CS231n——图像分类(KNN实现)
图像分类
目标:已有固定的分类标签集合,然后对于输入的图像,从分类标签集合中找出一个分类标签,最后把分类标签分配给该输入图像。
图像分类流程
- 输入:输入是包含N个图像的集合,每个图像的标签是K种分类标签中的一种。这个集合称为训练集。
- 学习:这一步的任务是使用训练集来学习每个类到底长什么样。一般该步骤叫做训练分类器或者学习一个模型。
- 评价:让分类器来预测它未曾见过的图像的分类标签,把分类器预测的标签和图像真正的分类标签对比,并以此来评价分类器的质量。
Nearest Neighbor分类器
数据集:CIFAR-10。这是一个非常流行的图像分类数据集,包含了60000张32X32的小图像。每张图像都有10种分类标签中的一种。这60000张图像被分为包含50000张图像的训练集和包含10000张图像的测试集。

Nearest Neighbor图像分类思想:拿测试图片和训练集中每一张图片去比较,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片。
如何比较来那个张图片?
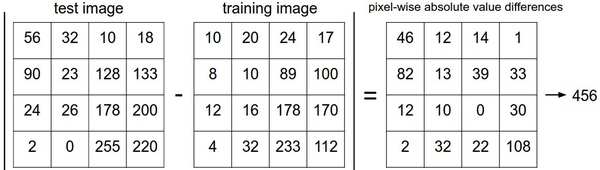
在本例中,就是比较32x32x3的像素块。最简单的方法就是逐个像素比较,最后将差异值全部加起来。换句话说,就是将两张图片先转化为两个向量I_1和I_2,然后计算他们的L1距离: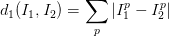
这里的求和是针对所有的像素。下面是整个比较流程的图例:
计算向量间的距离有很多种方法,另一个常用的方法是L2距离,从几何学的角度,可以理解为它在计算两个向量间的欧式距离。L2距离的公式如下: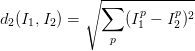
L1和L2比较:比较这两个度量方式是挺有意思的。在面对两个向量之间的差异时,L2比L1更加不能容忍这些差异。也就是说,相对于1个巨大的差异,L2距离更倾向于接受多个中等程度的差异。L1和L2都是在p-norm常用的特殊形式。
k-Nearest Neighbor分类器(KNN)
KNN图像分类思想:与其只找最相近的那1个图片的标签,我们找最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。
如何选择k值?
交叉验证:假如有1000张图片,我们将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。
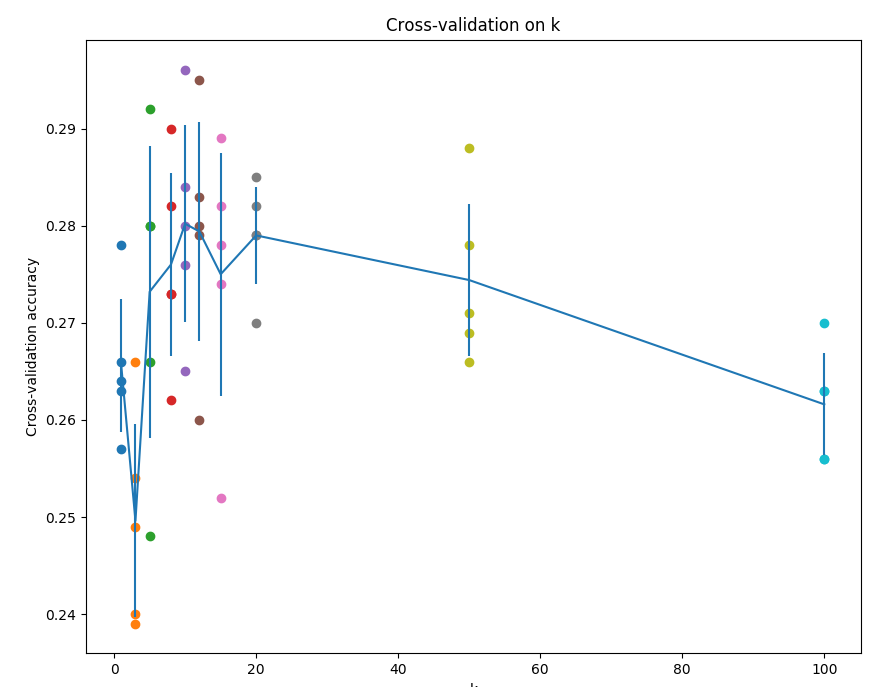
这就是5份交叉验证对k值调优的例子。针对每个k值,得到5个准确率结果,取其平均值,然后对不同k值的平均表现画线连接。本例中,当k=10的时算法表现最好(对应图中的准确率峰值)。如果我们将训练集分成更多份数,直线一般会更加平滑(噪音更少)。
k-Nearest Neighbor分类器的优劣
优点:
- 思路清晰,易于理解,实现简单;
- 算法的训练不需要花时间,因为其训练过程只是将训练集数据存储起来。
缺点:测试要花费大量时间计算,因为每个测试图像需要和所有存储的训练图像进行比较。
实际应用k-NN
如果你希望将k-NN分类器用到实处(最好别用到图像上,若是仅仅作为练手还可以接受),那么可以按照以下流程:
- 预处理你的数据:对你数据中的特征进行归一化(normalize),让其具有零平均值(zero mean)和单位方差(unit variance)。在后面的小节我们会讨论这些细节。本小节不讨论,是因为图像中的像素都是同质的,不会表现出较大的差异分布,也就不需要标准化处理了。
- 如果数据是高维数据,考虑使用降维方法,比如PCA(wiki ref, CS229ref, blog ref)或随机投影。
- 将数据随机分入训练集和验证集。按照一般规律,70%-90% 数据作为训练集。这个比例根据算法中有多少超参数,以及这些超参数对于算法的预期影响来决定。如果需要预测的超参数很多,那么就应该使用更大的验证集来有效地估计它们。如果担心验证集数量不够,那么就尝试交叉验证方法。如果计算资源足够,使用交叉验证总是更加安全的(份数越多,效果越好,也更耗费计算资源)。
- 在验证集上调优,尝试足够多的k值,尝试L1和L2两种范数计算方式。
- 如果分类器跑得太慢,尝试使用Approximate Nearest Neighbor库(比如FLANN)来加速这个过程,其代价是降低一些准确率。
