K Nearest Neighbor 算法
文章出处:http://coolshell.cn/articles/8052.html
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法。其中的K表示最接近自己的K个数据样本。KNN算法和K-Means算法不同的是,K-Means算法用来聚类,用来判断哪些东西是一个比较相近的类型,而KNN算法是用来做归类的,也就是说,有一个样本空间里的样本分成很几个类型,然后,给定一个待分类的数据,通过计算接近自己最近的K个样本来判断这个待分类数据属于哪个分类。你可以简单的理解为由那离自己最近的K个点来投票决定待分类数据归为哪一类。
Wikipedia上的KNN词条中有一个比较经典的图如下:
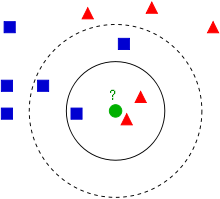
从上图中我们可以看到,图中的有两个类型的样本数据,一类是蓝色的正方形,另一类是红色的三角形。而那个绿色的圆形是我们待分类的数据。
- 如果K=3,那么离绿色点最近的有2个红色三角形和1个蓝色的正方形,这3个点投票,于是绿色的这个待分类点属于红色的三角形。
- 如果K=5,那么离绿色点最近的有2个红色三角形和3个蓝色的正方形,这5个点投票,于是绿色的这个待分类点属于蓝色的正方形。
我们可以看到,机器学习的本质——是基于一种数据统计的方法!那么,这个算法有什么用呢?我们来看几个示例。
产品质量判断
假设我们需要判断纸巾的品质好坏,纸巾的品质好坏可以抽像出两个向量,一个是“酸腐蚀的时间”,一个是“能承受的压强”。如果我们的样本空间如下:(所谓样本空间,又叫Training Data,也就是用于机器学习的数据)
|
向量X1 耐酸时间(秒) |
向量X2 圧强(公斤/平方米) |
品质Y |
|
7 |
7 |
坏 |
|
7 |
4 |
坏 |
|
3 |
4 |
好 |
|
1 |
4 |
好 |
那么,如果 X1 = 3 和 X2 = 7, 这个毛巾的品质是什么呢?这里就可以用到KNN算法来判断了。
假设K=3,K应该是一个奇数,这样可以保证不会有平票,下面是我们计算(3,7)到所有点的距离。(关于那些距离公式,可以参看K-Means算法中的距离公式)
|
向量X1 耐酸时间(秒) |
向量X2 圧强(公斤/平方米) |
计算到 (3, 7)的距离 |
向量Y |
|
7 |
7 |
|
坏 |
|
7 |
4 |
|
N/A |
|
3 |
4 |
|
好 |
|
1 |
4 |
|
好 |
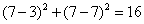
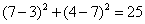
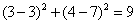
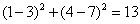
所以,最后的投票,好的有2票,坏的有1票,最终需要测试的(3,7)是合格品。(当然,你还可以使用权重——可以把距离值做为权重,越近的权重越大,这样可能会更准确一些)
注:示例来自这里,K-NearestNeighbors Excel表格下载
预测
假设我们有下面一组数据,假设X是流逝的秒数,Y值是随时间变换的一个数值(你可以想像是股票值)
