Hadoop经典案例(排序&Join&topk&小文件合并)
①自定义按某列排序,二次排序
writablecomparable中的compareto方法

②topk
a利用treemap,缺点:map中的key不允许重复:https://blog.csdn.net/u010660276/article/details/50967054
b封装mapper<key,value>中的key实现writablecompareable接口,实现排序https://blog.csdn.net/lzm1340458776/article/details/43228191
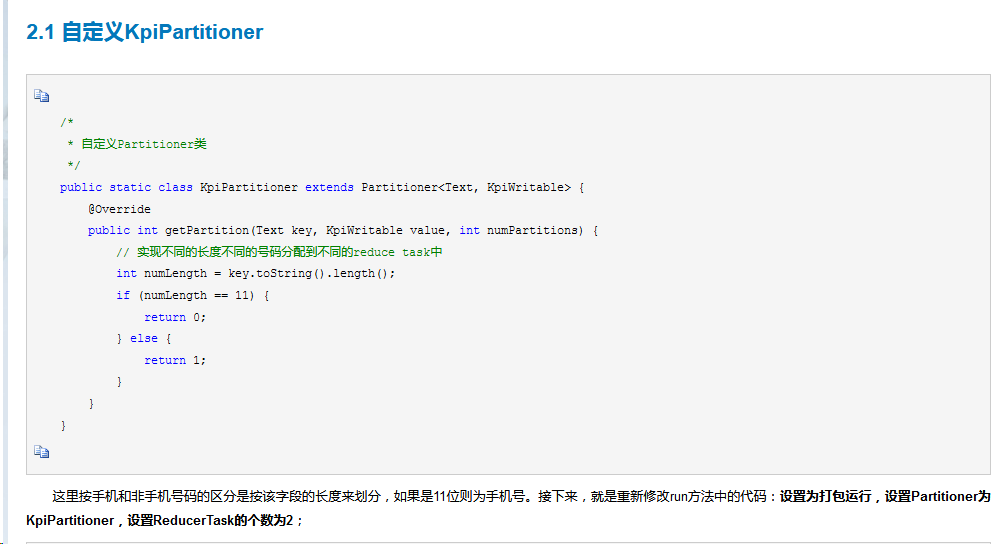
③自定义分区函数:实现按省份输出信息
分区的目的:将相同的key值放到一个reduce中处理,将reduce处理完的数据按key分别存到不同的文件中
④数据去重
由于在map阶段之后会将相同key的value分组,分组之后的每一个key都是唯一的,消除数据去重时可以将数据直接作为map的key然后输出,map之后就会是唯一的,在reduce阶段直接输出就可。
⑤常用的输入格式:https://blog.csdn.net/u011812294/article/details/63262624
⑥mapreduce中的join:map端join和reduce端join(将需要连接操作的表同时或者选择小的加载到内存中)
map端join和reduce端join举例:https://blog.csdn.net/litianxiang_kaola/article/details/71598632
https://blog.csdn.net/guxin0729/article/details/84035513
map端join:在map的setup()中将小的表加入hashmap中,(指定小表path将表存入话说hashmap中)(在setup中读取小文件)
map()中实现读取一行将条件去匹配hashmap中的值,构造join表类
在main()中只需要指定inputmapperpath为map()中需要读取的大文件即可
reduce端join:mapper中将条件作为key,join的类为value
reducer中创建ArrayList,然后实现join
两者的对比:https://blog.csdn.net/weixin_39979119/article/details/85041438
如何选择:
reduce端join,当两个文件的大小差距较大时,会产生数据倾斜,在reducer中需要结合List
map端join,仅适用于大小表或者小小表关联
⑦小文件合并
Hadoop经典案例(排序&Join&topk&小文件合并)的更多相关文章
- hadoop 将HDFS上多个小文件合并到SequenceFile里
背景:hdfs上的文件最好和hdfs的块大小的N倍.如果文件太小,浪费namnode的元数据存储空间以及内存,如果文件分块不合理也会影响mapreduce中map的效率. 本例中将小文件的文件名作为k ...
- Hadoop MapReduce编程 API入门系列之小文件合并(二十九)
不多说,直接上代码. Hadoop 自身提供了几种机制来解决相关的问题,包括HAR,SequeueFile和CombineFileInputFormat. Hadoop 自身提供的几种小文件合并机制 ...