- 对最优的超参数做记录。记录最优参数后,是否应该让使用最优参数的算法在完整的训练集上运行并再次训练呢?因为如果把验证集重新放回到训练集中(自然训练集的数据量就又变大了),有可能最优参数又会有所变化。在实践中,不要这样做。千万不要在最终的分类器中使用验证集数据,这样做会破坏对于最优参数的估计。直接使用测试集来测试用最优参数设置好的最优模型,得到测试集数据的分类准确率,并以此作为你的kNN分类器在该数据上的性能表现。
课程作业
KNN实现代码:
import numpy as np #http://blog.csdn.net/geekmanong/article/details/51524402
#http://www.cnblogs.com/daihengchen/p/5754383.html
#http://blog.csdn.net/han784851198/article/details/53331104
class KNearestNeighbor(object):
""" a kNN classifier with L2 distance """ def __init__(self):
pass def train(self, X, y):
"""
Train the classifier. For k-nearest neighbors this is just
memorizing the training data.
训练分类器。对于KNN算法,此处只需要存储训练数据即可。
Inputs:
- X: A numpy array of shape (num_train, D) containing the training data
consisting of num_train samples each of dimension D.
- y: A numpy array of shape (N,) containing the training labels, where
y[i] is the label for X[i].
"""
self.X_train = X
self.y_train = y def predict(self, X, k=1, num_loops=0):
"""
Predict labels for test data using this classifier.
基于该分类器,预测测试数据的标签分类。
Inputs:
- X: A numpy array of shape (num_test, D) containing test data consisting
of num_test samples each of dimension D.测试数据集
- k: The number of nearest neighbors that vote for the predicted labels.
- num_loops: Determines which implementation to use to compute distances
between training points and testing points.选择距离算法的实现方法 Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
if num_loops == 0:
dists = self.compute_distances_no_loops(X)
elif num_loops == 1:
dists = self.compute_distances_one_loop(X)
elif num_loops == 2:
dists = self.compute_distances_two_loops(X)
else:
raise ValueError('Invalid value %d for num_loops' % num_loops) return self.predict_labels(dists, k=k) def compute_distances_two_loops(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a nested loop over both the training data and the
test data. 两层循环计算L2距离 Inputs:
- X: A numpy array of shape (num_test, D) containing test data. Returns:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
is the Euclidean distance between the ith test point and the jth training
point.
