RbbitMQ消息队列及python实现
1、简介
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件)。RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的。
所有主要的编程语言均有与代理接口通讯的客户端库。官网:http://www.rabbitmq.com/
RabbidMQ是一个消息代理:它接受和转发消息。你可以把它想象成一个邮局:当你把你想要寄出的邮件放在一个邮箱里时,你可以确定,邮递员先生或女士最终会把邮件交给你的收件人。
在这个类比中,rabbitmq是一个邮箱、一个邮局和一个邮递员。
帮助文档:http://www.rabbitmq.com/getstarted.html
2、安装
Erlang与RabbitMQ,安装路径都应不含空格符。

3、测试
3.1、启用管理插件
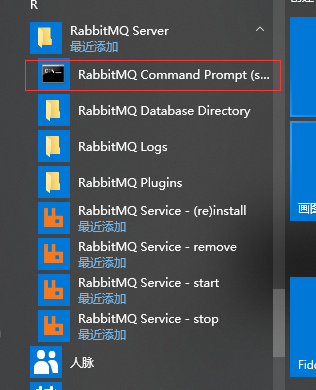
3.2、管理界面
打开浏览器输入:http://127.0.0.1:15672/
通过默认账户 guest/guest 登录,如果能够登录,说明安装成功。
添加Admin用户
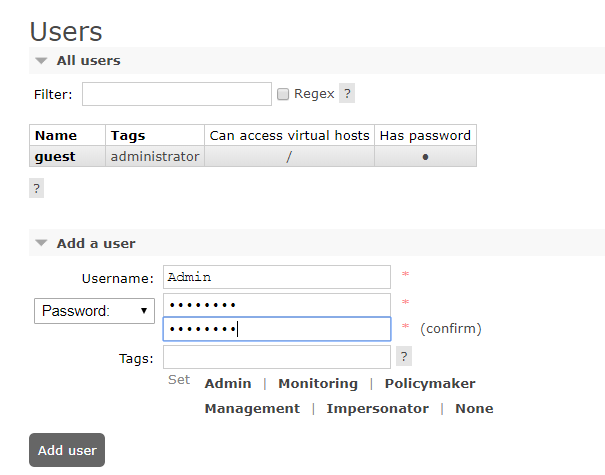
添加用户角色
1、超级管理员(administrator)
可登陆管理控制台,可查看所有的信息,并且可以对用户,策略(policy)进行操作。
2、监控者(monitoring)
可登陆管理控制台,同时可以查看rabbitmq节点的相关信息(进程数,内存使用情况,磁盘使用情况等)
3、策略制定者(policymaker)
可登陆管理控制台, 同时可以对policy进行管理。但无法查看节点的相关信息(上图红框标识的部分)。
4、普通管理者(management)
仅可登陆管理控制台,无法看到节点信息,也无法对策略进行管理。
5、其他
无法登陆管理控制台,通常就是普通的生产者和消费者。
添加角色testhost
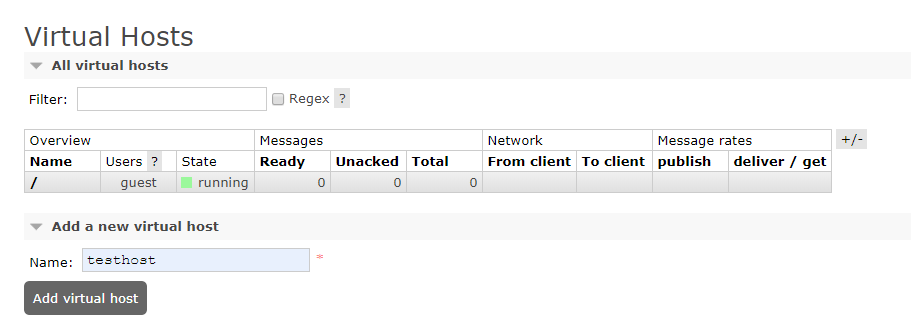
选中Admin用户,设置权限:
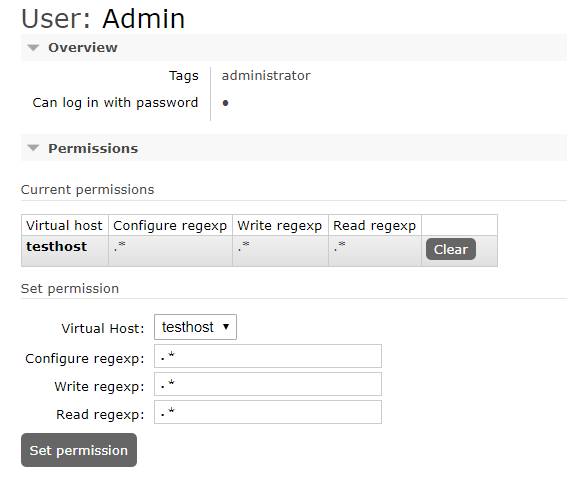
看到权限已加:
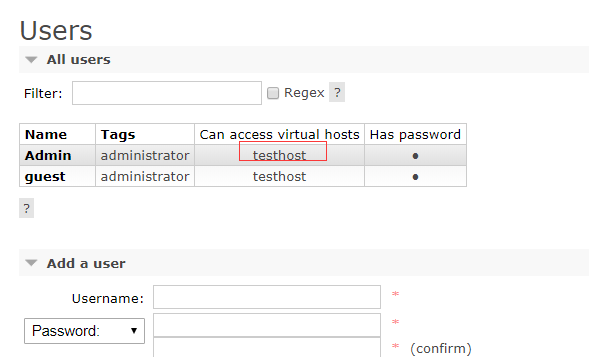
4、测试实例
安装pika模块,python使用rabbitmq服务,可以使用现成的类库pika、txAMQP或者py-amqplib,这里选择了pika。在命令行中直接使用pip命令:pip install pika
队列是位于rabbitmq中的邮箱的名称。尽管消息通过rabbitmq和在程序中传送,但它们只能存储在队列中。队列只受主机内存和磁盘限制的约束,
它本质上是一个大的消息缓冲区。许多生产者可以向一个队列发送消息,许多消费者可以尝试从一个队列接收数据。
请注意:生产者、消费者和代理不必驻留在同一主机上;实际上,在大多数应用程序中,它们不必驻留在同一主机上。应用程序也可以同时是生产者和消费者。
在本文章中,使用python编写两个小程序:一个发送单个消息的生产者(发送者)和一个接收并打印消息的消费者(接收者)。这是一个信息传递的“你好世界”。
在下图中,“P”是我们的生产者,“C”是我们的消费者。中间的框是一个队列-一个消息缓冲区,rabbitmq代表使用者保留该缓冲区。