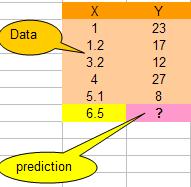
那么,当时间是6.5秒的时候,Y值会是多少呢?我们可以用KNN算法来预测之。
这里,让我们假设K=2,于是我们可以计算所有X点到6.5的距离,如:X=5.1,距离是 | 6.5 – 5.1 | = 1.4, X = 1.2 那么距离是 | 6.5 – 1.2 | = 5.3 。于是我们得到下面的表:
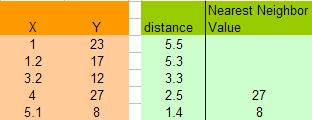
注意,上图中因为K=2,所以得到X=4 和 X =5.1的点最近,得到的Y的值分别为27和8,在这种情况下,我们可以简单的使用平均值来计算: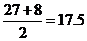
于是,最终预测的数值为:17.5
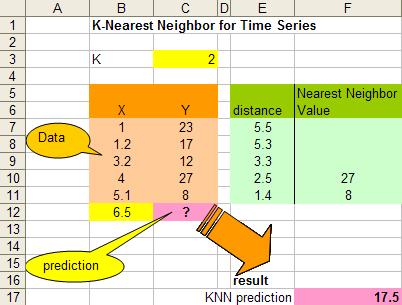
注:示例来自这里,KNN_TimeSeries Excel表格下载
插值,平滑曲线
KNN算法还可以用来做平滑曲线用,这个用法比较另类。假如我们的样本数据如下(和上面的一样):

要平滑这些点,我们需要在其中插入一些值,比如我们用步长为0.1开始插值,从0到6开始,计算到所有X点的距离(绝对值),下图给出了从0到0.5 的数据:
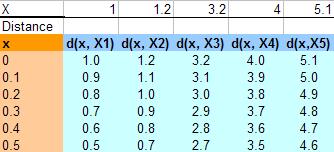
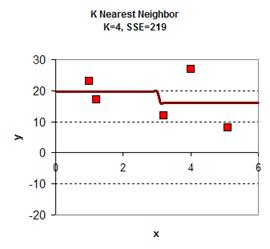
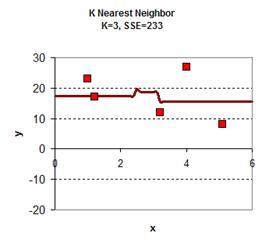
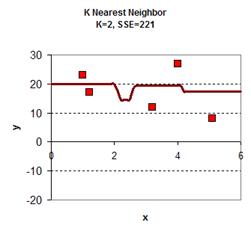
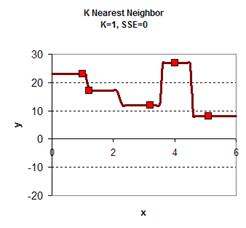
下图给出了从2.5到3.5插入的11个值,然后计算他们到各个X的距离,假值K=4,那么我们就用最近4个X的Y值,然后求平均值,得到下面的表:
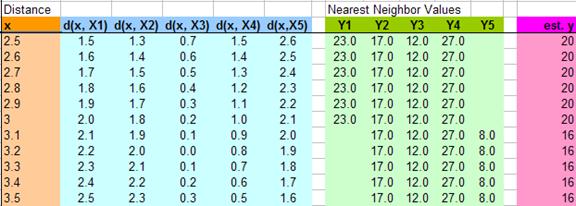
于是可以从0.0, 0.1, 0.2, 0.3 …. 1.1, 1.2, 1.3…..3.1, 3.2…..5.8, 5.9, 6.0 一个大表,跟据K的取值不同,得到下面的图:
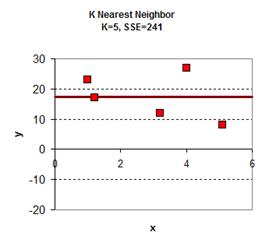 |
 |
 |
 |
 |
注:示例来自这里,KNN_Smoothing Excel表格下载
后记
最后,我想再多说两个事,
1) 一个是机器学习,算法基本上都比较简单,最难的是数学建模,把那些业务中的特性抽象成向量的过程,另一个是选取适合模型的数据样本。这两个事都不是简单的事。算法反而是比较简单的事。
2)对于KNN算法中找到离自己最近的K个点,是一个很经典的算法面试题,需要使用到的数据结构是“最大堆——Max Heap”,一种二叉树。你可以看看相关的算法。
K Nearest Neighbor 算法的更多相关文章
- K NEAREST NEIGHBOR 算法(knn)
K Nearest Neighbor算法又叫KNN算法,这个算法是机器学习里面一个比较经典的算法, 总体来说KNN算法是相对比较容易理解的算法.其中的K表示最接近自己的K个数据样本.KNN算法和K-M ...
