HBase多条件及分页查询的一些方法
HBase是Apache Hadoop生态系统中的重要一员,它的海量数据存储能力,超高的数据读写性能,以及优秀的可扩展性使之成为最受欢迎的NoSQL数据库之一。它超强的插入和读取性能与它的数据组织方式有着密切的关系,在逻辑上,HBase的表数据按RowKey进行字典排序, RowKey实际上是数据表的一级索引(Primary Index),由于HBase本身没有二级索引(Secondary Index)机制,基于索引检索数据只能单纯地依靠RowKey。也只有使用RowKey查询数据才能得到非常高的效率。当然,HBase也支持使用其他的字段进行查询,但是只要没有RowKey,那么都是全表扫描。试想一下,在数十亿数据中全表扫描是一种什么样的体验,查询几乎不可用。而作为数据库使用,在数据表上的多条件查询是必然的需求,本文将结合使用经验,介绍一些常规的HBase的多条件查询实现方式。
RowKey + Filter的方式
RowKey一般是必不可少的,但是如果数据量少,几十万数据,就问题不大。很多时候查询都会选择时间,如果能把时间放在RowKey里面,会极大的提升查询的效率。这里有个小技巧:如果Rowkey是按时间戳的方式递增,不要将时间放在二进制码的前面,建议将Rowkey的高位作为散列字段,由程序循环生成,低位放时间字段,这样将提高数据均衡分布在每个Regionserver实现负载均衡的几率。如果没有散列字段,首字段直接是时间信息将产生所有新数据都在一个RegionServer上堆积的热点现象,这样在做数据检索的时候负载将会集中在个别RegionServer,降低查询效率。
HBase的Scan可以通过setFilter方法添加过滤器(Filter),这也是分页、多条件查询的基础。HBase为筛选数据提供了一组过滤器,通过这个过滤器可以在HBase中的数据的多个维度(行,列,数据版本)上进行对数据的筛选操作。通常来说,通过行键,值来筛选数据的应用场景较多。这里简单举个例子,使用SingleColumnValueFilter过滤行,查找数据库中vehicle_speed列是77的数据:
FilterList filterList = new FilterList();
SingleColumnValueFilter scvf = new SingleColumnValueFilter(Bytes.toBytes("f"), Bytes.toBytes("vehicle_speed"), CompareOp.EQUAL, Bytes.toBytes("77"));
filterList.addFilter(scvf);
scan.setFilter(filterList);
ResultScanner scanner = table.getScanner(scan);
Filter是可以加多个的,HBase提供十多种Filter类型。filterList.addFilter(scvf) 就是可以添加多个查询条件,然后调用setFilter函数给Scanner。
这里再简单介绍一下分页的方式:
- client分页,scan查到N*M条,过滤掉N*M-M条,返回M条。对于M,N较小时比较适合。
- 自定义Filter,该filter可以传递offset(server端需要过滤的记录条数),在server端分页,注意,跨不同的region时需要重新计算该offset
- 缓存上次分页查询的最后一条,下次分页查询从这条(不包含)开始查。
- 查询条件固定的话,定时任务汇总表
- PageFilter
使用RowKey + Filter的方式只能满足一些查询(数据量少,或者RowKey是必须的参数),包括其分页的实现并不是最优,但这是使用原生的HBase的方法,比较简单。下面介绍的方法更好,但是依赖于其他的组件。
Coprocessor
利用Coprocessor协处理器,用户可以编写运行在 HBase Server 端的代码。HBase的Coprocessor分为两类,Observer和EndPoint。
HBase 支持两种类型的协处理器,Endpoint 和 Observer。Endpoint 协处理器类似传统数据库中的存储过程,客户端可以调用这些 Endpoint 协处理器执行一段Server 端代码,并将 Server 端代码的结果返回给客户端进一步处理。
