Pandas 基础(6) - 用 replace() 函数处理不合理数据
首先, 还是新建一个 jupyter notebook, 然后引入 csv 文件(此文件我已上传到博客园):
import pandas as pd
import numpy as np
df = pd.read_csv('/Users/rachel/Sites/pandas/py/pandas/6_handling_missing_data_replace/weather_data.csv')
df
输出:
从上面的输出截图, 可以看到有很多不合理的数据, 这时可以用 replace() 函数来处理:
new_df = df.replace([-99999, -88888], np.NaN)
输出: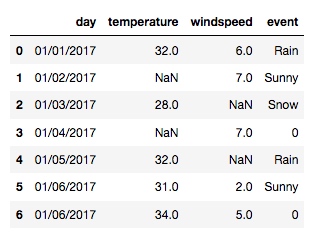
这时, 就还剩下 event 列里的 0 还没有改, 因为没办法简单粗暴地把数字 0 放到 replace 函数的数组里, 这样会影响其他列的值. 这个解决办法相信大家也都不会陌生了, 就是利用 python 的 dictionary:
new_df = df.replace({
'temperature' : -99999,
'windspeed':[-99999, -88888],
'event': '0'
}, np.NaN)
下面我们再来改下原 csv 文件, 把其中各别数据加上"单位":
如果我们想把多余的字母单位去掉, 可以用正则:
new_df = df.replace('[A-Za-z]','', regex=True)
这样替换之后, 大家可以看一眼输出结果, 发现 event 列的内容都没有了, 因为字母都被替换掉了. 所以还是要这样做:
new_df = df.replace({
'temperature': '[A-Za-z]',
'windspeed': '[A-Za-z]'
} ,'', regex=True)
下面再介绍另一个特性
首先
df = pd.DataFrame({
'score': ['exceptional', 'average', 'good', 'poor', 'average', 'exceptional'],
'student': ['rob', 'maya', 'jorge', 'tom', 'july', 'erica']
})
输出: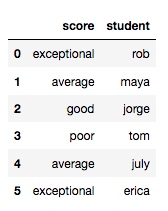
大家可以看到目前 score 列是用4个形容词来体现成绩的, 那如果想把它们按照等级换成 1-4分呢?
new_df = df.replace(['poor', 'average', 'good', 'exceptional'], [1, 2, 3, 4])
输出:
以上, 就是 replace() 函数的相关内容, enjoy~~~
Pandas 基础(6) - 用 replace() 函数处理不合理数据的更多相关文章
- python pandas replace函数
在处理数据的时候,很多时候会遇到批量替换的情况,如果一个一个去修改效率过低,也容易出错.replace()是很好的方法. 1.基本结构: df.replace(to_replace, value) 前 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- Python 数据分析(一) 本实验将学习 pandas 基础,数据加载、存储与文件格式,数据规整化,绘图和可视化的知识
第1节 pandas 回顾 第2节 读写文本格式的数据 第3节 使用 HTML 和 Web API 第4节 使用数据库 第5节 合并数据集 第6节 重塑和轴向旋转 第7节 数据转换 第8节 字符串操作 ...
- numpy&pandas基础
numpy基础 import numpy as np 定义array In [156]: np.ones(3) Out[156]: array([1., 1., 1.]) In [157]: np.o ...
- 基于 Python 和 Pandas 的数据分析(2) --- Pandas 基础
在这个用 Python 和 Pandas 实现数据分析的教程中, 我们将明确一些 Pandas 基础知识. 加载到 Pandas Dataframe 的数据形式可以很多, 但是通常需要能形成行和列的数 ...
- python学习笔记(四):pandas基础
pandas 基础 serise import pandas as pd from pandas import Series, DataFrame obj = Series([4, -7, 5, 3] ...
- pandas 基础介绍与概览
pandas是 基于NumPy数组构建的,特别是基于数组的函数和不使用for循环的数据处理 相关联的几个库, 分析库 scikit-learn 和 statsmodels 数值计算工具,NumPy 可 ...
- 数据转换--替换值(replace函数)
替换值 replace函数 data=Series([1,-999,2,-999,-1000,3]) data Out[34]: 0 1 1 -999 2 2 3 -999 4 -1000 5 3 d ...
- 数据分析02 /pandas基础
数据分析02 /pandas基础 目录 数据分析02 /pandas基础 1. pandas简介 2. Series 3. DataFrame 4. 总结: 1. pandas简介 numpy能够帮助 ...
随机推荐
- swust oj 1069
图的按录入顺序广度优先搜索 5000(ms) 10000(kb) 2347 / 4868 Tags: 广度优先 图的广度优先搜索类似于树的按层次遍历,即从某个结点开始,先访问该结 点,然后访问该结点的 ...
- loadrunner笔记(二):飞机订票系统--客户信息注册
(一) 几个重要概念说明 集合点:同步虚拟用户,以便同一时间执行任务. 事务:事务是指服务器响应用户请求所用的时间,当然它可以衡量某个操作,如登录所需要的时间,也可以衡量一系列的操作所用的时间,如从 ...
- react表单的一些小例子
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- 网页分帧操作<frameset>,<iframe>标签
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- 怎么把mkv转成mp4,有什么方法
Mkv怎样转换成MP4呢?mkv是一种开放标准的自由的容器和文件格式,是一种多媒体封装格式,能够在一个文件中容纳无限数量的视频.音频.图片或字幕轨道.所以其不是一种压缩格式,而是Matroska定义的 ...
- centos7磁盘在线扩容
1.添加新磁盘 2.fdisk -l查看磁盘被识别的名称 3.如果输入fdisk -l命令没有找到新的磁盘,按下面步骤操作 1)进入到cd /sys/class/scsi_host/ 2)echo & ...
- VBA语法总结
为了控制Excel,学了些VBA,总结下语法,下文分为五部分: 一.代码组织 二.常用数据类型 三.运算符 四.控制流 五.常用内置函数 一.代码组织 1.能写代码的地方有{模块,类模块}. 2.代码 ...
- Centos7+python3.6+face-recognition
Step1 安装Python3.6.xhttps://www.digitalocean.com/community/tutorials/how-to-install-python-3-and-set- ...
- Jmeter学习之-获取登录的oken值(2)
此篇介绍获取登录token的第二种方式--json提取器提取 PS:此方法针对接口返回值为json串格式 在登录请求上右键添加JSON提取器 ...
- pandas apply 添加进度条
Way:from tqdm import tqdmimport pandas as pdtqdm.pandas(desc='pandas bar')df['title_content'] = df.p ...