Python数据分析实例操作
import pandas as pd #导入pandas
import matplotlib.pyplot as plt #导入matplotlib
from pylab import *
mpl.rcParams['font.sans-serif'] = ['SimHei']
mpl.rcParams['axes.unicode_minus'] = False
%matplotlib inline
数据读取与索引
bra = pd.read_csv('data/bra.csv')
bra.head()

选取列
bra.content

bra[['creationTime','productColor']].head()

选择行
bra[1:6]
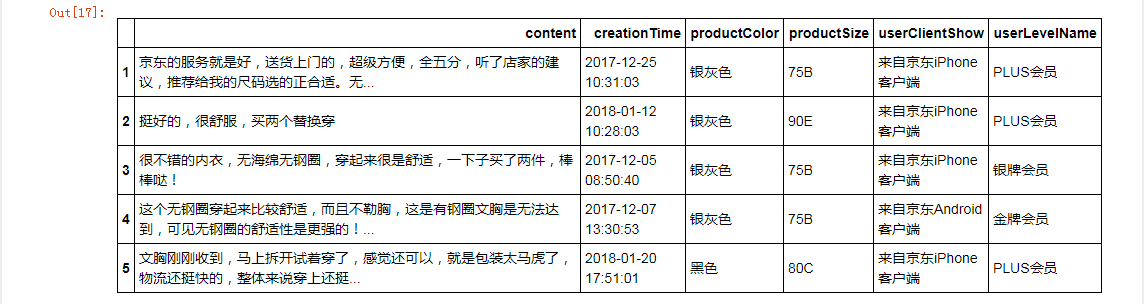
选择行和列
bra.ix[[2,3],[1,3]] #使用ix

bra.ix[1:5,['productColor']]

bra.iloc[[2,3],[1,3]] #使用iloc

bra.loc[1:5,['content','creationTime','productSize']] #使用loc

bra.loc[1:5,'content':'userClientShow']
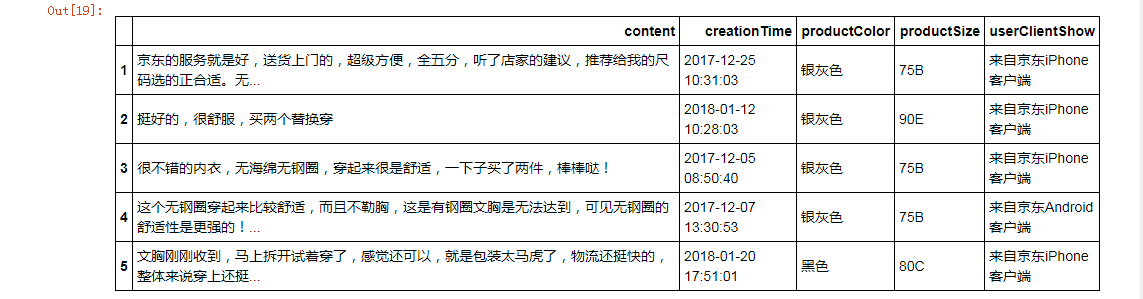
数据预处理
缺失值
bra.describe() #查看数据的分布情况,可返回变量和观测的数量、缺失值和唯一值的数目、平均值、分位数等相关信息

bra['userClientShow'].unique() #userClientShow列有几种选项
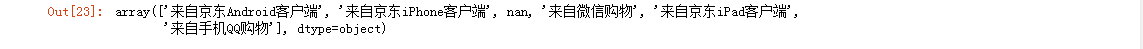
bra['userClientShow'].isnull().sum() #初始缺失值数量

bra['userClientShow'].fillna('不详',inplace=True) #缺失值替换为“不详”
bra['userClientShow'].isnull().sum() #赋值后的缺失值数量

