DML和索引内部结构变化
1.修改数据对索引结构的影响
合适的索引对查询性能和效率的提升是巨大的,但是万事有利有弊,拥有索引的表在增、删、改记录时需要去维护索引。如何让增、删、改更快速更高效?这就需要了解数据修改时对索引结构会产生什么影响。
1.1页拆分和行移动现象
1.页拆分
页拆分也称为页分裂。当有序的页面容不下新记录时就会出现页拆分现象。页拆分时SQL Server会尽量将旧页的一半记录复制到新页,其中的动作是先在旧页delete需要移动的行再在新页insert移动的行,新插入的行会根据键值大小来决定插在旧页中还是新页中。
INSERT和UPDATE都可能会导致页拆分。当页拆分后还是不能容下某记录时,会出现二次拆分,二次拆分后发现还是不能容下会三次拆分,直到能容下这部分记录。假如父页原有10行,插入一个7900字节的,第一次拆分差不多移动5行左右到新页,发现在新页还是容不下新行,又拆分移动2行到另一个新页,还是发现不能和新行并存,接着拆分2次,最后发现,新行只能独立成页才最后一次拆分页来存放新行,这时就有不少页只利用了很少一点空间。
页拆分后的页之间通过双链表连接,即形成上下页的关系。页拆分会记录日志,并且在拆分完成后,页拆分的专属系统内部事务会单独被提交,因此即使INSERT语句回滚了,拆分的页也不会回滚。也因此,频繁页拆分是一个消耗大量资源的动作。
页面容不下新记录时并不一定会页拆分,只有有序的页面会页拆分。如果是堆表的数据页,插入或更新记录都是“见缝插针”型的页填充,不会出现页拆分现象。如果新记录插入的位置是B树中某个层次的中间一个页面(如叶级层次的中间某页),当该页容不下新记录时,则一定会进行页拆分。如果新记录是插在最后一页(例如,具有IDENTITY属性的列为聚集键,向其中插入新记录时总是会插入在表尾),并且该页容不下新记录,则有两种情况:一是进行页拆分,所有的索引页(包括聚集的和非聚集的)和聚集索引叶级的第一页都是这种情况;二是直接分配新页存放新记录,不进行页拆分,聚集索引的叶级部分除了第一页的所有页都是这种情况。
下面的图中演示了向聚集表尾插入数据的页拆分过程。随着数据不断插入到聚集表的尾部,叶级的第一页首先拆分,这时会分配第二个叶级页和一个根页,并将接近一半的记录移动到第二个叶级页中,以后将尽量完全填充叶级页。这也是聚集索引的一个作用,表尾数据的插入不会导致大量的页拆分,并且保证了叶级页的空间使用率。当第一个根页无法容纳新记录时,将分配一个新的中间页和一个新的根页,旧的根页则变成中间页,并且以后将一直分裂,页面的空间使用率也不高。

需要引起注意的是,每当B树结构中出现一个新的层次页时,为这个新的层次分配的页码总是会挤在中间。例如,下面的图中所展示的情况,新分配的根页页码为257,挤在叶级第一页和第二页的页码中间。

2.行移动
行移动的现象只在更新行和页拆分的时候出现。行移动可能在本页移动,也可能在页间移动。
页拆分时的行移动很容易理解,拆分时尽量将旧页的大概一半记录移动到新页,这是页间的行移动。
那更新行时的行移动是怎么进行的呢?更新行时可能是在本页移动,可能是页间移动。不管在页内移动还是页间移动,移动后如何找到记录是问题的关键,这和记录是否有序、如何定位记录有关。
对于有序的记录(所有的索引页和聚集索引的叶级页中的记录),通过顺序就可以找到移动后的位置。如果更新行时,行记录只需在本页移动,则只需重排下该页的slot,空间位置上不会真的移动这一行。例如,某聚集表的数据页中记录了聚集键值为1(slot0)、3(slot1)、5(slot2)、7(slot3)、9(slot4)的记录,如果将3更新为6,则该记录可以继续留在本页,只需重排下slot,重排后记录对应为1(slot0)、5(slot1)、6(slot2)、7(slot3)和9(slot4)。如果将3修改为4呢?那么除了修改键值外不做任何其它改变。如果更新行时,行记录需要移动到其它页上,这时先在旧页执行DELETE再在新页执行INSERT,当然,这里也会重排相关页内的slot。
