机器学习工作流程第一步:如何用Python做数据准备?
这篇的内容是一系列针对在Python中从零开始运用机器学习能力工作流的辅导第一部分,覆盖了从小组开始的算法编程和其他相关工具。最终会成为一套手工制成的机器语言工作包。这次的内容会首先从数据准备开始。
—— 来自Matthew Mayo, KDnuggets
似乎大家对机器学习能力的认知总是简单到把一系列论据传送到越来越多的数据库和应用程序界面中,接着就期待能有一些神奇的结果出现。可能你对在这些数据库里究竟发生了什么有自己很好的理解—— 从数据准备到建模到结果演示呈现等等,但不得不说你依然需要依赖于这些纷繁的工具去完成自己的工作。

这其实很正常。我们用被准确检验证明过能运行的工具来完成一些日常的任务是无可厚非的。重新发明使用那些不能有效滚动的轮子不是最好的办法。这样会有很多局限,也会浪费很多的不必要的时间。无论你是使用开放源代码还是被授权的工具来完成你工作,这些代码工具已经被很多人反复试用升级以确保当你上手使用的时候能够以最好的质量完成你的工作。
然而,有些苦活累活你自己做也是有价值的,即便是作为一种教育性的努力。我不是要推荐你们从零开始通过自己深度学习练习写出一个程序框架,至少不能一直这样,但哪怕只有一次通过不断的试验和失败,从头开始写出和自己的算实现它们的支持工具也是非常好的。我可能说的不对,但我认为如今在学习机器学习能力、数据科学、人工智能等方面的大多数人都没有在这么做。
所以让我们从头开始,来学习在Python里建立一些机器学习能力的相关知识。
“From Scratch” 究竟是什么意思?
首先,我先申明:当我提到“From Scratch”,我的意思是尽可能少的借助外界的帮助。当然这也是相对的,但是为了达成我们的目标,我会划定界限,当我们在写自己的矩阵模型、数据框或者构建自己的数据库时,我们会分别使用Python中的numpy、panda和matplotlib库。在某些情况下,我们甚至不会使用这些库的全部功能。我们稍后会讨论,让我们先暂时放一放它们的名字以便大家更好的理解。在Python自带的库中自带的功能原则上都是可以使用的,但除此之外,我们就要自己来写了。
我们需要从一个点入手,那就让我们从一些简单的数据准备任务开始吧。开始的时候我们会慢一点,但当我们对(要学习的东西)有了一点感觉以后,我们会逐渐加快速度。除了数据准备,我们还需要数据转换、结果演示和呈现工具——更不必说机器学习能力算法了——来达成我们我们即将要完成的目标。
我们的想法是手动拼接任何我们需要的重大功能,以便完成我们的机器学习能力任务。当序列展开的时候,我们可以添加新的工具和算法,同时我们也能重新思考我们以前的假设(是否正确),使整个过程尽可能重复迭代,就像它会渐近一样。慢慢的,我们会集中精力在我们的目标上,制定策略来完成目标,把它们运用到Python里,再检验它们是否能够运行。
最终的结果,就想我们现在预期的一样,会是有序排列在我们自己的简易的机器学习数据库中的一系列简单的Python模型。对于初学者,我相信这是理解机器学习过程、工作流和算法如何运行的非常宝贵的经验。
工作流(workflow)究竟是什么意思?