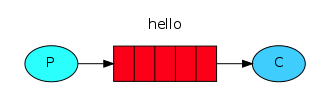
生产者将消息发送到“hello”队列。消费者从该队列接收消息。
4.1、发送
我们的第一个程序send.py将向队列发送一条消息。我们需要做的第一件事是与rabbitmq服务器建立连接。
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
我们现在已经连接到本地机器上的一个代理,因此就是本地主机。如果我们想连接到另一台机器上的代理,我们只需在这里指定它的名称或IP地址。
接下来,在发送之前,我们需要确保收件人队列存在。如果我们向不存在的位置发送消息,rabbitmq将只删除该消息。让我们创建一个Hello队列,将消息传递到该队列:
channel.queue_declare(queue='hello')
此时,准备发送消息。第一条消息将只包含一个字符串hello world!把它发送到问候队列。
在rabbitmq中,消息永远不能直接发送到队列,它总是需要通过一个交换。但不要被这些细节拖累。现在需要知道的只是如何使用由空字符串标识的默认交换。
此交换是特殊的它允许我们精确地指定消息应该进入哪个队列。队列名称需要在路由routing_key参数中指定:
channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
在退出程序之前,需要确保网络缓冲区已刷新,并且消息实际上已传递到rabbitmq。此时可以轻轻地关闭连接。
connection.close()
如果这是您第一次使用rabbitmq,并且您没有看到“已发送”消息,那么您可能会感到头疼,想知道可能出了什么问题。可能代理启动时没有足够的可用磁盘空间(默认情况下,它需要至少200 MB的可用空间),
因此拒绝接受消息。检查代理日志文件以确认并在必要时降低限制。配置文件文档将向您展示如何设置。
4.2、接收
我第二个程序receive.py将接收来自队列的消息,并将它们打印到屏幕上。同样,首先我们需要连接到rabbitmq服务器。负责连接到Rabbit的代码与以前相同。
下一步和前面一样,是确保队列存在。使用queue_declare创建队列是等幂的,我们可以根据需要多次运行该命令,并且只创建一个队列。
channel.queue_declare(queue='hello')
您可能会问我们为什么要再次声明队列我们已经在以前的代码中声明了队列。如果我们确定队列已经存在,就可以避免这种情况。例如,如果send.py程序以前运行过。但我们还不确定先运行哪个程序。
在这种情况下,最好在两个程序中重复声明队列。
如果希望看到rabbitmq有哪些队列以及其中有多少消息。可以使用rabbitmqctl工具(作为特权用户)执行此操作:
在linux上:sudo rabbitmqctl list_queues
在windows上:rabbitmqctl.bat list_queues
从队列接收消息更加复杂。它通过向队列订阅回调函数来工作。每当我们收到一条消息,这个回调函数就会被PIKA库调用。在我们的示例中,此函数将在屏幕上打印消息的内容。
def callback(ch, method, properties, body):
print(" [x] Received %r" % body)
