ceph数据自动均衡程序
声明:程序基于ceph0.94.x制作
前言:
ceph数据自动均衡,为了解决新集群搭建完成和添加新的节点后,不同或者相同容量的磁盘上面pg的分布不均衡,导致集群使用率达不到理想的标准
调整前准备:
为了数据安全,请提前将crush规则备份到合适的位置(调整前会在当前目录下备份一个)
ceph osd getcrushmap -o ceph_crush_map_backup
临时关闭集群的值:
scrub deep-scrub nobackfill norecover(待pg分布理想状态后开启norecover和nobackfill,待数据同步完毕开启scrub和deep-scrub)
调整数据同步的速度参考磨神博客:
http://www.zphj1987.com/2016/04/24/backfill%E5%92%8Crecovery%E7%9A%84%E6%9C%80%E4%BC%98%E5%80%BC/
计算pg的程序引用:
http://cephnotes.ksperis.com/blog/2015/02/23/get-the-number-of-placement-groups-per-osd/
参数说明:
程序中有三个可调值(有标注)
第一个值默认为1,增加后可提高调整的精度
第二个值默认为2,用于设置需要调整的osd所占数量之比
第三个值默认为1,用于设置调整的次数
实现逻辑:
磁盘的数据趋向于均衡的逻辑比较简单:将osd设置合适的权重使磁盘容量分布合理的pg数
实现前提:
假设相同容量的磁盘pg数量一样,磁盘的使用率就一样;
假设1T的容量对应的权重为1(建议添加osd时设置0.8);
假设集群中主要的数据都在一个pool内保存(需要给各个池设置合理的pg比例个数,请参考https://ceph.com/pgcalc)
实现过程:
1、首先需要计算出对应池里面的pg个数和副本数乘积;
2、获取集群中的磁盘容量类型:(类型越少,数据会越平均);
3、通过磁盘的类型和数量的累加可以得到集群的总容量;
4、获取运行集群的权重,(运行的权重和crush的权重的比例为65535);
5、将集群的容量换算为T与集群的权重进行比例,以获得动态的比例值,增加调整的准确度;
6、获取权重0.1对应的容量;
7、获取每个G对应的pg个数;
8、使用0.1除以(0.1对应的容量和每个G对应的pg的乘积)算出对应1个pg对应的权重;
9、计算出磁盘应该承载的pg个数和现有pg的差乘以单个pg的权重加上现有的权重就可以得到pg应该获得权重;
执行结果:
9 #第一行为总共调整的次数
1 #执行当前的次数
osd.0 1.67163 107.7321 107 #osd编号、当前权重、最理想的pg个数、当前的pg个数
ceph osd crush reweight osd.0 1.67299 #设置的权重
reweighted item id 0 name 'osd.0' to 1.67299 in crush map
dumped all in format plain
osd.0 108 #设置后的pg个数
经过调整后的效果:
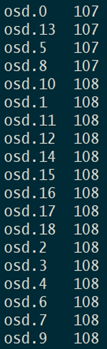
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
#!/bin/bash
# mail:863604721@qq.com
DIR=`pwd`
DIR="${DIR}/"
PGNUM=$( echo "scale=1; $(ceph osd pool get volumes pg_num|awk '{print $2}') * $(ceph osd pool get volumes size|awk '{print $2}')" | bc )
TOTAL_SIZE=0
ceph osd df|grep -v "TOTAL\|WEIGHT\|MIN"|awk '$8>0 {print $0}'|awk '{print $4}'|sort -u|sed 's/G//g' > "${DIR}osd_size.txt"
> "${DIR}osd_size_num.txt"
while read osd_size
do
num=`ceph osd df|grep -v "TOTAL\|WEIGHT\|MIN"|awk '$8>0 {print $0}'|awk '{print $4}'|grep ${osd_size}|wc -l`
echo "${osd_size} ${num}" >> ${DIR}osd_size_num.txt
let "TOTAL_SIZE+=${osd_size}*$num"
#echo "${TOTAL_SIZE}"
done < "${DIR}osd_size.txt"
run_weight=`ceph osd crush dump|grep -A 5 '"type_name": "root"'|awk -F '"weight":' '{print $2}'|grep [0-9]|sed 's/,//g'`
weight=`echo "scale=3;${run_weight} / 65535" |bc`
function_a=`echo "scale=6;${TOTAL_SIZE} / 1024" |bc`
function=`echo "scale=3;${weight} / ${function_a}" |bc`
function_b=`echo "scale=3;1 / ${function} * 102.4" |bc`
RATIO=`echo "scale=4;${PGNUM} / ${TOTAL_SIZE}" |bc`
STANDARDS=`echo "scale=6;${RATIO} * ${function_b} * 1"|bc` #变大此值可增加精度,默认为1
SET_STANDARD=`echo "scale=6;0.1 / ${STANDARDS}"|bc`
#echo "${SET_STANDARD}"
getpg(){
ceph pg dump | awk '
/^pg_stat/ { col=1; while($col!="up") {col++}; col++ }
/^[0-9a-f]+\.[0-9a-f]+/ { match($0,/^[0-9a-f]+/); pool=substr($0, RSTART, RLENGTH); poollist[pool]=0;