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
for j in range(num_train):
#####################################################################
# TODO: #
# Compute the l2 distance between the ith test point and the jth #
# training point, and store the result in dists[i, j]. You should #
# not use a loop over dimension. #
#####################################################################
test_row = X[i, :]
train_row = self.X_train[j, :]
dists[i, j] = np.sqrt(np.sum((test_row - train_row)**2)) return dists
#####################################################################
# END OF YOUR CODE #
#####################################################################
return dists def compute_distances_one_loop(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using a single loop over the test data. 一层循环计算L2距离 Input / Output: Same as compute_distances_two_loops
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
for i in range(num_test):
#######################################################################
# TODO: #
# Compute the l2 distance between the ith test point and all training #
# points, and store the result in dists[i, :]. #
#######################################################################
test_row = X[i, :]
dists[i,:] = np.sqrt(np.sum(test_row - self.X_train)**2) #numpy广播机制
#######################################################################
# END OF YOUR CODE #
#######################################################################
return dists def compute_distances_no_loops(self, X):
"""
Compute the distance between each test point in X and each training point
in self.X_train using no explicit loops. 无循环计算L2距离 Input / Output: Same as compute_distances_two_loops
"""
num_test = X.shape[0]
num_train = self.X_train.shape[0]
dists = np.zeros((num_test, num_train))
#########################################################################
# TODO: #
# Compute the l2 distance between all test points and all training #
# points without using any explicit loops, and store the result in #
# dists. #
# #
# You should implement this function using only basic array operations; #
# in particular you should not use functions from scipy. #
# #
# HINT: Try to formulate the l2 distance using matrix multiplication #
# and two broadcast sums. #
#########################################################################
X_sq = np.square(X).sum(axis=1)
X_train_sq = np.square(self.X_train).sum(axis=1)
dists = np.sqrt(-2*np.dot(X, self.X_train.T) + X_train_sq + np.matrix(X_sq).T)
dists = np.array(dists)
#########################################################################
# END OF YOUR CODE #
#########################################################################
return dists def predict_labels(self, dists, k=1):
"""
Given a matrix of distances between test points and training points,
predict a label for each test point. Inputs:
- dists: A numpy array of shape (num_test, num_train) where dists[i, j]
gives the distance betwen the ith test point and the jth training point. Returns:
- y: A numpy array of shape (num_test,) containing predicted labels for the
test data, where y[i] is the predicted label for the test point X[i].
"""
num_test = dists.shape[0]
y_pred = np.zeros(num_test)
for i in range(num_test):
# A list of length k storing the labels of the k nearest neighbors to
# the ith test point.
closest_y = []
#########################################################################
# TODO: #
# Use the distance matrix to find the k nearest neighbors of the ith #
# testing point, and use self.y_train to find the labels of these #
# neighbors. Store these labels in closest_y. #
# Hint: Look up the function numpy.argsort. #
# numpy.argsort.函数返回的是数组值从小到大的索引值 #
#########################################################################
closest_y = self.y_train[np.argsort(dists[i,:])[:k]]
#########################################################################
# TODO: #
# Now that you have found the labels of the k nearest neighbors, you #
# need to find the most common label in the list closest_y of labels. #
# Store this label in y_pred[i]. Break ties by choosing the smaller #
# label. #
#########################################################################
#np.bincount:统计每一个元素出现的次数
y_pred[i] = np.argmax(np.bincount(closest_y))
#########################################################################
# END OF YOUR CODE #
######################################################################### return y_pred k_nearest_neighbor.py
k_nearest_neighbor.py
测试和交叉验证代码:
#coding:utf-8
'''
Created on 2017年3月21日 @author: 206
'''
import random
import numpy as np
from assignment1.data_utils import load_CIFAR10
from assignment1.classifiers.k_nearest_neighbor import KNearestNeighbor
import matplotlib.pyplot as plt # This is a bit of magic to make matplotlib figures appear inline in the notebook
# rather than in a new window.
plt.rcParams['figure.figsize'] = (10.0, 8.0) # set default size of plots
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray' X_train, y_train, X_test, y_test = load_CIFAR10('../datasets') # As a sanity check, we print out the size of the training and test data.