另外一种协处理器叫做Observer Coprocessor,这种协处理器类似于传统数据库中的触发器,当发生某些事件的时候这类协处理器会被 Server 端调用。Observer Coprocessor 就是一些散布在 HBase Server 端代码中的 hook 钩子,在固定的事件发生时被调用。比如:put 操作之前有钩子函数 prePut,该函数在 put 操作执行前会被 Region Server 调用;在 put 操作之后则有 postPut 钩子函数。
使用Coprocessor来实现简单的HBase二级索引也是比较常见的方案。但是如果要使用Coprocessor进行二级索引的话,还是推荐下面成熟的方案,它其中也使用到了协处理器。
Phoenix
最早由Salesforce.com开源的Apache Phoenix 是一个Java中间层,可以让开发者在Apache HBase上执行SQL查询,目前的版本基本支持常用的操作(分页,排序,Group By,Having,函数,序列等等)。目前的Phoenix是非常成熟的解决方案,阿里、Salesforce、eBay等互联网都在广泛使用。
Phoenix完全使用Java编写,代码位于GitHub上,并且提供了一个客户端可嵌入的JDBC驱动。它查询的实时性非常高,一般查询都在秒级返回,可以应用OLTP的系统中。在用户必须通过Phoenix来建HBase的表,它会映射到HBase的表上。Phoenix可以创建索引来提升提升多条件查询HBase的效率。比如,在查询订单的时候,可以通过订单号、时间、状态等不同的维度来查询,要想把这么多角度的数据都放到RowKey中几乎不可能。而在Phoenix中,你可以针对这几个字段建立索引。在写SQL语句的时候,如果Where语句中使用到了这些条件,Phoenix就会自动判断是否走索引。
Phoenix的索引本质上也是一张HBase的表,它维护了索引和RowKey的关系。在查询的时候,它会从索引表中先找到RowKey,然后再根据RowKey再去HBase原始数据表中获取数据。关于Phoenix的二级索引在后续的文章中专门介绍。
Impala
Impala是Cloudera在受到Google的Dremel启发下开发的实时交互SQL大数据查询工具,Impala没有再使用缓慢的Hive+MapReduce批处理,而是通过使用与商用并行关系数据库中类似的分布式查询引擎(由Query Planner、Query Coordinator和Query Exec Engine三部分组成),可以直接从HDFS或HBase中用SELECT、JOIN和统计函数查询数据,从而大大降低了延迟。
Impala目前是Apache的孵化项目。Impala并非是一个OLTP系统,而更像是一个OLAP系统,更加类似于Hive。Impala不能运用在实时系统中,但是如果是针对HBase的统计或者异步查询的话不妨一试。
ElasticSearch/Solr + HBase
针对HBase使用RowKey访问超高的效率,我们可以把索引数据放在类似于ElasticSearch或者Solr这样的搜索引擎里面。用搜索引擎做二级索引。查询数据的时候先从搜索引擎中查询出RowKey,然后再用RowKey去获取数据。流行的搜索引擎基本可以满足查询的所有需求。
举个例子:订单数据项有10个,但是用于查询的有5个。当数据插入HBase的同时,也把这5个数据项加上预先生成的RowKey插入搜索引擎,也就是说部分数据存储两份。一份用于搜索,一份用于查询。大致的架构也许会是这样:
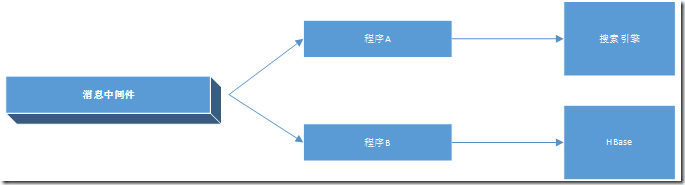
程序A和B分开主要是为了解耦和避免互相影响,当然也可以合并在一个程序里面。程序A和B也可以是类似于flume或者logstash这样的组件。
一些建议
在作者的实际经验中方案的选择还是要根据数据量和性能要求来选择。当数据量较小几十万,上百万的话可以使用RowKey+Filter的方式实现。如果数据量到了千万,甚至亿级别,可以尝试Phoenix。如果数据量到了10亿或者更多则需要选择搜索引擎。同时方案的系统维护难度和对技术的要求也是逐级递增的。
HBase多条件及分页查询的一些方法的更多相关文章
- mysq带条件的分页查询数据结果错误
记一次mysql分页条件查询的结果出错: 以一张用户表为例,首先我们看表中的所有数据,注意红色框住的部分: 我们使用不带条件的分页查询来查询,数据显示是OK的: SELECT id,login_nam ...
