cookie操作和代理
cookie操作
爬取豆瓣个人主页
# -*- coding: utf-8 -*-
import scrapy class DoubanSpider(scrapy.Spider):
name = 'douban'
#allowed_domains = ['www.douban.com']
start_urls = ['https://www.douban.com/accounts/login'] #重写start_requests方法
def start_requests(self):
#将请求参数封装到字典
data = {
'source': 'index_nav',
'form_email': '',
'form_password': 'bobo@15027900535'
}
for url in self.start_urls:
yield scrapy.FormRequest(url=url,formdata=data,callback=self.parse)
#针对个人主页页面数据进行解析操作
def parseBySecondPage(self,response):
fp = open('second.html', 'w', encoding='utf-8')
fp.write(response.text) #可以对当前用户的个人主页页面数据进行指定解析操作 def parse(self, response):
#登录成功后的页面数据进行存储
fp = open('main.html','w',encoding='utf-8')
fp.write(response.text) #获取当前用户的个人主页
url = 'https://www.douban.com/people/185687620/'
yield scrapy.Request(url=url,callback=self.parseBySecondPage)
因为要进行登录操作,所以一定要使用post请求进行表单提交,那么就必须重写start_requests()方法;观察代码就可以发现,当登录成功之后再次请求个人主页,不再需要
刻意地处理cookie,那是因为scrapy已经帮我们省去了这样的操作:第一次请求返回的cookie会在第二请求发送的时候被携带。
代理
import scrapy class ProxydemoSpider(scrapy.Spider):
name = 'proxyDemo'
#allowed_domains = ['www.baidu.com/s?wd=ip']
start_urls = ['https://www.baidu.com/s?wd=ip'] def parse(self, response):
fp = open('proxy.html','w',encoding='utf-8')
fp.write(response.text)
配置好配置文件,然后再执行,在proxy.html文件中就会看到本机ip的浏览器页面,ip就是真实的本机ip。
那如何更改ip呢?就用到了代理,在scrapy中使用代理操作需要对下载中间件下手。
那么什么是下载中间件呢?
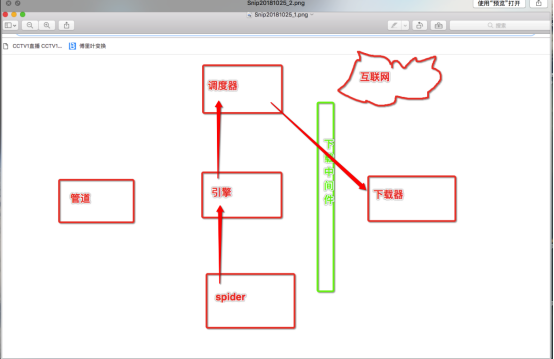
下载中间件的作用就是拦截请求,将请求的ip进行更换。
流程:
1. 下载中间件类的自制定
a) 继承object
b) 重写process_request(self,request,spider)的方法
2. 配置文件中进行下载中间价的开启。
middlewares.py 就是下载中间件的定义文件
from scrapy import signals #自定义一个下载中间件的类,在类中实现process_request(处理中间价拦截到的请求)方法
class MyProxy(object):
def process_request(self,request,spider):
#请求ip的更换
request.meta['proxy'] = "https://178.128.90.1:8080" # 这里需要一个有效的代理ip
开启下载中间件
# Enable or disable downloader middlewares
# See https://doc.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'proxyPro.middlewares.MyProxy': 543, # 数字大小代表优先级
}
再次执行,打开页面发现ip就被更改了!
cookie操作和代理的更多相关文章
- 爬虫--requests模块高级(代理和cookie操作)
代理和cookie操作 一.基于requests模块的cookie操作 引言:有些时候,我们在使用爬虫程序去爬取一些用户相关信息的数据(爬取张三“人人网”个人主页数据)时,如果使用之前requests ...
- Python脚本控制的WebDriver 常用操作 <二十八> 超时设置和cookie操作
超时设置 测试用例场景 webdriver中可以设置很多的超时时间 implicit_wait.识别对象时的超时时间.过了这个时间如果对象还没找到的话就会抛出异常 Python脚本 ff = webd ...