新增列
bra.dtypes #查看属性

bra['creationTime'] = pd.to_datetime(bra['creationTime']) #更新类型
bra.dtypes

bra['hour'] = [i.hour for i in bra['creationTime']] #新建hour列
bra

字符串操作
bra.productSize.unique() #查看productSize的唯一值

cup = bra.productSize.str.findall('[a-zA-Z]+').str[0] #新增列cup
cup2 = cup.str.replace('M','B')
cup3 = cup2.str.replace('L','C')
cup4 = cup3.str.replace('XC','D')
bra['cup'] = cup4
bra.head()

bra['cup'].unique() #查看cup唯一值

数据转换
bra.productColor.unique() #查看productColor唯一值

def getColor(s):
if '黑' in s:
return '黑色'
elif '肤' in s:
return '肤色'
elif '蓝' in s:
return '蓝色'
elif '红' in s:
return '红色'
elif '紫' in s:
return '紫色'
elif '白' in s:
return '白色'
elif '粉' in s:
return '粉色'
elif '灰' in s:
return '灰色'
elif '绿' in s:
return '绿色'
elif '青' in s:
return '青色'
else:
return s
bra['color'] = bra['productColor'].map(getColor) #从productColor列查询,赋值到定义的函数getColor,最终新增列color
bra
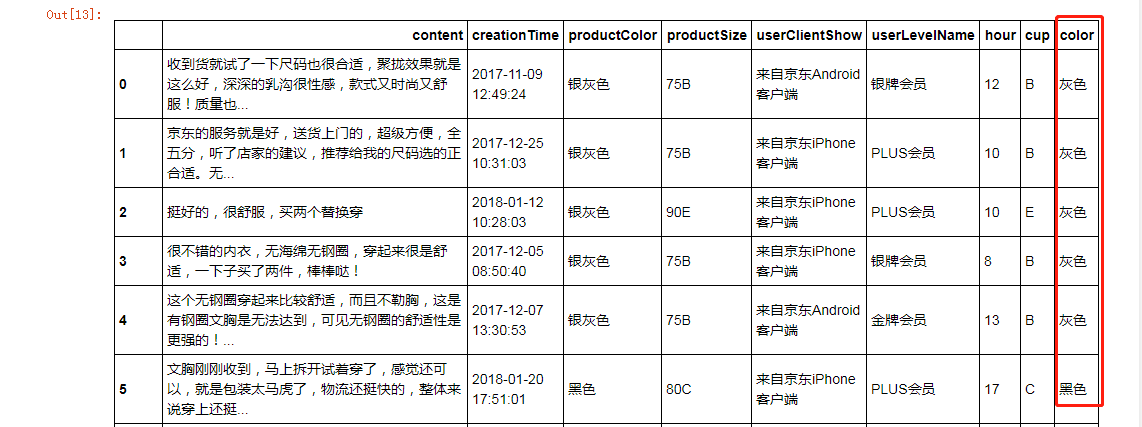
bra.color.unique() #查询color的唯一值