对于无序的记录,也就是堆表的数据页,如果记录在页间移动,则会在原记录处留下转发指针(forwarding pointer),用于定位移动后的位置。如果该记录需要二次移动,则会更新原记录处的转发指针指到最新的位置,而不会在中间的位置添加转发指针,即转发指针不可能指向另一个转发指针。转发指针的作用是用于定位,如果堆中有非聚集索引,只需让非聚集索引的叶级行定位器RID指向转发指针的位置,通过转发指针就能定位新位置。
转发指针只在堆中出现,当转发指针数量多时,它对性能的影响非常大,可能出现多十倍甚至百倍的逻辑读。数据库收缩或文件收缩会收缩转发指针;当再次更新转发后的行记录使得原位置又可以容纳该行,则该行会复位并删除转发指针。
堆中行的更新不会出现页内移动,因为只要本页空间够容下更新后的记录,该记录直接在本页上扩展空间即可。因此,除非物理移动了数据文件的位置,堆中非聚集索引行定位器RID将不会因为行的更新而受到影响。
1.2 插入行
堆中插入行,是“见缝插针”型。此时会寻找空间足够大的“缝”来插入这根“针”,如果有空“缝”但空间不够放这一行记录,则不会在这里插入;如果在已分配的页中没有“缝”可以存放记录,就新分配一个页来存放。由于总会找到合适的空间,因此不会出现页拆分现象。注意:更新行是DELETE和INSERT的结合操作,因此在堆表更新行时,即使容不下行也不会页拆分,而是留下转发指针。
聚集表中插入行的位置是固定了的,页中容不下新记录时可能会出现页拆分,也可能不会页拆分,具体的情况在刚才的页拆分段落的上下文中说明了。
在非聚集索引的索引页上插入记录且容纳不下时会出现页拆分。
1.3 删除行
1.删除堆的数据页
堆表数据删除后不释放空间,留下slot但slot不指向页中的位置,也就是像slot 0 0x0这样。这时候如果有新记录要存放就可以“见缝插针”,并将原来没有指向的slot指向这一插入的行。
下面的图中展示的是某个堆的页中记录被删除后的偏移信息,删除的是原来slot 0到slot 6的记录。

如果想要释放堆中的空间,可以使用TRUNCATE删除整个表中数据;或者在DELETE时加上WITH(TABLOCK)选项(如DELETE FROM WITH(TABLOCK) table_name WHERE...)来按页释放空间;也可以先在堆中建立聚集索引,然后删除数据再删除聚集索引。
2.删除聚集表中记录
聚集索引的叶级和聚集表中非聚集索引的叶级记录被删除后会在原位置留下虚影记录(ghost_record),它们不是真正的被删除,只是在记录上做了虚影标记。该标记可以从页的标头信息查看,看下图,图中只整理了某页与虚影记录相关的信息。虚影记录由后台进程定时清理,清理后空间被释放。
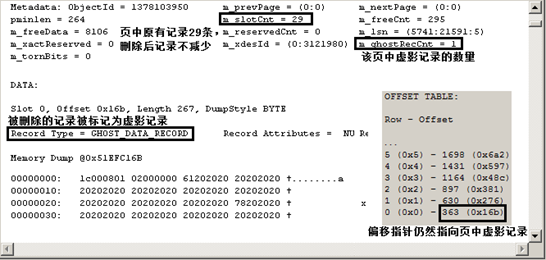
因为叶级还有虚影,所以非叶级仍然需要指向它们,因此聚集索引的非叶级和聚集表中非聚集索引的非叶级记录都不会被删除,而且它们不是虚影,而是原原本本的原记录。直到后台进程清除虚影后,叶级页被释放,指针也被释放,当非叶级页上没有数据了也直接删除并释放空间。
3.删除堆中非聚集索引的叶级和非叶级记录
因为堆中非聚集索引的行定位器指向堆中行位置,因此删除堆中行的同时会释放指针并删除叶级页中对应的记录,如果删除的记录足够多,还会删除非叶级的记录。不过删除非聚集索引的叶级和非叶级会直接释放空间,而不是和删除堆的数据页一样仍然占用空间。
1.4 更新行
更新行可能出现行移动和页拆分。行移动又可能是本页移动和页间移动,这种情况是非在位更新;还可能是原地更新,即不会出现任何移动,这种情况称为在位更新。
