keras 的svm做分类
SVC继承了父类BaseSVC
SVC类主要方法:
★__init__() 主要参数:
C: float参数 默认值为1.0
错误项的惩罚系数。C越大,即对分错样本的惩罚程度越大,因此在训练样本中准确率越高,但是泛化能力降低,也就是对测试数据的分类准确率降低。相反,减小C的话,容许训练样本中有一些误分类错误样本,泛化能力强。对于训练样本带有噪声的情况,一般采用后者,把训练样本集中错误分类的样本作为噪声。
kernel: str参数 默认为‘rbf’
算法中采用的核函数类型,可选参数有:
‘linear’:线性核函数
‘poly’:多项式核函数
‘rbf’:径像核函数/高斯核
‘sigmod’:sigmod核函数
‘precomputed’:核矩阵
具体这些核函数类型,请参考上一篇博客中的核函数。需要说明的是,precomputed表示自己提前计算好核函数矩阵,这时候算法内部就不再用核函数去计算核矩阵,而是直接用你给的核矩阵。核矩阵为如下形式:
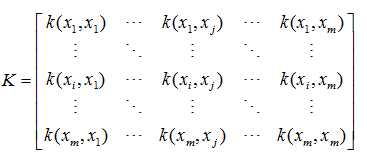
还有一点需要说明,除了上面限定的核函数外,还可以给出自己定义的核函数,其实内部就是用你自己定义的核函数来计算核矩阵。
degree:int型参数 默认为3
这个参数只对多项式核函数有用,是指多项式核函数的阶数n
如果给的核函数参数是其他核函数,则会自动忽略该参数。
gamma:float参数 默认为auto
核函数系数,只对‘rbf’,‘poly’,‘sigmod’有效。
如果gamma为auto,代表其值为样本特征数的倒数,即1/n_features.
coef0:float参数 默认为0.0
核函数中的独立项,只有对‘poly’和‘sigmod’核函数有用,是指其中的参数c
probability:bool参数 默认为False
是否启用概率估计。 这必须在调用fit()之前启用,并且会fit()方法速度变慢。
shrinking:bool参数 默认为True
是否采用启发式收缩方式
tol: float参数 默认为1e^-3
svm停止训练的误差精度
cache_size:float参数 默认为200
指定训练所需要的内存,以MB为单位,默认为200MB。
class_weight:字典类型或者‘balance’字符串。默认为None
给每个类别分别设置不同的惩罚参数C,如果没有给,则会给所有类别都给C=1,即前面参数指出的参数C.
如果给定参数‘balance’,则使用y的值自动调整与输入数据中的类频率成反比的权重。
verbose :bool参数 默认为False
是否启用详细输出。 此设置利用libsvm中的每个进程运行时设置,如果启用,可能无法在多线程上下文中正常工作。一般情况都设为False,不用管它。
max_iter :int参数 默认为-1
最大迭代次数,如果为-1,表示不限制
random_state:int型参数 默认为None
伪随机数发生器的种子,在混洗数据时用于概率估计。
★fit()方法:用于训练SVM,具体参数已经在定义SVC对象的时候给出了,这时候只需要给出数据集X和X对应的标签y即可。
★predict()方法:基于以上的训练,对预测样本T进行类别预测,因此只需要接收一个测试集T,该函数返回一个数组表示个测试样本的类别。
★属性有哪些:
svc.n_support_:各类各有多少个支持向量
svc.support_:各类的支持向量在训练样本中的索引
svc.support_vectors_:各类所有的支持向量
# -*- coding:utf-8 -*-
from sklearn.svm import SVC
import matplotlib.pyplot as plt
import numpy as np
X=np.array([[1,1],[1,2],[1,3],[1,4],[2,1],[2,2],[3,1],[4,1],[5,1],
[5,2],[6,1],[6,2],[6,3],[6,4],[3,3],[3,4],[3,5],[4,3],[4,4],[4,5]])
Y=np.array([1]*14+[-1]*6)
T=np.array([[0.5,0.5],[1.5,1.5],[3.5,3.5],[4,5.5]])
svc=SVC(kernel='poly',degree=2,gamma=1,coef0=0)
svc.fit(X,Y)
pre=svc.predict(T)
print pre
print svc.n_support_
print svc.support_
print svc.support_vectors_
运行结果:
[ 1 1 -1 -1] #预测结果
[2 3] #-1类和+1类分别有2个和3个支持向量
[14 17 3 5 13] #-1类支持向量在元训练集中的索引为14,17,同理-1类支持向量在元训练集中的索引为3,5,13
[[ 3. 3.] #给出各支持向量具体是哪些,前两个是-1类的
[ 4. 3.]
[ 1. 4.] #后3个是+1的支持向量
[ 2. 2.]
[ 6. 4.]]
