C Primer Plus学习笔记(二)- 数据和C
从一个简单的程序开始
#include <stdio.h> int main(void)
{
float weight;
float value; printf("Please enter your book's weight:"); scanf("%f", &weight); //用户输入 value = 17 * weight * 14.5833; printf("Your book's weight is %f and value is %.2f\n", weight, value); return 0;
}
程序运行结果

程序提示输入,156为输入的值,输入完成后要按Enter键,按Enter键是告诉计算机,你已经完成输入数据。
scanf("%f", &weight):scanf()函数用于读取键盘的输入,%f告诉scanf()函数要读取用户从键盘输入的浮点数,&weight告诉scanf()函数把输入的值赋给变量weight,scanf()函数使用&符号表明找到weight变量的地址。
scanf()函数读取用户从键盘输入的数据,并把数据传递给程序,printf()函数读取程序中的数据,并把数据显示在屏幕上。
printf()函数用%f来处理浮点值,%.2f中的“.2”用于精确控制输出,指定输出的浮点数只显示小数点后两位。
有些数据类型在程序使用之前已经预先设定好了,在整个程序的运行过程中没有变化,这些数据类型称为常量。17,14.5833就是常量。
其他数据类型在程序运行过程中可能会改变或被赋值,这些数据类型成为变量。weight,value就是变量。
位、字节和字:
位(bit)是最小的存储单位,可以存储0和1,或者说,位用于设置“开”或“关”,位是计算机内存的基本构建块。
字节(byte)是常用的计算机存储单位,1字节为8位,1位可以表示0或1,那么8位字节就有256(2的8次方)种可能的0、1的组合。
字(word)是设计计算机时给定的自然存储单位,计算机的字长越大,其数据转移越快,允许的内存访问也更多。
整数和浮点数:
和数学的概念一样,在C语言中,整数是没有小数部分的数,计算机以二进制数字储存整数。
浮点数和整数的储存方案不同,计算机把浮点数分成小数部分和指数部分来表示,而且分开来储存这两部分,7.00和7的值是一样的,但是储存方式不同。
在十进制中。可以把7.0写成0.7E1,0.7是小数部分,E后的1是指数部分。
计算机在内部使用二进制和2的幂进行储存,而不是10的幂。
2.75,3.16E7,7.00,2e-8都是浮点数,3.16E7表示3.16*107 ,7被称为指数。
整数和浮点数的区别:
整数没有小数部分,浮点数有小数部分。
浮点数可以表示的范围比整数大。
对于一些运算,浮点数损失的精度更多。
计算机的浮点数不能表示区间内所有的值,浮点数通常只是实际值的近似值。
int类型:
int类型是有符号的整型,int类型的值必须是整数,可以是正的,也可以是负的,也可以是0。
ISO C规定int的取值范围最小为-32768~32767。
声明int变量:先写上int,然后写变量名,最后加上一个分号
int weight; //声明一个int类型的变量
int weight, height; //声明多个int类型的变量
然后可以通过直接赋值给变量赋值,也可以通过函数给变量赋值
weight = 200; //直接赋值给变量
scanf("%d", &weight); //通过函数赋值
初始化变量:初始化变量就是为变量赋一个初始值。
在C语言中,初始化可以直接在声明中完成。在变量名后面加上赋值运算符(=)和待赋值给变量的值。
int one = 1; int two =2, three = 3; int four, five = 5;
第3行中的four并没有被赋值,只有five被赋值。最好不要把初始化的变量和未初始化的变量放在同一条声明中。
声明为变量创建和标记存储空间,并为其指定初始值。
打印int类型的值:%d指明了在一行中打印整数的位置
#include <stdio.h> int main(void)
{
int one = 1;
int five = 5; printf("One is %d and Five is %d, their subtraction is %d\n", one, 5, five - one);
printf("First is %d, %d, %d, %d, %d, %d\n", one); //少了5个参数 return 0;
}
运行结果
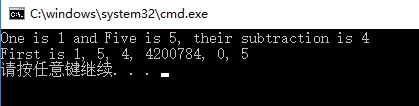
第一行中,第1个%d对应的是int类型变量one,第2个%d对应的是int类型常量5,第3个%d对应的为int类型表达式five - one的值。
第二行中,第1个%d对应的是int类型变量one,没有给后面的5个%d传值,所以打印出的值是内存中的任意值。