更新行的具体内部变化已经在刚才的页拆分和行移动段落里分情况讨论了,这里就不赘述了。
2.碎片
在SQL Server中,碎片分两种:内部碎片和外部碎片。
1.内部碎片
内部碎片一般还称为页密度或物理碎片,表示页中减去填充因子所占的空间后的空间使用率,也就是页面使用率。SQL Server综合每个B树的层次的页空间使用情况,分别生成一个内部碎片百分比。内部碎片可能由下面几种情况导致:
- 页拆分:页拆分后由于行移动,导致拆分的页面和新页面中出现空白空间。
- DELETE操作导致页面还剩部分数据。这里的例外是聚集表由于记录被删除时存在虚影,所以不会释放这些删除行的空间,直到后台进程清理后才出现空白空间。
- 行的大小使得页面填充不完整。例如,聚集索引叶级页中一个宽5000字节的行存放时一页只能放一行,每页都会浪费3000字节左右的空间。
在读取需要的数据时,内部碎片可能会使系统读取更多的页面,导致IO更大,并且需要更多的内存来存储这些页面。例如,读取聚集键值1-100的记录,如果不出现页拆分,它们可能存储在同一页上,这时只需从磁盘读取1页即可,如果内部碎片多,可能1-50在一页上,51-100在另一页上,这时就需要从磁盘读两页。
内部碎片也有好处,比如插入行时由于空闲空间的存在,可能不会出现页拆分现象。因此,经常需要DML操作的时候有一定的内部碎片是允许且有益的;但是对经常需要读取巨量数据进行分析的场景,对查询的性能要求较大,内部碎片越少越好。
可以通过sys.dm_db_index_physical_stats中的avg_page_space_used_in_percent列检测内部碎片。sys.dm_db_index_physical_stats是一个表值函数,它有5个参数,第一个参数是DatabaseID,第二个参数是ObjectID,第三个参数是IndexID,第四个参数是分区ID号,第五个参数是显示信息的模式。
SELECT OBJECT_NAME(object_id) AS name,
index_id,
index_type_desc AS index_type, --索引类型
index_depth, --索引B树的深度
index_level, --索引B树的层次位置
record_count AS rec_cnt, --对应层次的记录数量
page_count AS pg_cnt, --对应层次使用的页的数量
avg_fragmentation_in_percent AS frag_precent, --外部碎片百分比
avg_page_space_used_in_percent AS used_percent --内部碎片百分比
FROM sys.dm_db_index_physical_stats(DB_ID('testdb'),OBJECT_ID('dbo.Clu_Test'),NULL,
NULL,'DETAILED')
对Clu_test表中的索引进行分析,返回结果看下图,从图可知为Clu_test表中所有B树的每个层次都进行了分析,其中最后一列是内部碎片的情况。

2.外部碎片
外部碎片一般还称为逻辑碎片或扩展碎片,是页拆分时出现页的逻辑顺序和物理顺序不一致导致的。很多地方说碎片默认的就是外部碎片。