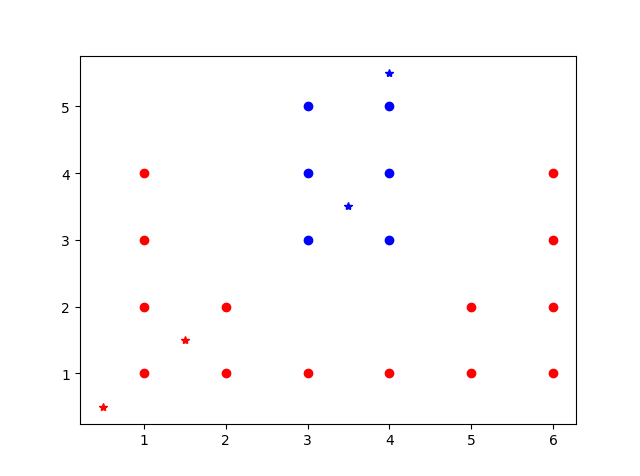
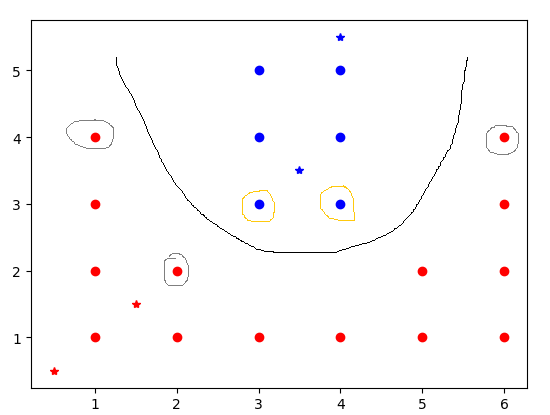
结果如图所示。
#参数的网格扫描
# Train a SVM classification modelprint("Fitting the classifier to the training set")t0 = time()param_grid = {'C': [1e3, 5e3, 1e4, 5e4, 1e5], 'gamma': [0.0001, 0.0005, 0.001, 0.005, 0.01, 0.1], }clf = GridSearchCV(SVC(kernel='rbf', class_weight='balanced'), param_grid)clf = clf.fit(X_train_pca, y_train)print("done in %0.3fs" % (time() - t0))print("Best estimator found by grid search:")print(clf.best_estimator_)Keras + 预训练好Word2Vec模型做文本分类核心解释
现在网上有一些预先训练好的Word2Vec模型, 比如Glove, Google-News以及我最喜欢的FastText,都有各自使用大数据训练出来的Word2Vec模型。 根据不同的业务, 也可以自己搜集语料库训练Word2Vec.
关于如何使用Keras加上预训练好的W2V模型, 具体可以参考官网教程: Using pre-trained word embeddings in a Keras model
篇幅比较长, 写得“太详细”了。 不过核心就在下面一行代码: ( Example Code on GitHub )
keras.layers import Embedding
embedding_layer = Embedding(len(word_index) + 1,
EMBEDDING_DIM,
weights=[embedding_matrix],
input_length=MAX_SEQUENCE_LENGTH,
trainable=False)
我们一点点来解释:
len(word_index)+1
word_index : 表示从语料库之中保留多少个单词。 因为Keras需要预留一个全零层, 所以+1
有的代码使用num_words来表示len(word_index)
word_index 又是如何得到的?
tokenizer = Tokenizer(num_words=MAX_NB_WORDS)
tokenizer.fit_on_texts(texts)
sequences = tokenizer.texts_to_sequences(texts)
word_index = tokenizer.word_index
即:使用Tokenizer,从语料库之中训练(fit_on_texts)之后得到的
EMBEDDING_DIM
即Word2Vec模型的维度。 比如你使用的是Glove_840B_300d, 那么EMBEDDING_DIM=300
weights=[embedding_matrix]
这一个参数, 应该是最关键的地方了。 weights,即权重。 权重的来源,embedding_matrix又是如何得来的?
思路大致如下:
(1) 构建一个[num_words, EMBEDDING_DIM]的矩阵
(2) 遍历word_index。 将word在W2V模型之中对应vector复制过来。
换个方式说:
- embedding_matrix 是原始W2V的子集
- 排列顺序按照Tokenizer在fit之后的词顺序。作为权重喂给Embedding Layer
input_length=MAX_SEQUENCE_LENGTH
我们输入的语料,长短不一。 有的比较长, 有的比较短。
在预处理的时候, 我们必经的一个步骤就是pad_sequence:
data = pad_sequences(sequences, maxlen=MAX_SEQUENCE_LENGTH)
上面的解释只是为了更好的让自己以及给位读者能更清楚的知道Keras是如何跟Pre-trained Word Embedding 对接的。
其实最好的方式还是亲自把原文博客之中的代码跑一遍, 然后可以按照笔者刚才的思路回过头来看代码。
本文并不能代替各位读者的亲身实践。
本文原创, 原文链接:
http://www.flyml.net/2017/11/26/deepnlp-keras-pre-trained-word2vec-explaination
keras 的svm做分类的更多相关文章
- keras系列︱图像多分类训练与利用bottleneck features进行微调(三)
引自:http://blog.csdn.net/sinat_26917383/article/details/72861152 中文文档:http://keras-cn.readthedocs.io/ ...