print('Training data shape: ', X_train.shape)
print('Training labels shape: ', y_train.shape)
print('Test data shape: ', X_test.shape)
print('Test labels shape: ', y_test.shape) # 从数据集中展示一部分数据
# 每个类别展示若干张对应图片
classes = ['plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
num_classes = len(classes)
samples_per_class = 7
for y, cls in enumerate(classes):
idxs = np.flatnonzero(y_train == y)
idxs = np.random.choice(idxs, samples_per_class, replace=False)
for i, idx in enumerate(idxs):
plt_idx = i * num_classes + y + 1
plt.subplot(samples_per_class, num_classes, plt_idx)
plt.imshow(X_train[idx].astype('uint8'))
plt.axis('off')
if i == 0:
plt.title(cls)
plt.show() # 截取部分样本数据,以提高本作业的执行效率
num_training = 5000
mask = range(num_training)
X_train = X_train[mask]
y_train = y_train[mask] num_test = 500
mask = range(num_test)
X_test = X_test[mask]
y_test = y_test[mask] # reshape训练和测试数据,转换为行的形式
X_train = np.reshape(X_train, (X_train.shape[0], -1))
X_test = np.reshape(X_test, (X_test.shape[0], -1)) print(X_train.shape)
print(X_test.shape) classifier = KNearestNeighbor()
classifier.train(X_train, y_train) dists = classifier.compute_distances_two_loops(X_test)
print(dists.shape) plt.imshow(dists, interpolation='none')
plt.show() # Now implement the function predict_labels and run the code below:
# k=1时
y_test_pred = classifier.predict_labels(dists, k=1) # Compute and print the fraction of correctly predicted examples
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy)) # k=5时
y_test_pred = classifier.predict_labels(dists, k=5)
num_correct = np.sum(y_test_pred == y_test)
accuracy = float(num_correct) / num_test
print('Got %d / %d correct => accuracy: %f' % (num_correct, num_test, accuracy)) ####测试三种距离计算法的效率 dists_one = classifier.compute_distances_one_loop(X_test) difference = np.linalg.norm(dists - dists_one, ord='fro')
print('Difference was: %f' % (difference, ))
if difference < 0.001:
print('Good! The distance matrices are the same')
else:
print('Uh-oh! The distance matrices are different') dists_two = classifier.compute_distances_no_loops(X_test)
difference = np.linalg.norm(dists - dists_two, ord='fro')
print('Difference was: %f' % (difference, ))
if difference < 0.001:
print('Good! The distance matrices are the same')
else:
print('Uh-oh! The distance matrices are different') def time_function(f, *args):
"""
Call a function f with args and return the time (in seconds) that it took to execute.
"""
import time
tic = time.time()
f(*args)
toc = time.time()
return toc - tic two_loop_time = time_function(classifier.compute_distances_two_loops, X_test)
print('Two loop version took %f seconds' % two_loop_time) one_loop_time = time_function(classifier.compute_distances_one_loop, X_test)
print('One loop version took %f seconds' % one_loop_time) no_loop_time = time_function(classifier.compute_distances_no_loops, X_test)
print('No loop version took %f seconds' % no_loop_time) # 交叉验证
num_folds = 5
k_choices = [1, 3, 5, 8, 10, 12, 15, 20, 50, 100] X_train_folds = []
y_train_folds = []
################################################################################
# TODO: #
# Split up the training data into folds. After splitting, X_train_folds and #
# y_train_folds should each be lists of length num_folds, where #
# y_train_folds[i] is the label vector for the points in X_train_folds[i]. #
# Hint: Look up the numpy array_split function. #
################################################################################
#数据划分
X_train_folds = np.array_split(X_train, num_folds);
y_train_folds = np.array_split(y_train, num_folds)
################################################################################
# END OF YOUR CODE #
################################################################################ # A dictionary holding the accuracies for different values of k that we find
