python摸爬滚打之day21---- 模块
1、MD5加密模块
MD5是一种不可逆的加密算法, 是安全而且可靠的.
在某些网站上能够搜到MD5解密工具, 其实并没有解密工具, 而是"撞库"的方式. 网站将一些MD5数据保存起来了, 在解密时通过排列组合将匹配到的信息反馈给用户.
对于这种情况, 只需要在用MD5时给加个bytes参数就OK.
import hashlib
def jiami(content):
EXTRA = b"abcdefg12345higklmn678910opqrst"
obj = hashlib.md5(EXTRA) # 额外加密
obj.update(content.encode("utf8")) # 给obj添加明文, 明文必须是bytes类型
return obj.hexdigest() # 输出obj中的密文 print(jiami("大头大头下雨不愁")) # 2bda31af1f147daf99d318c240a68824
MD5加密
2、logging日志模块
通过logging来记录日志.
用的时候直接调用就OK, 不需要去记.
import logging
file_handler = logging.FileHandler("choice_movie_age","a",encoding="utf8")
file_handler.setFormatter(logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s"))
logger = logging.Logger("脚本程序名字",level=20) # 记录级别大于等于20 的日志等级
logger.addHandler(file_handler)
logger.info("info信息....")
logging日志记录
项目中使用logging
from logging.handlers import RotatingFileHandler
def set_log():
# 设置日志的记录等级
logging.basicConfig(level="DEBUG") # 调试debug级
# 创建日志记录器,指明日志保存的路径、每个日志文件的最大大小、保存的日志文件个数上限
file_log_handler = RotatingFileHandler("logs/log", encoding="utf8", maxBytes=1024 * 1024 * 300, backupCount=10)
# 创建日志记录的格式 日志等级 输入日志信息的文件名 行数 日志信息
formatter = logging.Formatter('%(levelname)s %(filename)s:%(lineno)d %(message)s')
# 为刚创建的日志记录器设置日志记录格式
file_log_handler.setFormatter(formatter)
# 为全局的日志工具对象(flaskapp使用的)添加日志记录器
logging.getLogger().addHandler(file_log_handler)
注意:
RotatingFileHandler, 类似于上面的FileHandler,但是它可以管理文件大小。当文件达到一定大小之后,它会自动将当前日志文件改名,然后创建一个新的同名日志文件继续输出。比如日志文件是chat.log。当chat.log达到指定的大小之后,RotatingFileHandler自动把 文件改名为chat.log.1。不过,如果chat.log.1已经存在,会先把chat.log.1重命名为chat.log.2。。。最后重新创建 chat.log,继续输出日志信息。
项目练习: 小脚本 + 日志记录: 观看血腥恐怖动作电影, 年龄大于60岁不让观看, 年龄小于15岁不让观看, 性别女的不让观看.
# 配置日志操作
import traceback
import logging
file_handler = logging.FileHandler("choice_movie_age","a",encoding="utf8")
file_handler.setFormatter(logging.Formatter(fmt="%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s"))
logger = logging.Logger("脚本程序名字",level=20) # 记录级别大于等于20 的日志等级
logger.addHandler(file_handler) # 自定义异常
class BigAgeException(Exception):
pass
class SmallAgeException(Exception):
pass
class GenderException(Exception):
pass class WatchMovie:
def __init__(self,name,age,gender):
self.name = name
self.age = age
self.gender = gender
def judge(self):
if self.age < 15:
raise SmallAgeException("年龄太小不适合观看")
elif self.age > 60:
raise BigAgeException("年龄太大不宜观看")
elif self.gender == "女":
raise GenderException("泰国暴力女性不宜观看")
else:
logger.info("%s观看了电影" %(self.name)) # 日志记录....观看了电影
print("观影愉快") while 1:
try:
name = input("您的姓名:")
age = int(input("您的年龄: "))
gender = input("您的性别: ")
obj = WatchMovie(name,age,gender)
print(obj.judge())
except SmallAgeException as s:
msg = traceback.format_exc()
logger.warning(msg)
except BigAgeException as b:
msg = traceback.format_exc()
logger.warning(msg)
except GenderException as b:
msg = traceback.format_exc()
logger.warning(msg)
except Exception as e:
msg = traceback.format_exc()
logger.error(msg)
logging脚本练习
3、collection模块
collection模块主要封装了一些关于集合类的操作.