在不同的平台下,缺少参数或参数类型不匹配导致的结果不同。
八进制和十六进制:
0前缀表示八进制,十进制16表示成八进制为020。
0x或0X前缀表示十六进制,十进制16表示成十六进制是0x10或0X10。
打印八进制和十六进制:
以十进制打印数字,使用%d
以八进制打印数字,使用%o
以十六进制打印数字,使用%x
如果要显示各进制的前缀0,0x和0X,分别用%#o,%#x,%#X
#include <stdio.h> /*以十进制、八进制、十六进制打印十进制数100*/
int main(void)
{
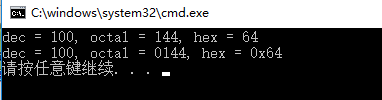
int x = 100; printf("dec = %d, octal = %o, hex = %x\n", x, x, x);
printf("dec = %d, octal = %#o, hex = %#x\n", x, x, x); return 0;
}
运行结果
其他整数类型:
short int 类型(或者简写成 short)占用的存储空间可能比 int 类型少,常用于小数值的场合以节省空间,short 有符号类型。
long int 或 long 占用的存储空间可能比 int 多。试用于较大数值的场合,long 也是有符号类型的。
long long int 或 long long 占用的储存空间可能比 long 多,适用于更大数值的场合,该类型至少占64位,long long 有符号类型。
unsigned int 或 unsigned,unsigned short int 或 unsigned short,unsigned long int 或 unsigned long,unsigned long long int 或 unsigned long long 只用于非负值的场合,这种类型与有符号类型表示的范围不同。16位 unsigned int 允许的取值范围是 0~65535,而不是-32768~32767。
在任何有符号类型前面添加关键字 signed,可强调使用有符号类型的意图。
使用多种整数类型的原因:
C语言规定short占用的存储空间不能多于 int,long 占用的存储空间不能少于 int。
现在最常见的设置是,long long 占64位,long 占32位,int 占16位或32位,short 占16位。
这4种类型代表4种不同的大小,但是实际使用中,有些类型之间通常用重叠。
C标准对基本数据类型规定了允许的最小大小。
对于16位机,short 和 int 的最小取值范围为[-32767,32767]
对于32位机,long 的最小取值范围为[-2147483647,2147483647]
对于 unsigned short 和 unsigned int ,最小取值范围为[0,65535]
对于 unsigned long,最小取值范围为[0,4294967295]
long long 的最小取值范围为[-9223372036854775807,9223372036854775807]
unsigned long long 的最小取值范围为[0,18446744073709551615]
用int类型首先考虑 unsigned 类型,这种类型的数常用于计数,unsigned 也可以表示更大的正数。
如果一个数超出了 int 类型的取值范围,且在 long 类型的取值范围内时,使用 long 类型。
long常量和long long常量:
如果数字超出了int可表示的最大值,编译器就会将其视为long int类型,如果超出了long可表示的最大值,编译器就会将其视为unsigned long类型,如果还不够大,编译器就会将其视为long long或unsigned long long类型。
八进制和十六进制常量被视为int类型,如果值太大,编译器就会使用unsigned int,如果还不够大,编译器会依次使用long,unsigned long,long long和unsigned long long类型。
要把一个较小的数作为long类型对待,可以在值的末尾加上l或L后缀,八进制和十六进制也适用l和L后缀。
在支持long long类型的系统中,也可以使用ll或LL后缀来表示long long类型的值
u或U后缀表示unsigned
整数超出了相应类型的取值范围:
#include <stdio.h> int main(void)
{
int i = 2147483647;
unsigned int j = 4294967295; printf("%d %d %d\n", i, i+1, i+2);
printf("%d %d %d\n", j, j+1, j+2); return 0;
}
运行结果
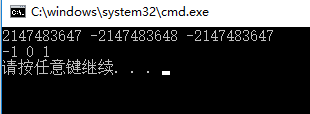
在超过最大值时,unsigned int类型的变量j从0开始,而int类型的变量i从-2147483648开始