数据可视化
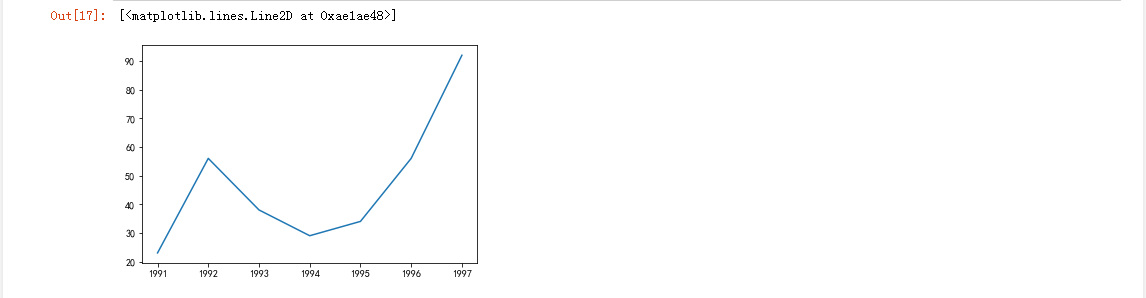
x = [1991,1992,1993,1994,1995,1996,1997]
y = [23,56,38,29,34,56,92]
plt.plot(x,y) #调用函数plot
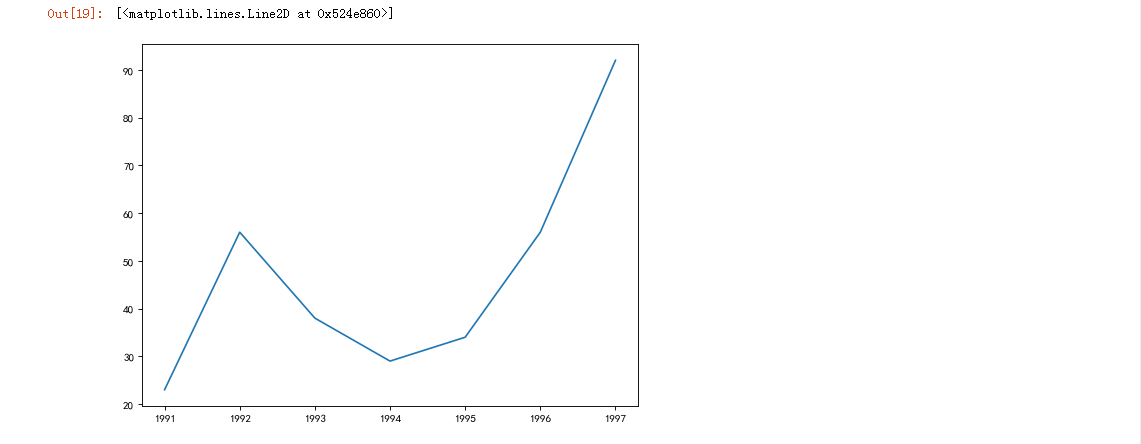
plt.figure(figsize=(8,6),dpi=80) #调用函数firgure
plt.plot(x,y)
hour = bra.groupby('hour')['hour'].count() #hour列排序
hour

plt.xlim(0,25) #横轴0~25
plt.plot(hour,linestyle='solid',color='royalblue',marker='8') #颜色深蓝

cup_style = bra.groupby('cup')['cup'].count() #cup列唯一值得数量
cup_style

plt.figure(figsize=(8,6),dpi=80)
labels = list(cup_style.index)
plt.xlabel('cup') #x轴为cup
plt.ylabel('count') #y轴为count数量
plt.bar(range(len(labels)),cup_style,color='royalblue',alpha=0.7) #alpha为透明度
plt.xticks(range(len(labels)),labels,fontsize=12)
plt.grid(color='#95a5a6',linestyle='--',linewidth=1,axis='y',alpha=0.6)
plt.legend(['user-count'])
for x,y in zip(range(len(labels)),cup_style):
plt.text(x,y,y,ha='center',va='bottom')

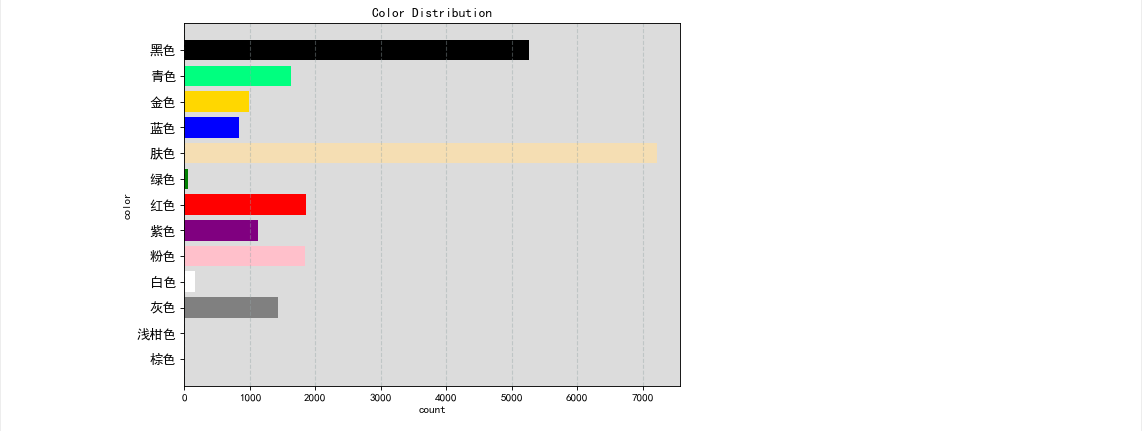
color_style = bra.groupby('color')['color'].count() #color列唯一值得数量
color_style