工作流对不同的人意味着不同的意思,但是我们这里说的工作流指的是机器学习项目中的一部分。我们有很多过程框架来帮助我们追踪我的工作进程,但现在让我们简化到一下的这些:
获取数据
处理/准备数据
建立模型
解释呈现结果
在我们真正做的时候我们可以拓展,但是这是我们现在自己设计的简单的机器学习的过程框架。同时,“输送管(小箭头)”暗含了把工作流中各功能聚集在一起的能力,所以让我们把这些记住然后继续向前。
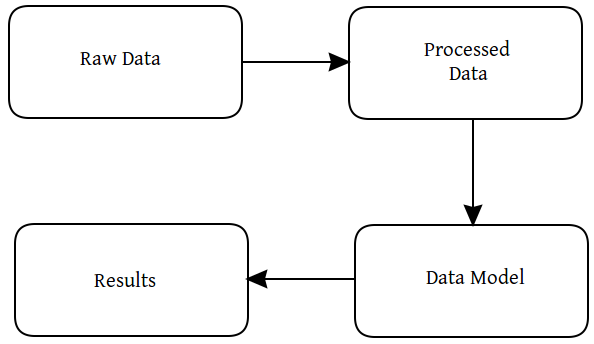
获得数据
在我们建立自己的模型之前,我们需要一些数据,还需要确认这些数据与我们合理的期望相符合。为了检测的目的(而不是训练或测试,但只是测试我们自己的设备),我们会使用虹膜数据集,你可以从这里下载。尽管我们可以在网上找到很多版本的数据集,但我建议我们都使用相同的原始数据,以确保我们的准备工作正常运行。
让我们来看一看:

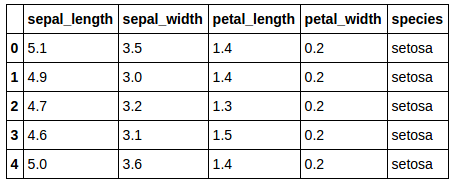
既然我们已经知道了这个简单的数据集和它对应的文件,我们先来想一想我们需要做什么使原始数据演变成我们想要的结果:
数据需要储存成CSV格式的文件
实例大部分由有数字属性的值组成
组别是经过分组的内容http://www.wmyl15.com/
到目前为止,以上没有一种是对所有的数据集都适用的,但是也没有任何一个是只能适用于某一种数据集的。这使得我们能够有机会编写我们可以以后重复使用的代码。好的编程练习会让我们集中于重复利用性和模块性。
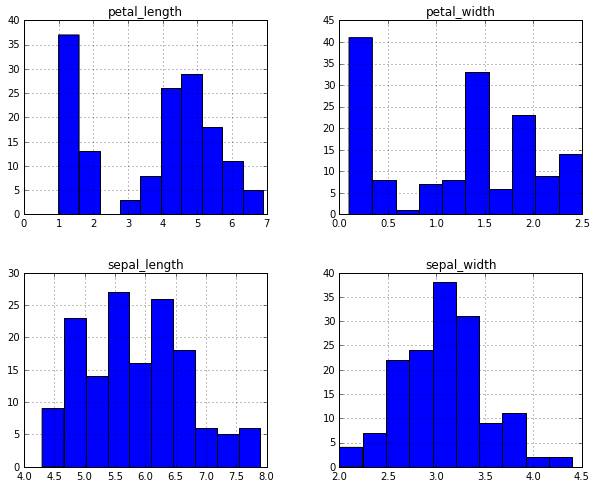
一些简单的探索性数据分析被罗列如下:
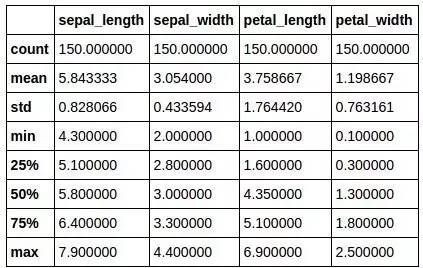
(上图为具体数值,下图为图像化数据)
准备数据
虽然数据准备在我们现在这个特定的情境中需要的很少,但是有时还是会需要。尤其是我们需要确认我们解释了标题行,去除了任何pandas呈现出来的参数,并且把我们的每一次组的值从名字型的转化成数值型的。因为在我们使用模型时已经没有名字性数值了,所以到此为止至少就没有更复杂的转化了。
最终,我们也需要一个对我们自己的算法的更好的数据呈现,所以我们在继续向前进行之前会确保我们最终呈现的是一个矩阵——或者numpy nadarry。我们的数据准备工作流接下来会做一下的表格:
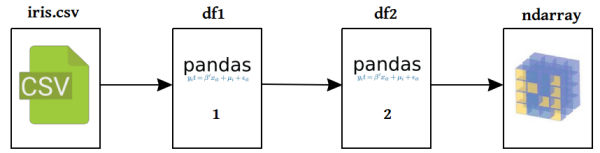
同时,我们需要主要我们没有理由相信所有有趣的数据都会被储存在被逗号分开的文件里。我们可能希望能够从一个SQL数据库里或者直接从网上获取数据,从这两个地方找到的数据我们以后还能返回去回看。
首先,让我们写一个简单的函数,把一个CSV文件上传到DataFrame。当然,这在内网做很容易,但是再往前想一步我们可能想再加一些额外的步骤到我们自己的数据集里以便我们以后上载函数。

这个编码是相当直接的。一行一行的读数据文件就完成了一些额外的预先加工,比如忽略了那些内容非数据的行(我们认为在数据文件中评价是由井号键开始的,尽管这很荒谬。)我们可以详细说明这个数据集文件是否包括标题,我们也可以接受csv和tsv文件,csv文件是默认的设置。
