[译]ElasticSearch vs. Solr
在Gen2产品的早期阶段, 我们事实上是失败的, 这促使我们重新审视我们现有的技术栈. 我们仔细分析系统中的每个独立的组件,并记录下来, 当然其中也包括构成我们核心功能的搜索引擎技术.
在我们的通用日志管理系统场景中, 提供了对每条单独日志事件的查询以及对所有日志事件的分析图表以帮助客户他们了解他们的数据动态. 解决这些场景的基本要求如下:
一个可扩展且高容错能力的日志收集管道. 我们团队使用了Apache Kafka作为数据管道;需要强调的是如果你需要为任何一个搜索引擎订阅大量数据, 你需要一个稳定的管道系统.
强大的搜索能力: 能给大量的数据提供准实时的索引支持, 同时也能提供高可用的搜索请求.
在我们的第一代产品Gen1(2010)时, 我们使用了当时具有云处理能力并且提供NRT(near real-time)搜索功能的Solr, 刚好Solr的这两项功能正是我们所需要的. 起初基于第一版具有云能力支持的Solr分支开始了我们系统的构建. 由于一些原因, 稳定版的SolrCloud + NRT功能直到2012年才基本可用. 那段时间, 我们通过插件和直接修改源代码的形式持续扩展和使用Solr.
在2012年, 我们准备启动Gen2, 当时SolrCloud4.0刚刚发布, 同时ElasticSearch也有了0.19.9版本. 在技术调研的时候,我是Solr技术的强烈支持者, 然而经过几个月的对比, 我终于意识到ElasticSearch才是我们更好的选择.
在任何技术选型过程中, 总有很多考虑因素. 下面是当时促使我们选择ElasticSearch的一些重要考虑. 不过这些总结是基于2012年时候的场景, 最近几年可能已经发生了翻天覆地的变化.
1) 搜索特性
因为ES和Solr都是基于Lucene构建, 所以无论选择哪个都能提供我们所需要的搜索特性. 然而因为每个系统的发展历程及其设计目标又让我们必须面对和区分他们的强项和不足.
Solr的设计目标主要是为了解决困难的信息检索(IR: information retrieval)问题. 这也反映在它的API设计上, 比ES提供了更强大的搜索能力. ES, 如其名称所述, 主要是定位在弹性扩展能力, 因此在IR特性上稍有欠缺. 就我们的业务场景, 并不需要立即使用这些复杂的高级特性. 尽管Solr具有更好的搜索技术优势, 然而ES满足了我们当前的需求并因此胜出.
2) 搜索扩展性
因为在Gen1中已经使用了Solr, 所以我们有能力对Solr进行扩展, 并且掌握了如何管理以及Solr在这方面的一些限制. ES有所不同, 我们必须验证它的扩展能力可以满足我们的需求.
我们开始为每个系统各部署一个集群, 并通过加载大量的数据进行极限测试, 以及通过强制关停部分节点以观察每个系统的表现. 那个时候, 我们就像一群捣乱的猴子.
在测试中发现SolrCloud最大的问题在于它的集群管理能力. 同时在内存不足时, SolrCound也面临着稳定性的稳定. 另外还遇到了集群锁定(lock-up)问题, 只能整个集群的重启才能解决. 与此同时, 同样的场景下ES并未遇到不可恢复的失败. 虽然也有办法能让ES丢失数据, 但我们清楚的知道什么时候会发生, 并能有办法解决这些问题.
3)配置管理
在Gen1中, 我们耗费了大量的精力来处理Solr的配置管理,包括数据流向以及索引和分片的管理等. 当时我们通过一系统的插件以及源代码修改来处理的.虽然这项技术挑战让人兴奋, 但我们并不想在这上面耗费太多时间, 而是把更多的精力放在产品差异化上: 更好的展示通过引擎获取和分析后的结果, 并给客户提供更好的数据内涵.
毫无疑问, ES赢得了这项比较. 因为ES团队对灵活性的追求几近疯狂. 具体如下:
Solr的Collections API是最新提供的,并且非常简陋.而ES则提供了原生的, 稳定的索引管理功能.
Solr和ES都默认提供了合理的分片分配策略, 但ES的路由框架相比Solr的Collections API更强大可靠.
我们曾讨论过ES的Master/Slave模型是否不如Solr的分布式模型,事实上功能实现的质量远比完美的理论更重要.
