通过Maven管理多个MapReduce项目
1. 配置Maven环境
首先检查Windows是否配置了maven,进入cmd命令行,输入mvn -version命令,如果出现下图所示的 情形则表示满意配置maven。
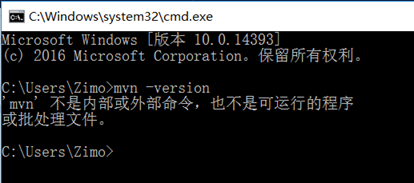
从浏览器进入maven官网,下载maven压缩包:http://maven.apache.org/download.cgi。下载完后将其解压的一个自定义目录,然后配置环境变量。
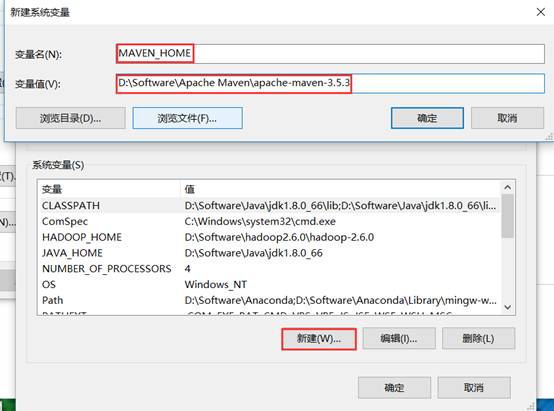
进入环境变量配置页面,新建一个MAVEN_HOME变量,变量值为刚才解压的路径(进入能看到bin文件夹的路径)。
然后,在Path变量下添加MAVEN_HOME变量。
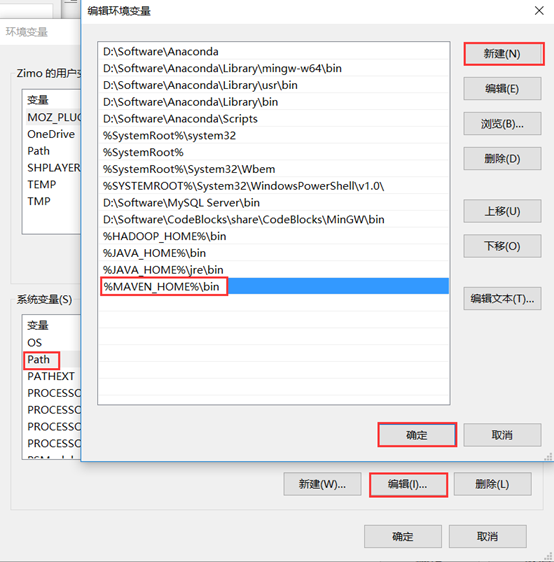
注意:老版本Windows直接在变量后面加上分号,然后加上%MAVEN_HOME%\bin。
回到命令行,再输入mvn -version,如果出现下图所示的情形则表明配置成功。

2. 在Eclipse中配置Maven
进入Eclipse,然后Window->Preferences->Maven,首先关联Maven安装路径待eclipse.