- [深度应用]·Keras实现Self-Attention文本分类(机器如何读懂人心)
[深度应用]·Keras实现Self-Attention文本分类(机器如何读懂人心) 配合阅读: [深度概念]·Attention机制概念学习笔记 [TensorFlow深度学习深入]实战三·分别使用 ...
- SVM多分类
http://www.matlabsky.com/thread-9471-1-1.htmlSVM算法最初是为二值分类问题设计的,当处理多类问题时,就需要构造合适的多类分类器.目前,构造SVM多类分类器 ...
- keras系列︱人脸表情分类与识别:opencv人脸检测+Keras情绪分类(四)
引自:http://blog.csdn.net/sinat_26917383/article/details/72885715 人脸识别热门,表情识别更加.但是表情识别很难,因为人脸的微表情很多,本节 ...
- SVM实现分类识别及参数调优(一)
前言 项目有一个模块需要将不同类别的图片进行分类,共有三个类别,使用SVM实现分类. 实现步骤: 1.创建训练样本库: 2.训练.测试SVM模型: 3.SVM的数据要求: 实现系统: windows_ ...
- 使用百度NLP接口对搜狐新闻做分类
一.简介 本文主要是要利用百度提供的NLP接口对搜狐的新闻做分类,百度对NLP接口有提供免费的额度可以拿来练习,主要是利用了NLP里面有个文章分类的功能,可以顺便测试看看百度NLP分类做的准不准.详细 ...
- 吴裕雄 python 机器学习——支持向量机SVM非线性分类SVC模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets, linear_model,svm fr ...
- 机器学习之SVM多分类
实验要求数据说明 :数据集data4train.mat是一个2*150的矩阵,代表了150个样本,每个样本具有两维特征,其类标在truelabel.mat文件中,trainning sample 图展 ...
- 用keras的cnn做人脸分类
keras介绍 Keras是一个简约,高度模块化的神经网络库.采用Python / Theano开发. 使用Keras如果你需要一个深度学习库: 可以很容易和快速实现原型(通过总模块化,极简主义,和可 ...
随机推荐
- 一脸懵逼学习Hive的使用以及常用语法(Hive语法即Hql语法)
Hive官网(HQL)语法手册(英文版):https://cwiki.apache.org/confluence/display/Hive/LanguageManual Hive的数据存储 1.Hiv ...
- [转] Javascript中理解发布--订阅模式
发布订阅模式介绍 发布---订阅模式又叫观察者模式,它定义了对象间的一种一对多的关系,让多个观察者对象同时监听某一个主题对象,当一个对象发生改变时,所有依赖于它的对象都将得到通知. 现实生活中的发布- ...
- openpose pytorch代码分析
github: https://github.com/tensorboy/pytorch_Realtime_Multi-Person_Pose_Estimation # -*- coding: utf ...
- centos7 查看ip地址
命令: ip address 简写ip a 过滤出来某个网卡的ip: ip a show ens33 |awk -F ' ' 'NR==3{print$2}'|cut -d / -f1
- C# 之 数字格式化
格式规范的完整形式:{index [,width][:formatstring]} index是此格式程序引用的格式字符串之后的参数,从零开始计数:width(可选) 是要设置格式的字段的宽度,wid ...
- Shiro笔记(一)Shiro整体介绍
介绍:是一个java的安全(权限)框架 可以完成的功能:认证登录(Authentication).授权(Authorization).加密(cryptography).会话管理(session man ...
- Qt界面设计基础
一.安装Qt相关基本组件: 在ubuntu上安装,可以直接使用如下的命令来安装: sudo apt-get install ubuntu-sdk 详细的安装方法可以参考这篇文章:https://blo ...
- Linux下的Sreen命令使用
详细的介绍请参看:http://www.cnblogs.com/mchina/archive/2013/01/30/2880680.html 一.简介 GNU Screen是一款由GNU计划开发的用于 ...
- 利用OpenVPN实现局域网内多台机器共享上网
本文转载自 https://www.digitalocean.com/community/tutorials/how-to-set-up-an-openvpn-server-on-ubuntu-14- ...
- c/c++关于指针的一点理解
#include <iostream> #include <string> using namespace std; int main() { }, n{}; cout < ...