plt.figure(figsize=(8,6),dpi=80)
plt.subplot(facecolor='gainsboro',alpha=0.2)
colors = ['brown','orange','gray','white','pink','purple','red','green','wheat','blue','gold','springgreen','black'] #颜色种类
labels = list(color_style.index)
plt.xlabel('count') #x轴为count数量
plt.ylabel('color') #y轴为color
plt.title('Color Distribution') #定义标题
plt.barh(range(len(labels)),color_style,color=colors,alpha=1)
plt.yticks(range(len(labels)),labels,fontsize=12)
plt.grid(color='#95a5a6',linestyle='--',linewidth=1,axis='x',alpha=0.4)
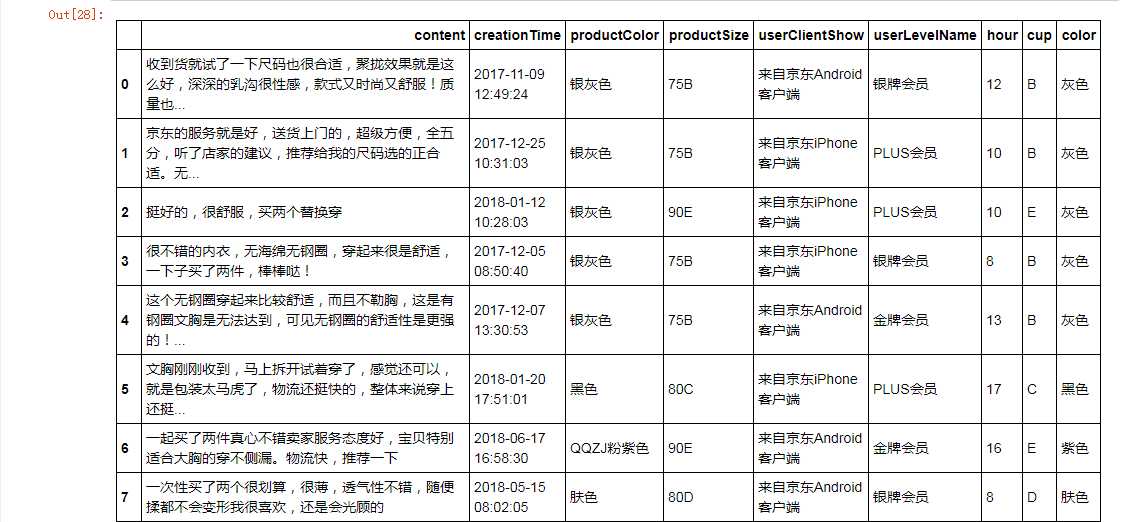
bra.head(30)
Python数据分析实例操作的更多相关文章
- python数据分析实例(1)
1.获取数据: 想要获得道指30只成分股的最新股价 import requests import re import pandas as pd def retrieve_dji_list(): try ...
- 创建Python数据分析的Docker镜像+Docker自定义镜像commit,Dockerfile方式解析+pull,push,rmi操作
实例解析Docker如何通过commit,Dockerfile两种方式自定义Dcoker镜像,对自定义镜像的pull,push,rmi等常用操作,通过实例创建一个Python数据分析开发环境的Dock ...
- 【Python数据分析】Python3操作Excel(二) 一些问题的解决与优化
继上一篇[Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 对豆瓣图书Top250进行爬取以后,鉴于还有一些问题没有解决,所以进行了进一步的交流讨论,这期间得到了一只尼玛 ...
- Python之虚拟机操作:利用VIX二次开发,实现自己的pyvix(系列一)成果展示和python实例
在日常工作中,需要使用python脚本去自动化控制VMware虚拟机,现有的pyvix功能较少,而且不适合个人编程习惯,故萌发了开发一个berlin版本pyvix的想法,暂且叫其OpenPyVix.O ...
- 小白学 Python 数据分析(5):Pandas (四)基础操作(1)查看数据
在家为国家做贡献太无聊,不如跟我一起学点 Python 人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Panda ...
- 小白学 Python 数据分析(6):Pandas (五)基础操作(2)数据选择
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- Python数据分析之Pandas操作大全
从头到尾都是手码的,文中的所有示例也都是在Pycharm中运行过的,自己整理笔记的最大好处在于可以按照自己的思路来构建矿建,等到将来在需要的时候能够以最快的速度看懂并应用=_= 注:为方便表述,本章设 ...