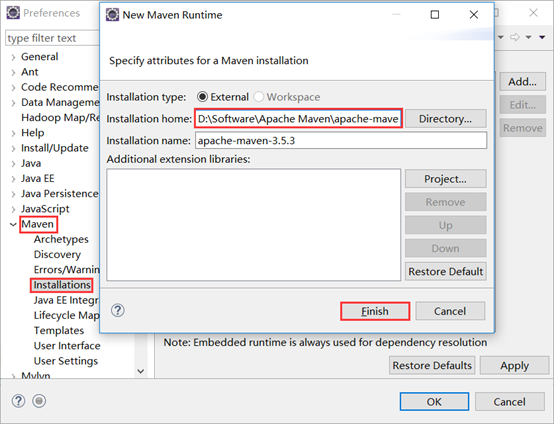
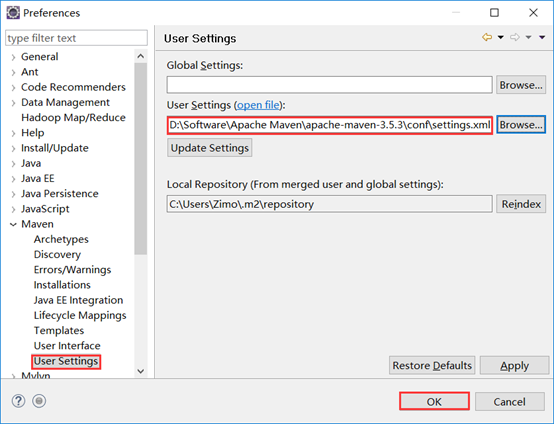
然后配置settings.xml文件,下面的本地库保存路径可以自定义(一般默认就好)。
3. 使用Maven管理多个MapReduce项目
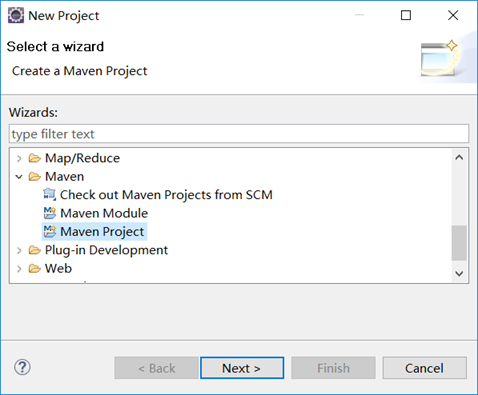
首先新建一个maven项目。
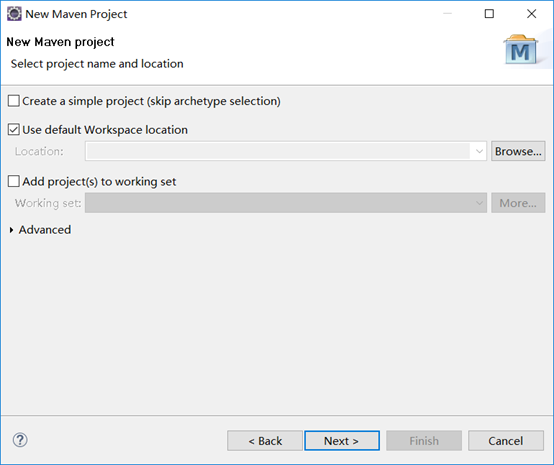
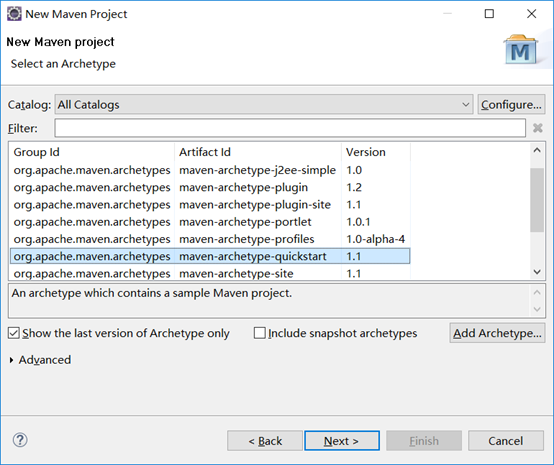
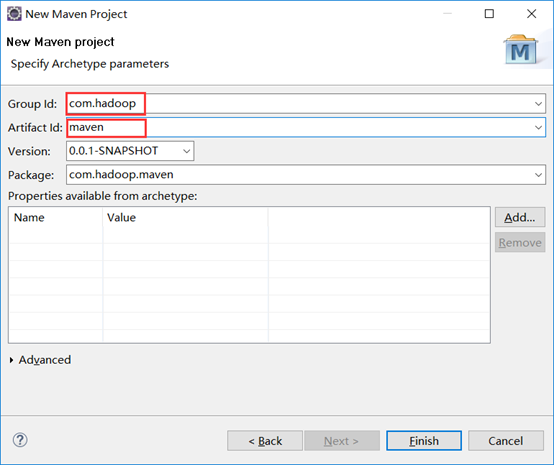
*(该图和我最后的名称不同,因为修改过,不过不影响,按照你自己的来即可)
然后新建一个WordCount.java类,代码可以从官网下载:http://hadoop.apache.org/docs/current/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html#Source_Code
此时,WordCount.java类肯定是一片红,有很多报错,这是因为我们目前还没有引入所需要的jar文件。接下来是通过Maven框架引入所依赖的jar文件,这和之前我们直接导入然后Build Path的方法不同。我们现在使用Maven框架来进行管理,我们只需要在pom.xml文件中写入以下内容就可以实现jar文件的自动下载和管理。配置完后保存文件,然后Maven会自动下载好所需要的jar文件,报错也都会给解决掉。
pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.</modelVersion>
//下面两行改为自己新建项目时的Id
<groupId>com.hadoop</groupId>
<artifactId>maven</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging> <name>maven</name>
<url>http://maven.apache.org</url> <properties>
<project.build.sourceEncoding>UTF-</project.build.sourceEncoding>
<hadoop.version>2.6.</hadoop.version>
</properties> <dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.</version>
<scope>test</scope>
</dependency> <dependency>
<groupId>jdk.tools</groupId>
<artifactId>jdk.tools</artifactId>
<version>1.8</version> //改成自己对于的JDK版本号
<scope>system</scope>