- Spring Data JPA 复杂/多条件组合分页查询
推荐视频: http://www.icoolxue.com/album/show/358 public Map<String, Object> getWeeklyBySearch(fina ...
- laravel 带条件的分页查询
laravel 带条件的分页查询, 原文:http://blog.csdn.net/u011020900/article/details/52369094 bug:断点查询,点击分页,查询条件消失. ...
- 【spring boot】14.spring boot集成mybatis,注解方式OR映射文件方式AND pagehelper分页插件【Mybatis】pagehelper分页插件分页查询无效解决方法
spring boot集成mybatis,集成使用mybatis拖沓了好久,今天终于可以补起来了. 本篇源码中,同时使用了Spring data JPA 和 Mybatis两种方式. 在使用的过程中一 ...
- Oracle中的SQL分页查询原理和方法详解
Oracle中的SQL分页查询原理和方法详解 分析得不错! http://blog.csdn.net/anxpp/article/details/51534006
- 序列化表单为json对象,datagrid带额外参提交一次查询 后台用Spring data JPA 实现带条件的分页查询 多表关联查询
查询窗口中可以设置很多查询条件 表单中输入的内容转为datagrid的load方法所需的查询条件向原请求地址再次提出新的查询,将结果显示在datagrid中 转换方法看代码注释 <td cols ...
- php 之 分页查询的使用方法及其类的封装
一.分页的使用: <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://ww ...
- hibernate分页查询的各种方法
统计总数: public Integer countAll1() { String hql = "select count(*) from News as news"; List ...
- Mysql中分页查询两个方法比较
mysql中分页查询有两种方式, 一种是使用COUNT(*)的方式,具体代码如下 1 2 3 SELECT COUNT(*) FROM foo WHERE b = 1; SELECT a FROM ...
随机推荐
- linux之软连接,硬连接篇
作业四: 1) 建立/etc/passwd的软连接文件,放在/tmp目录下 [root@localhost 桌面]# ln -s /etc/passwd/a.txt /tmp/aa.txt 2) 建立 ...
- angular学习笔记(6)- 指令
angular1学习笔记(6)- 指令 restrict-匹配模式 1.A - 属性 <my-menu title=Products></my-menu> 2.M - 注释 & ...
- CSS Flex布局整理
Flex布局 display: flex; 将对象作为弹性伸缩盒展示,用于块级元素 display: inline-flex; 将对象作为弹性伸缩盒展示,用于行内元素 注意兼容问题: webkit内核 ...
- SpringBoot无废话入门04:MyBatis整合
1.Parent引入及pom配置 首先,如果要支持mybatis,那么我们就应该引入mybatis的starter.同时,由于连接本身还需要用jdbc的connetor和连接池,所以一并需要引入这些依 ...
- 使用cefsharp 浏览器放大
(1)如果浏览器位置有问题,需要设置 Cef.EnableHighDPISupport(); (2)如果要放大浏览器,需要设置 browser.SetZoomLevel(1.25); Chromiu ...
- 遭遇ASP.NET的Request is not available in this context
如果ASP.NET程序以IIS集成模式运行,在Global.asax的Application_Start()中,只要访问Context.Request,比如下面的代码 var request = Co ...
- C++ 中的不定参数与格式化字符串 # ## vsprintf
日志打印或者格式字符串时,可能会用到不定参数的使用,这里记录一下. 格式化字符串有很多方法: snprintf std::stringstream # ##的使用 ##是一个连接符号,用于把参数连在一 ...
- OpenCV3 for python3 学习笔记3-----用OpenCV3处理图像一
本文的内容都与图像处理有关,这时需要修改图像,比如要使用具有艺术性的滤镜.外插(extrapolate)某些部分.分割.粘贴或其他需要的操作. 1.不同色彩空间的的转换 OpenCV有数百种关于在不同 ...
- 找回停掉docker的文件
如果容器还能重启,就restart, 如果状态是DEAD的话, Error response from daemon: Container is marked for removal and cann ...
- 一步步教你轻松学关联规则Apriori算法
一步步教你轻松学关联规则Apriori算法 (白宁超 2018年10月22日09:51:05) 摘要:先验算法(Apriori Algorithm)是关联规则学习的经典算法之一,常常应用在商业等诸多领 ...