up=$col; i=0; RSTART=0; RLENGTH=0; delete osds; while(match(up,/[0-9]+/)>0) { osds[++i]=substr(up,RSTART,RLENGTH); up = substr(up, RSTART+RLENGTH) }
for(i in osds) {array[osds[i],pool]++; osdlist[osds[i]];}
}
END {
printf("\n");
printf("pool :\t"); for (i in poollist) printf("%s\t",i); printf("| SUM \n");
for (i in poollist) printf("--------"); printf("----------------\n");
for (i in osdlist) { printf("osd.%i\t", i); sum=0;
for (j in poollist) { printf("%i\t", array[i,j]); sum+=array[i,j]; poollist[j]+=array[i,j] }; printf("| %i\n",sum) }
for (i in poollist) printf("--------"); printf("----------------\n");
printf("SUM :\t"); for (i in poollist) printf("%s\t",poollist[i]); printf("|\n");
}'
}
ceph osd getcrushmap -o "${DIR}crushmap" > /dev/null 2>&1
run_num=`echo "$(ceph osd ls|wc -l) / 2" |bc` #调整osd的所占比,默认为2
echo $run_num
for i in $(seq 1 ${run_num}) #通过改变此值可以修改调整osd的数量,默认为1
do
echo $i
getpg |grep osd|awk '{print $1" "$2}' > "${DIR}"pg_table.txt
while read osd_size
do
PG_NUM=`echo "$osd_size * $RATIO" | bc`
ceph osd df|grep -v "TOTAL\|WEIGHT\|MIN"|awk '$8>0 {print $0}'|awk '{print $1"\t"$2"\t"$4"\t"$7}'|grep "${osd_size}" > "${DIR}""${osd_size}.txt"
sed -i "s/^/osd./g" "${DIR}""${osd_size}.txt"
sed -i "s/$/\t${PG_NUM}/" "${DIR}""${osd_size}.txt"
while read osd_id pg_num
do
sed -i "/\<${osd_id}\>/ s/$/\t${pg_num}/" "${DIR}""${osd_size}.txt"
done < "${DIR}"pg_table.txt
done < "${DIR}"osd_size.txt
while read osd_size
do
osd_nu=`cat ${DIR}${osd_size}.txt |sort -n -k 6|head -n1|awk '{print $1}'`
alter_price=`cat ${DIR}${osd_size}.txt |sort -n -k 6|head -n1|awk \
'{mean_pg = $5;run_pg = $6;SET_STANDARD = '${SET_STANDARD}';RUN_WEIGHT = $2;} END {average = mean_pg-run_pg;average0 = average * SET_STANDARD;print average1 = average0+RUN_WEIGHT }'`
cat ${DIR}${osd_size}.txt|grep -w "${osd_nu}"|awk '{print $1"\t"$2"\t"$5"\t"$6}'
echo 'ceph osd crush reweight' "${osd_nu}" "${alter_price}"
ceph osd crush reweight "${osd_nu}" "${alter_price}"
sleep 8
getpg |grep -w "${osd_nu}"|awk '{print $1"\t"$2}'
osd_nu_h=`cat ${DIR}${osd_size}.txt |sort -n -k 6|tail -n1|awk '{print $1}'`
alter_price_h=`cat ${DIR}${osd_size}.txt |sort -n -k 6|tail -n1|awk \
'{mean_pg = $5;run_pg = $6;SET_STANDARD = '${SET_STANDARD}';RUN_WEIGHT = $2;} END {average = mean_pg-run_pg;average0 = average * SET_STANDARD;print average1 = average0+RUN_WEIGHT }'`
cat "${DIR}${osd_size}.txt"|grep -w "${osd_nu_h}"|awk '{print $1"\t"$2"\t"$5"\t"$6}'
echo 'ceph osd crush reweight' "${osd_nu_h}" "${alter_price_h}"
ceph osd crush reweight "${osd_nu_h}" "${alter_price_h}"
sleep 8
getpg |grep -w "${osd_nu_h}"|awk '{print $1"\t"$2}'
done < "${DIR}osd_size.txt"
done
ceph数据自动均衡程序的更多相关文章
- C#之tcp自动更新程序
.NETTCP自动更新程序有如下几步骤: 第一步:服务端开启监听 ServiceHost host; private void button1_Click(object sender, EventAr ...