<systemPath>${JAVA_HOME}/lib/tools.jar</systemPath>
</dependency> <dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.</version>
<executions>
<!-- Run shade goal on package phase -->
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<!-- add Main-Class to manifest file -->
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>com.hadoop.mavenPro.MyDriver</mainClass> //根据自己的项目路径修改
</transformer>
</transformers>
<createDependencyReducedPom>false</createDependencyReducedPom> //该句很关键,必须配置为false
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
接下来是调试Maven项目中的MapReduce程序。
在右键WordCount类选择:Run as->Run Configuration。
搜索主类:
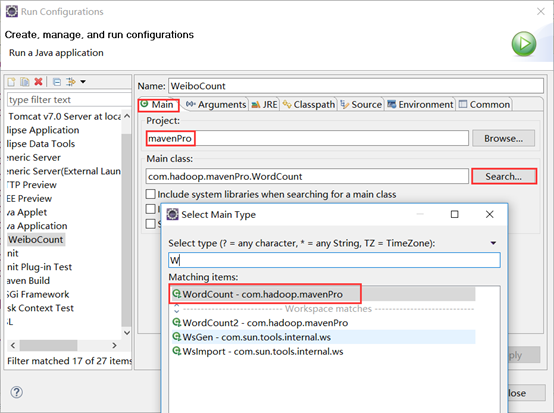
注意:如果搜不到对应类,请将Search上面的Project选择为自己所新建的项目。
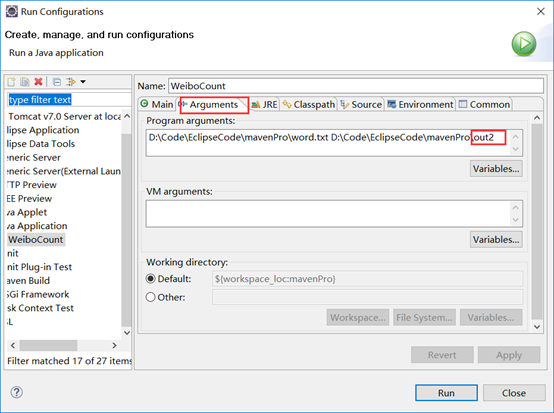
设置输入输出路径
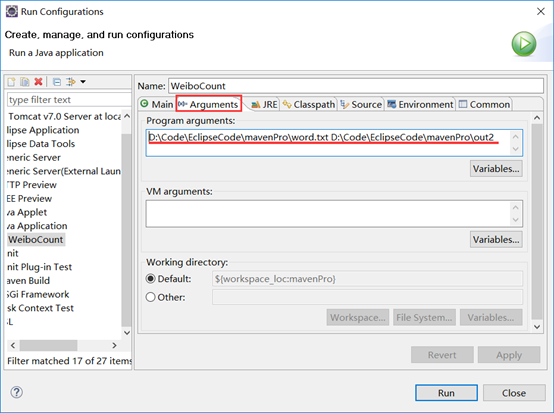
然后点击运行。
运行结果如下:
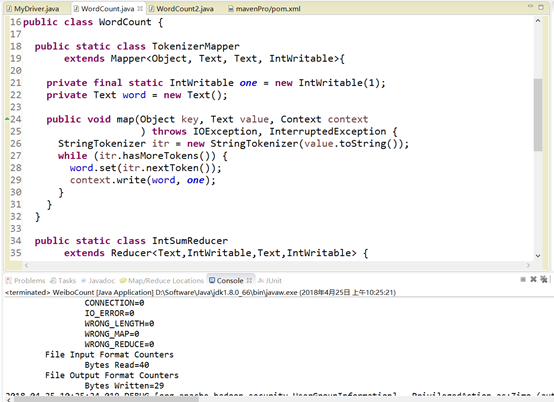
输出目录如下


那么,Maven如何管理多个MapReduce程序呢?
我们再新建一个MapReduce程序,于是我又新建了一个2.0版本的WordCount类WordCount2.java。然后配置方法同上,只是输出路径要修改一下。
运行结果如下
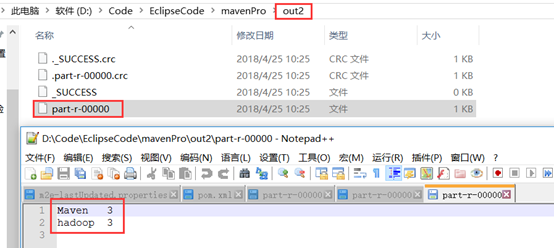
根据以上的本地调试证明两个MapReduce程序都没有问题,以下就是多个MapReduce程序的管理。
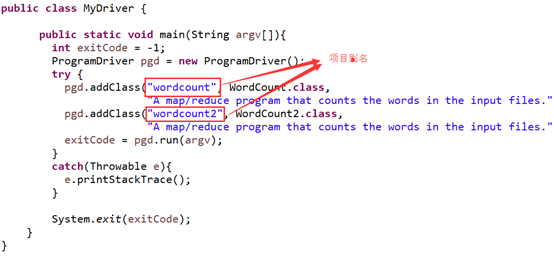
Maven是通过ProgramDriver类来进行管理的。首先我们先新建一个MyDriver类,代码如下:
MyDriver.java package com.hadoop.mavenPro; import org.apache.hadoop.util.ProgramDriver; /**
* @author Zimo
*
*/
public class MyDriver { public static void main(String argv[]){
int exitCode = -;
