神经网络和误差逆传播算法(BP)
本人弱学校的CS 渣硕一枚,在找工作的时候,发现好多公司都对深度学习有要求,尤其是CNN和RNN,好吧,啥也不说了,拿过来好好看看。以前看习西瓜书的时候神经网络这块就是一个看的很模糊的块,包括台大的视频,上边有AutoEncoder,感觉很乱,所以总和了各种博客,各路大神的知识,总结如果,如有问题,欢迎指出。
1 人工神经网络
1.1 神经元
神经网络由大量的神经元相互连接而成。每个神经元接受线性组合的输入后,最开始只是简单的线性加权,后来给每个神经元加上了非线性的激活函数,从而进行非线性变换后输出。每两个神经元之间的连接代表加权值,称之为权重(weight)。不同的权重和激活函数,则会导致神经网络不同的输出。
举个手写识别的例子,给定一个未知数字,让神经网络识别是什么数字。此时的神经网络的输入由一组被输入图像的像素所激活的输入神经元所定义。在通过非线性激活函数进行非线性变换后,神经元被激活然后被传递到其他神经元。重复这一过程,直到最后一个输出神经元被激活。从而识别当前数字是什么字。
神经网络的每个神经元如下

基本wx + b的形式,其中
、
表示输入向量
、
为权重,几个输入则意味着有几个权重,即每个输入都被赋予一个权重
b为偏置bias
g(z) 为激活函数
a 为输出
如果只是上面这样一说,估计以前没接触过的十有八九又必定迷糊了。事实上,上述简单模型可以追溯到20世纪50/60年代的感知器,可以把感知器理解为一个根据不同因素、以及各个因素的重要性程度而做决策的模型。
举个例子,这周末北京有一草莓音乐节,那去不去呢?决定你是否去有二个因素,这二个因素可以对应二个输入,分别用x1、x2表示。此外,这二个因素对做决策的影响程度不一样,各自的影响程度用权重w1、w2表示。一般来说,音乐节的演唱嘉宾会非常影响你去不去,唱得好的前提下 即便没人陪同都可忍受,但如果唱得不好还不如你上台唱呢。所以,我们可以如下表示:
这样,咱们的决策模型便建立起来了:g(z) = g(
一开始为了简单,人们把激活函数定义成一个线性函数,即对于结果做一个线性变化,比如一个简单的线性激活函数是g(z) = z,输出都是输入的线性变换。后来实际应用中发现,线性激活函数太过局限,于是人们引入了非线性激活函数。
1.2 激活函数
常用的非线性激活函数有sigmoid、tanh、relu等等,前两者sigmoid/tanh比较常见于全连接层,后者relu常见于卷积层。这里先简要介绍下最基础的sigmoid函数(btw,在本博客中SVM那篇文章开头有提过)。
sigmoid的函数表达式如下

其中z是一个线性组合,比如z可以等于:b +
因此,sigmoid函数g(z)的图形表示如下( 横轴表示定义域z,纵轴表示值域g(z) ):

也就是说,sigmoid函数的功能是相当于把一个实数压缩至0到1之间。当z是非常大的正数时,g(z)会趋近于1,而z是非常小的负数时,则g(z)会趋近于0。
压缩至0到1有何用处呢?用处是这样一来便可以把激活函数看作一种“分类的概率”,比如激活函数的输出为0.9的话便可以解释为90%的概率为正样本。
举个例子,如下图(图引自Stanford机器学习公开课)

z = b +
如果
如果
如果
换言之,只有
1.3 神经网络
将下图的这种单个神经元

组织在一起,便形成了神经网络。下图便是一个三层神经网络结构

上图中最左边的原始输入信息称之为输入层,最右边的神经元称之为输出层(上图中输出层只有一个神经元),中间的叫隐藏层。
啥叫输入层、输出层、隐藏层呢?
输入层(Input layer),众多神经元(Neuron)接受大量非线形输入讯息。输入的讯息称为输入向量。
输出层(Output layer),讯息在神经元链接中传输、分析、权衡,形成输出结果。输出的讯息称为输出向量。
隐藏层(Hidden layer),简称“隐层”,是输入层和输出层之间众多神经元和链接组成的各个层面。如果有多个隐藏层,则意味着多个激活函数。
同时,每一层都可能由单个或多个神经元组成,每一层的输出将会作为下一层的输入数据。比如下图中间隐藏层来说,隐藏层的3个神经元a1、a2、a3皆各自接受来自多个不同权重的输入(因为有x1、x2、x3这三个输入,所以a1 a2 a3都会接受x1 x2 x3各自分别赋予的权重,即几个输入则几个权重),接着,a1、a2、a3又在自身各自不同权重的影响下 成为的输出层的输入,最终由输出层输出最终结果。