- 小白学 Python 数据分析(17):Matplotlib(二)基础操作
人生苦短,我用 Python 前文传送门: 小白学 Python 数据分析(1):数据分析基础 小白学 Python 数据分析(2):Pandas (一)概述 小白学 Python 数据分析(3):P ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
随机推荐
- Badge
The following plugin provides functionality available through Pipeline-compatible steps. Read more a ...
- Bootstrap-table 使用总结
一.什么是Bootstrap-table? 在业务系统开发中,对表格记录的查询.分页.排序等处理是非常常见的,在Web开发中,可以采用很多功能强大的插件来满足要求,且能极大的提高开发效率,本随笔介绍这 ...
- Ado.net和EF的区别
ado.net EF作为微软的一个ORM框架,通过实体.关系型数据库表之间的映射,使开发人员可以通过操作表实体而间接的操作数据库,大大的提高了开发效率.这样一来,.net平台下,我们与底层数据库的交互 ...
- 深入理解Java 8 Lambda(类库篇)
背景(Background) 自从lambda表达式成为Java语言的一部分之后,Java集合(Collections)API就面临着大幅变化.而 JSR 355(规定了 Java lambda 表达 ...
- 微信跳一跳Python辅助无需配置一键操作
作者:NiceCui 本文谢绝转载,如需转载需征得作者本人同意,谢谢. 本文链接:http://www.cnblogs.com/NiceCui/p/8350329.html 邮箱:moyi@moyib ...
- 10个最佳ES6特性
译者按: 人生苦短,我用ES6. 原文: Top 10 ES6 Features Every Busy JavaScript Developer Must Know 译者: Fundebug 为了保证 ...
- lfs(systemv版本)学习笔记-第2页
我的邮箱地址:zytrenren@163.com欢迎大家交流学习纠错! lfs(systemv)学习笔记-第1页 的地址:https://www.cnblogs.com/renren-study-no ...
- php+smarty轻松开发微社区/微论坛
今天我们就来分析微社区的基本功能构成吧.首先,每个论坛最主要的是会员在对应的版块下发帖,或者在感兴趣的主题帖下跟帖盖楼.其次,会员能时时看到帖子或版块的基本信息.所以主要大块是: 前台:会员的注册登录 ...
- SVN SVN合并(Merge)与拉取分支(Branch/tag)操作简介
SVN合并(Merge)与拉取分支(Branch/tag)操作简介 合并(Merge) 例子:把对feature_branch\project_name_v3.3.7_branch的修改合并到deve ...
- loadrunner 运行脚本-Run-time Settings->General->Additional attributes设置
运行脚本-Run-time Settings->General->Additional attributes设置 by:授客 QQ:1033553122 作用说明 为Vuser脚本提供额外 ...