- cookie操作大全
JavaScript中的另一个机制:cookie,则可以达到真正全局变量的要求. cookie是浏览器 提供的一种机制,它将document 对象的cookie属性提供给JavaScript.可以由J ...
- js 判断js函数、变量是否存在 JS保存和删除cookie操作,判断cookie是否存在的方法
//是否存在指定函数 function isExitsFunction(funcName) { try { if (typeof(eval(funcName)) == " ...
- JS封装cookie操作函数实例(设置、读取、删除)
本文实例讲述了JS封装cookie操作函数.分享给大家供大家参考,具体如下: ? 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 ...
- 网上收集的WebBrowser的Cookie操作
原文:网上收集的WebBrowser的Cookie操作 1.WebBrowser设置Cookie Code highlighting produced by Actipro CodeHighlight ...
- 学习笔记: JavaScript/JQuery 的cookie操作
转自:http://blog.csdn.net/barryhappy/archive/2011/04/27/6367994.aspx cookie是网页存储到用户硬盘上的一小段信息.最常见的作用是判断 ...
- js实用方法记录-简单cookie操作
js实用方法记录-简单cookie操作 设置cookie:setCookie(名称,值,保存时间,保存域); 获取cookie:setCookie(名称); 移除cookie:setCookie(名称 ...
- 前端cookie操作用到的一些小总结
前后端完全分离的是目前web开发的大趋势,包括现下流行的前端框架的应用vue,angular,在不同页面跳转时,前端需要对用户登录状态进行判断,拿到用户的id,除了Ajax从服务器端获取数据外,对co ...
随机推荐
- cf1059D. Nature Reserve(三分)
题意 题目链接 Sol 欲哭无泪啊qwq....昨晚一定是智息了qwq 说一个和标算不一样做法吧.. 显然\(x\)轴是可以三分的,半径是可以二分的. 恭喜你获得了一个TLE的做法.. 然后第二维的二 ...
- MarkDown 编辑器学习
MarkDown 编辑器学习 是一种简单快键的文字排版工具,可以用于编写说明文档,鉴于其语法简洁明了,且其渲染生成的样式简单美观,很多开发者也用它来写博客,已被国内外很多流行博客平台所支持.生成的文件 ...
- (生产)vue-router:路由
参考:https://router.vuejs.org/zh-cn/ 安装 直接下载 / CDN https://unpkg.com/vue-router/dist/vue-router.js 使用: ...
- [原创]Centos7 安装配置ASP.NET Core+Nginx+Supervisor
序言 此教程安装的都是最新版本的. 一键安装 有了这个神器,下面的教程就不用做了!只需运行几行代码,直接打开浏览器就可以访问! cd /home/ wget https://files.cnblogs ...
- Azure本月最新活动,速度Mark!
桃花夭夭,渌水盈盈,就这样四月的脚步迫不及待地来了.为了帮助您能在第一时间了解 Azure 最新的活动,我们推出每月活动合集,你准备好了吗,一起来看吧! 立即访问http://market.azure ...
- Windows下安装ElasticSearch及工具
转载自个人主页 前言 什么是ElasticSearch 官网如是介绍:Elasticsearch 是一个分布式.可扩展.实时的搜索与数据分析引擎. 它能从项目一开始就赋予你的数据以搜索.分析和探索的能 ...
- mysql自增ID
InnoDB引擎的表,执行清空操作之后,表的auto_increment值不会受到影响:一旦重启MySQL,auto_increment值将变成1. MyISAM引擎的表,执行清空操作之后,表的aut ...
- word禁止自动编号
在回车.换行时使用 shift + enter
- Sliding Window - The Smallest Window II(AIZU) && Leetcode 76
http://judge.u-aizu.ac.jp/onlinejudge/description.jsp?id=DSL_3_B For a given array a1,a2,a3,...,aNa1 ...
- 牛客国庆day 6 A
题目链接 : https://ac.nowcoder.com/acm/contest/206/A 这个题去年有幸去秦皇岛参加集训,见过这道题,当时特别菜还不会网络流,现在学了一点发现这个网络流还是比较 ...