ProgramDriver pgd = new ProgramDriver();
try {
pgd.addClass("wordcount", WordCount.class, //设置项目别名
"A map/reduce program that counts the words in the input files."); //添加项目描述
pgd.addClass("wordcount2", WordCount2.class,
"A map/reduce program that counts the words in the input files.");
exitCode = pgd.run(argv);
}
catch(Throwable e){
e.printStackTrace();
} System.exit(exitCode);
}
}
通过cmd命令行打包项目:进入项目路径->clean->package。

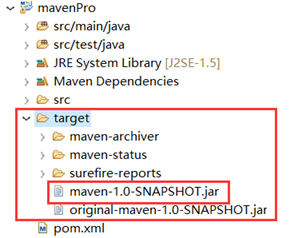
然后回到Eclipse,右键项目刷新一下,target目录下也出现了相应的jar包了,可以直接上传到Hadoop集群运行。
然后登陆到Hadoop集群并启动。
[hadoop@centpy ~]$ cd $HADOOP_HOME //进入Hadoop路径
[hadoop@centpy hadoop-2.6.]$ pwd
/usr/hadoop/hadoop-2.6.0
[hadoop@centpy hadoop-2.6.]$ sbin/start-all.sh //启动集群
This script is Deprecated. Instead use start-dfs.sh and start-yarn.sh
Starting namenodes on [centpy]
centpy: starting namenode, logging to /usr/hadoop/hadoop-2.6./logs/hadoop-hadoop-namenode-centpy.out
centpy: starting datanode, logging to /usr/hadoop/hadoop-2.6./logs/hadoop-hadoop-datanode-centpy.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/hadoop/hadoop-2.6./logs/hadoop-hadoop-secondarynamenode-centpy.out
starting yarn daemons
starting resourcemanager, logging to /usr/hadoop/hadoop-2.6./logs/yarn-hadoop-resourcemanager-centpy.out
centpy: starting nodemanager, logging to /usr/hadoop/hadoop-2.6./logs/yarn-hadoop-nodemanager-centpy.out