4) 性能
尽管ES和Solr都基于Lucene, 但在我们的性能测试过程中发现了他们在使用方式上的不同. 在索引速度上, Solr无疑更高效, 如下图所示:
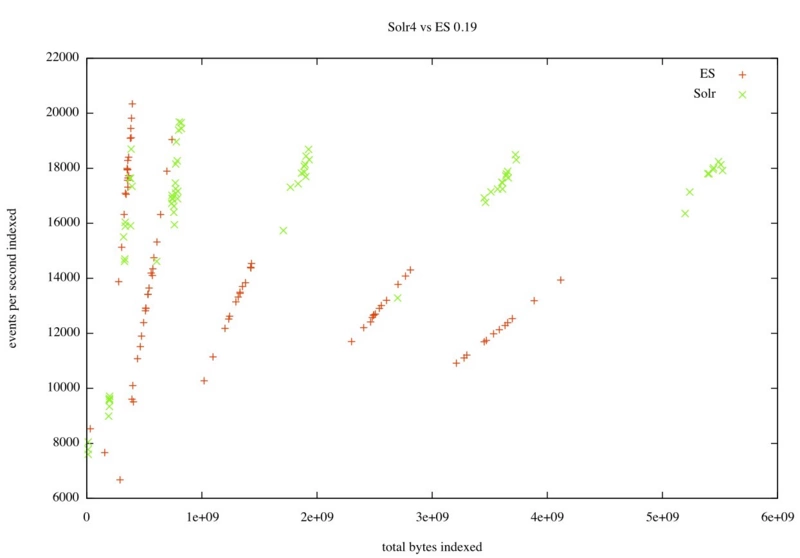
上图中每个结点都是一组独立的测试结果, 在每一组中我们在一个固定的时间周期(2,5,10,20分钟等等)里每次批量索引8000次. 在测试结果中可以清楚的看到结果被分成了两组: Solr基本上能稳定的索引18000次/秒, 而ES在开始的时候速度相当(虽然也不太稳定), 但随着测试时间变长, ES的索引速度下降不能承受12000次/秒.
尽管看起来Solr赢了, 但很大的变数可能在于Solr使用的是Lucene4, 而ES使用的是Lucene3.6.所以很难客观的说哪个更好. 并且ES也将引入Lucene4, 所以这项差异应该也将会不复存在.
最终, 在我们的决定中性能只作为一个参考因素而非决定因素.
5) 社区支持
ES和Solr都是开源项目, 并且社区都很活跃. 我们讨论了ES和Solr的模型在理论上的不同, 更倾向于Solr的开放模型, 同时也对ES团队的管理工作印象深刻. 虽然Solr在社区的规模和活跃度上都占优势, 但ES也在快速增长,并且增长速度飞快.
6) 其他因素
我们对这两个产品还有很多讨论, 下面再简单看下其中的几个:
ES的API非常优雅强大, 并且其REST服务非常适合我们前后端分离的架构
ES的扫描和过滤特性非常有趣, 并且发现了很多可能的使用场景
都原生支持JSON数据格式, 能节省很多我们曾在Loggly Gen1中写的代码
ES的类型自动解析和Solr的动态字段都非常有用, 可以避免对持续演进的输入数据的管理
Solr4原生的分层/中心模型很赞
ES的内存管理比Solr更简单
二者对插件支持都非常好, 但Solr支持更核心层的插件
还有一些我们并未固执坚持的因素, 如下;
索引一旦创建, 都不允许动态修改分片数量
ES只有单层模型, 不过也没关系
在ES中使用主分片和副本分片有数据不一致的情况, 在一个准实时系统中可能会带来潜在问题
在讨论的最后, 我们认为这些影响并不是非常严重. 随着讨论的深入, 我们更清晰的意识到哪些因素对系统具有更深的影响, 相应的这些因素被赋予了更高的权重.
我们的选择
最后, 基于以下两点, 我们选择了ES:
我们希望减少在配置管理上的精力, 更多的关注产品本身
我们相信随着ES的强大, 一些相比于Solr的不同也会逐步解决
当然这个选择也会有所付出. 虽然需要把ES配置纳入我们的管道, 并且前后端和架构团队需要实现管道管理, 但相比在Gen1中的付出, 这些都是更高层次的工作. 所以我们可以更聚焦在自己的产品本身, 这也是开始时所想要的, 也是我们的客户所需要得到的.
随着SolrCloud和ElasticSearch的成熟, 差距的缩小, 今天很难再对二者进行决择. 不过对大家来说,这确是件好事: 二者的较力驱使它们以及Lucene的不断提升.
[译]ElasticSearch vs. Solr的更多相关文章
- 搜索引擎选择: Elasticsearch与Solr
我用过这两种搜索引擎,但也仅仅是用过而已,没有非常深入研究,以下是我的看法 lucene是完全用java实现,而sphinx是支持java api.显然这两者是有差别的,用java实现的意义在于,你可 ...