当i超出(溢出)其相应类型所能表达的最大值时,系统并未通知用户,需要自己注意这类问题
打印short、long、long long和unsigned类型:
打印unsigned int类型的值,使用%u转换说明
打印long类型的值,使用%ld转换说明
打印八进制long类型的值,使用%lo转换说明
打印十六进制long类型的值,使用%lx转换说明
虽然C语言允许使用大写或小写的常量后缀,但是在转换说明中只能用小写
对于short类型,使用h前缀
%hd表示打印十进制short类型的整数
%ho表示打印八进制short类型的整数
h和l前缀都可以和u一起使用,用于表示无符号类型
支持long long类型的系统,%lld和%llu分别表示有符号和无符号类型
#include <stdio.h> int main(void)
{
unsigned int un = 3000000000;
short end = 200;
long big = 65537;
long long verybig = 12345678908642; printf("un = %u and not %d\n", un, un);
printf("end = %hd and %d\n", end, end);
printf("big = %ld and not %hd\n", big, big);
printf("verybig = %lld and not %ld\n", verybig, verybig); return 0;
}
运行结果
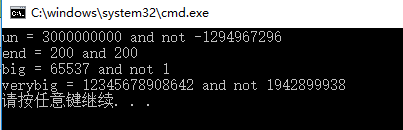
第1行输出,对于无符号变量un,使用%d会产生负值,因为无符号值3000000000和有符号值-1294967296在系统内存中的内部表示完全相同
在待打印的值大于有符号值的最大值时,会发生这种无符号和有符号所打印的值不同的情况
对于较小的正数,有符号和无符号类型的存储、显示都相同
第2行输出,对于short类型的变量end,在printf()中无论指定以short类型(%hd)还是int类型(%d)打印,打印出来的值都相同
这是因为在给函数传递参数的时候,C编译器把short类型的值自动转换成int类型的值
int类型被认为是计算机处理整数类型时最高效的类型
使用h修饰符的用处:使用h修饰符可以显示较大整数被截断成short类型值的情况
第3行输出,把65537以二进制格式写成一个32位是00000000000000010000000000000001,使用%hd,printf()只会查看后16位,所以显示的值是1
第4行输出,使用了%ld,printf()只显示了储存在后32位的值
char类型:
char类型用于储存字符,char也是整数类型,因为char类型实际上储存的是整数而不是字符,整数和字符通过ASCII码互相对应
C语言把字符常量视为int类型而不是char类型
一般来说,C语言会保证char类型足够大,以储存系统(实现C语言的系统)的基本字符集
C语言把1字节定义为char类型占用的位(bit)数
C语言允许在关键字char前面使用signed或unsigned,signed char表示有符号类型,unsigned char表示无符号类型,如果只用char处理字符,char前面不需要使用任何修饰符
有符号char可表示的范围为-128~127,无符号char可表示的范围为0~255
字符常量和初始化:
char grade = 'A'; 或者 char grade = 65;
单引号括起来的是字符,双引号括起来的是字符串
非打印字符:
单引号只适用于字符、数字和标点符号,有些ASCII字符是打印不出来的
C语言中有3种方法打印这些字符:
第1种是用ASCII码
第2种是用特殊的符号序列表示一些特殊的字符,这些字符序列叫做转义序列
| 转义序列 | 含义 |
| \a | 警报 |
| \b | 退格 |
| \f | 换页 |
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \\ | 反斜杠(\) |
| \' | 单引号 |
| \" | 双引号 |
| \? | 问号 |
| \0oo | 八进制值(oo必须是有效的八进制数,即每个o可表示0~7中的一个数) |
| \xhh | 十六进制(hh必须是有效的十六进制数,即每个h可表示0~f中的一个数) |
如果要用八进制ASCII码表示一个字符,可以在编码值前面加一个反斜杠(\),并用单引号括起来
十进制、八进制、十六进制都可以表示字符常量
打印字符:
printf()函数用%c指明待打印的字符
一个字符变量被储存为1字节的整数值,所以可以用%d打印char类型的整数值
#include <stdio.h> /*字符ASCII码*/
int main(void)
{
char ch = 'B'; printf("The code for %c is %d\n", ch, ch); return 0;