# when running cross-validation. After running cross-validation,
# k_to_accuracies[k] should be a list of length num_folds giving the different
# accuracy values that we found when using that value of k. k_to_accuracies = {} ################################################################################
# TODO: #
# Perform k-fold cross validation to find the best value of k. For each #
# possible value of k, run the k-nearest-neighbor algorithm num_folds times, #
# where in each case you use all but one of the folds as training data and the #
# last fold as a validation set. Store the accuracies for all fold and all #
# values of k in the k_to_accuracies dictionary. #
################################################################################
for k in k_choices:
k_to_accuracies[k] = [] for k in k_choices:#find the best k-value
for i in range(num_folds):
X_train_cv = np.vstack(X_train_folds[:i]+X_train_folds[i+1:])
X_test_cv = X_train_folds[i] y_train_cv = np.hstack(y_train_folds[:i]+y_train_folds[i+1:]) #size:4000
y_test_cv = y_train_folds[i] classifier.train(X_train_cv, y_train_cv)
dists_cv = classifier.compute_distances_no_loops(X_test_cv) y_test_pred = classifier.predict_labels(dists_cv, k)
num_correct = np.sum(y_test_pred == y_test_cv)
accuracy = float(num_correct) / y_test_cv.shape[0] k_to_accuracies[k].append(accuracy)
################################################################################
# END OF YOUR CODE #
################################################################################ # Print out the computed accuracies
for k in sorted(k_to_accuracies):
for accuracy in k_to_accuracies[k]:
print('k = %d, accuracy = %f' % (k, accuracy)) # plot the raw observations
for k in k_choices:
accuracies = k_to_accuracies[k]
plt.scatter([k] * len(accuracies), accuracies) # plot the trend line with error bars that correspond to standard deviation
accuracies_mean = np.array([np.mean(v) for k,v in sorted(k_to_accuracies.items())])
accuracies_std = np.array([np.std(v) for k,v in sorted(k_to_accuracies.items())])
plt.errorbar(k_choices, accuracies_mean, yerr=accuracies_std)
plt.title('Cross-validation on k')
plt.xlabel('k')
plt.ylabel('Cross-validation accuracy')
plt.show()
testKNN.py
运行结果:
Training data shape: (50000, 32, 32, 3)
Training labels shape: (50000,)
Test data shape: (10000, 32, 32, 3)
Test labels shape: (10000,)
(5000, 3072)
(500, 3072)
(500, 5000)
Got 137 / 500 correct => accuracy: 0.274000
Got 139 / 500 correct => accuracy: 0.278000
Difference was: 794038655446.820190
Uh-oh! The distance matrices are different
Difference was: 0.000000
Good! The distance matrices are the same
Two loop version took 52.208034 seconds
One loop version took 42.104724 seconds
No loop version took 0.371247 seconds
k = 1, accuracy = 0.263000
k = 1, accuracy = 0.257000
k = 1, accuracy = 0.264000
k = 1, accuracy = 0.278000
k = 1, accuracy = 0.266000
k = 3, accuracy = 0.239000
k = 3, accuracy = 0.249000
k = 3, accuracy = 0.240000
k = 3, accuracy = 0.266000
k = 3, accuracy = 0.254000
k = 5, accuracy = 0.248000
k = 5, accuracy = 0.266000
k = 5, accuracy = 0.280000
k = 5, accuracy = 0.292000
k = 5, accuracy = 0.280000
k = 8, accuracy = 0.262000
k = 8, accuracy = 0.282000
k = 8, accuracy = 0.273000
k = 8, accuracy = 0.290000
k = 8, accuracy = 0.273000
k = 10, accuracy = 0.265000
k = 10, accuracy = 0.296000
k = 10, accuracy = 0.276000
k = 10, accuracy = 0.284000
k = 10, accuracy = 0.280000
k = 12, accuracy = 0.260000
k = 12, accuracy = 0.295000
k = 12, accuracy = 0.279000
k = 12, accuracy = 0.283000
k = 12, accuracy = 0.280000
k = 15, accuracy = 0.252000
k = 15, accuracy = 0.289000
k = 15, accuracy = 0.278000
k = 15, accuracy = 0.282000
k = 15, accuracy = 0.274000
k = 20, accuracy = 0.270000
k = 20, accuracy = 0.279000
k = 20, accuracy = 0.279000
k = 20, accuracy = 0.282000
k = 20, accuracy = 0.285000
k = 50, accuracy = 0.271000
k = 50, accuracy = 0.288000
k = 50, accuracy = 0.278000
k = 50, accuracy = 0.269000
k = 50, accuracy = 0.266000
k = 100, accuracy = 0.256000
k = 100, accuracy = 0.270000
k = 100, accuracy = 0.263000
k = 100, accuracy = 0.256000
k = 100, accuracy = 0.263000
result
交叉验证结果:

完整代码见这里。
CS231n——图像分类(KNN实现)的更多相关文章
- cs231n assignment1 KNN
title: cs231n assignment1 KNN tags: - KNN - cs231n categories: - 机器学习 date: 2019年9月16日 17:03:13 利用KN ...
- 深度学习与计算机视觉系列(2)_图像分类与KNN
作者: 寒小阳 &&龙心尘 时间:2015年11月. 出处: http://blog.csdn.net/han_xiaoyang/article/details/49949535 ht ...