3.1 Counter 计数器, 用来计数, 结果是一个类似于字典的Counter对象.
from collections import Counter
s = "wo you yi ge meng xiang jiu shi you yi tian quan shi jie dou mei you zhong zu qi shi"
print(Counter(s)) # 结果像字典一样可以调用
3.2 栈(先进后出)
python没有stack模块, 粗略手写一个实现栈的类(此版本有很严重的高并发问题)
class StackFullError(Exception):
pass
class StackEmptyError(Exception):
pass
class Stack:
def __init__(self,size):
self.size = size
self.index = 0
self.lst = []
def push(self,item):
if self.index == self.size:
raise StackFullError("栈满")
self.lst.insert(self.index,item)
# self.lst[self.index] = item
self.index += 1
def pop(self):
if self.index == 0:
raise StackEmptyError("栈空")
self.index -= 1
item = self.lst.pop(self.index)
return item s = Stack(5)
s.push("馒头1")
s.push("馒头2")
s.push("馒头3")
s.push("馒头4")
s.push("馒头5")
print(s.pop())
print(s.pop())
print(s.pop())
print(s.pop())
print(s.pop())
栈的实现
3.3 队列(先进先出)
import queue
q = queue.Queue(4) # q 里放四个元素
q.put("馒头1")
q.put("馒头2")
q.put("馒头3")
q.put("馒头4")
# q.put("馒头5",0) # 第二个参数为0, 能看到阻塞信息. queue.Full
print(q.get())
print(q.get())
print(q.get())
print(q.get())
queue队列
3.4 双向队列(左右可进可出)
from collections import deque
dq = deque()
dq.append("1号")
dq.append("2号")
dq.appendleft("3号")
dq.appendleft("4号")
print(dq.pop())
print(dq.pop())
print(dq.popleft())
print(dq.popleft())
print(dq.popleft()) # 队列里为空时会报错不会阻塞
双向队列
3.5 namedtuple 命名元组
给元组内的元素进行命名. 比如. 我们说(x, y) 这是一个元组. 同时. 我们还可以认为这是一个点坐标. 这时, 我们就可以使用namedtuple对元素进行命名.
from collections import namedtuple
point = namedtuple("三维坐标",["x","y","z"])
p = point(20,56,89)
print(p.x)
print(p.y)
print(p.z)
# p.z = 58 # 不能修改, 命名元组也是一个元组,不可变
namedtuple
3.6 defaultdict 默认值字典可以给字典设置默认值. 当key不存在时. 直接获取默认值.
from collections import defaultdict
dic = defaultdict(list) -----> 设置默认值是一个list, 是一个空列表
print(dic["大手笔"]) dic[ ''大手笔'' ] = []
from collections import defaultdict
lst = [11,22,33,44,55,66,77,88,99,100]
dic = defaultdict(list) # 参数必须是可调用的, 即 参数()... 如果dic中某个键没有对应值时创建一个空[], 也可以自己
# 写个函数,放函数名, dic对象中键名没有对应值的话默认会执行函数并返回函数值 for i in lst:
if i > 55:
dic["大于55"].append(i) # 从dic里面找"大于55",有的话直接append(), 没有的话会默认生成一个list
# dic.setdefault("大于55").append(i)
else:
dic["小于等于55"].append(i)
# dic.setdefault("xiao于55").append(i)
print(dic)
defaultdict
4、time模块
在python中时间分成三种表现形式:
1. 时间戳(timestamp). 时间戳使用的是从1970年年01月01日 00点00分00秒到现在 一共经过了多少秒... 使用float来表示 .
2. 格式化时间(strftime). 这个时间可以根据我们的需要对时间进行任意的格式化.
3. 结构化时间(struct_time). 这个时间主要可以把时间进行分类划分. 比如. 1970 年年01月01日 00点00分00秒, 这个时间可以被细分为年, 月, 日.....一大堆东西.
%y 两位数的年年份表示(00-99)
%Y 四位数的年年份表示(000-9999)
%m 月份(01-12)
%d 月内中的⼀一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地简化星期名称
%A 本地完整星期名称
%b 本地简化的月份名称
%B 本地完整的月份名称
%c 本地相应的日期表示和时间表示
%j 年年内的一天(001-366)
%p 本地A.M.或P.M.的等价符
%U 一年年中的星期数(00-53)星期天为星期的开始
%w 星期(0-6),星期天为星期的开始
%W 一年年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%% %号本身
# 时间戳 ----> 格式化时间
stamp_time = time.time() # 时间戳
struck_time = time.gmtime() # 时间戳 -----> 结构化时间(也可以用localtime)
f_time = time.strftime("%Y-%m-%d %H:%M:%S",struck_time) # 结构化时间 ----> 格式化时间
print(f_time) # 格式化时间 -----> 时间戳
f_time = "2018-11-14 12:53:33"
struck_time = time.strptime(f_time,"%Y-%m-%d %H:%M:%S") # 格式化时间 ----> 结构化时间
stamp_time2 = time.mktime(struck_time) # 结构化时间 -----> 时间戳
print(stamp_time2)
(时间戳 <----------> 格式化时间) 的相互转换?