有一些错误检查存在,但它还并不是很健全,所以我们或许可以晚一点再回来说这个话题。此外,逐条读文件再逐条决定要对这些行做什么,比直接用内置功能把处理干净的一致的cs一文件直接读到DataFrame中要慢,但权衡之后我们发现允许更多的灵活性,在这一阶段是值得的(但读大的文件可能会发花费很久的时间)。不要忘了,如果一部分内置操作不是最好的方法,我们可以晚一些再做调整。
在我们尝试运行自己的编码之前,我们需要来写一个函数,把名字类数值转化成数字类数值。为了推广函数,我们需要使它能够用于数据集中的任何属性的数值,不仅仅是运用于不同的类别。我们还应该跟踪属性名称最终是否成为了整数。有了之前把csv或ts me的数据文件上传pandas的DataFrame的步骤经验,这个函数应该同时接受一个pandas DataFrames以及被转化为数字的属性名称。
我们还要注意,我们回避了关于使用单热编码的话题,这涉及到分类的非分类属性,但我认为我们以后还会回到这个话题。

上述的函数又是一个简单的,但是能帮助我们完成目标函数。我们可以用很多不同的方式来完成这个任务,包括使用pandas内置的功能,但是让你从一些会让你有些累的苦差事开始做就是这个函数的意义。
现在我们可以从文件中加载一个数据集,然后把分类属性值转换成数字属性值(我们也可以保留这些映像在字典中供以后使用)。就像之前提到的,我们希望我们的数据集最终是以numpy ndarry的形式存在,这样我们可以在自己的算法中很简单的使用。同样的,这是一个简单的任务,但写一个函数会让我们在以后需要的时候还可以以此为准。
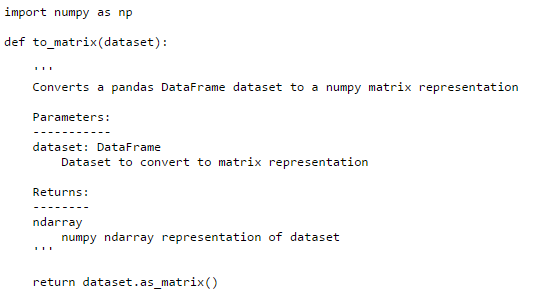
即使以前任何的功能都没有过度的杀伤力,但这个功能有可能有。但请忍耐我,我们遵守非常全面的编程准则--如果过于谨慎的话。在我们继续往下讲的过程中会有很好的机会让我们对已有的功能做改变或添加。这些变化如果能在一个地方实施并且记录在案,从长远来看非常有意义。
测试数据准备的工作流
我们的工作流迄今为止可能仍然是构建板块的形式,但让我们给自己的编码一个测试。


我们的代码正在按我们希望的方式工作,让我们做一些简单的房屋清理工作。一旦开始滚动,我们将为我们的编码提供一个更全面的组织结构,但是现在我们需要把所有这些功能加到一个单独的文件中,并保存成为dataset.py的格式。这会让我们以后的使用更方便,下次我们会学到。
未来计划
之后我们会学习简单的分类算法,k最近邻算法。我们会学习如何在简单的工作流中构建分类和聚类模型。毫无疑问,这需要编写一些限额外的工具来帮助我们完成项目,并且我确定我们还将对已经做完的部分进行修改。
练习机器学习就是理解机器学习的最好方法。运用我们的工作流中需要的算法和支持工具最终会被证明是有用的。
机器学习工作流程第一步:如何用Python做数据准备?的更多相关文章
- 一步一步教你如何用Python做词云
前言 在大数据时代,你竟然会在网上看到的词云,例如这样的. 看到之后你是什么感觉?想不想自己做一个? 如果你的答案是正确的,那就不要拖延了,现在我们就开始,做一个词云分析图,Python是一个当下很流 ...
- 如何用Python做Web开发?——Django环境配置
用Python做Web开发,Django框架是个非常好的起点.如何从零开始,配置好Django开发环境呢?本文带你一步步无痛上手. 概念 最近有个词儿很流行,叫做“全栈”(full stack ...