- K nearest neighbor cs229
vectorized code 带来的好处. import numpy as np from sklearn.datasets import fetch_mldata import time impo ...
- K-Means和K Nearest Neighbor
来自酷壳: http://coolshell.cn/articles/7779.html http://coolshell.cn/articles/8052.html
- [机器学习系列] k-近邻算法(K–nearest neighbors)
C++ with Machine Learning -K–nearest neighbors 我本想写C++与人工智能,但是转念一想,人工智能范围太大了,我根本介绍不完也没能力介绍完,所以还是取了他的 ...
- 【cs231n】图像分类-Nearest Neighbor Classifier(最近邻分类器)【python3实现】
[学习自CS231n课程] 转载请注明出处:http://www.cnblogs.com/GraceSkyer/p/8735908.html 图像分类: 一张图像的表示:长度.宽度.通道(3个颜色通道 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- K近邻分类算法实现 in Python
K近邻(KNN):分类算法 * KNN是non-parametric分类器(不做分布形式的假设,直接从数据估计概率密度),是memory-based learning. * KNN不适用于高维数据(c ...
- Nearest neighbor graph | 近邻图
最近在开发一套自己的单细胞分析方法,所以copy paste事业有所停顿. 实例: R eNetIt v0.1-1 data(ralu.site) # Saturated spatial graph ...
- K邻近分类算法
# -*- coding: utf-8 -*- """ Created on Thu Jun 28 17:16:19 2018 @author: zhen "& ...
随机推荐
- 浮动、清除浮动、BFC
一. 浮动 1. 浮动的定义 使元素脱离文档流,按照向左或向右的方向移动,直到它的外边缘碰到包含它的框或另一个浮动框为止. 脱离文档流就是在页面中不占位置了. 左浮动右浮动此处就不再赘述了. 2. 看 ...
- 基于Redis实现一个安全可靠的消息队列
http://doc.redisfans.com/list/rpoplpush.html
- Ubuntu sudo apt-get 安装下载更新软件包命令详解
sudo apt-get install package 安装软件包sudo apt-get install package - - reinstall 重新安装 ...
- linux ntp 时间同步
一.时间同步服务器可以将数据库服务器作为同步服务器ntp.conf 保持不变 //启动服务service ntpd start //设置ntpd服务自启动chkconfig ntpd on//检查ch ...
- ArrayList源码中的两个值得注意的问题
1.“拖泥带水”的删除 测试代码: package com.demo; import java.util.ArrayList; public class TestArrayList { public ...
- 读《Top benefits of continuous integration》有感
看到一片文章<Top benefits of continuous integration>,这张图画的很棒.将整个CI流程各阶段,列举出来了. 作者在文章里面介绍了CI和TDD,以及采用 ...
- SkylineGlobe 从v6.1到v6.5 二次开发方面的变化参考
2.1关于 TerraExplorer v6.5 API 除了一些新的功能,API v6.5不同于API v6.1的最大改进是其对象ID系统.虽然在以前版本的API中,有两个ID系统,一个用于对 ...
- Luogu3175 HAOI2015 按位或 min-max容斥、高维前缀和、期望
传送门 套路题 看到\(n \leq 20\),又看到我们求的是最后出现的位置出现的时间的期望,也就是集合中最大值的期望,考虑min-max容斥. 由\(E(max(S)) = \sum\limits ...
- 【php增删改查实例】第二十三节 - PHP文件上传
22. PHP文件上传 22.1 资源文件 将这三个东西拷贝项目的根目录. 拷贝完毕后,打开upload.html: 现在,我们在项目的根目录去编写一个upload.php. PHP给我们提供了很多关 ...
- Echo团队便利记事本项目终审报告
一.团队成员简介 http://www.cnblogs.com/echo-buaa/p/3991968.html 二.团队项目的目标,预期的典型用户,预期的功能描述,预期的用户数量在哪里? 项目的目标 ...