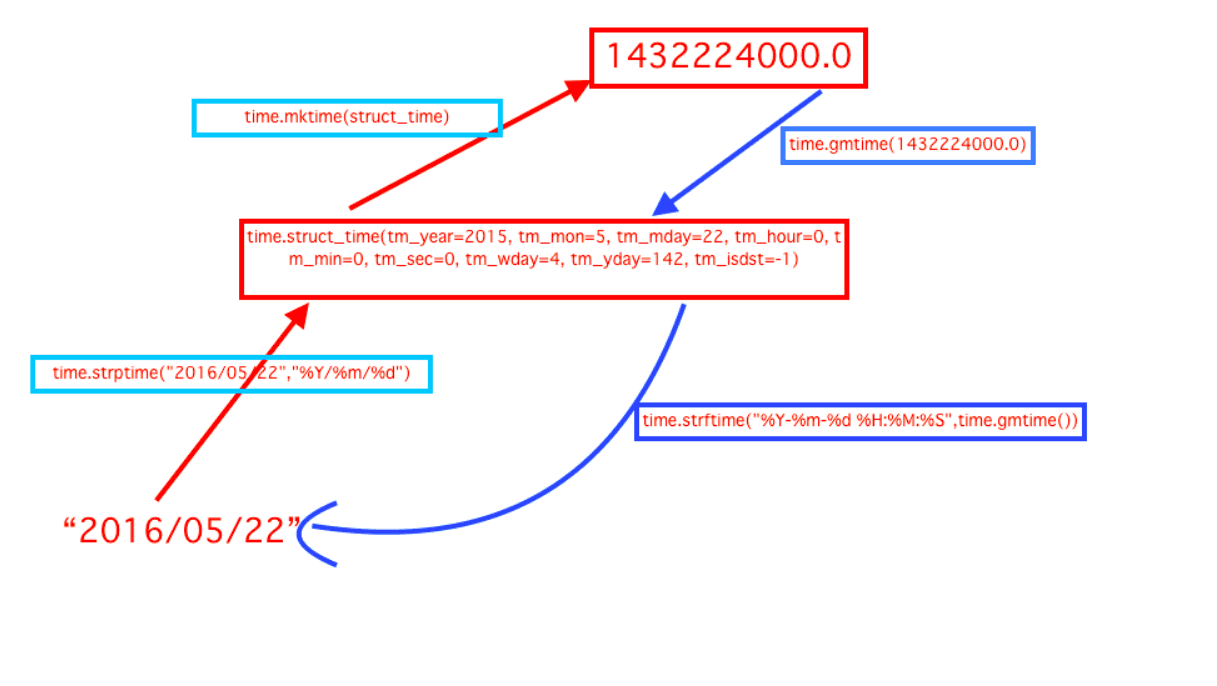
计算时间差的两种方案:
# 计算时间差的两种方案
start_time = "2018-11-21 12:15:20"
end_time = "2018-11-21 15:28:59"
def trans(t):
struck_time = time.strptime(t,"%Y-%m-%d %H:%M:%S")
stamp_time = time.mktime(struck_time)
return stamp_time dis_time = abs(trans(end_time) - trans(start_time)) # 第一种方案
m,s = divmod(dis_time,60)
h,m = divmod(m,60)
d,h = divmod(h,24)
print(f"从开始到结束的时间差为{int(d)}天{int(h)}时{int(m)}分{int(s)}秒") # 第二种方案
struck_time = time.gmtime(dis_time)
print(f"从开始到结束的时间差为{struck_time.tm_year - 1970}年"
f"{struck_time.tm_mon - 1}月"
f"{struck_time.tm_mday-1}天"
f"{struck_time.tm_hour}时"
f"{struck_time.tm_min}分"
f"{struck_time.tm_sec}秒")
time计算时间差
5、random模块 ----> 所有随机的操作
import random print(random.random()) # (0,1)之间小数
print(random.uniform(1,10)) # (0,10)之间小数
print(random.randint(1,10)) # [1,10]之间的整数,包括1,10
print(random.randrange(1,10,3)) # 1到10,每三个取一个的随机数
print(random.choice([1,25,"山东",[25,"丰富"],None])) # []中的任意一个
print(random.sample([11,456,"马东北",[25,"单位"],{"鲁":"山东"}],3)) # []中的任意三个
lst = [1,2,3,4,5,6,7]
random.shuffle(lst) # 将lst随意打散
6、os模块 ----> 和操作系统相关的操作
import os # 操作操作系统的
os.makedirs("mulu1/mulu11") # 在当前程序所在的文件夹中创建"目录1",在"目录1"里创建"目录11",可以循环一直添加.