}
运行结果
_Bool类型:
_Bool类型用于表示布尔值,true和false
C语言中可以用1表示true,0表示false,所以_Bool类型也是一种整数类型
float、double、和long double:
C标准规定,float类型必须至少能表示6位有效数字,且取值范围至少是10-37~10+37
通常系统储存一个浮点数要占用32位,其中8位用于表示指数的值和符号,剩下24位用于表示非指数部分(也叫作尾数或有效数)及其符号
double类型和float类型的最小取值范围相同,但至少必须能表示10位有效数字,实际上double类型的值至少有13位有效数字
long double类型的精度比double类型更高,但C只保证long double类型至少与double类型的精度相同
浮点型常量:
浮点型常量的基本形式是:有符号的数字(包括小数点),后面紧跟e或E,最后一个是有符号数表示10的指数
可以没有小数点(如,2E5)或指数部分(如,19.28),但是不能同时省略两者
可以省略小数部分(如,3.E16)或整数部分(如,.45E-6),但是不能同时省略两者
不能在浮点型常量中间加空格,如156 E+12
默认情况下,编译器假定浮点型常量是double类型的精度
通常,4.0和2.0被储存为64位的double类型,使用双精度进行乘法运算,然后将乘积截断成float类型的宽度
在浮点数后面加上f或F后缀可覆盖默认设置,编译器会将浮点型常量看作float类型,如2.3f和9.11E9F
使用l或L后缀使得数字成为long double类型,没有后缀的浮点型常量是double类型
打印浮点值:
printf()函数使用%f转换说明打印十进制记数法的float和double类型浮点数
用%e打印指数记数法的浮点数
如果系统支持用十六进制格式的浮点数,可用a和A分别代替e和E
用%Lf,%Le,%La打印long double类型
浮点值的上溢和下溢:
float toobig = 3.4E38 * 100.0f;
printf("%e\n", toobig);
当计算导致数字过大,超过当前类型能表达的范围时,就会发生上溢
在这种情况下会给toobig赋一个表示无穷大的特定值,而且printf()显示该值为int或infinity(或者具有无穷含义的其他内容)
在计算过程中损失了原末尾有效位数上的数字,这种情况叫做下溢
C语言把损失了类型全精度的浮点值称为低于正常的浮点值
因此,把最小的正浮点数除以2将得到一个低于正常的值,如果除以一个非常大的值,会导致所有的位都为0
如果传入的值超出了函数规定的范围,函数将返回NaN值
复数和虚数类型:
C语言的3种复数类型:float _Complex,double _Complex和long double _Complex
C语言的3种虚数类型:float _Imaginary,double _Imaginary和long double _Imaginary
如果包含complex.h头文件,就可以用complex代替_Complex,用imaginary代替_Imaginary
类型大小:
sizeof是C语言的内置运算符,以字节为单位给出指定类型的大小
C99和C11提供%zd转换说明匹配sizeof的返回类型,一些不支持C99和C11的编译器可用%u或%lu代替%zd转换说明匹配sizeof的返回类型
在char类型为16位,double类型为64位的系统中,sizeof给出的double是4字节
运算对象是类型时,圆括号不能少,如,sizeof(char),但是对于特定量,可有可无,如sizeof name,sizeof 6.28
在limits.h和float.h头文件中有类型限制的相关信息
使用数据类型:
把一个类型的数值初始化给不同类型的变量时,编译器会把值转换成与变量匹配的类型,这将导致部分数据丢失
C编译器把浮点数转换成整数时,会直接丢弃(截断)小数部分,而不进行四舍五入
C只保证了float类型前6位的精度
刷新输出:
printf()语句把输出发送到一个叫做缓冲区的中间存储区域,然后缓冲区中的内容再不断被发送到屏幕上
C标准明确规定了何时把缓冲区中的内容发送到屏幕:当缓冲区满、遇到换行字符或需要输入的时候(从缓冲区把数据发送到屏幕或文件被称为刷新缓冲区)
C Primer Plus学习笔记(二)- 数据和C的更多相关文章
- C Primer Plus学习笔记(二)
1. C的左值用是指用于标志一个特定的数据对象的名字或表达式.“数据对象”是泛指数据存储的术语. 赋值运算符的左边应该是以个可以修改的左值. 右值是指可赋给可修gia的左值的量.右值可以是常量.变量或 ...
- Spring.Net学习笔记(二)-数据访问器
Spring对ADO.NET也提供了支持,依赖与程序集Spring.Data.dll IDbProvider IDbProvider定义了数据访问提供器的基础,配置如下 <?xml versio ...
