NLP笔记:词向量和语言模型
NLP问题如果要转化为机器学习问题,第一步是要找一种方法把这些符号数学化。
有两种常见的表示方法:
One-hot Representation,这种方法把每个词表示为一个很长的向量。这个向量的维度是词表大小,其中绝大多数元素为 0,只有一个维度的值为 1,这个维度就代表了当前的词。例如[0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0]。这种表示方法会造成“词汇鸿沟”现象:不能反映词与词之间的语义关系,因为任意两个词都是正交的;而且,这种表示的维度很高。
Distributed Representation,表示的一种低维实数向量,维度以 50 维和 100 维比较常见,这种向量的表示不是唯一的。例如:[0.792, −0.177, −0.107, 0.109, −0.542, …]。这种方法最大的贡献就是让相关或者相似的词,在距离上更接近了。向量的距离可以用最传统的欧氏距离来衡量,也可以用 cos 夹角来衡量。
如果用传统的稀疏表示法表示词,在解决某些任务的时候(比如构建语言模型)会造成维数灾难。使用低维的词向量就没这样的问题。同时从实践上看,高维的特征如果要使用 Deep Learning,其复杂度太高,因此低维的词向量使用的更多。 并且,相似词的词向量距离相近,这就让基于词向量设计的一些模型自带平滑功能。word2vec 是 Google 于 2013 年开源推出的一个用于获取 word vector 的工具包,word2vec模型其实就是简单化的神经网络。随便找了张图:
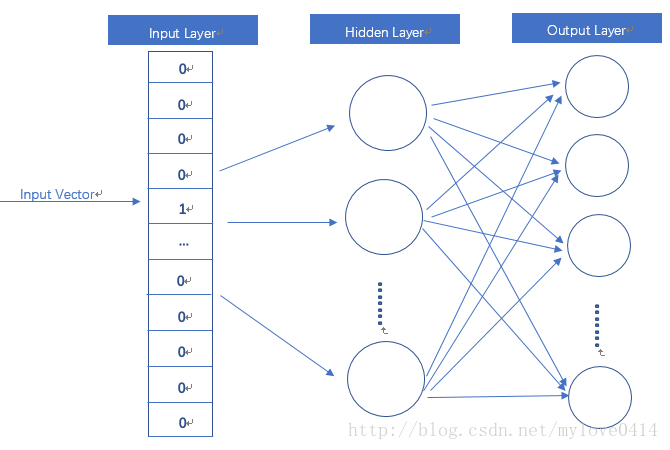
输入是One-Hot Vector,Hidden Layer没有激活函数,也就是线性的单元。Output Layer维度跟Input Layer的维度一样,用的是Softmax回归。我们要获取的dense vector其实就是Hidden Layer的输出单元。

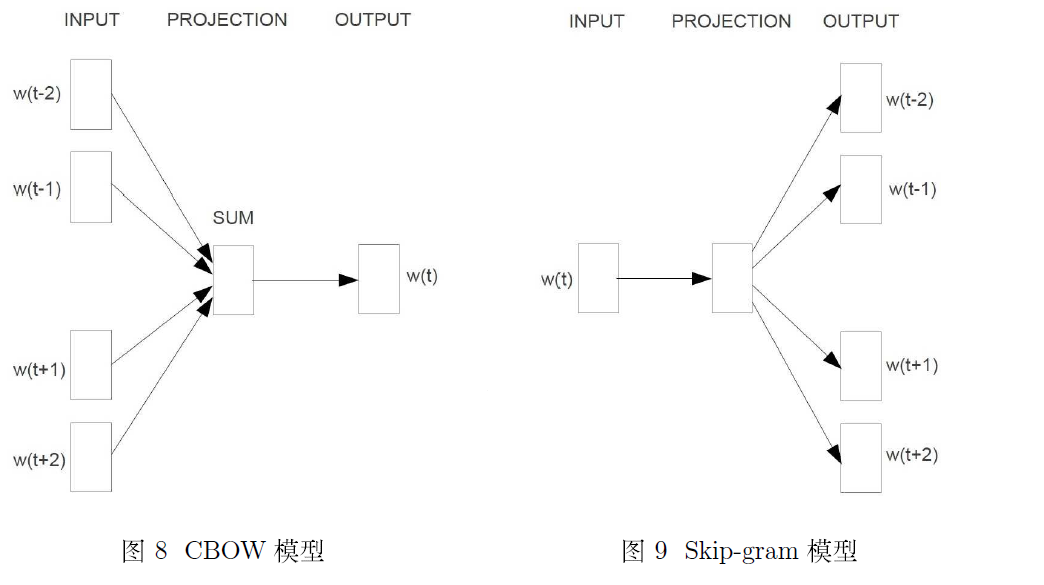
word2vec主要分为CBOW(Continuous Bag of Words)和Skip-Gram两种模式。CBOW是从原始语句推测目标字词;而Skip-Gram正好相反,是从目标字词推测出原始语句。CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好。
NLP笔记:词向量和语言模型的更多相关文章
- Deep Learning in NLP (一)词向量和语言模型
原文转载:http://licstar.net/archives/328 Deep Learning 算法已经在图像和音频领域取得了惊人的成果,但是在 NLP 领域中尚未见到如此激动人心的结果.关于这 ...