- 【cs231n作业笔记】一:KNN分类器
安装anaconda,下载assignment作业代码 作业代码数据集等2018版基于python3.6 下载提取码4put 本课程内容参考: cs231n官方笔记地址 贺完结!CS231n官方笔记授 ...
- 【cs231n笔记】assignment1之KNN
k-Nearest Neighbor (kNN) 练习 这篇博文是对cs231n课程assignment1的第一个问题KNN算法的完成,参考了一些网上的博客,不具有什么创造性,以个人学习笔记为目的发布 ...
- 『cs231n』绪论
笔记链接 cs231n系列所有图片笔记均拷贝自网络,链接如上,特此声明,后篇不再重复. 计算机视觉历史 总结出视觉两个重要结论:1.基础的视觉神经识别的是简单的边缘&轮廓2.视觉是分层的 数据 ...
- 斯坦福大学CS231n简要笔记和课后作业
笔记目录: 1. CS231n--图像分类(KNN实现) 2. 待更新... 3. 4.
- Atitit 图像处理知识点体系知识图谱 路线图attilax总结 v4 qcb.xlsx
Atitit 图像处理知识点体系知识图谱 路线图attilax总结 v4 qcb.xlsx 分类 图像处理知识点体系 v2 qb24.xlsx 分类 分类 理论知识 图像金字塔 常用底层操作 卷积扫描 ...
- Atiti attilax主要成果与解决方案与案例rsm版 v4
Atiti attilax主要成果与解决方案与案例rsm版 v4 版本历史记录1 1. ##----------主要成果与解决方案与 参与项目1 ###开发流程与培训系列1 #-----组织运营与文 ...
- 【cs231n】图像分类-Linear Classification线性分类
[学习自CS231n课程] 转载请注明出处:http://www.cnblogs.com/GraceSkyer/p/8824876.html 之前介绍了图像分类问题.图像分类的任务,就是从已有的固定分 ...
随机推荐
- 2018.7.26 进程和线程的区别 &&你对 Java平台的理解
进程和线程的区别 1.定义 进程:具有一定独立功能的程序关于某个数据集合上的一次运行活动,进程是系统进行资源分配和调度的一个独立单位. 线程:进程的一个实体,是CPU调度和分派的基本单位,它是比进程更 ...
- vim常用操作整理
一.删除操作 :%s/r//g 删除DOS方式的回车^M :%s= *$== 删除行尾空白 :%s/^(.*)n1/1$/ 删除重复行 :%s/^.pdf/new.pdf/ 只是删除第一个pdf :% ...
- JavaScript正则(一)
1.字符组: ^ $ 说的是开始位置和结束位置,在JS中,既表示字符串的起始位置和结束位置,也表示行的起始位置和结束位置 console.log(/^\d$/.test('2')); // true ...
- node.js启动调试方式
node.js启动调试方式(nodeJs不能像js一样在控制台调试) 以express项目为例,启动路径是localhost:3000 一.通过node命令启动 node server/bin/www ...
- 经典sql语句汇总
1,某条数据放首位,其他倒序并分页 select * from Student order by( case when id='2' then 1 ELSE 4 END),id desc l ...
- ssm整合-错误3
1.警告: Unknown version string [3.1]. Default version will be used. 因为Tomcat版本为7,支持3.1版本的为Tomcat 8: 2. ...
- Linux文件服务器实战(虚拟用户)
vsftpd基于系统用户访问ftp服务器,系统用户越多越不利于管理,不利于系统安全,这样就以vsftp虚拟防护的方式来解决. 虚拟用户没有实际的真实系统用户,,而是通过映射到其中一个真实用户以及设置相 ...
- Go Doc文档
Go为我们提供了快速生成文档和查看文档的工具,很容易编写查看代码文档.在项目协作过程中,可以帮助我们快速理解代码. 查看文档方式有两种:一种是通过终端查看,使用go doc命令,一种是通过网页查看,使 ...
- HDFS学习指南
本篇HDFS组件基于CDH5进行安装,安装过程:https://www.cnblogs.com/dmjx/p/10037066.html 角色分布 hdp02.yxdev.wx:HDFS server ...
- Linux系统崩溃,数据迁移
就在1小时前,处理了件如标题所述的麻烦事儿.吃完午饭,想对此作个总结,一来自己梳理下过程以便后面遇见类似的事可以 快速处理,二来同行的小伙伴们可以探讨下.故事是这样的,公司所在园区物业晚上断电8小时, ...