- Github标星4W+,热榜第一,如何用Python实现所有算法
文章发布于公号[数智物语] (ID:decision_engine),关注公号不错过每一篇干货. 来源 | 大数据文摘(BigDataDigest) 编译 | 周素云.蒋宝尚 学会了 Python 基 ...
- Andrew Ng机器学习课程,第一周作业,python版本
Liner Regression 1.梯度下降算法 Cost Function 对其求导: theta更新函数: 代码如下: from numpy import * import numpy as n ...
- 如何用Python做词云(收藏)
看过之后你有什么感觉?想不想自己做一张出来? 如果你的答案是肯定的,我们就不要拖延了,今天就来一步步从零开始做个词云分析图.当然,做为基础的词云图,肯定比不上刚才那两张信息图酷炫.不过不要紧,好的开始 ...
- 如何用 Python 做自动化测试【进阶必看】
一.Selenium 环境部署 1. window 环境部署 1.1 当前环境Win10 64 位系统:Python3.6.2(官方已经更新到了 3.6.4) 官方下载地址:https://www.p ...
- 如何用Python做自动化特征工程
机器学习的模型训练越来越自动化,但特征工程还是一个漫长的手动过程,依赖于专业的领域知识,直觉和数据处理.而特征选取恰恰是机器学习重要的先期步骤,虽然不如模型训练那样能产生直接可用的结果.本文作者将使用 ...
- Python做数据预处理
在拿到一份数据准备做挖掘建模之前,首先需要进行初步的数据探索性分析(你愿意花十分钟系统了解数据分析方法吗?),对数据探索性分析之后要先进行一系列的数据预处理步骤.因为拿到的原始数据存在不完整.不一致. ...
- 如何用Python从海量文本抽取主题?
摘自https://www.jianshu.com/p/fdde9fc03f94 你在工作.学习中是否曾因信息过载叫苦不迭?有一种方法能够替你读海量文章,并将不同的主题和对应的关键词抽取出来,让你谈笑 ...
随机推荐
- Linux java 命令行编译 jar包
Java 命令行编译成class,然后在打包成jar文件. 编译成class javac -classpath $CLASS_PATH -d class ./src/Hello.java 可以通过ja ...
- CF1056E Check Transcription 字符串哈希
传送门 暴力枚举\(0\)的长度,如果对应的\(1\)的长度也是一个整数就去check是否合法.check使用字符串哈希. 复杂度看起来是\(O(st)\)的,但是因为\(01\)两个数中数量较多的至 ...
- echarts柱状图标签显示不完全的问题
echarts 柱状图当x轴标签数目超过一定数目时在小尺寸设备上第一个和最后一个标签不显示(不是重叠),axisLabel设置interval:0也不起作用; 解决办法: 这个问题存在于4.0版本以上 ...
- 从源码的角度再看 React JS 中的 setState
在这一篇文章中,我们从源码的角度再次理解下 setState 的更新机制,供深入研究学习之用. 在上一篇手记「深入理解 React JS 中的 setState」中,我们简单地理解了 React 中 ...
- list 的 增 删
增: 1. name = [] 2. name.append() 3. name.extend(name2) name2为可迭代的 name + name2 与之效果一样,合并为一个列表 4. nam ...
- c++ 中关于一些变量不能声明的问题
j0,j1,jn,y0,y1,yn被c++中某些函数占用了,所以是不能被声明的,今天就遇到了这个问题,结果我在自己写的程序中找了半天都没找到重复申明的y1
- B. Equations of Mathematical Magic
思路 打表找规律,发现结果是,2的(a二进制位为1总数)次方 代码 #include<bits/stdc++.h> using namespace std; #define ll long ...
- 《Linux内核分析》第五周学习总结
<Linux内核分析>第五周学习总结 ——扒开系统调用的三层皮(下) 姓名:王玮怡 学号:20135116 1.给menu ...
- Linux实践:ELF文件格式分析
标签(空格分隔): 20135321余佳源 一.基础知识 ELF全称Executable and Linkable Format,可执行连接格式,ELF格式的文件用于存储Linux程序.ELF文件(目 ...
- ASP.NET Web Service 标准SOAP开发案例代码(自定义验证安全头SOAPHeader)
using System.Xml;using System.Xml.Serialization;using System.Web.Services.Protocols;using System.Con ...