os.removedirs("mulu1/mulu11") # 若目录为空则直接删除,并递归到上层目录, 如若也为空,继续删, 不为空的话则会报错.
os.mkdir('dirname') # 创建单级目录
os.rmdir('dirname') # 删除单级目录, 不为空则删除不了
print(os.listdir("../")) # 以列表的方式返回指定路径中的文件及文件夹,和隐藏文件
os.remove("mulu") # 移除文件
os.rename("../day003+","../day003 +") # 给指定文件夹重新命名 "../"表示上一级目录 # --------------------------------------------------------------------------------------------------------------
print(os.stat("text1")) # 获取文件或目录的所有信息
os.stat_result(st_mode=16895, st_ino=24488322973829161, st_dev=440696584, st_nlink=1, st_uid=0,
st_gid=0, st_size=0, st_atime=1542194130, st_mtime=1542194130, st_ctime=1542193782)
os.stat(path) #属性解读:
st_mode #inode 保护模式
st_ino #inode 节点号
st_dev #inode 驻留留的设备
st_nlink #inode 的链接数
st_uid #所有者的用户ID
st_gid #所有者的组ID
st_size #普通⽂文件以字节为单位的⼤大⼩小;包含等待某些特殊⽂文件的数据
st_atime #上次访问的时间
st_mtime #最后⼀一次修改的时间
st_ctime #由操作系统报告的"ctime".在某些系统上(如Unix)是最新的元数据更更改的时间,在其它系统上(如Windows)是创建时间(详细信息参⻅见平台的⽂文档)。
# ---------------------------------------------------------------------------------------------------------------------- print(os.system("dir")) # 直接执行命令行程序, 会乱码
print(os.popen("dir").read()) # 直接执行命令行程序, 但不会乱码
print(os.getcwd()) # 获取当前程序所在的文件夹目录 # os.path系列
os.path.abspath("text1") # 获取绝对路径, 包括上级, 上上级.....
os.path.split("E:\日常练习\day021\\text1") # 将path分割成文件目录和文件名,并以元组的形式返回('E:\\日常练习\\day021', 'text1')
os.path.dirname("E:\日常练习\day021\\text1") # 返回除path最后文件的之前所有路径 E:\日常练习\day021
os.path.basename("E:\日常练习\day021\\text1") # 返回path最后的文件名 text1
# 其实 os.path.dirname()就是os.path.split()的第一个元素, os.path.basename()就是第二个元素. os.path.exists("text1") # 如果"text1"存在,返回True;如果"text1"不不存在,返回False(只能找到当前路径)
os.path.isabs("text1") # 如果"text1"是绝对路路径,返回True
os.path.isfile("text1") # 如果"text1"是一个存在的文件,返回True。否则返回False
os.path.isdir("text1") # 如果"text1"是一个存在的目录,则返回True。否则返回False path = "E:\日常练习\day021\\text1"
os.path.join(path,"望月") # 路径拼接, 即 "E:\日常练习\day021\\text1\望月" path = "E:\日常练习业\day021\\text1\望月"
print(os.path.getsize(path)) # 返回path的大小
7、sys模块 ----> 和解释器相关的操作
import sys # ----> 操作解释器的
sys.argv # 命令⾏行行参数List,第⼀一个元素是程序本身路路径
sys.exit() # 退出程序,正常退出时exit(0),错误退出sys.exit(1)
print(sys.version) #获取Python解释程序的版本信息
pr/int(sys.platform) #返回操作系统平台名称
print(sys.path) # 返回模块的搜索路径
sys.path.append("e:/") # 当路径移动时, 可直接将新的路径添加进去, 就能查找到.
8 sys.modules[__name__] # 获取到当前文件的所有内容 -----> 一般用于反射,如 clss = getattr(sys.modules[__name__],role)
python摸爬滚打之day21---- 模块的更多相关文章
- Python之路,Day21 - 常用算法学习
Python之路,Day21 - 常用算法学习 本节内容 算法定义 时间复杂度 空间复杂度 常用算法实例 1.算法定义 算法(Algorithm)是指解题方案的准确而完整的描述,是一系列解决问题的 ...