[hadoop@centpy hadoop-2.6.]$ jps
NameNode
NodeManager
DataNode
Jps
ResourceManager
SecondaryNameNode
新建一个文件夹用于该项目文件的存放。
[hadoop@centpy hadoop-2.6.]$ hadoop fs -mkdir /maven [hadoop@centpy hadoop-2.6.]$ hadoop fs -ls / Found items drwxr-xr-x - hadoop hadoop -- : /hdfsOutput drwxr-xr-x - hadoop supergroup -- : /maven drwxrwxrwx - hadoop supergroup -- : /phone drwxr-xr-x - hadoop hadoop -- : /test drwx------ - hadoop hadoop -- : /tmp drwxr-xr-x - hadoop hadoop -- : /weather drwxr-xr-x - hadoop hadoop -- : /weibo
上传一个输入文件到/maven。
[hadoop@centpy hadoop-2.6.]$ vi word.txt //新建一个文件作为输入文件
hadoop maven
hadoop maven
hadoop maven
[hadoop@centpy hadoop-2.6.]$ hadoop fs -put word.txt /maven //将输入文件放到HDFS中
[hadoop@centpy hadoop-2.6.]$ hadoop fs -ls /maven
Found items
-rw-r--r-- hadoop supergroup -- : /maven/word.txt
上传项目jar包
[hadoop@centpy hadoop-2.6.]$ rz //上传之前打包的jar文件 [hadoop@centpy hadoop-2.6.]$ ls bin lib libhadoop.so.1.0. LICENSE.txt sbin word.txt data libexec libhadooputils.a logs share etc libhadoop.a libhdfs.a maven-1.0-SNAPSHOT.jar Temperature.jar include libhadooppipes.a libhdfs.so NOTICE.txt WeiboCount.jar jar libhadoop.so libhdfs.so.0.0. README.txt WordCount.jar
运行项目
[hadoop@centpy hadoop-2.6.]$ hadoop jar maven-1.0-SNAPSHOT.jar wordcount /maven/word.txt /maven/output //运行程序
//由于pom.xml中配置了主类,出现可以直接找到Driver类,所以不用再像以前一样写全包路径,直接写Driver类中的项目别名就行了!
