Machine Learning——Unsupervised Learning(机器学习之非监督学习)

Machine Learning——Unsupervised Learning(机器学习之非监督学习)的更多相关文章
- supervised learning|unsupervised learning
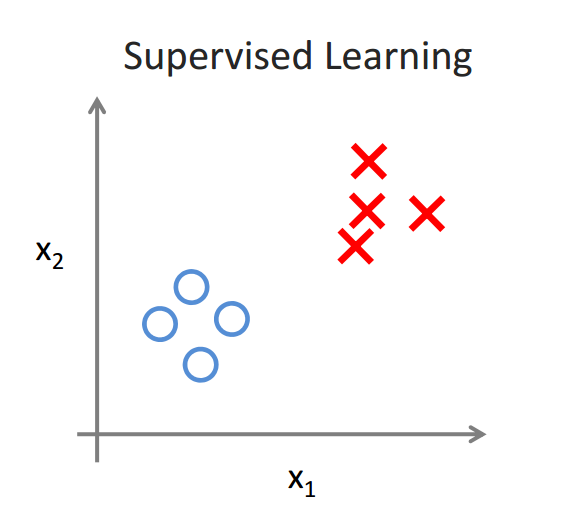
监督学习即是supervised learning,原始数据中有每个数据有自己的数据结构同时有标签,用于classify,机器learn的是判定规则,通过已成熟的数据training model达到判 ...
- 131.008 Unsupervised Learning - Principle component Analysis |PCA | 非监督学习 - 主成分分析
@(131 - Machine Learning | 机器学习) PCA是一种特征选择方法,可将一组相关变量转变成一组基础正交变量 25 PCA的回顾和定义 Demo: when to use PCA ...
- Coursera, Machine Learning, Unsupervised Learning, K-means, Dimentionality Reduction
Clustering K-means: 基本思想是先随机选择要分类数目的点,然后找出距离这些点最近的training data 着色,距离哪个点近就算哪种类型,再对每种分类算出平均值,把中心点移动到 ...
- 【Machine Learning】监督学习、非监督学习及强化学习对比
Supervised Learning Unsupervised Learning Reinforced Learning Goal: How to apply these methods How t ...
- Introduction - Unsupervised Learning
摘要: 本文是吴恩达 (Andrew Ng)老师<机器学习>课程,第一章<绪论:初识机器学习>中第4课时<无监督学习>的视频原文字幕.为本人在视频学习过程中逐字逐句 ...
- Unsupervised learning, attention, and other mysteries
Unsupervised learning, attention, and other mysteries Get notified when our free report “Future of M ...
- Supervised Learning and Unsupervised Learning
Supervised Learning In supervised learning, we are given a data set and already know what our correc ...
- Standford机器学习 聚类算法(clustering)和非监督学习(unsupervised Learning)
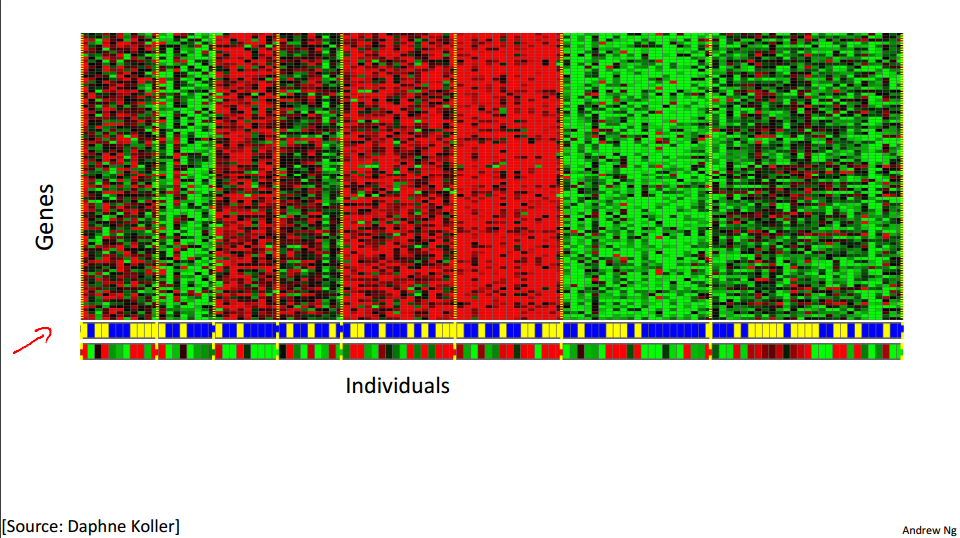
聚类算法是一类非监督学习算法,在有监督学习中,学习的目标是要在两类样本中找出他们的分界,训练数据是给定标签的,要么属于正类要么属于负类.而非监督学习,它的目的是在一个没有标签的数据集中找出这个数据集的 ...
- Machine Learning Algorithms Study Notes(4)—无监督学习(unsupervised learning)
1 Unsupervised Learning 1.1 k-means clustering algorithm 1.1.1 算法思想 1.1.2 k-means的不足之处 1 ...
随机推荐
- Visual Studio跨平台开发(2):Xamarin.iOS基本控制项介绍
前言 在上一篇文章中, 我们介绍了Xamarin 以及简单的HelloWorld范例, 这次我们针对iOS的专案目录架构以及基本控制项进行说明. 包含UIButton,UISlider,UISwitc ...
- [Python Cookbook] Pandas: 3 Ways to define a DataFrame
Using Series (Row-Wise) import pandas as pd purchase_1 = pd.Series({'Name': 'Chris', 'Item Purchased ...
- Lightoj 1348 Aladdin and the Return Journey (树链剖分)(线段树单点修改区间求和)
Finally the Great Magical Lamp was in Aladdin's hand. Now he wanted to return home. But he didn't wa ...
- Jboss ESB简介及开发实例
一.Jboss ESB的简介 1. 什么是ESB. ESB的全称是Enterprise Service Bus,即企业服务总线.ESB是过去消息中间件的发展,ESB采用了“总线”这样一 ...
- zoj Burn the Linked Camp (查分约束)
Burn the Linked Camp Time Limit: 2 Seconds Memory Limit: 65536 KB It is well known that, in the ...
- Codeforces Round #535 (Div. 3) [codeforces div3 难度测评]
hhhh感觉我真的太久没有接触过OI了 大约是前天听到JK他们约着一起刷codeforces,假期里觉得有些颓废的我忽然也心血来潮来看看题目 今天看codeforces才知道居然有div3了,感觉应该 ...
- XTU | 人工智能入门复习总结
写在前面 本文严禁转载,只限于学习交流. 课件分享在这里了. 还有人工智能标准化白皮书(2018版)也一并分享了. 绪论 人工智能的定义与发展 定义 一般解释:人工智能就是用 人工的方法在 **机器( ...
- 动态路由协议(3)--ospf
1.设置pc ip 网关 192.168.1.1 192.168.1.254 192.168.4.1 192.168.4.254 2.设置路由器 (1)设置接口ip Router(config-/ R ...
- Python学习笔记——对象
Python 的对象定义方式如下: class Person: def __init__(self, name): self.name = name ...
- UBIFS - UBI File-System
参考:http://www.linux-mtd.infradead.org/doc/ubifs.html#L_raw_vs_ftl UBIFS - UBI File-System Table of c ...