那什么是页的逻辑顺序什么是页的物理顺序?页的逻辑顺序是指通过双链表形成的顺序,它能体现B树结构中键值的顺序,因此读取和扫描时按照页的逻辑顺序进行;页的物理顺序是指物理页的页码数值顺序。如果完全按序分配区间和页面,则页面之间不仅在逻辑上连续,在物理页码的数值上也是连续的,比如1-->2-->3。如果页面2出现页拆分,逻辑顺序变成1—>2-->10-->3,这样逻辑顺序和物理顺序将不一致。在页读取或扫描时,会在不连续的页面上不断的进行跳跃定位,很可能会让磁盘臂进行来回移动,从而消耗大量时间。例如从2定位到10进行一次页定位动作,再从10定位回3也要一次定位动作,这需要消耗时间;如果是1-->2-->3-->4这样连续的页就可以快速下一页下一页扫描甚至一次性抓取多个邻近的页到内存中(SQL Server允许一次性读取64个连续的页到内存中,更详细的页读取情况可以查看这篇文章https://msdn.microsoft.com/zh-cn/library/ms191475(v=sql.105).aspx),从而节省大量的页定位时间,并提高效率。
如果查询请求的记录较少,外部碎片的影响可以忽略,因为读取页时少量的页定位影响不大;但是如果查询要返回大量记录,由于要读取较多页面,大量的外部碎片会导致多次来回页定位,会严重影响查询性能。可以通过sys.dm_db_index_physical_stats中的avg_fragmentation_in_percent列来检测外部碎片。
传统的机械硬盘读取数据需要先计算地址后寻道,寻道时会移动磁盘臂,寻道后盘片旋转使数据所在扇区处于磁头下方,最后磁头读取扇区数据。扇区数据的读取动作非常快,整个过程的大部分时间都消耗在寻址上。在SQL Server存储机制上,读取一个页和读取一个区的时间几乎是相等的,而页定位很可能意味着要消耗大量时间寻址。因此对于有大量定位动作的读取行为,时间主要消耗在定位上。
固态硬盘只有得到指令后地址的计算时间,几乎没有寻址时间,不存在定位消耗大量时间的问题,因此外部碎片问题也迎刃而解。
3.重组和重建索引
重组索引可以将索引的叶级进行重新排列并整理。重组索引使用的是原有的叶级页,重组完成后如果有空页则会释放空页。因为索引重组没有涉及创建索引的过程,因此重组语句中不能指定填充因子,只能默认使用创建索引时指定的填充因子进行重组。重组时会根据内部算法(冒泡排序算法)合理的移动行到合理的位置,尽可能的填充页面空间,并使页的逻辑顺序和物理顺序尽量保持一致,这样可以减少内部碎片和外部碎片。
和重组索引相比,重建索引更彻底。重建索引会为索引B树(不只是叶级)重新分配一套页面,并释放旧页。重建索引实现的是删除旧碎片(其实是释放旧的页),但是并不能保证重建后完全无碎片。
例如,新分配的页面之间本身就不连续,或者分配页面的时候正好有其它进程(例如多个CPU并行重建索引时)抢占了中间的页面导致两个进程的页面有交错区域。实际上B树结构中拆分出新层次的页(如第一个中间页或者新的根页)时,都会为新层次的页分配一个中间的页码,如某聚集索引重建最初只有一个页码为208的叶级页,出现第二个叶级页的同时会分配一个根页,根页页码为209,第二个叶级页页码为210,这样根页页码就挤在了叶级页的中间,这也是外部碎片只能无限趋于0但不可能完全被删除的原因之一。
DML和索引内部结构变化的更多相关文章
- Sql Server之旅——第十站 看看DML操作对索引的影响
我们都知道建索引是需要谨慎的,当只有利大于弊的时候才适合建,我们也知道建索引是需要维护成本的,这个维护也就在于DML操作了, 下面我们具体看看到底DML对索引都有哪些内幕.... 一:delete操作 ...
- [每日一题] OCP1z0-047 :2013-07-27 外部表――不能被DML和建索引
首先看官方文档上的解释: Managing External Tables Oracle Database allows you read-only access to data in externa ...
- ORACLE关于索引是否需要定期重建争论的整理
ORACLE数据库中的索引到底要不要定期重建呢? 如果不需要定期重建,那么理由是什么? 如果需要定期重建,那么理由又是什么?另外,如果需要定期重建,那么满足那些条件的索引才需要重建呢?关于这个问题,网 ...