// :: INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:
// :: WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
// :: INFO input.FileInputFormat: Total input paths to process :
// :: INFO mapreduce.JobSubmitter: number of splits:
// :: INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1524619938432_0001
// :: INFO impl.YarnClientImpl: Submitted application application_1524619938432_0001
// :: INFO mapreduce.Job: The url to track the job: http://centpy:8088/proxy/application_1524619938432_0001/
// :: INFO mapreduce.Job: Running job: job_1524619938432_0001
// :: INFO mapreduce.Job: Job job_1524619938432_0001 running in uber mode : false
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: map % reduce %
// :: INFO mapreduce.Job: Job job_1524619938432_0001 completed successfully
// :: INFO mapreduce.Job: Counters:
File System Counters
FILE: Number of bytes read=
FILE: Number of bytes written=
FILE: Number of read operations=
FILE: Number of large read operations=
FILE: Number of write operations=
HDFS: Number of bytes read=
HDFS: Number of bytes written=
HDFS: Number of read operations=
HDFS: Number of large read operations=
HDFS: Number of write operations=
Job Counters
Launched map tasks=
Launched reduce tasks=
Data-local map tasks=
Total time spent by all maps in occupied slots (ms)=
Total time spent by all reduces in occupied slots (ms)=
Total time spent by all map tasks (ms)=
Total time spent by all reduce tasks (ms)=
Total vcore-seconds taken by all map tasks=
Total vcore-seconds taken by all reduce tasks=
Total megabyte-seconds taken by all map tasks=
Total megabyte-seconds taken by all reduce tasks=
Map-Reduce Framework
Map input records=
Map output records=
Map output bytes=
Map output materialized bytes=
Input split bytes=
Combine input records=
Combine output records=
Reduce input groups=
Reduce shuffle bytes=
Reduce input records=
Reduce output records=
Spilled Records=
Shuffled Maps =
Failed Shuffles=
Merged Map outputs=
GC time elapsed (ms)=
CPU time spent (ms)=
Physical memory (bytes) snapshot=
Virtual memory (bytes) snapshot=
Total committed heap usage (bytes)=
Shuffle Errors
BAD_ID=
CONNECTION=
IO_ERROR=
WRONG_LENGTH=
WRONG_MAP=
WRONG_REDUCE=
File Input Format Counters
Bytes Read=
File Output Format Counters
Bytes Written=
输出结果可以从浏览器进入文件系统查看。
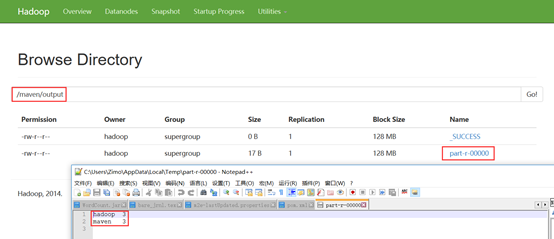
同样,运行我们的2.0版本的WordCount程序只需要将运行命令中的wordcount修改为wordcount2即可。
运行后文件系统中也出现了结果目录
到此,通过Maven框架管理多个MapReduce项目的步骤就到此结束了,大家可以多建几个MapReduce项目进行进一步测试。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
通过Maven管理多个MapReduce项目的更多相关文章
- IntelliJ IDEA 12创建Maven管理的Java Web项目(图解)
转:http://blog.csdn.net/zht666/article/details/8673609/ 本文主要使用图解介绍了使用IntelliJIDEA 12创建Maven管理的JavaWeb ...
- Eclipse/MyEclipse下如何Maven管理多个Mapreduce程序?(企业级水平)
不多说,直接上干货! 如何在Maven官网下载历史版本 Eclipse下Maven新建项目.自动打依赖jar包(包含普通项目和Web项目) Eclipse下Maven新建Web项目index.jsp报 ...
- IntelliJIDEA 14创建Maven管理的Java Web项目
1.新建项目,选择Maven,点击Next继续. 接着输入项目名 接着直接点击Finish即可 下图就是创建完毕后的Maven项目,双击pom.xml查看POM文件内容,可以自行添加Maven的依赖. ...
- *IntelliJ idea创建创建Maven管理的Java Web项目
配置IntelliJ在IntelliJ的设置中,可以设置maven的安装目录,settings.xml文件的位置,和本地仓库的位置等信息.
