "trying out Elasticsearch")
.endObject()
)
);
bulkProcessor.add(new IndexRequest("twitter", "tweet", "13")
.source(XContentFactory.jsonBuilder()
.startObject()
.field("user", "judy")
.field("postDate", new Date())
.field("message", "another post")
.endObject()
)
); // Flush any remaining requests
bulkProcessor.flush();
// Or close the bulkProcessor if you don't need it anymore
bulkProcessor.close(); // Refresh your indices
client.admin().indices().prepareRefresh().get(); MultiGetResponse multiGetItemResponses = client.prepareMultiGet()
.add("twitter", "tweet", "1", "2", "12", "13")
.get(); for (MultiGetItemResponse itemResponse : multiGetItemResponses) {
GetResponse response = itemResponse.getResponse();
if (response.isExists()) {
String json = response.getSourceAsString();
System.out.println(json);
}
} client.close();
}
}
什么情况下重建索引?《Elasticsearch索引管理-reindex重建索引》------字段类型发生变化时需要重建索引。
使用在spark下写入elasticsearch
如果要使用spark相关类(例如:SparkConf)需要引入spark-core,要把RDD相关数据写入ES需要引入elasticsearch-spark-20_2.11
maven引入如下:
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.elasticsearch/elasticsearch-spark-20 -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-spark-20_2.11</artifactId>
<version>6.2.2</version>
</dependency>
代码实现:
package com.dx.es; import java.util.Map; import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.elasticsearch.spark.rdd.api.java.JavaEsSpark; import com.google.common.collect.ImmutableList;
import com.google.common.collect.ImmutableMap; public class JavaEsSpark_Test {
public static void main(String[] args) throws InterruptedException {
SparkConf conf = new SparkConf();
conf.setMaster("local[*]"); // 指定运行模式模式
conf.setAppName("spark to es");// 设置任务名
conf.set("es.index.auto.create", "true");// 开启自动创建索引
conf.set("es.nodes", "192.168.0.120,192.168.0.121,192.168.0.122");// es的节点,多个用逗号分隔
conf.set("es.port", "9200");// 端口号
JavaSparkContext jsc = new JavaSparkContext(conf); Map<String, ?> numbers = ImmutableMap.of("one", 1, "two", 2);
Map<String, ?> airports = ImmutableMap.of("OTP", "Otopeni", "SFO", "San Fran"); JavaRDD<Map<String, ?>> javaRDD = jsc.parallelize(ImmutableList.of(numbers, airports));
JavaEsSpark.saveToEs(javaRDD, "spark/docs"); jsc.close();
}
}
执行之后通过head工具查看是否插入成功。
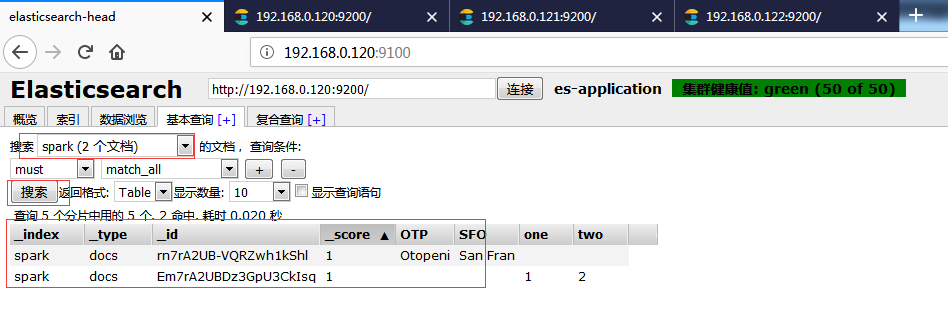
参考:
Es Client Api
https://www.sojson.com/blog/87.html
https://www.sojson.com/blog/88.html
https://www.elastic.co/guide/en/elasticsearch/client/java-api/current/transport-client.html
ES索引存储原理:
https://blog.csdn.net/cyony/article/details/65437708?locationNum=9&fps=1
写入ES示例:
http://qindongliang.iteye.com/blog/2372853
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十)ES6.2.2 Client API的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十六)Structured Streaming中ForeachSink的用法
Structured Streaming默认支持的sink类型有File sink,Foreach sink,Console sink,Memory sink. ForeachWriter实现: 以写 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十四)定义一个avro schema使用comsumer发送avro字符流,producer接受avro字符流并解析
参考<在Kafka中使用Avro编码消息:Consumer篇>.<在Kafka中使用Avro编码消息:Producter篇> 在了解如何avro发送到kafka,再从kafka ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十五)Spark编写UDF、UDAF、Agg函数
Spark Sql提供了丰富的内置函数让开发者来使用,但实际开发业务场景可能很复杂,内置函数不能够满足业务需求,因此spark sql提供了可扩展的内置函数. UDF:是普通函数,输入一个或多个参数, ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十八)ES6.2.2 增删改查基本操作
#文档元数据 一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息. 三个必须的元数据元素如下:## _index 文档在哪存放 ## _type 文档表示的对象类别 ## ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- Redis如何处理客户端连接
本文主要介绍了 Redis 处理客户端连接的一些内部实现机制,包括连接处理.超时.缓冲区等一系列内容. 注:本文所述内容基于 Redis2.6 及以上版本. 连接的建立 Redis 通过监听一个 TC ...
- spring cloud 学习(8) - sleuth & zipkin 调用链跟踪
业务复杂的微服务架构中,往往服务之间的调用关系比较难梳理,一次http请求中,可能涉及到多个服务的调用(eg: service A -> service B -> service C... ...
- SGU 200. Cracking RSA (高斯消元求自由变元个数)
题目链接:http://acm.sgu.ru/problem.php?contest=0&problem=200 200. Cracking RSA time limit per test: ...
- STM32F4 Timer Internal Trigger Connection
The Timers can be cascaded to make more complex timing relationships, or longer periods. Internally ...
- Nginx配置文件nginx.conf具体解释
#定义Nginx执行的用户和用户组user www www; #nginx进程数.建议设置为等于CPU总核心数. worker_processes 8; #全局错误日志定义类型,[ debug | i ...
- Revit API过滤元素类别(FamilySymbol与FamilyInstance)
仅OfCategory()过滤的元素包含系统FamilySymbolOfClass(typeof(FamilyInstance))过滤出来文档中族实例. ; ; ; ...
- vuex 基础:教程和说明
作者注:[2016.11 更新]这篇文章是基于一个非常旧的 vuex api 版本而写的,代码来自于2015年12月.但是,它仍能针对下面几个问题深入探讨: vuex 为什么重要 vuex 如何工作 ...
- ASP.NET Web API中展示实体Link相关的方面
有时候,向服务端请求一个实体,我们希望返回如下的格式: links: [ href: http://localhost:8901/api/user/diaries/2013-08-17, ...
- ASP.NET Web API实践系列02,在MVC4下的一个实例, 包含EF Code First,依赖注入, Bootstrap等
本篇体验在MVC4下,实现一个对Book信息的管理,包括增删查等,用到了EF Code First, 使用Unity进行依赖注入,前端使用Bootstrap美化.先上最终效果: →创建一个MVC4项目 ...
- 委托、Lambda表达式、事件系列04,委托链是怎样形成的, 多播委托, 调用委托链方法,委托链异常处理
委托是多播委托,我们可以通过"+="把多个方法赋给委托变量,这样就形成了一个委托链.本篇的话题包括:委托链是怎样形成的,如何调用委托链方法,以及委托链异常处理. □ 调用返回类型为 ...