- Word2Vec之Deep Learning in NLP (一)词向量和语言模型
转自licstar,真心觉得不错,可惜自己有些东西没有看懂 这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领域中应用的理解和总结,在此分享.其中必然有局限性,欢迎各种交 ...
- 【NLP】自然语言处理:词向量和语言模型
声明: 这是转载自LICSTAR博士的牛文,原文载于此:http://licstar.net/archives/328 这篇博客是我看了半年的论文后,自己对 Deep Learning 在 NLP 领 ...
- NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
FastText是Facebook开发的一款快速文本分类器,提供简单而高效的文本分类和表征学习的方法,不过这个项目其实是有两部分组成的,一部分是这篇文章介绍的 fastText 文本分类(paper: ...
- NLP之词向量
1.对词用独热编码进行表示的缺点 向量的维度会随着句子中词的类型的增大而增大,最后可能会造成维度灾难2.任意两个词之间都是孤立的,仅仅将词符号化,不包含任何语义信息,根本无法表示出在语义层面上词与词之 ...
- NLP获取词向量的方法(Glove、n-gram、word2vec、fastText、ELMo 对比分析)
自然语言处理的第一步就是获取词向量,获取词向量的方法总体可以分为两种两种,一个是基于统计方法的,一种是基于语言模型的. 1 Glove - 基于统计方法 Glove是一个典型的基于统计的获取词向量的方 ...
- NLP︱高级词向量表达(三)——WordRank(简述)
如果说FastText的词向量在表达句子时候很在行的话,GloVe在多义词方面表现出色,那么wordRank在相似词寻找方面表现地不错. 其是通过Robust Ranking来进行词向量定义. 相关p ...
- NLP︱高级词向量表达(一)——GloVe(理论、相关测评结果、R&python实现、相关应用)
有很多改进版的word2vec,但是目前还是word2vec最流行,但是Glove也有很多在提及,笔者在自己实验的时候,发现Glove也还是有很多优点以及可以深入研究对比的地方的,所以对其进行了一定的 ...
- 斯坦福NLP课程 | 第12讲 - NLP子词模型
作者:韩信子@ShowMeAI,路遥@ShowMeAI,奇异果@ShowMeAI 教程地址:http://www.showmeai.tech/tutorials/36 本文地址:http://www. ...
随机推荐
- 3星|《创投42章经》:前VC投资人的商业评论文集
创投42章经:互联网商业逻辑与投资进阶指南 作者2014年入行VC做投资人,2016年退出改作自媒体.书中主要是作者的各类商业评论的文集,少部分是跟投资相关的内容. 投资相关的内容,有些作者自己的视角 ...
- MATLAB最小二乘法
MATLAB最小二乘法 作者:凯鲁嘎吉 - 博客园http://www.cnblogs.com/kailugaji/ 三.实验程序 四.实验内容 设有如下数据: 用3次多项式拟合这组数据. 五.解答( ...
- 布隆过滤BitMap原理
一.问题引入 BitMap从字面的意思,很多人认为是位图,其实准确的来说,翻译成基于位的映射,怎么理解呢?举一个例子,有一个无序有界int数组{1,2,5,7},初步估计占用内存44=16字节,这倒是 ...
- LCA转换成RMQ
LCA(Lowest Common Ancestor 最近公共祖先)定义如下:在一棵树中两个节点的LCA为这两个节点所有的公共祖先中深度最大的节点. 比如这棵树 结点5和6的LCA是2,12和7的LC ...
- BLDC
BLDC working principle: https://www.bilibili.com/video/av31423350?from=search&seid=1569792618769 ...
- Identity(五)
本文摘自 ASP.NET MVC 随想录—— 使用ASP.NET Identity实现基于声明的授权,高级篇 在这篇文章中,我将继续ASP.NET Identity 之旅,这也是ASP.NET Ide ...
- BZOJ2154/BZOJ2693/Luogu1829 Crash的数字表格/JZPFAR 莫比乌斯反演
传送门--Luogu 传送门--BZOJ2154 BZOJ2693是权限题 其中JZPFAR是多组询问,Crash的数字表格是单组询问 先推式子(默认\(N \leq M\),所有分数下取整) \(\ ...
- Luogu4040 AHOI/JSOI2014 宅男计划 贪心、二分、三分
传送门 仍然对"为什么这个函数单峰"的问题毫无理解 首先,对于保质期又低.价格又贵的食物,我们显然不需要购买它.所以如果设\(pri_i\)表示保质期不小于\(i\)的所有食品中价 ...
- Luogu4528 CTSC2008 图腾 树状数组、容斥
传送门 设$f_i$表示$i$排列的数量,其中$x$表示不确定 那么$$ans=f_{1324}-f_{1432}-f_{1243}=(f_{1x2x}-f_{1423})-(f_{14xx}-f_{ ...
- CF1038E Maximum Matching 搜索/区间DP
题目传送门:http://codeforces.com/problemset/problem/1038/E 题意:给出$N$个方块,每个方块有左右两种颜色$a,b$(可以翻转使左右两种颜色交换)和一个 ...