- 详解MySQL---DDL语句、DML语句与DCL语句
背景:近几年,开源数据库逐渐流行起来.由于具有免费使用.配置简单.稳定性好.性能优良等优点,开源数据库在中低端应用上占据了很大的市场份额,而 MySQL 正是开源数据库中的杰出代表.MySQL 数据库 ...
- 索引rebuild与rebuild online区别
索引rebuild与rebuild online区别 1.0目的,本篇文档探讨索引rebuild 与 rebuild online的区别 2.0猜测:已有的知识 2.1对索引rebuild重建会对表申 ...
- MySQL的DDL语句、DML语句与DCL语句
背景:近几年,开源数据库逐渐流行起来.由于具有免费使用.配置简单.稳定性好.性能优良等优点,开源数据库在中低端应用上占据了很大的市场份额,而 MySQL 正是开源数据库中的杰出代表.MySQL 数据库 ...
- 【MySQL】(五)索引与算法
本篇文章的主旨是对InnoDB存储引擎支持的索引做一个概述,并对索引内部的机制做一个深入的解析,通过了解索引内部构造来了解哪里可以使用索引. 1.InnoDB存储引擎支持以下几种常见的索引: B+树索 ...
- SQLSERVER聚集索引与非聚集索引的再次研究(上)
SQLSERVER聚集索引与非聚集索引的再次研究(上) 上篇主要说聚集索引 下篇的地址:SQLSERVER聚集索引与非聚集索引的再次研究(下) 由于本人还是SQLSERVER菜鸟一枚,加上一些实验的逻 ...
- SQL Server-聚焦聚集索引对非聚集索引的影响(四)
前言 在学习SQL 2012基础教程过程中会时不时穿插其他内容来进行讲解,相信看过SQL Server 2012 T-SQL基础教程的童鞋知道前面写的所有内容并非都是摘抄书上内容,如若是这样那将没有任 ...
随机推荐
- 基于OpenCV的图书扫描识别程序开发
1.AndroidStudio环境配置 https://www.cnblogs.com/little-monkey/p/7162340.html
- cp备份操作时如何忽略指定的目录
需求场景:进行CP拷贝备份的时候,子目录里面的某些大文件或是一些log文件是无需备份的,那么在CP操作时需要忽略掉指定的目录. 案例演示如下:备份data目录,但是不包括里面的share子目录. 先看 ...
- HDU 1171 01背包
http://acm.hdu.edu.cn/showproblem.php?pid=1171 基础的01背包,求出总值sum,背包体积即为sum/2 #include<stdio.h> # ...
- noip第14课资料
- 使用gulp+bebal实现前端自动化es6转es5的构建
说明:es6语法已经越来越普及,但是一些低版本的浏览器不支持es6的语法特性,所以我们在开发完前端项目后,往往需要统一把前端es6的代码编译成es5的代码.本文介绍的就是如何手动和自动的把es6转成e ...
- SSH框架搭建过程详解
Spring.Struts2.Hibernate框架: 具体三大框架的知识以前的文章写过,在这里整合 Spring框架知识:http://www.cnblogs.com/xuyiqing/catego ...
- Java学习笔记36(File类)
File类可以对操作系统中的文件进行操作: File类的静态成员变量: package demo; import java.io.File; public class FileDemo { publi ...
- Netty 发送消息失败或者接收消息失败的可能原因
1. 消息发送失败: 检查通道是否建立成功 Netty中的通道建立采用的是异步方式,获取到的通道对象可能为空或初始化未完成: 2. 接收的消息有丢失 消息可能会粘包,是否有拆包机制
- [EXP]Microsoft Windows 10 - XmlDocument Insecure Sharing Privilege Escalation
Windows: XmlDocument Insecure Sharing Elevation of Privilege Platform: Windows (almost certainly ear ...
- [视频]K8飞刀 解密菜刀后门教程
链接:https://pan.baidu.com/s/1raC1S_njxeqS7TaiTN6jLA 提取码:otmb