上图(图引自Stanford机器学习公开课)中
表示第j层第i个单元的激活函数/神经元
表示从第j层映射到第j+1层的控制函数的权重矩阵
此外,输入层和隐藏层都存在一个偏置(bias unit),所以上图中也增加了偏置项:x0、a0。针对上图,有如下公式

此外,上文中讲的都是一层隐藏层,但实际中也有多层隐藏层的,即输入层和输出层中间夹着数层隐藏层,层和层之间是全连接的结构,同一层的神经元之间没有连接。

2 误差逆传播算法(BP)
由上面可以得知:神经网络的学习主要蕴含在权重和阈值中,多层网络使用上面简单感知机的权重调整规则显然不够用了,BP神经网络算法即误差逆传播算法(error BackPropagation)正是为学习多层前馈神经网络而设计,BP神经网络算法是迄今为止最成功的的神经网络学习算法。
一般而言,只需包含一个足够多神经元的隐层,就能以任意精度逼近任意复杂度的连续函数[Hornik et al.,1989],故下面以训练单隐层的前馈神经网络为例,介绍BP神经网络的算法思想。

上图为一个单隐层前馈神经网络的拓扑结构,BP神经网络算法也使用梯度下降法(gradient descent),以单个样本的均方误差的负梯度方向对权重进行调节。可以看出:BP算法首先将误差反向传播给隐层神经元,调节隐层到输出层的连接权重与输出层神经元的阈值;接着根据隐含层神经元的均方误差,来调节输入层到隐含层的连接权值与隐含层神经元的阈值。BP算法基本的推导过程与感知机的推导过程原理是相同的,下面给出调整隐含层到输出层的权重调整规则的推导过程:





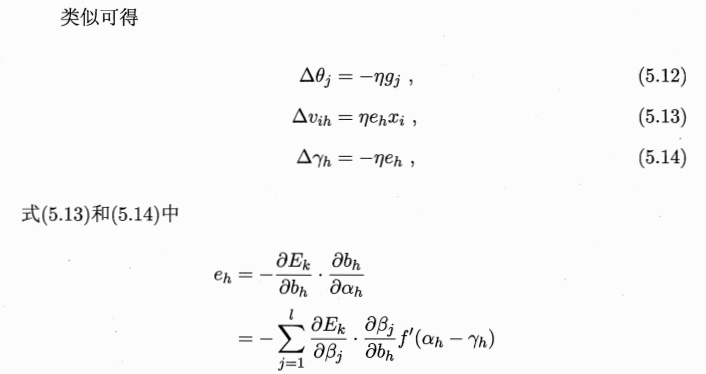
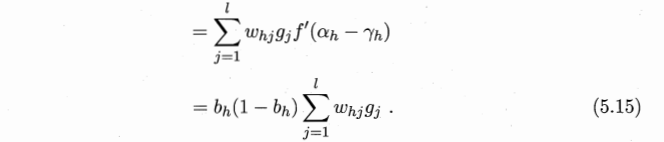