- ElasticSearch 与 Solr 的对比测试
ElasticSearch 与 Solr 的对比测试 本文从两个方面对ElasticSearch和Solr进行对比,从关系型数据库中的导入速度和模糊查询的速度. 单机对比 1. Solr 发布了4.0 ...
- 【转】搜索引擎选择: Elasticsearch与Solr
原文地址:http://i.zhcy.tk/blog/elasticsearchyu-solr/ Elasticsearch简介 Elasticsearch是一个实时的分布式搜索和分析引擎.它可以帮助 ...
- Elasticsearch与Solr
公司之前有个用Lucene实现的伪分布式项目,实时性很差,后期数据量逐渐增大的时候,数据同步一次需要十几小时.当时项目重构考虑到的是Solr和ES,我参与的是Solr技术的预研.因为项目实时性要求很高 ...
- ElasticSearch和solr的差别
Elasticsearch简介 Elasticsearch是一个实时分布式搜索和分析引擎.它让你以前所未有的速度处理大数据成为可能.它用于全文搜索.结构化搜索.分析以及将这三者混合使用:维基百科使用E ...
- 全文检索选择-------- Elasticsearch与Solr
Elasticsearch简介* Elasticsearch是一个实时的分布式搜索和分析引擎.它可以帮助你用前所未有的速度去处理大规模数据. 它可以用于全文搜索,结构化搜索以及分析,当然你也可以将这三 ...
- 全文搜索引擎 ElasticSearch 还是 Solr?
最近项目组安排了一个任务,项目中用到了全文搜索,基于全文搜索 Solr,但是该 Solr 搜索云项目不稳定,经常查询不出来数据,需要手动全量同步,而且是其他团队在维护,依赖性太强,导致 Solr 服务 ...
- 搜索引擎选择: Elasticsearch与Solr(转)
搜索引擎选型调研文档 Elasticsearch简介* Elasticsearch是一个实时的分布式搜索和分析引擎.它可以帮助你用前所未有的速度去处理大规模数据. 它可以用于全文搜索,结构化搜索以及分 ...
- ElasticSearch vs Solr多维度分析对比
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
随机推荐
- ligbox 插件介绍
浏览器支持情况:一般情况都支持.最好是jQuery v1.x + lightbox.js,这样的组合IE6,IE7,IE8也支持! 1 light插件的下载地址:https://pan.baidu.c ...
- C# WinForm窗体及其控件的自适应
3步骤: 1.在需要自适应的Form中实例化全局变量 AutoSizeFormClass.cs源码在下方 AutoSizeFormClass asc = new AutoSizeFormClass ...
- Spark 基础之SQL 快速上手
知识点 SQL 基本概念 SQL Context 的生成和使用 1.6 版本新API:Datasets 常用 Spark SQL 数学和统计函数 SQL 语句 Spark DataFrame 文件保存 ...
- 安装php调试工具 Xdebug的步骤 火狐 phpstorm联调
一 安装服务器端 1 选择你的版本 <?php phpinfo(); ?> 比如我的: 关键是这三项:PHP Version 7.3.0Architecture x86 (x86是32位系 ...
- 利用PHPExcel导出excel 以及利用js导出excel
导出excel的方法output_excel需要依赖PHPExcel 导出csv的方法csv_export不需要 <?php /** * @author ttt */ class ExcelCo ...
- mysql学习笔记--数据操作
一.插入数据 1. 语法:insert into 表名 (字段名.字段名,...) values (值1,值2...) 2. 注意: a. 插入字段的个数和顺序与值的个数和顺序必须一致 b. 通过de ...
- 记录----第一次使用BFS(广度搜索)学习经验总结
学习经验记录与分享—— 最近在学习中接触到了一种解决最短路径的实用方法----BFS(广度搜索),在这里总结并分享一下第一次学习的经验. 首先第一个要了解的是"queue"(队列函 ...
- 516. Longest Palindromic Subsequence最长的不连续回文串的长度
[抄题]: Given a string s, find the longest palindromic subsequence's length in s. You may assume that ...
- java 远程debug
在启动jar包添加如下参数16091是端口 java -Xdebug -Xrunjdwp:transport=dt_socket,address=16091,server=y,suspend=n -j ...
- Python开发——数据类型【字符串】
字符串定义 字符串是一个有序的字符的集合,用于存储和表示基本的文本信息 在Python中加了引号的字符,都被认为是字符串! 单引号.双引号.多引号之间的区别? 答案:单双引号没有区别 多引号的作用? ...