- python的内置模块xml模块方法 xml解析 详解以及使用
一.XML介绍 xml是实现不同语言或程序直接进行数据交换的协议,跟json差不多,单json使用起来更简单,不过现在还有很多传统公司的接口主要还是xml xml跟html都属于是标签语言 我们主要学 ...
- Python(五)模块
本章内容: 模块介绍 time & datetime random os sys json & picle hashlib XML requests ConfigParser logg ...
- [转载]Python中的sys模块
#!/usr/bin/python # Filename: cat.py import sys def readfile(filename): '''Print a file to the stand ...
- Python安装包或模块的多种方式汇总
windows下安装python第三方包.模块汇总如下(部分方式同样适用于其他平台): 1. windows下最常见的*.exe,*msi文件,直接运行安装即可: 2. 安装easy_install, ...
- Python 五个常用模块资料 os sys time re built-in
1.os模块 os模块包装了不同操作系统的通用接口,使用户在不同操作系统下,可以使用相同的函数接口,返回相同结构的结果. os.name:返回当前操作系统名称('posix', 'nt', ' ...
- Python中的random模块,来自于Capricorn的实验室
Python中的random模块用于生成随机数.下面介绍一下random模块中最常用的几个函数. random.random random.random()用于生成一个0到1的随机符点数: 0 < ...
- python函数和常用模块(三),Day5
递归 反射 os模块 sys模块 hashlib加密模块 正则表达式 反射 python中的反射功能是由以下四个内置函数提供:hasattr.getattr.setattr.delattr,改四个函数 ...
- Python基础之--常用模块
Python 模块 为了实现对程序特定功能的调用和存储,人们将代码封装起来,可以供其他程序调用,可以称之为模块. 如:os 是系统相关的模块:file是文件操作相关的模块:sys是访问python解释 ...
- Python自动化之常用模块
1 time和datetime模块 #_*_coding:utf-8_*_ __author__ = 'Alex Li' import time # print(time.clock()) #返回处理 ...
随机推荐
- centos mysql密码忘记了如何修改
# /etc/init.d/mysql stop# mysqld_safe --user=mysql --skip-grant-tables --skip-networking &# mysq ...
- html input 文本框 只能输入数字,包含输小数点.
<input type="text" id="source_tds" name="source_tds" value="&l ...
- ORACLE 存储函数
前奏: 必要的概念: ORACLE 提供能够把 PL/SQL 程序存储在数据库中.并能够在不论什么地方来运行它.这样就叫存储过 程或函数. 过程和函数统称为 PL/SQL 子程序.他们是被命名的 PL ...
- pandas Series的sort_values()方法
pandas Series的 sort_values() 方法能对Series进行排序,返回一个新的Series: s = pd.Series([np.nan, 1, 3, 10, 5]) 升序排列: ...
- HTTP 06 用户认证
SSL 客户端认证具有高度的安全等级, 但是因为导入及维持费用等问题, 还未普及. 认证的方式有很多种, 多半是 基于表单的认证(即用户名/密码的方式) Session 管理及 Cookie 应用 基 ...
- ICE简单介绍及使用示例
转自:http://blog.csdn.net/zhu2695/article/details/51494664 1.ICE是什么? ICE是ZEROC的开源通信协议产品,它的全称是:The Inte ...
- 一文弄懂神经网络中的反向传播法(Backpropagation algorithm)
最近在看深度学习的东西,一开始看的吴恩达的UFLDL教程,有中文版就直接看了,后来发现有些地方总是不是很明确,又去看英文版,然后又找了些资料看,才发现,中文版的译者在翻译的时候会对省略的公式推导过程进 ...
- git 中merge的用法
git merge –no-ff 可以保存你之前的分支历史.能够更好的查看 merge历史,以及branch 状态. git merge 则不会显示 feature,只保留单条分支记录.
- Mac 安装win10操作系统
因为是做苹果开发的,用的一直是苹果的系统,前两天因为想要做内网穿透,需要用到花生壳这个软件,问题是这个软件只有windows版本和Linux版本,所以就想在苹果电脑上装一个windows系统,也想借此 ...
- 使用Newtonsoft将DataTable转Json
Newtonsoft提供的将DataTable转成Json: /// <summary> /// DataTable转Json /// </summary> /// <p ...