- IDEA14创建Maven管理的Java Web项目
刚开始进入公司实习,什么都不懂的小白,经过一上午加一点下午的时间,各种百度之后,终于找到了完整的流程,亲测成功,下面是我的一些步骤和图解,如果有什么错误,欢迎指正. 主要分为下面的几个步骤: 1.前期 ...
- 记录心得-IntelliJ iDea 创建一个maven管理的的javaweb项目
熟能生巧,还是记录一下吧~ 开始! 第一步:File--New--Project--Maven--Create from archetype--maven-archetype-webapp 第二步:解 ...
- 普通的javaweb项目和用maven管理的javaweb project的目录结构的区别
图一,图二 这种就是单独的建立普通的(也就是没有用maven管理包)javaweb项目的结构目录,这种需要将普通的jar依赖放到lib目录下,之后通过bulid 图一
- Maven管理 划分模块
转载地址:juvenshun.iteye.com/blog/305865 “分天下为三十六郡,郡置守,尉,监” —— <史记·秦始皇本纪> 所有用Maven管理的真实的项目都应该是分模块的 ...
- 如何在maven项目里面编写mapreduce程序以及一个maven项目里面管理多个mapreduce程序
我们平时创建普通的mapreduce项目,在遍代码当你需要导包使用一些工具类的时候, 你需要自己找到对应的架包,再导进项目里面其实这样做非常不方便,我建议我们还是用maven项目来得方便多了 话不多说 ...
随机推荐
- Python:easygui的安装、导入、使用、设置
转于:https://blog.csdn.net/sinat_37390744/article/details/55211652 博主:钏的博客 一.下载安装 1)下载0.96的easygui.htt ...
- Spring 3.1新特性之四:p命名空间设置注入(待补充)
https://www.ibm.com/developerworks/cn/java/j-lo-jparelated/ http://www.ibm.com/developerworks/cn/jav ...
- Nginx正则表达式之匹配操作符详解
nginx可以在配置文件中对某些内置变量进行判断,从而实现某些功能.例如:防止rewrite.盗链.对静态资源设置缓存以及浏览器限制等等.由于nginx配置中有if指令,但是没有对应else指令,所以 ...
- 韩顺平循序渐进学JAVA从入门到精通 视频全套,需要的联系我
0讲-开山篇.avi 10讲-访问修饰符.重载.覆盖.avi 11讲-约瑟夫问题.avi 12讲-多态.avi 13讲-抽象类.接口.avi 14讲-final.作业评讲.avi 15讲-作业.测试题 ...
- 为JFileChooser设定扩展名过滤
--------------------siwuxie095 工程名:TestFileChooser 包名:com.siwuxie095.fil ...
- p1098 逆序对
传送门 题目 输入格式: 第一行,一个数n,表示序列中有n个数. 第二行n个数,表示给定的序列. 输出格式: 给定序列中逆序对的数目. 数据范围: 对于50%的数据,n≤2500 对于100%的数据, ...
- 关于 char 和 unsigned char 的区别
首先卖个关子: 为什么网络编程中的字符定义一般都为无符号的字符? char buf[16] = {0}; unsigned char ubuf[16] = { 0 }; 上面两个定义的区别是: ...
- 第5季-小试牛刀-项目开发\阶段2-新手上路\项目-移动物体监控系统\Sprint0-产品设计与规划
lesson1---产品功能展示 先完成准备阶段,准备阶段要做的事情: a.项目经理选择团队, b.根据项目用户需求以及同类型的实物,制定产品功能列表 c.根据功能的难易程度,制定迭代周期以及在每周期 ...
- 【IDEA下使用tomcat部署web项目】
1.IDEA下的WEB项目新建就不说了. 2.配置tomcat:file-->settings-->Build,Execution,Deployment-->Application ...
- RDS mysql 与ECS自建mysql做主从备份
由于公司要组建一个数据中心,简而言之就是把各个地方的数据都同步到一个地方,做BI建模和数据分析. 一般来说这种需求是由hadoop来实现的,但由于预算不够..所以,来个low点的办法吧 以下主要是讲r ...