- Hadoop案例(六)小文件处理(自定义InputFormat)
小文件处理(自定义InputFormat) 1.需求分析 无论hdfs还是mapreduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件的场景,此时,就需要有相应解决方案.将多个小文件合并 ...
- hadoop经典案例
hadoop经典案例http://blog.csdn.net/column/details/sparkhadoopdemo.html
- MR案例:小文件合并SequeceFile
SequeceFile是Hadoop API提供的一种二进制文件支持.这种二进制文件直接将<key, value>对序列化到文件中.可以使用这种文件对小文件合并,即将文件名作为key,文件 ...
- hive小文件合并设置参数
Hive的后端存储是HDFS,它对大文件的处理是非常高效的,如果合理配置文件系统的块大小,NameNode可以支持很大的数据量.但是在数据仓库中,越是上层的表其汇总程度就越高,数据量也就越小.而且这些 ...
- HDFS操作及小文件合并
小文件合并是针对文件上传到HDFS之前 这些文件夹里面都是小文件 参考代码 package com.gong.hadoop2; import java.io.IOException; import j ...
- Hive merge(小文件合并)
当Hive的输入由非常多个小文件组成时.假设不涉及文件合并的话.那么每一个小文件都会启动一个map task. 假设文件过小.以至于map任务启动和初始化的时间大于逻辑处理的时间,会造成资源浪费.甚至 ...
- hive优化之小文件合并
文件数目过多,会给HDFS带来压力,并且会影响处理效率,可以通过合并Map和Reduce的结果文件来消除这样的影响: set hive.merge.mapfiles = true ##在 map on ...
随机推荐
- nlp底层技术列举
其实目前除了之前博客写到的一些关于自然语言处理用到的知识点之外,很多其他nlp技术只是会用但是不了解原理,先整体分个类,之后再仔细分析吧. 上图是https://www.sohu.com/a/1386 ...
- python框架之Django(5)-O/RM
字段&参数 字段与db类型的对应关系 字段 DB Type AutoField integer AUTO_INCREMENT BigAutoField bigint AUTO_INCREMEN ...
- 【Mac】-NO.100.Mac.1.java.1.001-【Mac Install multiple JDK】-
Style:Mac Series:Java Since:2018-09-10 End:2018-09-10 Total Hours:1 Degree Of Diffculty:5 Degree Of ...
- EasyUI中使用textbox赋值,setValue和setText顺序问题
注意两点: 当text和value的值不同时,一定要先赋值Value,然后赋值Text,否则text和value全部为Value的值. 如果只setValue,则使用getText和getValue得 ...
- 剑指offer(34)第一个只出现一次的字符
题目描述 在一个字符串(1<=字符串长度<=10000,全部由字母组成)中找到第一个只出现一次的字符,并返回它的位置 题目分析 只需要用map记录字符出现的次数就行,比较简单的题 代码 f ...
- vijos 1605 双栈排序 - 贪心 - 二分图
题目传送门 传送门I 传送门II 题目大意 双栈排序,问最小字典序操作序列. 不能发现两个数$a_{j}, a_{k}\ \ (j < k)$不能放在同一个栈的充分必要条件时存在一个$i$使得$ ...
- ARM基础
ARM汇编:(APCS过程调用标准) 汇编:用助记符(如$ # .)代替操作码,用地址符号或标签代替地址码的编程语言 特点: 优点:可以直接访问硬件,目标代码简短,执行速度快(CPU启动时需要直接操作 ...
- SpringBoot执行定时任务
1.在启动类中加入@EnableScheduling来开启定时任务. package com.example.demo; import org.springframework.boot.SpringA ...
- 20175312 2018-2019-2 《Java程序设计》第3周学习总结
20175312 2018-2019-2 <Java程序设计>第3周学习总结 教材学习内容总结 已依照蓝墨云班课的要求完成了第四章的学习,主要的学习渠道是PPT,和书的课后习题. 总结如下 ...
- leetcode 编译问题:Line x: member access within null pointer of type 'struct TreeNode'
参考: LEETCODE 中的member access within null pointer of type 'struct ListNode' 解决 leetcode 编译问题:Line x: ...