- openresty 学习笔记二:获取请求数据
openresty 学习笔记二:获取请求数据 openresty 获取POST或者GET的请求参数.这个是要用openresty 做接口必须要做的事情.这里分几种类型:GET,POST(urlenco ...
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
- [Firefly引擎][学习笔记二][已完结]卡牌游戏开发模型的设计
源地址:http://bbs.9miao.com/thread-44603-1-1.html 在此补充一下Socket的验证机制:socket登陆验证.会采用session会话超时的机制做心跳接口验证 ...
- Windows phone 8 学习笔记(2) 数据文件操作
原文:Windows phone 8 学习笔记(2) 数据文件操作 Windows phone 8 应用用于数据文件存储访问的位置仅仅限于安装文件夹.本地文件夹(独立存储空间).媒体库和SD卡四个地方 ...
- Java IO学习笔记二
Java IO学习笔记二 流的概念 在程序中所有的数据都是以流的方式进行传输或保存的,程序需要数据的时候要使用输入流读取数据,而当程序需要将一些数据保存起来的时候,就要使用输出流完成. 程序中的输入输 ...
- 《SQL必知必会》学习笔记二)
<SQL必知必会>学习笔记(二) 咱们接着上一篇的内容继续.这一篇主要回顾子查询,联合查询,复制表这三类内容. 上一部分基本上都是简单的Select查询,即从单个数据库表中检索数据的单条语 ...
- NumPy学习笔记 二
NumPy学习笔记 二 <NumPy学习笔记>系列将记录学习NumPy过程中的动手笔记,前期的参考书是<Python数据分析基础教程 NumPy学习指南>第二版.<数学分 ...
随机推荐
- hadoop 指定 key value分隔符
原文:http://wingmzy.iteye.com/blog/1260570 hadoop中的map-reduce是处理<key,value>这样的键值对,故指定<key,val ...
- 中文乱码之myEclipse项目导入时中文乱码(待)
方法1:检查默认的编码是否设置成utf-8. 步骤如图: window——>preferences... 若Text file encoding 中的编码为 Other == UTF-8 ,则已 ...
- Mac键盘图标与对应快捷按键标志汇总 分类
Mac键盘图标与对应快捷按键 ⌘——Command () win键 ⌃ ——Control ctrl键 ⌥——Option (alt) ⇧——Shift ⇪——Caps Lock fn——功能键就是 ...
- Java -- JDBC 批处理
两种批处理方式: 采用Statement.addBatch(sql)方式实现批处理: •优点:可以向数据库发送多条不同的SQL语句. •缺点: •SQL语句没有预编译. •当向数据库发送多条语句相同, ...
- JavaScript -- 操作input CheckBox 全选框
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- Android在layout xml中使用ViewStub完成动态加载
Android在layout xml中使用ViewStub完成动态加载 一.Layout XML文件常见的两种模块加载方式 1.静态加载:被加载的模块和其它模块加载的时间一样. <include ...
- jsonp: js跨域
JSONP是JSON with padding(填充式JSON或参数式JSON)的简写,是应用JSON的一种新方法,常用于服务器与客户端跨源通信,在后来的Web服务中非常流行.本文将详细介绍JSONP ...
- APP测试的那些坑
在记录app测试走过的那些坑之前,先总结下app测试的工作主要有哪些: 1.功能测试,无论是什么软件产品,必不可少的就是功能测试.我们需要测试这款app产品的功能是否完善,是否符合客户需求,是否符 ...
- KNN cosine 余弦相似度计算
# coding: utf-8 import collections import numpy as np import os from sklearn.neighbors import Neares ...
- Nodejs调试技术总结
调试技术与开发技术构成了软件开发的基石.目前Nodejs作为新型的Web Server开发栈倍受开发者关注.总的来说Nodejs的应用程序主要有两部分:JavaScript编写的js模块和C语言编译的 ...