接下来,我们需要告诉rabbitmq这个特定的回调函数应该从hello队列接收消息:
channel.basic_consume(callback,
queue='hello',
no_ack=True)
要使该命令成功,我们必须确保要订阅的队列存在。幸运的是,我们相信我们已经使用上面queue declare创建了的队列。
最后,我们进入一个永不结束的循环,它等待数据并在必要时运行回调。
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
完整的send.py代码
#!/usr/bin/env python
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel() channel.queue_declare(queue='hello') channel.basic_publish(exchange='',
routing_key='hello',
body='Hello World!')
print(" [x] Sent 'Hello World!'")
connection.close()
完整的receive.py代码
#!/usr/bin/env python
import pika connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel() channel.queue_declare(queue='hello') def callback(ch, method, properties, body):
print(" [x] Received %r" % body) channel.basic_consume(callback,
queue='hello',
no_ack=True) print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
现在我们可以在终端上试用我们的程序。首先,让我们启动一个消费者,它将连续运行等待交付:
python receive.py
send.py
RbbitMQ消息队列及python实现的更多相关文章
- RabbitMq 消息队列 在Python端的应用
https://www.cnblogs.com/Xuuuuuu/p/10895552.html rabbit_server持久化,消费者端手动确认保证消息不会丢失.具体代码如下: 1对1生产者端代码: ...
- Python操作rabbitmq消息队列持久化
消息队列持久化 Python操作rabbit消息队列的持久化,如下: # 创建一个名为balance的队列,对queue进行durable持久化设为True(持久化第一步)channel.queue_ ...
- python之消息队列
引言 你是否遇到过两个(多个)系统间需要通过定时任务来同步某些数据?你是否在为异构系统的不同进程间相互调用.通讯的问题而苦恼.挣扎?如果是,那么恭喜你,消息服务让你可以很轻松地解决这些问题.消息服务擅 ...
- Python进阶【第二篇】多线程、消息队列queue
1.Python多线程.多进程 目的提高并发 1.一个应用程序,可以有多进程和多线程 2.默认:单进程,单线程 3.单进程,多线程 IO操作,不占用CPU python的多线程:IO操作,多线程提供并 ...