- winform自动更新程序实现
一.问题背景 本地程序在实际项目使用过程中,因为可以操作电脑本地的一些信息,并且对于串口.OPC.并口等数据可以方便的进行收发,虽然现在软件行业看着动不动都是互联网啊啥的,大有Web服务就是高大上的感 ...
- ibatis实战之插入数据(自动生成主键)
ibatis实战之插入数据(自动生成主键) --------- 如果你将数据库设计为使用自动生成的主键,就可以使用ibatis的<selectKey>元素(该元素是<insert&g ...
- ios Coredata 关联 UITableView 数据自动更新
昨天写了一篇关于coredata的文章,自己觉得挺傻的文章.没想其它程序员看过后觉得更傻,于是今天决定写一篇厉害点的,首先写了一个coredata和uitableview结合的框架,非常简单实现了数据 ...
- C#.Net版本自动更新程序及3种策略实现
C#.Net版本自动更新程序及3种策略实现 C/S程序是基于客户端和服务器的,在客户机编译新版本后将文件发布在更新服务器上,然后建立一个XML文件,该文件列举最新程序文件的版本号及最后修改日期.如程序 ...
- dk.exe自动填报程序的反编译
dk.exe自动填报程序的反编译 dk.exe用于学校每日健康报的自动填写.
- Salesforce Apex 使用JSON数据的示例程序
本文介绍了一个在Salesforce Apex中使用JSON数据的示例程序, 该示例程序由以下几部分组成: 1) Album.cls, 定了了封装相关字段的数据Model类 2) RestClient ...
- ASP.NET网站版本自动更新程序及代码[转]
1.自动更新程序主要负责从服务器中获取相应的更新文件,并且把这些文件下载到本地,替换现有的文件.达到修复Bug,更新功能的目的.用户手工点击更新按钮启动更新程序.已测试.2.环境VS2008,采用C# ...
- SNF开发平台WinForm之八-自动升级程序部署使用说明-SNF快速开发平台3.3-Spring.Net.Framework
9.1运行效果: 9.2开发实现: 1.首先配置服务器端,把“SNFAutoUpdate2.0\服务器端部署“目录按网站程序进行发布到IIS服务器上. 2.粘贴语句,生成程序 需要调用的应用程序的Lo ...
随机推荐
- thrift rpc 使用常见问题解答和经验
Thrift是一个非常棒的工具,是Facebook的开源项目,目前的开发非常的活跃,由Apache管理,所以用的是Apache Software License,这非常重要,因为可以放心的对其修改并用 ...
- [cinder] volume type 使用简记
cinder type-create sharecinder type-key share set volume_backend_name=GLUSTERFScinder type-create lo ...
- Spring学习十 rest
1: Web service: 是一个大的概念范畴,它表现了一种设计思想 SOAP 是 Web service 的一个重要组成部份. SOAP 是一种协议而非详细产品.SOAP 是通过 XML ...
- 2015.9.28 不能将多个项传入“Microsoft.Build.Framework.ITaskItem”类型的参数 问题解决
方法是:项目->属性->安全性->启用ClickOnce安全设置, 把这个复选框前面的勾去掉就可以了.
- 第十三章 Spring框架的设计理念与设计模式分析(待续)
Spring的骨骼架构 核心组件详解 Spring中AOP的特性详解 设计模式解析之代理模式 设计模式解析之策略模式
- Solaris Tips: Repairing the Boot Archive (ZT)
http://www.seedsofgenius.net/solaris/solaris-tips-repairing-the-boot-archive 注意以下是系统盘非镜像情况下的操作,如果系统盘 ...
- 解决springMVC文件上传报错: The current request is not a multipart request
转自:https://blog.csdn.net/HaHa_Sir/article/details/79131607 解决springMVC文件上传报错: The current request is ...
- JS中substring()方法(用于提取字符串中介于两个指定下标之间的字符)
<!DOCTYPE html> <html> <head> <meta charset="UTF-8"> <title> ...
- spring整合mybatis的事物管理配置
一.基本配置 <?xml version="1.0" encoding="UTF-8"?> <beans xmlns="http:/ ...
- ie6-ie8不支持opacity,rgba解决方法
半透明部分设置样式:opacity:0.7在ie9/ie10/ff/chrome/opera/safari显示正常. 但是这样在ie6-ie8中是不支持的,需要加上下面这句话: filter: pro ...