参考自:http://blog.csdn.net/zouxy09/article/details/8781543
http://m.blog.csdn.net/v_JULY_v/article/details/51812459
神经网络和误差逆传播算法(BP)的更多相关文章
- 神经网络 误差逆传播算法推导 BP算法
误差逆传播算法是迄今最成功的神经网络学习算法,现实任务中使用神经网络时,大多使用BP算法进行训练. 给定训练集\(D={(x_1,y_1),(x_2,y_2),......(x_m,y_m)} ...
- BP(back propagation)误差逆传播神经网络
[学习笔记] BP神经网络是一种按误差反向传播的神经网络,它的基本思想还是梯度下降法,中间隐含层的误差和最后一层的误差存在一定的数学关系,(可以计算出来),就像误差被反向传回来了,所以顾名思义BP.想 ...
- MATLAB神经网络(3) 遗传算法优化BP神经网络——非线性函数拟合
3.1 案例背景 遗传算法(Genetic Algorithms)是一种模拟自然界遗传机制和生物进化论而形成的一种并行随机搜索最优化方法. 其基本要素包括:染色体编码方法.适应度函数.遗传操作和运行参 ...
- 《深度学习-改善深层神经网络》-第二周-优化算法-Andrew Ng
目录 1. Mini-batch gradient descent 1.1 算法原理 1.2 进一步理解Mini-batch gradient descent 1.3 TensorFlow中的梯度下降 ...
- BP神经网络的数学原理及其算法实现
什么是BP网络 BP网络的数学原理 BP网络算法实现 转载请声明出处http://blog.csdn.net/zhongkejingwang/article/details/44514073 上一篇 ...
- 深度神经网络(DNN)反向传播算法(BP)
在深度神经网络(DNN)模型与前向传播算法中,我们对DNN的模型和前向传播算法做了总结,这里我们更进一步,对DNN的反向传播算法(Back Propagation,BP)做一个总结. 1. DNN反向 ...
- 神经网络与机器学习 笔记—反向传播算法(BP)
先看下面信号流图,L=2和M0=M1=M2=M3=3的情况,上面是前向通过,下面部分是反向通过. 1.初始化.假设没有先验知识可用,可以以一个一致分布来随机的挑选突触权值和阈值,这个分布选择为均值等于 ...
- 【机器学习】反向传播算法 BP
知识回顾 1:首先引入一些便于稍后讨论的新标记方法: 假设神经网络的训练样本有m个,每个包含一组输入x和一组输出信号y,L表示神经网络的层数,S表示每层输入的神经元的个数,SL代表最后一层中处理的单元 ...
- 卷积神经网络(CNN)前向传播算法
在卷积神经网络(CNN)模型结构中,我们对CNN的模型结构做了总结,这里我们就在CNN的模型基础上,看看CNN的前向传播算法是什么样子的.重点会和传统的DNN比较讨论. 1. 回顾CNN的结构 在上一 ...
随机推荐
- PHP05
php05 1.音乐案例删除部分 1)通过执行某些PHP代码获取到指定的数据,填充到html的指定位置 accept属性也可以直接写扩展名,多个扩展名间用英文的逗号分隔 accept=".l ...
- Codeforces899C Dividing the numbers(数论)
http://codeforces.com/problemset/problem/899/C tot为奇数时,绝对差为1:tot为偶数时,绝对差为0. 难点在于如何输出. #include<io ...
- 使用js冒泡实现点击空白处关闭弹窗
什么是事件冒泡? 如图:在一个对象上触发某类事件(比如单击onclick事件),这个事件会向这个对象的父级对象传播,从里到外,直至它被处理(父级对象所有同类事件都将被激活),或者它到达了对象层次的最顶 ...
- Android support 26.0.0-alpha1 产生的问题(zz)
针对以下两个错误 Java.lang.NoClassDefFoundError: Failed resolution of: Landroid/support/v4/animation/Animato ...
- 汉诺塔系列问题: 汉诺塔II、汉诺塔III、汉诺塔IV、汉诺塔V、汉诺塔VI
汉诺塔 汉诺塔II hdu1207: 先说汉若塔I(经典汉若塔问题),有三塔.A塔从小到大从上至下放有N个盘子.如今要搬到目标C上. 规则小的必需放在大的上面,每次搬一个.求最小步数. 这个问题简单, ...
- wifipineapple外接网卡上网
买了一台wifipineapple, pineapple有两种版本, 第一种是3G版本,可以外接3G上网卡, 还有一种是wifi版本, 包含一个物理的网络插槽, 我买的是第二种 wifipineapp ...
- angular 2 - 005 路由实现机制
angular2的路由是不是很神奇, url发生了变化却没有看到有任何请求发出? 1. hash模式 url类似 http://localhost:4200/#/task-list,跳转到路由页面再刷 ...
- Java编译过程(传送门)
我不是要做一门编程语言,了解这个对我现在的工作也没什么帮助,纯粹好奇而已. 传送门
- 多线程处理N维度topk问题demo--[c++]
问题 -对多维度特征进行topk排序,使用c++ 优先队列模拟最大堆. /* ---------------------------------- Version : ?? File Name : d ...
- 12C - PDB archive file
在unplug一个pdb的时候,如果将扩展名定义为.pdb,oracle就会创建一个.pdb归档文件.包含pdb数据文件和xml元数据文件的压缩文件.创建archive file之后,就不用分开拷贝数 ...