- python 操作消息队列
图示 其中P指producer,即生产者:C指consumer,即消费者.中间的红色表示消息队列,实例中表现为HELLO队列. 往队列里插入数据前,查看消息队列 $sudo rabbitmqctl l ...
- python【第十一篇】消息队列RabbitMQ、缓存数据库Redis
大纲 1.RabbitMQ 2.Redis 1.RabbitMQ消息队列 1.1 RabbitMQ简介 AMQP,即Advanced Message Queuing Protocol,高级消息队列协议 ...
- python消息队列snakemq使用总结
Python 消息队列snakemq总结 最近学习消息总线zeromq,在网上搜了python实现的消息总线模块,意外发现有个消息队列snakemq,于是拿来研究一下,感觉还是很不错的,入手简单使用也 ...
- python多进程之间的通信:消息队列Queue
python中进程的通信:消息队列. 我们知道进程是互相独立的,各自运行在自己独立的内存空间. 所以进程之间不共享任何变量. 我们要想进程之间互相通信,传送一些东西怎么办? 需要用到消息队列!! 进程 ...
- Python并发编程-RabbitMQ消息队列
RabbitMQ队列 RabbitMQ是一个在AMQP基础上完整的,可复用的企业消息系统.他遵循Mozilla Public License开源协议. MQ全称为Message Queue, 消息队列 ...
随机推荐
- http--tomcat--memcached配置
两个tomcat节点:172.16.100.7(tomcatA.magedu.com),172.16.100.8(tomcatB.magedu.com) 两个memcached节点:172.16.10 ...
- ifconf家族命令
1 ifconfig 命令: ifconfig 命令用来查看和配置网络设备.当网络环境发生改变时可通过此命令对网络进行相应的配置. 查看: ifconfig : 显示正在激活中的网卡 ifconfi ...
- Berlekamp-Massey算法简单介绍
请阅读本文的同学们注意:之前这篇博客和所附代码有点问题,求的不一定是最短递推式,非常抱歉 看毛爷爷的论文大概断断续续看了一个月了,看得不是很懂,google了一波好像很快就看懂了,就先口胡一下这个算法 ...
- 070 DStream中的transform和foreachRDD函数
1.说明 DStream的API不够满足使用的时候,可以使用这两个函数,将dstream转换为rdd,然后进行操作 2.transform transform:将DStream的操作转换为RDD的操作 ...
- 《第六周java学习笔记》
教材知识点总结 Java 把 String 类定义为 final 类. new 运算符首先分配内存空间并在内存空间中放入字符序列,然后计算出引用.(new String(char a[],int st ...
- Python “No module named” 以及在Python2中可以导入,但在python3中却出现的原因
Python “No module named” 以及在Python2中可以导入,但在python3中却出现的原因 原因之1: 例如有这样的一个包和它的模块: Test __init__.py Mod ...
- Gym 100342J Triatrip (求三元环的数量) (bitset优化)
<题目链接> 题目大意:用用邻接矩阵表示一个有向图,现在让你求其中三元环的数量. 解题分析:先预处理得到所有能够直接到达每个点的集合$arrive[N]$和所有能够由当前点到达的集合$to ...
- POJ 3177 Redundant Paths (边双连通+缩点)
<题目链接> <转载于 >>> > 题目大意: 有n个牧场,Bessie 要从一个牧场到另一个牧场,要求至少要有2条独立的路可以走.现已有m条路,求至少要新 ...
- php mysql 编码问题
php mysql 编码问题 问题: PHP从数据库中读取数据,并echo出来,数据中文显示正常:但是echo出新定义的中文字符串,新定义的字符串会乱码. 由此可能是数据库中提取出来的中文编码和php ...
- PostgreSQL 调用存储过程返回结果集
创建返回结果集类型的存储过程: CREATE OR REPLACE FUNCTION public.f_get_member_info( id integer, productname charact ...